tensorflow入门教程(四十二)ckpt,pb模型的保存,固化和加载操作
#
#作者:韦访
#博客:https://blog.csdn.net/rookie_wei
#微信:1007895847
#添加微信的备注一下是CSDN的
#欢迎大家一起学习
#
------韦访 20190525
1、概述
又是25号,老天保佑我摇到车牌啊~~开玩笑,这不是今天的重点。有网友表示,模型训练出来以后,不知道要怎么用,今天就来聊聊tensorflow模型的保存、固化、加载等操作,为方便讲解,直接拿第二讲的两层卷积神经网络训练MNIST的代码来改,如果忘了了,博客链接如下,
https://blog.csdn.net/rookie_wei/article/details/80146620
2、将模型保存成ckpt格式
对以前的代码稍微修改一点点,以前我们定义变量或者占位符等是没有指定名字的,不指定名字也是可以的,系统会自动给它们名字的,但是为了更直观的理解代码,我们现在给它们都指定个名字,
比如我们以前定义占位符如下,是没有指定名字的,
#创建x占位符,用于临时存放MNIST图片的数据,
# [None, 784]中的None表示不限长度,而784则是一张图片的大小(28×28=784)
x = tf.placeholder(tf.float32, [None, 784])
#y_存的是实际图像的标签,即对应于每张输入图片实际的值
y_ = tf.placeholder(tf.float32, [None, 10])现在我们要给它们指定个名字,如下,
#创建x占位符,用于临时存放MNIST图片的数据,
# [None, 784]中的None表示不限长度,而784则是一张图片的大小(28×28=784)
x = tf.placeholder(tf.float32, [None, 784], name='input_x')
#y_存的是实际图像的标签,即对应于每张输入图片实际的值
y_ = tf.placeholder(tf.float32, [None, 10], name='input_y')还有其他的就不一一贴了,这里直接给出修改以后的完整代码,
# coding: utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
mnist = input_data.read_data_sets('mnist_data', one_hot=True)
#初始化过滤器
def weight_variable(shape, name):
return tf.Variable(tf.truncated_normal(shape, stddev=0.1), name=name)
#初始化偏置,初始化时,所有值是0.1
def bias_variable(shape, name):
return tf.Variable(tf.constant(0.1, shape=shape), name=name)
#卷积运算,strides表示每一维度滑动的步长,一般strides[0]=strides[3]=1
#第四个参数可选"Same"或"VALID",“Same”表示边距使用全0填充
def conv2d(x, W, name):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding="SAME", name=name)
#池化运算
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
#创建x占位符,用于临时存放MNIST图片的数据,
# [None, 784]中的None表示不限长度,而784则是一张图片的大小(28×28=784)
x = tf.placeholder(tf.float32, [None, 784], name='input_x')
#y_存的是实际图像的标签,即对应于每张输入图片实际的值
y_ = tf.placeholder(tf.float32, [None, 10], name='input_y')
#将图片从784维向量重新还原为28×28的矩阵图片,
# 原因参考卷积神经网络模型图,最后一个参数代表深度,
# 因为MNIST是黑白图片,所以深度为1,
# 第一个参数为-1,表示一维的长度不限定,这样就可以灵活设置每个batch的训练的个数了
x_image = tf.reshape(x, [-1, 28, 28, 1])
#第一层卷积
#将过滤器设置成5×5×1的矩阵,
#其中5×5表示过滤器大小,1表示深度,因为MNIST是黑白图片只有一层。所以深度为1
#32表示我们要创建32个大小5×5×1的过滤器,经过卷积后算出32个特征图(每个过滤器得到一个特征图),即输出深度为64
W_conv1 = weight_variable([5, 5, 1, 32], 'W_conv1')
#有多少个特征图就有多少个偏置
b_conv1 = bias_variable([32], 'b_conv1')
#使用conv2d函数进行卷积计算,然后再用ReLU作为激活函数
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1, 'h_conv1') + b_conv1)
#卷积以后再经过池化操作
h_pool1 = max_pool_2x2(h_conv1)
#第二层卷积
#因为经过第一层卷积运算后,输出的深度为32,所以过滤器深度和下一层输出深度也做出改变
W_conv2 = weight_variable([5, 5, 32, 64], 'W_conv2')
b_conv2 = bias_variable([64], 'b_conv2')
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2, 'h_conv2') + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
#全连接层
#经过两层卷积后,图片的大小为7×7(第一层池化后输出为(28/2)×(28/2),
#第二层池化后输出为(14/2)×(14/2)),深度为64,
