大话CNN经典模型:AlexNet
—— 原文发布于本人的微信公众号“大数据与人工智能Lab”(BigdataAILab),欢迎关注。
2012年,Alex Krizhevsky、Ilya Sutskever在多伦多大学Geoff Hinton的实验室设计出了一个深层的卷积神经网络AlexNet,夺得了2012年ImageNet LSVRC的冠军,且准确率远超第二名(top5错误率为15.3%,第二名为26.2%),引起了很大的轰动。AlexNet可以说是具有历史意义的一个网络结构,在此之前,深度学习已经沉寂了很长时间,自2012年AlexNet诞生之后,后面的ImageNet冠军都是用卷积神经网络(CNN)来做的,并且层次越来越深,使得CNN成为在图像识别分类的核心算法模型,带来了深度学习的大爆发。
在本博客之前的文章中已经介绍过了卷积神经网络(CNN)的技术原理(大话卷积神经网络),也回顾过卷积神经网络(CNN)的三个重要特点(大话CNN经典模型:LeNet),有兴趣的同学可以打开链接重新回顾一下,在此就不再重复CNN基础知识的介绍了。下面将先介绍AlexNet的特点,然后再逐层分解解析AlexNet网络结构。
一、AlexNet模型的特点
AlexNet之所以能够成功,跟这个模型设计的特点有关,主要有:
- 使用了非线性激活函数:ReLU
- 防止过拟合的方法:Dropout,数据扩充(Data augmentation)
- 其他:多GPU实现,LRN归一化层的使用
1、使用ReLU激活函数
传统的神经网络普遍使用Sigmoid或者tanh等非线性函数作为激励函数,然而它们容易出现梯度弥散或梯度饱和的情况。以Sigmoid函数为例,当输入的值非常大或者非常小的时候,这些神经元的梯度接近于0(梯度饱和现象),如果输入的初始值很大的话,梯度在反向传播时因为需要乘上一个Sigmoid导数,会造成梯度越来越小,导致网络变的很难学习。(详见本公博客的文章:深度学习中常用的激励函数)。
