TensorFlow入门教程(3)深度学习基本概念和知识点
#
#作者:韦访
#博客:https://blog.csdn.net/rookie_wei
#微信:1007895847
#添加微信的备注一下是CSDN的
#欢迎大家一起学习
#
1、概述
上一讲,我们讲解了深度学习界的“hello world”---用Softmax对MNIST数据集进行分类的任务。对于一些刚接触深度学习的朋友来说可能会觉得一脸懵逼,所以,这一讲,我们就来看看一些深度学习的基本概念和知识点,为后面的学习打下基础。

3、前向传播
数据从输入到输出的的过程叫前向传播,不同的神经网络结构前向传播的方式是不一样的,最简单的前向传播算法就是上面的公式,输入x经过与权重w的加权和再加上偏置b,得到的结果y。
4、反向传播
网络训练前,我们当然不知道w和b的值是多少才是合适的值,反向传播的作用就是根据前向传播的到的结果与实际标签的误差,反馈给网络,网络根据误差来调整权重以得到更优值。
在实际应用中,一般都是经过多次迭代,一点一点修正w和b的值,直到模型的输出和实际标签的误差小于我们设定的某个阈值为止。以后我们会有专门的博客来讲解前向传播的具体算法,这里先有个概念就可以了。
5、损失函数
训练模型的输出值和实际值肯定存在一定偏差,这种偏差越小,表示模型预测越准确,而衡量这种偏差的函数我们称为损失函数。
常用的损失函数有均方误差(MSE)和交叉熵。

6、分类和回归
既然上面说到分类问题和回归问题,这里就介绍一下这两类问题。
分类问题:分类问题希望解决的是将不同的样本分到事先定义好的类别中,比如判断一个零件是否合格的问题就是一个二分类问题。手写体数字识别问题是一个十分类问题(0~9十个数字)。
回归问题:回归问题解决的是对具体数值的预测。比如房价预测、销量预测等。这些问题所需要预测的不是一个事先定义好的类别,而是任意实数。解决回归问题一般只有一个输出节点,这个节点的输出值就是预测值。
7、优化器
前面说过,反向传播是将预测值与实际值之间的误差,反馈给网络,网络再去优化权重,怎么优化权重,就是优化器函数该做的事了。常用的优化算法有梯度下降法,关于梯度下降法,上一讲也有详细的介绍,这里不再赘述。
8、学习率
上一讲在讲解梯度下降法时也提过学习率,每个优化器都会有一个学习率的参数,设置学习率的大小,是在精度和速度之间找到一个平衡,学习率决定了每次更新的速度,如果幅度过大,可能导致参数在极忧值两侧来回移动,如果幅度过小,就会大大降低优化速度。
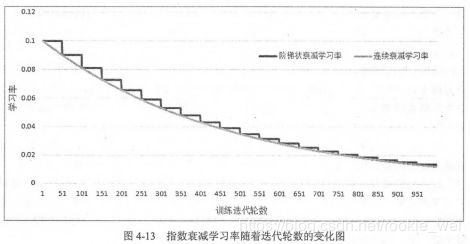
为了解决这个问题,有人提出了一种更加灵活的学习率设置方法----指数衰减法。
通过这种方法可以先使用较大的学习率快速得到一个比较优的解,然后逐步减小学习率,使得模型在训练后期更加稳定,如下图所示(图的出处我忘了),
9、激活函数
线性模型的局限性:只通过线性变换,任意层的全连接神经网络和单层神经网络的表达能力并没有任何区别,线性模型能解决的问题是有限的。
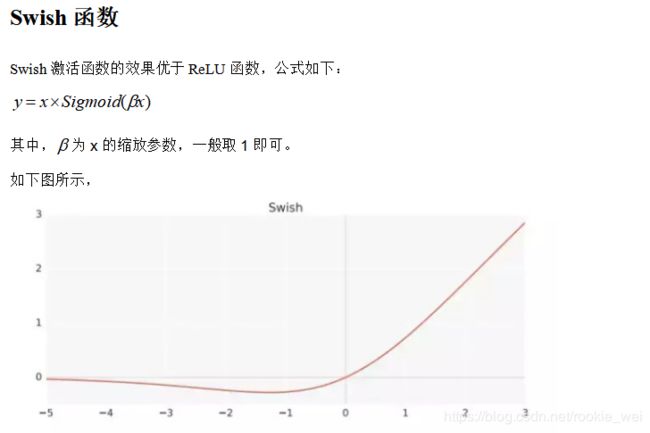
激活函数的目的是去线性化,如果将每一个神经元的输出通过一个非线性函数,那么整个神经网络的模型也就不再是线性的了,这个非线性函数就是激活函数。
下面来看几个常见的激活函数,



