人工智能的45篇论文
1. wide and deep network
—wide模型:一种浅层模型。它通过大量的单层网络节点,实现对训练样本的高度拟合性。它的缺点是泛化能力很差。
ϕ k ( x ) = ∏ i = 1 d x i c k i c k i ∈ { 0 , 1 } \phi_{k}(\mathbf{x})=\prod_{i=1}^{d} x_{i}^{c_{k i}} \quad c_{k i} \in\{0,1\} ϕk(x)=∏i=1dxickicki∈{0,1}
—deep模型:一种深层模型。它通过多层的非线性变化,使模型具有很好的泛化性。它的缺点是拟合度欠缺。
a ( l + 1 ) = f ( W ( l ) a ( l ) + b ( l ) ) a^{(l+1)}=f\left(W^{(l)} a^{(l)}+b^{(l)}\right) a(l+1)=f(W(l)a(l)+b(l))
将二者结合起来——用联合训练方法共享反向传播的损失值来进行训练—可以使两个模型综合优点,得到最好的结果。**

P ( Y = 1 ∣ x ) = σ ( w w i d e T [ x , ϕ ( x ) ] + w d e e p T a ( l f ) + b ) P(Y=1 | \mathbf{x})=\sigma\left(\mathbf{w}_{w i d e}^{T}[\mathbf{x}, \phi(\mathbf{x})]+\mathbf{w}_{d e e p}^{T} a^{\left(l_{f}\right)}+b\right) P(Y=1∣x)=σ(wwideT[x,ϕ(x)]+wdeepTa(lf)+b)

2. Adam
Adam,一种有效的随机优化方法,只需要一阶内存很少的内存需求。
该方法根据梯度的第一和第二矩的估计来计算不同参数的各个自适应学习速率; Adam的名称来源于自适应矩估计。
Adam 算法和传统的随机梯度下降不同。随机梯度下降保持单一的学习率(即 alpha)更新所有的权重,学习率在训练过程中并不会改变。而 Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
适应性梯度算法(AdaGrad)为每一个参数保留一个学习率以提升在稀疏梯度(即自然语言和计算机视觉问题)上的性能。
均方根传播(RMSProp)基于权重梯度最近量级的均值为每一个参数适应性地保留学习率。这意味着算法在非稳态和在线问题上有很有优秀的性能。
alpha:同样也称为学习率或步长因子,它控制了权重的更新比率(如 0.001)。较大的值(如 0.3)在学习率更新前会有更快的初始学习,而较小的值(如 1.0E-5)会令训练收敛到更好的性能。
beta1:一阶矩估计的指数衰减率(如 0.9)。
beta2:二阶矩估计的指数衰减率(如 0.999)。该超参数在稀疏梯度(如在 NLP 或计算机视觉任务中)中应该设置为接近 1 的数。
epsilon:该参数是非常小的数,其为了防止在实现中除以零(如 10E-8)。
另外,学习率衰减同样可以应用到 Adam 中。原论文使用衰减率 alpha = alpha/sqrt(t) 在 logistic 回归每个 epoch(t) 中都得到更新。
Adam 论文建议的参数设定:
测试机器学习问题比较好的默认参数设定为:alpha=0.001、beta1=0.9、beta2=0.999 和 epsilon=10E−8。
g1, … , gT是后续时间步长的梯度