#我们在这里加入一个有1024个神经元的全连接层,所以权重W的尺寸为[7 * 7 * 64, 1024]
W_fc1 = weight_variable([7 * 7 * 64, 1024], 'W_fc1')
#偏置的个数和权重的个数一致
b_fc1 = bias_variable([1024], 'b_fc1')
#这里将第二层池化后的张量(长:7 宽:7 深度:64) 变成向量(跟上一节的Softmax模型的输入一样了)
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
#使用ReLU激活函数
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
#dropout
#为了减少过拟合,我们在输出层之前加入dropout
keep_prob = tf.placeholder(tf.float32, name='keep_prob')
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
#输出层
#全连接层输入的大小为1024,而我们要得到的结果的大小是10(0~9),
# 所以这里权重W的尺寸为[1024, 10]
W_fc2 = weight_variable([1024, 10], 'W_fc2')
b_fc2 = bias_variable([10], 'b_fc2')
#最后都要经过Softmax函数将输出转化为概率问题
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2, name='y_conv')
#损失函数和损失优化
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv)))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
#测试准确率,跟Softmax回归模型的一样
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
#将训练结果保存,如果不保存我们这次训练结束后的结果也随着程序运行结束而释放了
savePath = './mnist_model/'
saveFile = savePath + 'mnist_model.ckpt'
if os.path.exists(savePath) == False:
os.mkdir(savePath)
saver = tf.train.Saver()
#开始训练
with tf.Session() as sess:
#初始化所有变量
sess.run(tf.global_variables_initializer())
#训练两万次
for i in range(20000):
#每次获取50张图片数据和对应的标签
batch = mnist.train.next_batch(50)
#每训练100次,我们打印一次训练的准确率
if i % 100 == 0:
train_accuracy =sess.run(accuracy, feed_dict={x:batch[0], y_:batch[1], keep_prob:1.0})
print("step %d, training accuracy %g" % (i, train_accuracy))
#这里是真的训练,将数据传入
sess.run(train_step, feed_dict={x:batch[0], y_:batch[1], keep_prob:0.5})
print ("end train, start testing...")
mean_value = 0.0
for i in range(mnist.test.labels.shape[0]):
batch = mnist.test.next_batch(50)
train_accuracy = sess.run(accuracy, feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0})
mean_value += train_accuracy
print("test accuracy %g" % (mean_value / mnist.test.labels.shape[0]))
# #训练结束后,我们使用mnist.test在测试最后的准确率
# print("test accuracy %g" % sess.run(accuracy, feed_dict={x:mnist.test.images, y_:mnist.test.labels, keep_prob:1.0}))
# 最后,将会话保存下来
saver.save(sess, saveFile)运行结果如下,
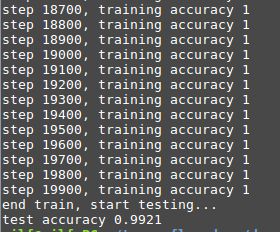

mnist_model文件夹下生成4个文件,这个就是我们保存好的ckpt模型。
3、加载ckpt模型
以前我们加载ckpt模型直接用saver.restore来加载,可以回去看以前的博客,
https://blog.csdn.net/rookie_wei/article/details/80142876
这样做其实我们并没有调用ckpt里保存的图,而是还是用我们原来代码里定义好的图,现在我们来使用ckpt里保存的图,代码会简洁很多。来看代码,
# coding: utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
mnist = input_data.read_data_sets('mnist_data', one_hot=True)
#看指定路径有没有我们要用的ckpt模型,没有就退出
savePath = './mnist_model/'
saveFile = os.path.join(savePath, 'mnist_model.ckpt.meta')
if os.path.exists(saveFile) is False:
print('Not found ckpt file!')