10、欠拟合和过拟合
欠拟合(Underfitting)是指模型不能在训练集上获得足够低的误差。而过拟合(Overfitting)是指训练误差和和测试误差之间的差距太大。 如下图所示,
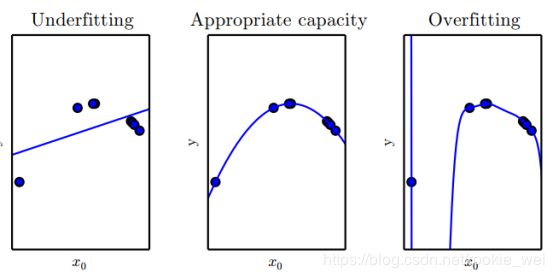
上图中,(左) 用一个线性函数拟合数据会导致欠拟合——它无法捕捉数据中的曲率信息。 (中) 用二次函数拟合数据在未观察到的点上泛化得很好。这并不会导致明显的欠拟合或者过拟合。 (右) 一个 9 阶的多项式拟合数据会导致过拟合。
11、正则化
在机器学习中,为了避免过拟合问题,许多策略显式地被设计来减少测试误差(可能会以增大训练误差为代价),这些策略被统称为正则化(regularization)。



数据增强
数据增强也是一种正则化方法。让机器学习模型泛化得更好的最好办法是使用更多的数据进行训练。在实践中,我们拥有的数据量是很有限的,解决这个问题的一种方法是创建假数据并添加到训练集中,这就是数据增强。
对图像任务来说,数据增强是指对训练的图像数据,利用平移、翻转、缩放、颜色变换等操作,增大训练样本个数,从而得到充足的数据,使模型训练得更好。
常用的数据增强方法如下:
平移:将图像在一定尺寸范围内平移
翻转:水平或上下翻转图像
旋转:将图像在一定角度内旋转
裁剪:在原图像中裁剪一块图像
缩放:将图像按一定比例方法或者缩小
颜色变换:对图像的RGB进行变换
噪声扰动:给图像加入一些人工噪声
注:使用数据增强的前提是不能改变图像原有标签属性,比如,数字6不能旋转180度等等
提前终止
当训练有足够的表示能力甚至会过拟合的大模型时,我们经常观察到,训练误差会随着时间的推移逐渐降低但验证集的误差会再次上升。下图是这些现象的一个例子,这种现象几乎一定会出现。

这意味着我们只要返回使验证集误差最低的参数设置,就可以获得验证集误差更低的模型(并且因此有希望获得更好的测试误差)。
在每次验证集误差有所改善后,我们存储模型参数的副本。当训练算法终止时,我们返回这些参数而不是最新的参数。当验证集上的误差在事先指定的循环次数内没有进一步改善时,算法就会终止。这种策略被称为提前终止。
Droupout
Dropout是非常常用的一个正则化方法,在不同的训练过程中随机“丢掉”一部分神经元,让其不工作,但这个“丢掉”只是针对当前训练步骤的,让其在这次训练中不更新权值,也不参与这次的神经网络计算,下次训练时,这个神经元又可能工作。
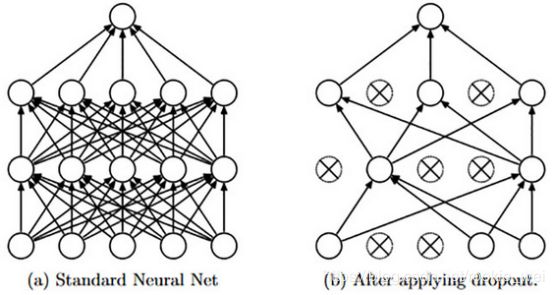
对于非常大的数据集, 正则化带来的泛化误差减少得很小。在这些情况下,使用Dropout和更大模型的计算代价可能超过正则化带来的好处。只有极少的训练样本可用时, Dropout不会很有效。
12、交叉验证
假设我们有一堆数据,一般都是将其分为train数据和test数据,train数据用来训练模型,test数据用来测试模型的。如下图所示,

交叉验证呢,就是再将train数据分成几份,比如分成3份,分别为A、B、C,然后,先用A、B作为train数据,C作为test数据;再用A、C作为train数据,B作为test数据;再用B、C作为train数据,A作为test数据。最后,记录每次训练的误差![]() ,取其平均值作为总误差。模型如下图所示,
,取其平均值作为总误差。模型如下图所示,

这一讲就先讲这么多吧,以后遇到什么新的概念再讲吧。
下一讲,我们来看看TensorFlow的一些编程基础。