首先,计算优化的梯度大小
g t ← ∇ θ f t ( θ t − 1 ) g_{t} \leftarrow \nabla_{\theta} f_{t}\left(\theta_{t-1}\right) gt←∇θft(θt−1)
然后计算一阶矩,二阶矩,并且用滑动平均方法更新
m 0 ← 0 m_{0} \leftarrow 0 m0←0
v 0 ← 0 v_{0} \leftarrow 0 v0←0
m t ← β 1 ⋅ m t − 1 + ( 1 − β 1 ) ⋅ g t m_{t} \leftarrow \beta_{1} \cdot m_{t-1}+\left(1-\beta_{1}\right) \cdot g_{t} mt←β1⋅mt−1+(1−β1)⋅gt
v t ← β 2 ⋅ v t − 1 + ( 1 − β 2 ) ⋅ g t 2 v_{t} \leftarrow \beta_{2} \cdot v_{t-1}+\left(1-\beta_{2}\right) \cdot g_{t}^{2} vt←β2⋅vt−1+(1−β2)⋅gt2
由于 m t , v t m_t, v_t mt,vt在迭代初期偏向0,( β 1 , β 2 \beta_1, \beta_2 β1,β2 比较大),需要进行修正
m ^ t ← m t / ( 1 − β 1 t ) \widehat{m}_{t} \leftarrow m_{t} /\left(1-\beta_{1}^{t}\right) m t←mt/(1−β1t)
v ^ t ← v t / ( 1 − β 2 t ) \widehat{v}_{t} \leftarrow v_{t} /\left(1-\beta_{2}^{t}\right) v t←vt/(1−β2t)
最后才是更新参数 θ \theta θ
θ t ← θ t − 1 − α ⋅ m ^ t / ( v ⃗ t + ϵ ) \theta_{t} \leftarrow \theta_{t-1}-\alpha \cdot \widehat{m}_{t} /\left(\sqrt{\vec{v}_{t}}+\epsilon\right) θt←θt−1−α⋅m t/(vt+ϵ)
3. Targeted Dropout
3.1 Dropout
对于全连接层,输入 X \boldsymbol{X} X,权重矩阵 W \boldsymbol{W} W,输出 Y \boldsymbol{Y} Y, M i , o ∼ \mathbf{M}_{i, o} \sim Mi,o∼ Bernoulli ( α ) (\alpha) (α),定义:
单元dropout (Unit dropout):
Y = ( X ⊙ M ) W \boldsymbol{Y}=(\boldsymbol{X} \odot \mathbf{M}) \mathbf{W} Y=(X⊙M)W
单元dropout在每个训练步骤中随机把神经元丢失,减少单元间的依赖关系以及防止过拟合。
权重dropout:
Y = X ( W ⊙ M ) \boldsymbol{Y}=\boldsymbol{X}(\mathbf{W} \odot \mathbf{M}) Y=X(W⊙M)
权重dropout在训练阶段随机把权重矩阵的值丢失,减少层与层之间的联接。
3.2 基于大小的裁剪
把 top-k 大的权重当做是重要的。
Unit pruning
在 L2 范数评价指标考虑权重矩阵。
W ( θ ) = { argmax − k 1 ≤ o ≤ N c o l ( W ) ∥ w o ∥ 2 ∣ W ∈ θ } \mathcal{W}(\boldsymbol{\theta})=\left\{\underset{1 \leq o \leq N_{\mathrm{col}}(\mathbf{W})}{\operatorname{argmax}-\mathrm{k}}\left\|\boldsymbol{w}_{o}\right\|_{2} | \mathbf{W} \in \boldsymbol{\theta}\right\} W(θ)={1≤o≤Ncol(W)argmax−k∥wo∥2∣W∈θ}
Weight pruning
在L1 norm 准则考虑权重矩阵。
W ( θ ) = { argmax − k 1 ≤ i ≤ N row ( W ) ∣ W i o ∣ ∣ 1 ≤ o ≤ N c o l ( W ) , W ∈ θ } \mathcal{W}(\boldsymbol{\theta})=\left\{\underset{1 \leq i \leq N_{\text {row }}(\mathbf{W})}{\operatorname{argmax}-\mathrm{k}}\left|\mathbf{W}_{i o}\right| | 1 \leq o \leq N_{\mathrm{col}}(\mathbf{W}), \mathbf{W} \in \boldsymbol{\theta}\right\} W(θ)={1≤i≤Nrow (W)argmax−k∣Wio∣∣1≤o≤Ncol(W),W∈θ}
实现:
def targeted_dropout(x, drop_rate, targ_rate, is_training):
# x is a weight with shape: [in, out]
# drop_rate is the dropout rate
# targ_rate is the percentage of elements you intend to prune
norms = tf.abs(x)
k = tf.to_int32(tf.to_float(tf.shape(x)[0]) * targ_rate)
transpose_norms = tf.transpose(norms) # unfortunately this transpose is necessary since top_k only acts on the last dimension
vals, _ = -tf.nn.top_k(-transpose_norms, k=k)
threshold = val[-1]
targ_mask = tf.to_float(norms >= threshold)
drop_mask = tf.to_float(tf.random.uniform(targ_mask.shape) < drop_rate)
if not is_training:
return targ_mask * x
return targ_mask * drop_mask * x
4. Xception
具有深度可分离卷积的深度学习方法。
Xception 是在Inception的基础上修改的。