exit()上面是先检测看指定路径有没有我们要用的ckpt模型,没有就退出,
with tf.Session() as sess:
# 加载图
saver = tf.train.import_meta_graph(saveFile)
# 使用最后一次保存的
saver.restore(sess, tf.train.latest_checkpoint(savePath))
# 通过名字,直接从ckpt里获取对应的tensor
input_x = sess.graph.get_tensor_by_name('input_x:0')
input_y = sess.graph.get_tensor_by_name('input_y:0')
keep_prob = sess.graph.get_tensor_by_name('keep_prob:0')
y_conv = sess.graph.get_tensor_by_name('y_conv:0')接着就是从ckpt中加载图,然后通过名字获取相应的tensor,拿到tensor以后就可以直接用了,代码如下,
# 测试准确率
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(input_y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
mean_value = 0.0
for i in range(mnist.test.labels.shape[0]):
batch = mnist.test.next_batch(50)
train_accuracy = sess.run(accuracy, feed_dict={input_x: batch[0], input_y: batch[1], keep_prob: 1.0})
mean_value += train_accuracy
print("test accuracy %g" % (mean_value / mnist.test.labels.shape[0]))
# #训练结束后,我们使用mnist.test在测试最后的准确率
# print("test accuracy %g" % sess.run(accuracy, feed_dict={x:mnist.test.images, y_:mnist.test.labels, keep_prob:1.0}))完整代码如下,
# coding: utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
mnist = input_data.read_data_sets('mnist_data', one_hot=True)
#看指定路径有没有我们要用的ckpt模型,没有就退出
savePath = './mnist_model/'
saveFile = os.path.join(savePath, 'mnist_model.ckpt.meta')
if os.path.exists(saveFile) is False:
print('Not found ckpt file!')
exit()
with tf.Session() as sess:
# 加载图
saver = tf.train.import_meta_graph(saveFile)
# 使用最后一次保存的
saver.restore(sess, tf.train.latest_checkpoint(savePath))
# 通过名字,直接从ckpt里获取对应的tensor
input_x = sess.graph.get_tensor_by_name('input_x:0')
input_y = sess.graph.get_tensor_by_name('input_y:0')
keep_prob = sess.graph.get_tensor_by_name('keep_prob:0')
y_conv = sess.graph.get_tensor_by_name('y_conv:0')
# 测试准确率
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(input_y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
mean_value = 0.0
for i in range(mnist.test.labels.shape[0]):
batch = mnist.test.next_batch(50)
train_accuracy = sess.run(accuracy, feed_dict={input_x: batch[0], input_y: batch[1], keep_prob: 1.0})
mean_value += train_accuracy
print("test accuracy %g" % (mean_value / mnist.test.labels.shape[0]))
# #训练结束后,我们使用mnist.test在测试最后的准确率
# print("test accuracy %g" % sess.run(accuracy, feed_dict={x:mnist.test.images, y_:mnist.test.labels, keep_prob:1.0}))运行结果,
![]()
一样能用是吧,而且我们代码精简了很多,你根本不用关心整个模型的结构。
4、将ckpt模型固化成pb模型文件
真正部署的时候,一般人家不会给你ckpt模型的,而是固化成pb模型以后再给你用,现在我们就来看看怎么将ckpt固化成pb模型。还是用上面的例子,这里比较简单,直接给出完整代码,
# coding: utf-8
import tensorflow as tf
from tensorflow.python.framework import graph_util
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
#看指定路径有没有我们要用的ckpt模型,没有就退出
savePath = './mnist_model/'
saveFile = os.path.join(savePath, 'mnist_model.ckpt.meta')
if os.path.exists(saveFile) is False:
print('Not found ckpt file!')