在AlexNet中,使用了ReLU (Rectified Linear Units)激励函数,该函数的公式为:f(x)=max(0,x),当输入信号<0时,输出都是0,当输入信号>0时,输出等于输入,如下图所示: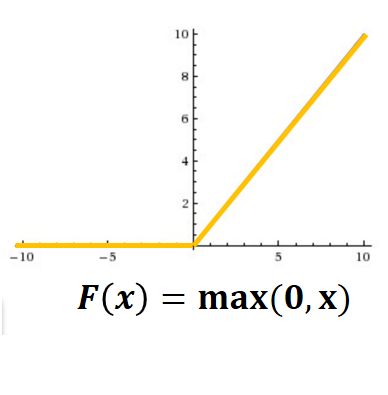
使用ReLU替代Sigmoid/tanh,由于ReLU是线性的,且导数始终为1,计算量大大减少,收敛速度会比Sigmoid/tanh快很多,如下图所示: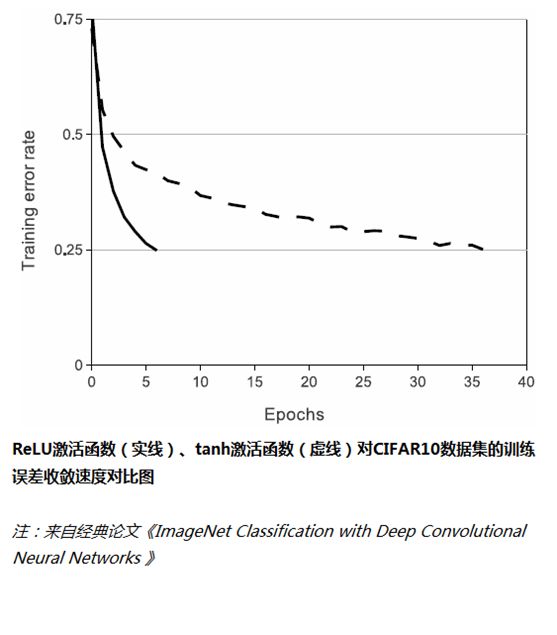
2、数据扩充(Data augmentation)
有一种观点认为神经网络是靠数据喂出来的,如果能够增加训练数据,提供海量数据进行训练,则能够有效提升算法的准确率,因为这样可以避免过拟合,从而可以进一步增大、加深网络结构。而当训练数据有限时,可以通过一些变换从已有的训练数据集中生成一些新的数据,以快速地扩充训练数据。
其中,最简单、通用的图像数据变形的方式:水平翻转图像,从原始图像中随机裁剪、平移变换,颜色、光照变换,如下图所示:
AlexNet在训练时,在数据扩充(data augmentation)这样处理:
(1)随机裁剪,对256×256的图片进行随机裁剪到224×224,然后进行水平翻转,相当于将样本数量增加了((256-224)^2)×2=2048倍;
(2)测试的时候,对左上、右上、左下、右下、中间分别做了5次裁剪,然后翻转,共10个裁剪,之后对结果求平均。作者说,如果不做随机裁剪,大网络基本上都过拟合;
(3)对RGB空间做PCA(主成分分析),然后对主成分做一个(0, 0.1)的高斯扰动,也就是对颜色、光照作变换,结果使错误率又下降了1%。
3、重叠池化 (Overlapping Pooling)
一般的池化(Pooling)是不重叠的,池化区域的窗口大小与步长相同,如下图所示: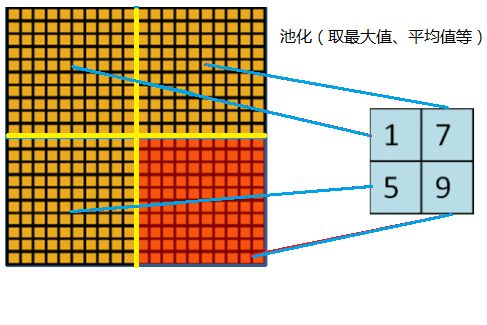
在AlexNet中使用的池化(Pooling)却是可重叠的,也就是说,在池化的时候,每次移动的步长小于池化的窗口长度。AlexNet池化的大小为3×3的正方形,每次池化移动步长为2,这样就会出现重叠。重叠池化可以避免过拟合,这个策略贡献了0.3%的Top-5错误率。