假设:在卷积神经网络的特征图中,跨通道相关性和空间相关性的映射可以完全解耦。
因为这个假设是Inception架构背后假设的一个更强大的版本,所以我们将我们提出的架构Xception命名为“Extreme Inception”。

Xception:

“extreme” version of Inception Module:具体操作过程可以参考上图。
第一步:普通11卷积。
第二步:对11卷积结果的每个channel,分别进行3*3卷积操作,并将结果concat。
Depthwise Separable Convolution的结构在MobileNet V1。
第一步:depthwise卷积,对输入的每个channel,分别进行33卷积操作,并将结果concat。
第二步:pointwise卷积,对depthwise卷积中的concat结果,进行11卷积操作。
Depthwise Separable Convolution 与 “extreme” version of Inception Module的区别:
操作循序不一致:Depthwise Separable Convolution先进行33卷积,再进行11卷积;Inception先进行11卷积,再进行33卷积。
是否使用非线性激活操作:Inception中,两次卷积后都使用Relu;Depthwise Separable Convolution中,在depthwise卷积后一般不添加Relu。在本论文中,通过试验进行验证。具体原因在论文MobileNet V2中有解释。
5. Resnet
残差学习网络。
更深的神经网络往往更难以训练,我们在此提出一个残差学习的框架,以减轻网络的训练负担,这是个比以往的网络要深的多的网络。我们明确地将层作为输入学习残差函数,而不是学习未知的函数。我们提供了非常全面的实验数据来证明,残差网络更容易被优化,并且可以在深度增加的情况下让精度也增加。在ImageNet的数据集上我们评测了一个深度152层(是VGG的8倍)的残差网络,但依旧拥有比VGG更低的复杂度。残差网络整体达成了3.57%的错误率,这个结果获得了ILSVRC2015的分类任务第一名,我们还用CIFAR-10数据集分析了100层和1000层的网络。
梯度消失/爆炸问题,它从一开始就阻碍了收敛,然而梯度消失/爆炸的问题,很大程度上可以通过标准的初始化和正则化层来基本解决,确保几十层的网络能够收敛(用SGD+反向传播)。
然而当开始考虑更深层的网络的收敛问题时,退化问题就暴露了:随着神经网络深度的增加,精确度开始饱和(这是不足为奇的),然后会迅速的变差。出人意料的,这样一种退化,并不是过拟合导致的,并且增加更多的层匹配深度模型,会导致更大的训练误差。


6. 空洞卷积
dilated convolution 多了一个 hyper-parameter 称之为 dilation rate 指的是kernel的间隔数量(e.g. 正常的 convolution 是 dilatation rate 1)。
感受野计算:
令 n为空洞率;k为卷积核大小。
感受野为 ( n ∗ ( k + 1 ) − 1 ) ∗ ( n ∗ ( k + 1 ) − 1 ) (n*(k+1) - 1)*(n*(k+1) - 1) (n∗(k+1)−1)∗(n∗(k+1)−1).