exit()
#我们要保存的pb模型的路径
savePbPath = os.path.join(savePath, 'model_pb')
if os.path.exists(savePbPath) is False:
os.mkdir(savePbPath)
#我们要保存的pb模型的文件名
savePbFile = os.path.join(savePbPath, 'mnist_model.pb')
with tf.Session() as sess:
# 加载图
saver = tf.train.import_meta_graph(saveFile)
# 使用最后一次保存的
saver.restore(sess, tf.train.latest_checkpoint(savePath))
# 我们要固化哪些tensor
output_graph_def = graph_util.convert_variables_to_constants(
sess=sess,
input_graph_def= sess.graph_def,
output_node_names=['input_x', 'input_y', 'keep_prob', 'y_conv']
)
# 保存
with tf.gfile.GFile(savePbFile, 'wb') as fd:
fd.write(output_graph_def.SerializeToString())运行结果,
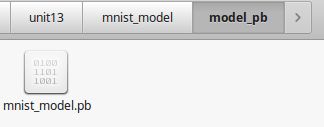
运行完以后,mnist_model文件夹下会生成一个model_pb文件夹,model_pb文件下下有个.pb文件,这个文件就是我们固化后的模型。
5、加载pb模型文件
模型固化成pb文件以后,我们的最终目的当然还是要用起来啊,接下来我们看看怎么用这个pb模型,也比较简单,直接给完整代码,
# coding: utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
from tensorflow.python.platform import gfile
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
mnist = input_data.read_data_sets('mnist_data', one_hot=True)
#先检测看pb文件是否存在
savePath = './mnist_model/'
savePbPath = os.path.join(savePath, 'model_pb')
savePbFile = os.path.join(savePbPath, 'mnist_model.pb')
if os.path.exists(savePbFile) is False:
print('Not found pb file!')
exit()
with tf.Session() as sess:
# 打开pb模型文件
with gfile.FastGFile(savePbFile, 'rb') as fd:
# 导入图
graph_def = tf.GraphDef()
graph_def.ParseFromString(fd.read())
sess.graph.as_default()
tf.import_graph_def(graph_def, name='')
# 根据名字获取对应的tensorflow
input_x = sess.graph.get_tensor_by_name('input_x:0')
input_y = sess.graph.get_tensor_by_name('input_y:0')
keep_prob = sess.graph.get_tensor_by_name('keep_prob:0')
y_conv = sess.graph.get_tensor_by_name('y_conv:0')
# 测试准确率
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(input_y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
mean_value = 0.0
for i in range(mnist.test.labels.shape[0]):
batch = mnist.test.next_batch(50)
train_accuracy = sess.run(accuracy, feed_dict={input_x: batch[0], input_y: batch[1], keep_prob: 1.0})
mean_value += train_accuracy
print("test accuracy %g" % (mean_value / mnist.test.labels.shape[0]))
# #训练结束后,我们使用mnist.test在测试最后的准确率
# print("test accuracy %g" % sess.run(accuracy, feed_dict={x:mnist.test.images, y_:mnist.test.labels, keep_prob:1.0}))运行结果,
![]()
就是这么简单。
===============================================================================
20190813补充:
今天想讲tensorflow转成onnx模型,发现用上面的固化方法行不通,报错如下,
D:\ProgramData\anaconda3\lib\site-packages\h5py\__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
Traceback (most recent call last):
File "D:\ProgramData\anaconda3\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "D:\ProgramData\anaconda3\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "D:\ProgramData\anaconda3\lib\site-packages\tf2onnx\convert.py", line 161, in
main()
File "D:\ProgramData\anaconda3\lib\site-packages\tf2onnx\convert.py", line 123, in main
args.saved_model, args.inputs, args.outputs, args.signature_def)
File "D:\ProgramData\anaconda3\lib\site-packages\tf2onnx\loader.py", line 103, in from_saved_model