4、局部归一化(Local Response Normalization,简称LRN)
在神经生物学有一个概念叫做“侧抑制”(lateral inhibitio),指的是被激活的神经元抑制相邻神经元。归一化(normalization)的目的是“抑制”,局部归一化就是借鉴了“侧抑制”的思想来实现局部抑制,尤其当使用ReLU时这种“侧抑制”很管用,因为ReLU的响应结果是无界的(可以非常大),所以需要归一化。使用局部归一化的方案有助于增加泛化能力。
LRN的公式如下,核心思想就是利用临近的数据做归一化,这个策略贡献了1.2%的Top-5错误率。
5、Dropout
引入Dropout主要是为了防止过拟合。在神经网络中Dropout通过修改神经网络本身结构来实现,对于某一层的神经元,通过定义的概率将神经元置为0,这个神经元就不参与前向和后向传播,就如同在网络中被删除了一样,同时保持输入层与输出层神经元的个数不变,然后按照神经网络的学习方法进行参数更新。在下一次迭代中,又重新随机删除一些神经元(置为0),直至训练结束。
Dropout应该算是AlexNet中一个很大的创新,以至于“神经网络之父”Hinton在后来很长一段时间里的演讲中都拿Dropout说事。Dropout也可以看成是一种模型组合,每次生成的网络结构都不一样,通过组合多个模型的方式能够有效地减少过拟合,Dropout只需要两倍的训练时间即可实现模型组合(类似取平均)的效果,非常高效。
如下图所示: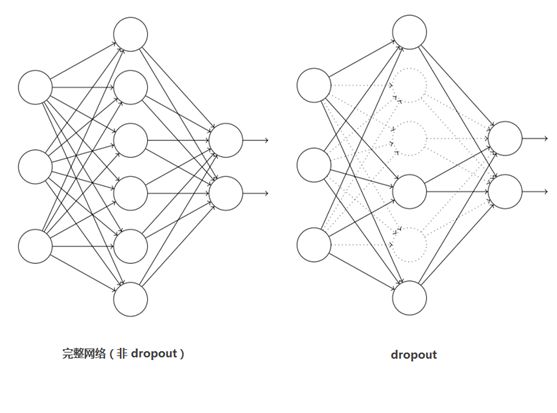
6、多GPU训练
AlexNet当时使用了GTX580的GPU进行训练,由于单个GTX 580 GPU只有3GB内存,这限制了在其上训练的网络的最大规模,因此他们在每个GPU中放置一半核(或神经元),将网络分布在两个GPU上进行并行计算,大大加快了AlexNet的训练速度。
