本文首发于“合天智汇”微信公众号,作者:Kale
前言
上次分享了javascript语义分析,并且简单介绍了新型xss扫描器的一些想法,如何在不进行大量fuzz的情况下又能准确的检测出xss漏洞,这其中我们又可以尽量的避免触发waf的xss防护功能!
关联文章:XSS语义分析的阶段性总结(一)
首先先接着上文介绍一下html语义分析的方法。
扫描思路
HTML语义分析
如果把html语义分析看为对html结构的解析与识别,在python中我们可以使用HTMLParser,对,又是python帮我解决了难题。在XSStrike里面同样使用了自定义的HTMLParser进行漏洞的辅助识别。
我们可以通过继承HTMLParser并重载其方法来实现我们需要的功能
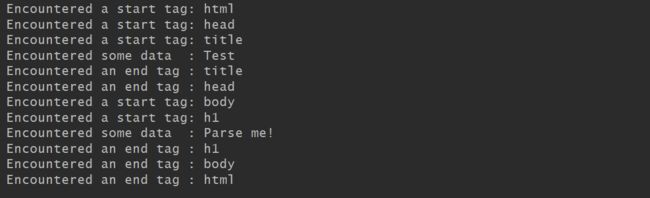
下面是简单的 HTML 解析器的一个基本示例,使用 HTMLParser 类,当遇到开始标记、结束标记以及数据的时候将内容打印出来
from html.parser import HTMLParser class MyHTMLParser(HTMLParser): def handle_starttag(self, tag, attrs): print("Encountered a start tag:", tag) def handle_endtag(self, tag): print("Encountered an end tag :", tag) def handle_data(self, data): print("Encountered some data :", data) parser = MyHTMLParser() parser.feed('Test ' 'Parse me!
')
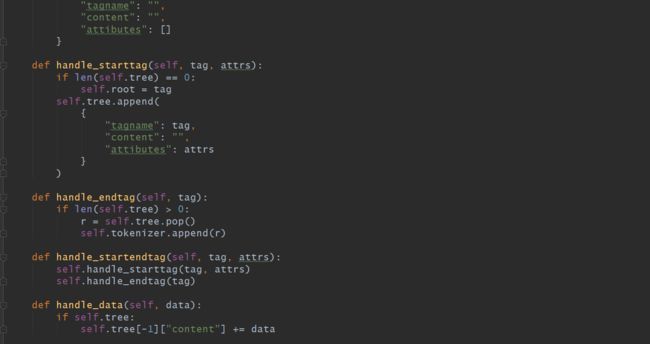
我们需要定义一个我们自己的HTML解析器来处理我们的标签,标识出来script标签,html注释,html标签,属性,css等等
部分代码如下
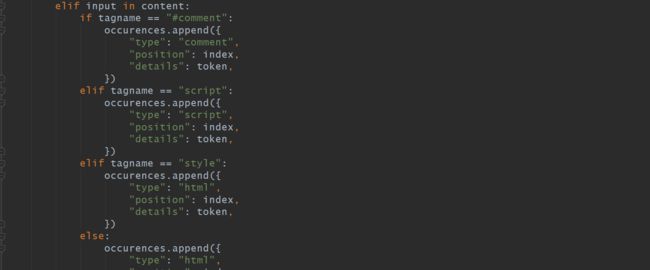
寻找反射点的思路和js的类似,通过遍历标签来来解析html结构,tagname代表标签名,attibutes代表属性,content代表数据内容,#comment代表注释,每个标签被封装为字典形式的列表元素
使用以下的demo
 "?q=1&w=2&e=3&r=4&t=5">testkkkffffbb "color:flag{111222}" value2="flag{111222}" aflag{111222}="aaa"/>
处理后的效果

处理完html标签,接下该寻找sink输出点在html的上下文。思路跟js的寻找思路是相同的
通过遍历列表内容来找到我们的input,部分代码如下:
最后会给出输出点上下文的一些细节信息,如是否是html标签等等

然后根据不同的上下文给出我们的payload,使用html语法树有很多好处,比如可以准确判断回显的位置
探究发包
X3Scan的扫描思路参考了一些xray的扫描思路,比如不发送一些产生危害的payload,只根据回显的上下文发送一些flag测试一些关键字符是否被转义和过滤,如<>,".',()等,如果没有过滤最后给出建议payload,如:confirm()