meta_graph_def = tf.saved_model.loader.load(sess, [tf.saved_model.tag_constants.SERVING], model_path)
File "D:\ProgramData\anaconda3\lib\site-packages\tensorflow\python\util\deprecation.py", line 324, in new_func
return func(*args, **kwargs)
File "D:\ProgramData\anaconda3\lib\site-packages\tensorflow\python\saved_model\loader_impl.py", line 269, in load
return loader.load(sess, tags, import_scope, **saver_kwargs)
File "D:\ProgramData\anaconda3\lib\site-packages\tensorflow\python\saved_model\loader_impl.py", line 420, in load
**saver_kwargs)
File "D:\ProgramData\anaconda3\lib\site-packages\tensorflow\python\saved_model\loader_impl.py", line 347, in load_graph
meta_graph_def = self.get_meta_graph_def_from_tags(tags)
File "D:\ProgramData\anaconda3\lib\site-packages\tensorflow\python\saved_model\loader_impl.py", line 323, in get_meta_graph_def_from_tags
" could not be found in SavedModel. To inspect available tag-sets in"
RuntimeError: MetaGraphDef associated with tags 'serve' could not be found in SavedModel. To inspect available tag-sets in the SavedModel, please use the SavedModel CLI: `saved_model_cli`
上面提示说要用 SavedModel 的方式保存模型。
还是以我上面的mnist为例,但是,这次不用tf.train.Saver()的方法保存了,而是直接用SavedModel的方法保存成pb文件,训练的完整源码如下,
# coding: utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
mnist = input_data.read_data_sets('mnist_data', one_hot=True)
#初始化过滤器
def weight_variable(shape):
return tf.Variable(tf.truncated_normal(shape, stddev=0.1))
#初始化偏置,初始化时,所有值是0.1
def bias_variable(shape):
return tf.Variable(tf.constant(0.1, shape=shape))
#卷积运算,strides表示每一维度滑动的步长,一般strides[0]=strides[3]=1
#第四个参数可选"Same"或"VALID",“Same”表示边距使用全0填充
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding="SAME")
#池化运算
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
#创建x占位符,用于临时存放MNIST图片的数据,
# [None, 784]中的None表示不限长度,而784则是一张图片的大小(28×28=784)
x = tf.placeholder(tf.float32, [None, 784], name='input')
#y_存的是实际图像的标签,即对应于每张输入图片实际的值
y_ = tf.placeholder(tf.float32, [None, 10])
#将图片从784维向量重新还原为28×28的矩阵图片,
# 原因参考卷积神经网络模型图,最后一个参数代表深度,
# 因为MNIST是黑白图片,所以深度为1,
# 第一个参数为-1,表示一维的长度不限定,这样就可以灵活设置每个batch的训练的个数了
x_image = tf.reshape(x, [-1, 28, 28, 1])
#第一层卷积
#将过滤器设置成5×5×1的矩阵,
#其中5×5表示过滤器大小,1表示深度,因为MNIST是黑白图片只有一层。所以深度为1
#32表示我们要创建32个大小5×5×1的过滤器,经过卷积后算出32个特征图(每个过滤器得到一个特征图),即输出深度为64
W_conv1 = weight_variable([5, 5, 1, 32])
#有多少个特征图就有多少个偏置
b_conv1 = bias_variable([32])
#使用conv2d函数进行卷积计算,然后再用ReLU作为激活函数
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
#卷积以后再经过池化操作
h_pool1 = max_pool_2x2(h_conv1)
#第二层卷积
#因为经过第一层卷积运算后,输出的深度为32,所以过滤器深度和下一层输出深度也做出改变
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
#全连接层
#经过两层卷积后,图片的大小为7×7(第一层池化后输出为(28/2)×(28/2),
#第二层池化后输出为(14/2)×(14/2)),深度为64,
#我们在这里加入一个有1024个神经元的全连接层,所以权重W的尺寸为[7 * 7 * 64, 1024]
W_fc1 = weight_variable([7 * 7 * 64, 1024])
#偏置的个数和权重的个数一致
b_fc1 = bias_variable([1024])
#这里将第二层池化后的张量(长:7 宽:7 深度:64) 变成向量(跟上一节的Softmax模型的输入一样了)
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
#使用ReLU激活函数
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
#dropout
#为了减少过拟合,我们在输出层之前加入dropout
keep_prob = tf.placeholder(tf.float32, name='keep_prob')
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
#输出层
#全连接层输入的大小为1024,而我们要得到的结果的大小是10(0~9),