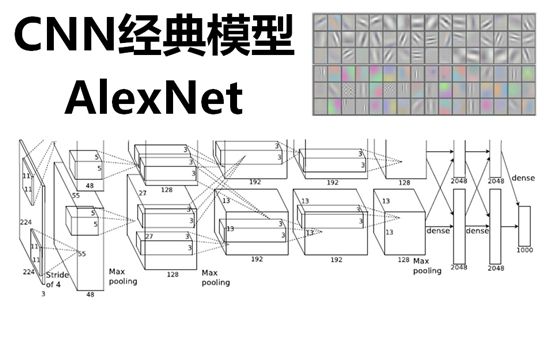
二、AlexNet网络结构的逐层解析
下图是AlexNet的网络结构图: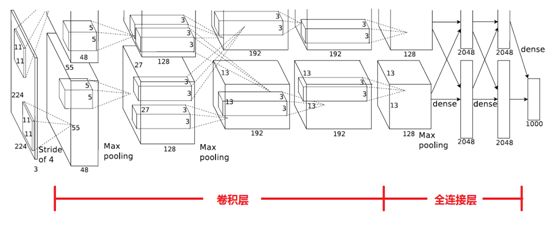
AlexNet网络结构共有8层,前面5层是卷积层,后面3层是全连接层,最后一个全连接层的输出传递给一个1000路的softmax层,对应1000个类标签的分布。
由于AlexNet采用了两个GPU进行训练,因此,该网络结构图由上下两部分组成,一个GPU运行图上方的层,另一个运行图下方的层,两个GPU只在特定的层通信。例如第二、四、五层卷积层的核只和同一个GPU上的前一层的核特征图相连,第三层卷积层和第二层所有的核特征图相连接,全连接层中的神经元和前一层中的所有神经元相连接。
下面逐层解析AlexNet结构:
1、第一层(卷积层)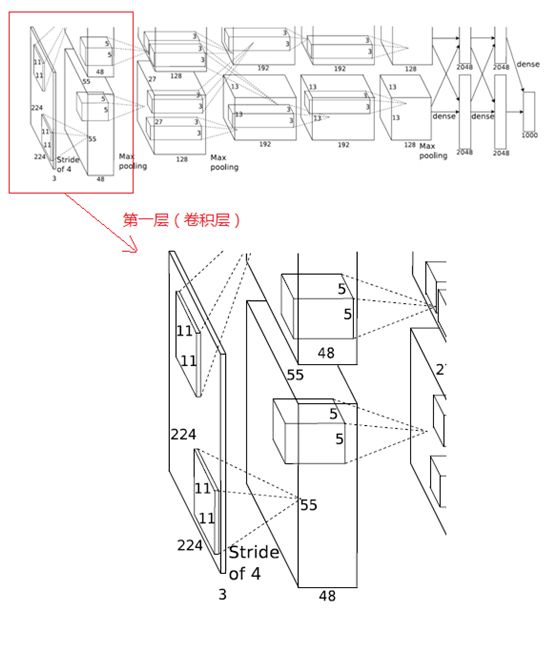
该层的处理流程为:卷积-->ReLU-->池化-->归一化,流程图如下: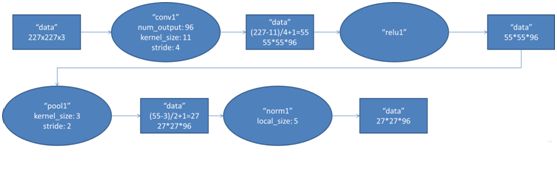
(1)卷积
输入的原始图像大小为224×224×3(RGB图像),在训练时会经过预处理变为227×227×3。在本层使用96个11×11×3的卷积核进行卷积计算,生成新的像素。由于采用了两个GPU并行运算,因此,网络结构图中上下两部分分别承担了48个卷积核的运算。
卷积核沿图像按一定的步长往x轴方向、y轴方向移动计算卷积,然后生成新的特征图,其大小为:floor((img_size - filter_size)/stride) +1 = new_feture_size,其中floor表示向下取整,img_size为图像大小,filter_size为核大小,stride为步长,new_feture_size为卷积后的特征图大小,这个公式表示图像尺寸减去卷积核尺寸除以步长,再加上被减去的核大小像素对应生成的一个像素,结果就是卷积后特征图的大小。