首先对于无法使用html和js解析的回显,如jsonp和json格式的相应包,我们使用如下的发包顺序:
随机flag ---》判断回显 ----》解析找不到回显 ---》发送<随机flag> ---》判断响应包中字符是否转义---》给出payload
最后给出content-type是包含text/html,然后继续测试,实际测试中当content-type为空时,也可能存在xss漏洞,因此应该对两种情况都进行一下判断。
if 'html' in (resp_headers.get("content-type","").lower()) or resp_headers.get("content-type")==None:
对于html标签内的内容
xxxxx
扫描器会依次发送0xb9d8c,
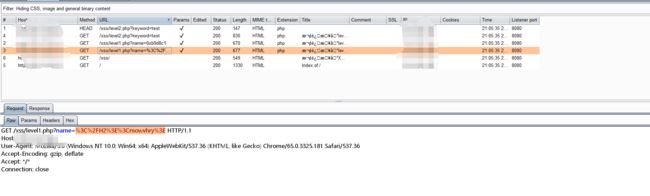
对于标签属性
demo:https://brutelogic.com.br/xss.php?b3=
扫描器会依次发送0xb78123,'psafq=','>,"psafq=",">,当确认引号和尖括号没有被过滤时,最终给出">,"OnMoUsEoVeR=confirm()//。
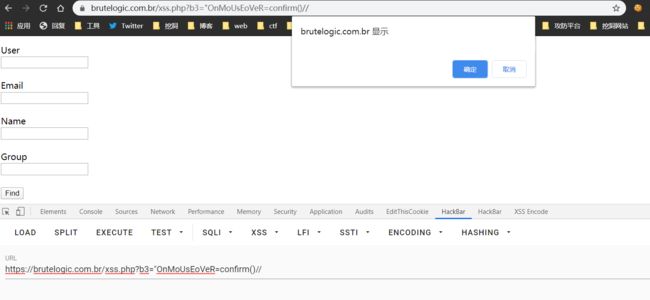
对于html注释
``
扫描器会依次发送0xfda748,-->,--!>,当确定-->或--!>没有过滤时,给出payload,-->
对于script标签的回显
扫描器会依次发送0x829a5c,-829a5c-,,当最后确认未被过滤时,最终给出payload,
另外一种情况就是回显到script标签的注释里面
使用以下demo
扫描器会依次发出0x829a5c,-829a5c-,,\n;rmhwe;//,最后给出payload,,/n;prompt(1);//。
对于块注释,扫描器会依次发出,0xc13f,*/0xc13f;/*,最后给出payload,*/prompt(1);/*
通过上面的分析,我们可以发现使用html语法树有很多好处,比如通过发送一个随机payload,例如:wrqweew这个标签,便可以确定payload是否执行成功了。
对于回显在js的情况,发送测试payload后,通过js语法树解析确定Identifier和Literal这两个类型中是否包含,如果payload是Identifier类型,就可以直接判断存在xss,最后给出payload,confirm();//。如果payload是Literal类型,再通过单双引号来测试是否可以闭合。
另外,还有一些比较精致的技巧,比如对payload的随机大小写,由于html对大小写是不敏感的,但是一些waf由于设计缺陷能会被绕过。
大致流程
扫描器大致流程:
发送随机字符--》确认参数回显---》通过html/js解析确认回显位置--》根据回显的上下文发送不同的payload进行测试--》使用html,js语法树解析是否多出来标签,属性,js语句等来确定是否执行成功
成果展示
由于一直处于开发阶段,并没进行大规模测试,但是偶尔也会有个小惊喜,某次调bug的时候发现京东某站的xss