基于深度学习的目标检测(综述)
综述(基于深度学习的目标检测)
目录
- 综述
- 1、主流算法
- two-stage检测算法
- 1.基本流程
- one-stage检测算法
- 2.基本流程
- 算法综述
- 2、数据集
- pascal voc数据集
- imagenet数据集
- ms coco数据集
- 3、目标检测算法网络
- 1. R-cnn
- 2. Fast R-CNN
- 3.Faster R-CNN
- 总结
综述
1、图像分类和图像检测还有图像分割是计算机视觉的三大任务,图像分类模型含义就是把图像类别进行划分,就是识别图像的内容是什么。但是值得注意的是现实什么中的图像不单单只有一个图像,而是可能包含很多的信息,这样的话我们图像分类就会有自己的弊端,他只会把目标最大概率的图像进行进行分类,而忽略了其他的信息,这样得到的信息是不完整的,不准确的。对于这种情况,势必会采用一种全新的方式来进行我们图像的识别,这就是-----目标检测,通俗点说就是在一张图像里面,进行图像的内容的多分类识别,例如现实生活中的自动行驶汽车等等。。。。。。。。

1、主流算法
two-stage检测算法
1.基本流程
生成目标的候选区域,然后进行目标区域的划分分类,典型算法有基于region proposal的R-CNN系算法,如R-CNN,Fast R-CNN,Faster R-CNN等。
one-stage检测算法
2.基本流程
这个的流程就不行two-stage算法,要经过region proposal阶段,直接产生物体的类别概率和位置坐标值,典型算法有yolo和sdd。
算法综述
目标检测模型的主要性能指标是检测准确度和速度,对于准确度,目标检测要考虑物体的定位准确性,而不单单是分类准确度。一般情况下,two-stage算法在准确度上有优势,而one-stage算法在速度上有优势。

2、数据集
目标检测的数据集合我们常用的包括PASCAL VOC,ImageNet等数据集,这些数据集用于研究人员来研究和进行算法竞赛。下面进行介绍。
pascal voc数据集
这个数据集包括的计算机视觉三个方面的任务的著名数据集合,但是他的数据类别是20个类别,一般作为目标检测问题的一个基础数据集合,
imagenet数据集
这是包括边界框的目标检测数据集,他的训练集包含500000张图像,有200个类别。他的数据集合非常的大,这就导致了他的数据集合的训练时间很长,分类的列别数也很大,这就导致了训练的难度是非常大的,因为这些弊端导致了目标检测的难度是很大的。
ms coco数据集
这个数据集合是microsoft公司提出的,他可以应用在视觉三大任务和标题检测、关键点检测。对于我们的目标检测问题,它包含了80个类别,每年大赛的训练和验证数据集包含超过120,000个图片,超过40,000个测试图片。
3、目标检测算法网络
1. R-cnn
r-cnn 这个网络是基于region proposal方法的目标检测算法系列的开山之作,他首先是对图像进行区域搜索,然后对候选区域进行分类。在R-CNN中,选用selective search方法来生成候选区域,这属于一种启发式搜索算法。先是通过简单的区域划分呢算法将图像划分为很多小区域,然后通过层级分组方法按照一定相似度合并他们,最后的剩下的就是候选区域,他们可能包含一个物体。

2. Fast R-CNN
Fast R-CNN 的提出是来解决候选区域使用cnn模型特征向量所消耗的时间,其主要借鉴了spp-net的思想。在r-cnn网络中,他的每个候选区域使用都要单独的送入css模型计算特征向量,这是非常消耗时间的,而对于fast r-cnn,他的cnn输入的整个的图像特征,然后结合RoIs(Region of Interests)pooling和elective Search的方法从CNN得到的特征图中提取各个候选区域的所对应的特征,
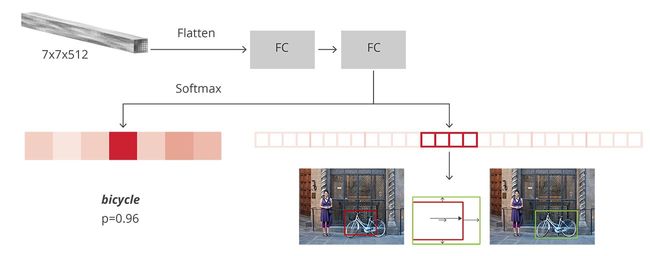

Fast R-CNN与R-CNN的另外的一个主要区别点是采用了softmax分类器而不是SVM分类器,而且训练过程是单管道的,因为Fast R-CNN将分类误差和定位误差合并在一起训练,定位误差采用smooth L1 而不是R-CNN中的L2。
3.Faster R-CNN
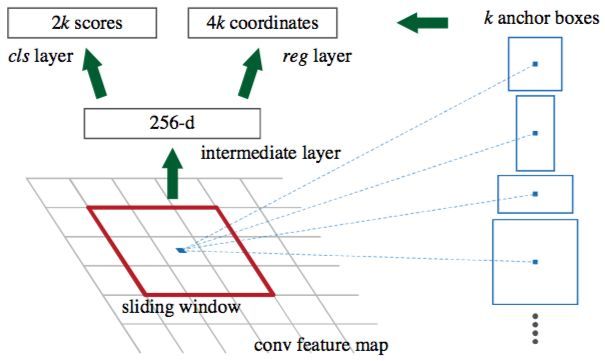
对于Fast R-CNN,其仍然需要selective search方法来生产候选区域,这是非常费时的。为了解决这个问题我们在这里引入了Faster R-CNN的概念,他是采用了RPN直接产生候选区域,Faster R-CNN可以看成是RPN和Fast R-CNN模型的组合体,即Faster R-CNN = RPN + Fast R-CNN。对于RPN网络,先采用一个CNN模型(一般称为特征提取器)接收整张图片并提取特征图。然后在这个特征图上采用一个 N x N 的滑动窗口,对于每个滑窗位置都映射一个低维度的特征(如256-d)。然后这个特征分别送入两个全连接层,一个用于分类预测,另外一个用于回归。对于每个窗口位置一般设置 K个不同大小或比例的先验框(anchors, default bounding boxes),这意味着每个位置预测 K 个候选区域(region proposals)。对于分类层,其输出大小是 2K ,表示各个候选区域包含物体或者是背景的概率值,而回归层输出 4K 个坐标值,表示各个候选区域的位置(相对各个先验框)。对于每个滑窗位置,这两个全连接层是共享的。因此,RPN可以采用卷积层来实现:首先是一个 **N X N ** 卷积得到低维特征,然后是两个 1 X 1 的卷积,分别用于分类与回归。
Faster R-CNN模型采用一种4步迭代的训练策略:(1)首先在ImageNet上预训练RPN,并在PASCAL VOC数据集上finetuning;(2)使用训练的PRN产生的region proposals单独训练一个Fast R-CNN模型,这个模型也先在ImageNet上预训练;(3)用Fast R-CNN的CNN模型部分(特征提取器)初始化RPN,然后对RPN中剩余层进行finetuning,此时Fast R-CNN与RPN的特征提取器是共享的;(4)固定特征提取器,对Fast R-CNN剩余层进行finetuning。这样经过多次迭代,Fast R-CNN可以与RPN有机融合在一起,形成一个统一的网络。
总结
这是一个对于目标检测算法的综述,我们能从里面了解到目标检测的基础知识。
这是个人的一个学习总结,有错误请联系作者,谢谢。