AlexNet中本层的卷积移动步长是4个像素,卷积核经移动计算后生成的特征图大小为 (227-11)/4+1=55,即55×55。
(2)ReLU
卷积后的55×55像素层经过ReLU单元的处理,生成激活像素层,尺寸仍为2组55×55×48的像素层数据。
(3)池化
RuLU后的像素层再经过池化运算,池化运算的尺寸为3×3,步长为2,则池化后图像的尺寸为 (55-3)/2+1=27,即池化后像素的规模为27×27×96
(4)归一化
池化后的像素层再进行归一化处理,归一化运算的尺寸为5×5,归一化后的像素规模不变,仍为27×27×96,这96层像素层被分为两组,每组48个像素层,分别在一个独立的GPU上进行运算。
2、第二层(卷积层)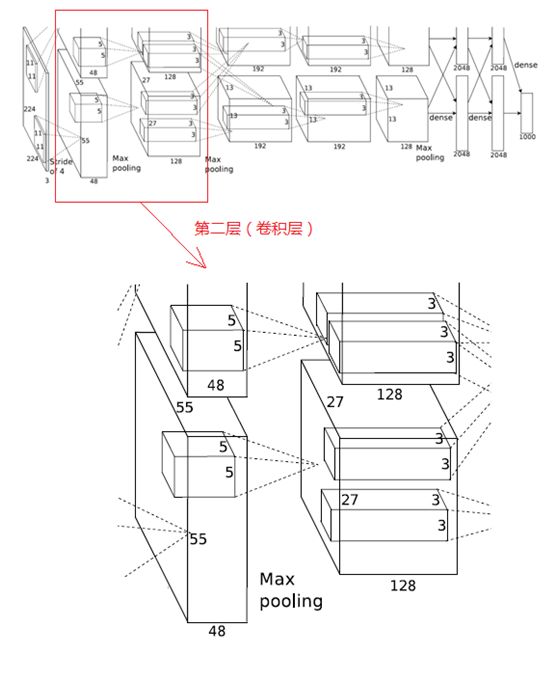
该层与第一层类似,处理流程为:卷积-->ReLU-->池化-->归一化,流程图如下: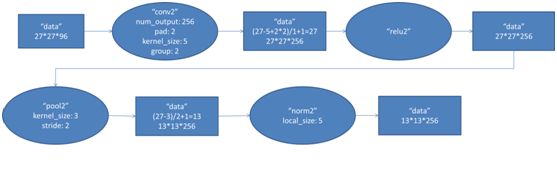
(1)卷积
第二层的输入数据为第一层输出的27×27×96的像素层(被分成两组27×27×48的像素层放在两个不同GPU中进行运算),为方便后续处理,在这里每幅像素层的上下左右边缘都被填充了2个像素(填充0),即图像的大小变为 (27+2+2) ×(27+2+2)。第二层的卷积核大小为5×5,移动步长为1个像素,跟第一层第(1)点的计算公式一样,经卷积核计算后的像素层大小变为 (27+2+2-5)/1+1=27,即卷积后大小为27×27。
本层使用了256个5×5×48的卷积核,同样也是被分成两组,每组为128个,分给两个GPU进行卷积运算,结果生成两组27×27×128个卷积后的像素层。
(2)ReLU
这些像素层经过ReLU单元的处理,生成激活像素层,尺寸仍为两组27×27×128的像素层。
(3)池化
再经过池化运算的处理,池化运算的尺寸为3×3,步长为2,池化后图像的尺寸为(57-3)/2+1=13,即池化后像素的规模为2组13×13×128的像素层
(4)归一化
然后再经归一化处理,归一化运算的尺度为5×5,归一化后的像素层的规模为2组13×13×128的像素层,分别由2个GPU进行运算。