比如,图(c)n = 4, k = 3;视野为 15*15。
7.DenseNet
与Resnet相比,DenseNet 把前面所有层都concat给后面的节点。比如有 L 层, 普通的网络就 L 个连接,但是 DenseNet 有 L ( L + 1 ) 2 \frac{L(L+1)}{2} 2L(L+1)个连接。
第 l l l 层 接受到所有之前层的特征图 X 0 , … , X ℓ − 1 \mathbf{X}_{0}, \dots, \mathbf{X}_{\ell}-1 X0,…,Xℓ−1。
x ℓ = H ℓ ( [ x 0 , x 1 , … , x ℓ − 1 ] ) \mathbf{x}_{\ell}=H_{\ell}\left(\left[\mathbf{x}_{0}, \mathbf{x}_{1}, \ldots, \mathbf{x}_{\ell-1}\right]\right) xℓ=Hℓ([x0,x1,…,xℓ−1])

Bottleneck
在 33 卷积之前加一个 11 卷积,把k个特征图扩大到4k个。
i.e., to the BN-ReLU-Conv(11)-BN-ReLU-Conv(3*3) version of H l H_l Hl, as DenseNet-B.
Compression
在转换层减少特征图。
8. EfficentNet
经过简单的固定比例缩放就可以实现很好的网络的深度,宽度,分辨率的平衡从而达到更好的accuracy-efficiency tradeoff。基于这个观察,文章提出compound scaling method的缩放方法,同时采用MNAS的神经架构搜索方法搜索到基础骨架,然后与缩放结合,实现又好有快的EfficientNet。
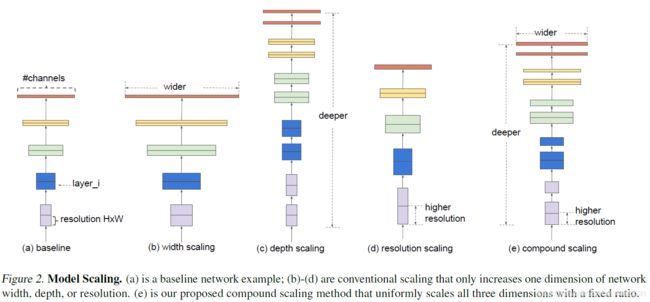
复合模型压缩


与常规的ConvNet设计主要关注于寻找最佳层架构不同,模型缩放尝试在不更改基线网络中预定义的的情况下扩展网络长度(Li)、宽度(Ci)和/或分辨率(Hi, Wi)。通过修正Fi,模型缩放简化了新资源约束的设计问题,但对于每一层来说,探索不同的Li、Ci、Hi、Wi仍然是一个很大的设计空间。为了进一步缩小设计空间,我们限制了所有层必须以恒定的比例均匀缩放。
9. Grad-CAM模型
CNN 网络可视化技巧:Gradient-weighted Class Activation Mapping (Grad-CAM),加权梯度类激活映射。




和CAM的另一个区别是,Grad-CAM对最终的加权和加了一个ReLU,加这么一层ReLU的原因在于我们只关心对类别c有正影响的那些像素点,如果不加ReLU层,最终可能会带入一些属于其它类别的像素,从而影响解释的效果。
参考:
- 微信公众号;
- 深度学习最常用的学习算法:Adam优化算法;
- Targeted Dropout;
- Xception deep learning with depthwise separable convolutions;
- zhihu 精读深度学习论文(10) Xception;
- Deep Residual Learning for Image Recognition;
- 译 Deep Residual Learning for Image Recognition (ResNet);
- Multi Scale Context Aggregation By Dilated Convolutions;
- 如何理解空洞卷积(dilated convolution)?;
- Densely Connected Convolutional Networks;
- EfficentNet Rethinking Model Scaling for Convolutional Neural Networks;
- Grad CAM Visual Explanations from Deep Networks via Gradient-based Localization;
- 凭什么相信你,我的CNN模型?(篇一:CAM和Grad-CAM)