# 所以这里权重W的尺寸为[1024, 10]
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
#最后都要经过Softmax函数将输出转化为概率问题
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2, name='output')
#损失函数和损失优化
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv)))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
#测试准确率,跟Softmax回归模型的一样
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# #将训练结果保存,如果不保存我们这次训练结束后的结果也随着程序运行结束而释放了
# savePath = './mnist_conv/'
# saveFile = savePath + 'mnist_conv.ckpt'
# if os.path.exists(savePath) == False:
# os.mkdir(savePath)
# saver = tf.train.Saver()
#开始训练
with tf.Session() as sess:
#初始化所有变量
sess.run(tf.global_variables_initializer())
#训练两万次
for i in range(2000):
#每次获取50张图片数据和对应的标签
batch = mnist.train.next_batch(50)
#每训练100次,我们打印一次训练的准确率
if i % 100 == 0:
train_accuracy =sess.run(accuracy, feed_dict={x:batch[0], y_:batch[1], keep_prob:1.0})
print("step %d, training accuracy %g" % (i, train_accuracy))
#这里是真的训练,将数据传入
sess.run(train_step, feed_dict={x:batch[0], y_:batch[1], keep_prob:0.5})
# print ("end train, start testing...")
# mean_value = 0.0
# for i in range(mnist.test.labels.shape[0]):
# batch = mnist.test.next_batch(50)
# train_accuracy = sess.run(accuracy, feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0})
# mean_value += train_accuracy
# print("test accuracy %g" % (mean_value / mnist.test.labels.shape[0]))
# #训练结束后,我们使用mnist.test在测试最后的准确率
# print("test accuracy %g" % sess.run(accuracy, feed_dict={x:mnist.test.images, y_:mnist.test.labels, keep_prob:1.0}))
# 最后,将会话保存下来
# saver.save(sess, saveFile)
# 用SavedModel的方式保存
tf.compat.v1.saved_model.simple_save(sess,
"./saved_model",
inputs={"input": x, 'keep_prob':keep_prob},
outputs={"output": y_conv})
运行结果,
在当前目录下生产一个saved_model文件夹,文件夹下有如下文件,

接着,模型训练完了肯定得用起来啊,调用的完整源码如下,
# coding: utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
import numpy as np
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
mnist = input_data.read_data_sets('mnist_data', one_hot=True)
with tf.Session() as sess:
tf.compat.v1.saved_model.loader.load (sess, ["serve"], "./saved_model")
x = sess.graph.get_tensor_by_name('input:0')
y = sess.graph.get_tensor_by_name('output:0')
keep_prob = sess.graph.get_tensor_by_name('keep_prob:0')
for i in range(mnist.test.labels.shape[0]):
batch = mnist.test.next_batch(1)
print("wf======== batch :", np.argmax(batch[1], 1))
train_accuracy = sess.run(y, feed_dict={x: batch[0], keep_prob:1})
print("wf======== accuracy :", np.argmax(train_accuracy, 1))
if i == 10:
break
运行结果,
Use standard file APIs to check for files with this prefix.
wf======== batch : [6]
wf======== accuracy : [6]
wf======== batch : [7]
wf======== accuracy : [7]
wf======== batch : [3]
wf======== accuracy : [3]
wf======== batch : [2]
wf======== accuracy : [2]
wf======== batch : [9]
wf======== accuracy : [9]
wf======== batch : [7]
wf======== accuracy : [7]
wf======== batch : [1]
wf======== accuracy : [1]
wf======== batch : [0]
wf======== accuracy : [0]
wf======== batch : [6]
wf======== accuracy : [0]
wf======== batch : [3]
wf======== accuracy : [3]
wf======== batch : [6]
wf======== accuracy : [6]
如果您感觉本篇博客对您有帮助,请打开支付宝,领个红包支持一下,祝您扫到99元,谢谢~~