3、第三层(卷积层)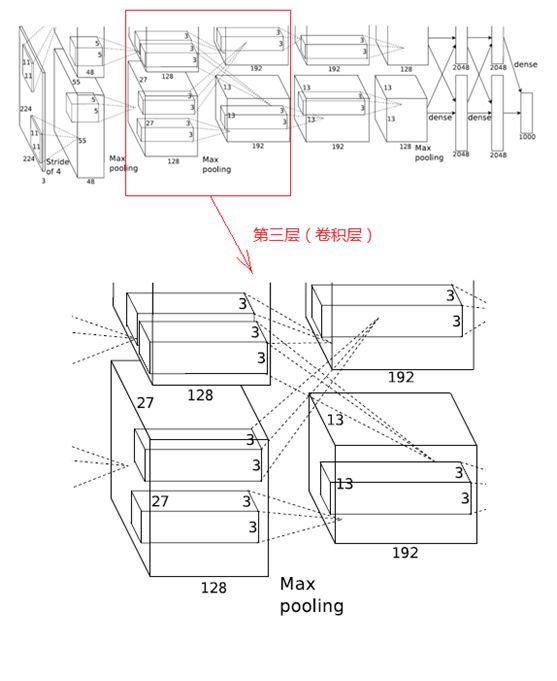
第三层的处理流程为:卷积-->ReLU
(1)卷积
第三层输入数据为第二层输出的2组13×13×128的像素层,为便于后续处理,每幅像素层的上下左右边缘都填充1个像素,填充后变为 (13+1+1)×(13+1+1)×128,分布在两个GPU中进行运算。
这一层中每个GPU都有192个卷积核,每个卷积核的尺寸是3×3×256。因此,每个GPU中的卷积核都能对2组13×13×128的像素层的所有数据进行卷积运算。如该层的结构图所示,两个GPU有通过交叉的虚线连接,也就是说每个GPU要处理来自前一层的所有GPU的输入。
本层卷积的步长是1个像素,经过卷积运算后的尺寸为 (13+1+1-3)/1+1=13,即每个GPU中共13×13×192个卷积核,2个GPU中共有13×13×384个卷积后的像素层。
(2)ReLU
卷积后的像素层经过ReLU单元的处理,生成激活像素层,尺寸仍为2组13×13×192的像素层,分配给两组GPU处理。
4、第四层(卷积层)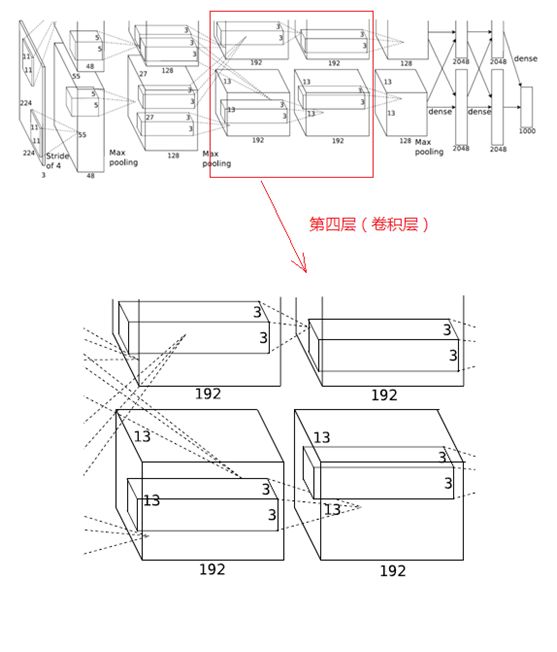
与第三层类似,第四层的处理流程为:卷积-->ReLU

(1)卷积
第四层输入数据为第三层输出的2组13×13×192的像素层,类似于第三层,为便于后续处理,每幅像素层的上下左右边缘都填充1个像素,填充后的尺寸变为 (13+1+1)×(13+1+1)×192,分布在两个GPU中进行运算。
这一层中每个GPU都有192个卷积核,每个卷积核的尺寸是3×3×192(与第三层不同,第四层的GPU之间没有虚线连接,也即GPU之间没有通信)。卷积的移动步长是1个像素,经卷积运算后的尺寸为 (13+1+1-3)/1+1=13,每个GPU中有13×13×192个卷积核,2个GPU卷积后生成13×13×384的像素层。
(2)ReLU
卷积后的像素层经过ReLU单元处理,生成激活像素层,尺寸仍为2组13×13×192像素层,分配给两个GPU处理。
5、第五层(卷积层)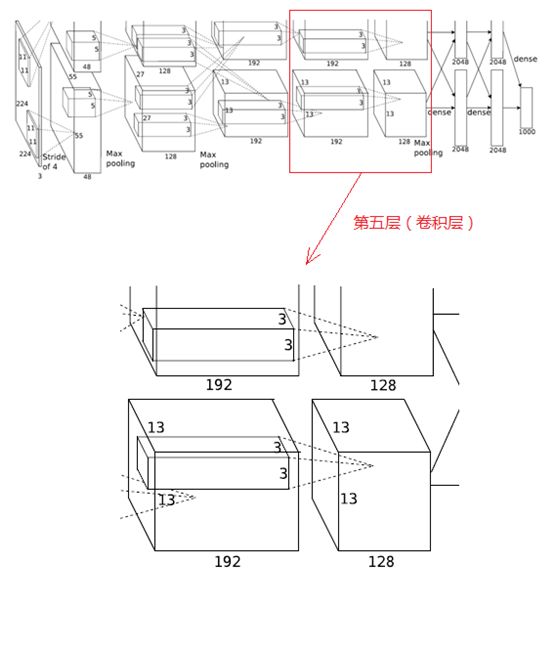
第五层的处理流程为:卷积-->ReLU-->池化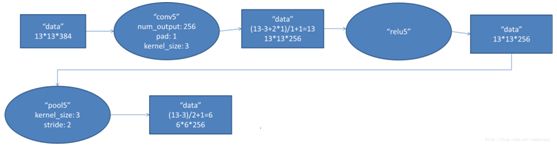
(1)卷积
第五层输入数据为第四层输出的2组13×13×192的像素层,为便于后续处理,每幅像素层的上下左右边缘都填充1个像素,填充后的尺寸变为 (13+1+1)×(13+1+1) ,2组像素层数据被送至2个不同的GPU中进行运算。
这一层中每个GPU都有128个卷积核,每个卷积核的尺寸是3×3×192,卷积的步长是1个像素,经卷积后的尺寸为 (13+1+1-3)/1+1=13,每个GPU中有13×13×128个卷积核,2个GPU卷积后生成13×13×256的像素层。
(2)ReLU
卷积后的像素层经过ReLU单元处理,生成激活像素层,尺寸仍为2组13×13×128像素层,由两个GPU分别处理。
(3)池化
2组13×13×128像素层分别在2个不同GPU中进行池化运算处理,池化运算的尺寸为3×3,步长为2,池化后图像的尺寸为 (13-3)/2+1=6,即池化后像素的规模为两组6×6×128的像素层数据,共有6×6×256的像素层数据。
6、第六层(全连接层)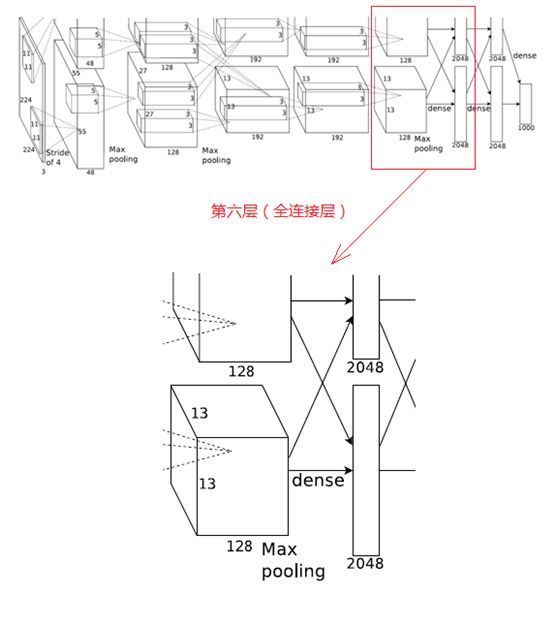
第六层的处理流程为:卷积(全连接)-->ReLU-->Dropout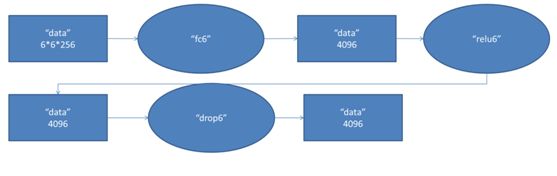
(1)卷积(全连接)
第六层输入数据是第五层的输出,尺寸为6×6×256。本层共有4096个卷积核,每个卷积核的尺寸为6×6×256,由于卷积核的尺寸刚好与待处理特征图(输入)的尺寸相同,即卷积核中的每个系数只与特征图(输入)尺寸的一个像素值相乘,一一对应,因此,该层被称为全连接层。由于卷积核与特征图的尺寸相同,卷积运算后只有一个值,因此,卷积后的像素层尺寸为4096×1×1,即有4096个神经元。
(2)ReLU
这4096个运算结果通过ReLU激活函数生成4096个值。
(3)Dropout
然后再通过Dropout运算,输出4096个结果值。
7、第七层(全连接层)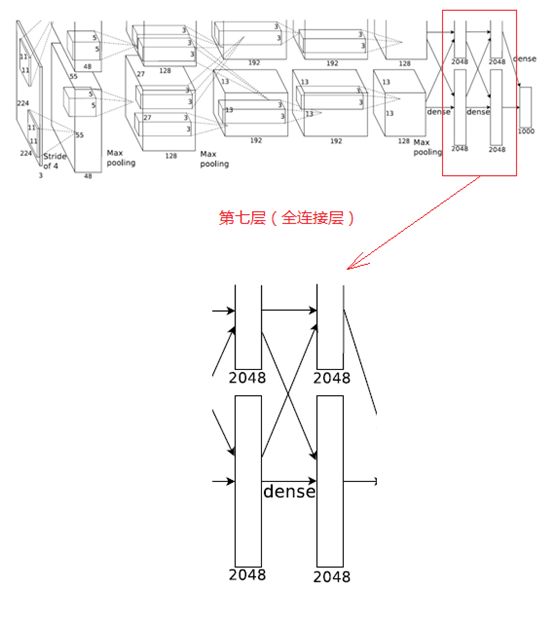
第七层的处理流程为:全连接-->ReLU-->Dropout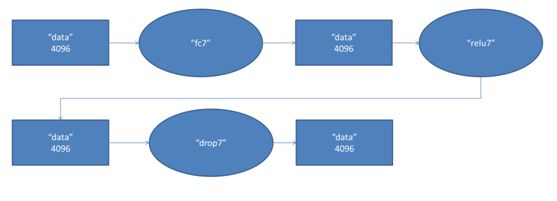
第六层输出的4096个数据与第七层的4096个神经元进行全连接,然后经ReLU进行处理后生成4096个数据,再经过Dropout处理后输出4096个数据。
8、第八层(全连接层)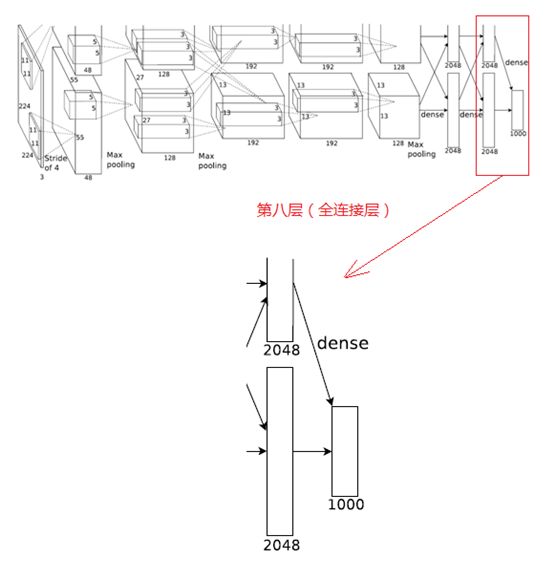
第八层的处理流程为:全连接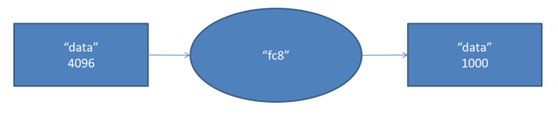
第七层输出的4096个数据与第八层的1000个神经元进行全连接,经过训练后输出1000个float型的值,这就是预测结果。
以上就是关于AlexNet网络结构图的逐层解析了,看起来挺复杂的,下面是一个简图,看起来就清爽很多啊
通过前面的介绍,可以看出AlexNet的特点和创新之处,主要如下: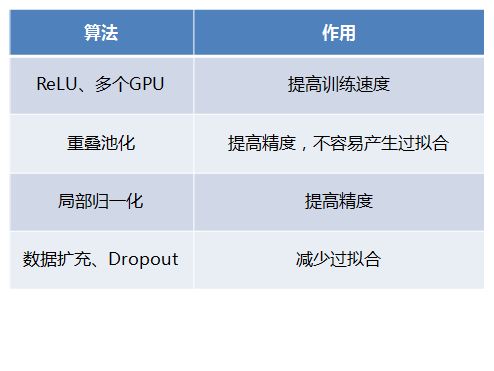
墙裂建议
Alex等人在2012年发表了关于AlexNet的经典论文《ImageNet Classification with Deep Convolutional Neural Networks》(基于深度卷积神经网络的 ImageNet 分类),整个过程都有详细的介绍,建议阅读这篇论文,进一步了解细节。
扫描以下二维码关注本人公众号“大数据与人工智能Lab”(BigdataAILab),然后回复“论文”关键字可在线阅读这篇经典论文的内容。

推荐相关阅读
- 大话卷积神经网络(CNN)
- 大话循环神经网络(RNN)
- 大话深度残差网络(DRN)
- 大话深度信念网络(DBN)
- 大话CNN经典模型:LeNet
- 深度学习中常用的激励函数