项目实践 | 超强EfficientDet原理讲解与目标检测项目实践
点击最上方蓝色【AI算法修炼营】关注公众号
回复【Det】即可获得完整的项目代码以及文档说明。
目录
1、EfficientDet简介
2、EfficientDet原理与PyTorch实现
2.1、EfficientNet模型
2.1.1、EfficientNet简介
2.1.2、EfficientNet网络模型结构(附PyTorch代码)
2.2、BiFPN模块(附PyTorch代码)
2.3、EfficientDet结构
2.4、模型复合扩张
2.5、EfficientDet结构总结
2.6、训练过程与测试结果
1、EfficientDet简介
在简介部分,作者提出了 “鱼与熊掌俺能兼得乎?”,要知道在此之前,实际目标检测算法家族已经提出了很多很多经典的算法,有two-stage方法的,主要是早期的一些算法,如Fast R-CNN、Faster R-CNN,一般检测精度较高但速度慢,为了加快速度,后来逐步发展为one-stage,从RoI的提取到识别检测全部融合在一个框架下,实现 end to end,加快检测速度,但一般是以牺牲精度换速度的。
因此在FPN及EfficientNet 的影响下,作者分别基于此在 FPN 基础上进行优化提出BiFPN以及全方位的模型缩放探索。
作者提出两个方法:
BiFPN: 这个毋庸置疑,肯定是从 FPN 发展过来的,至于 Bi 就是双向,原始的FPN实现的自顶向下(top-down)融合,所谓的BiFPN就是两条路线既有top-down也有down-top。
在融合过程中,之前的一些模型方法没有考虑到各级特征对融合后特征的g共享度问题,即之前模型认为各级特征的贡献度相同,而本文作者认为它们的分辨率不同,其对融合后特征的贡献度不同,因此在特征融合阶段引入了weight。
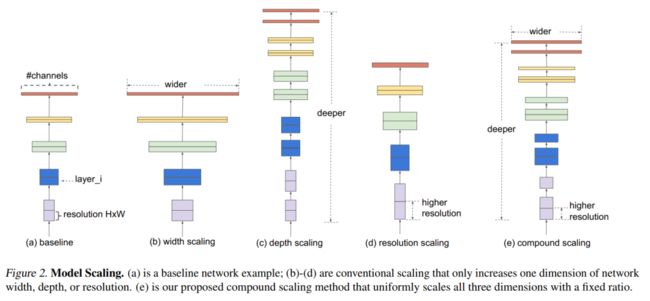
复合缩放方法(compound scaling method):这个主要灵感来自于 EfficientNet,即在基线网络上同时对多个维度进行缩放(一般都是放大),这里的维度体现在主干网络、特征网络、以及分类/回归网络全流程的整体架构上整体网络由主干网络、特征网络以及分类/回归网络组成,可以缩放的维度比 EfficientNet 多得多,所以用网络搜索方式不合适了,作者提出一些启发式方法,可以参照论文的 Table 1。
该方法可以统一地对所有主干网、特征网络和预测网络的分辨率、深度和宽度进行缩放。基于这些优化,开发了一个新的对象检测器家族,称为EfficientDet。
2、EfficientDet原理与PyTorch实现
2.1、EfficientNet模型

2.1.1、EfficientNet简介
模型的基础网络架构是通过使用神经网络架构搜索(neural architecture search)设计得到。为了研究系统的模型缩放,谷歌大脑的研究人员针对EfficientNets的基础网络模型提出了一种全新的模型缩放方法,该方法使用简单而高效的复合系数来权衡网络深度、宽度和输入图片分辨率。
通过放大EfficientNets基础模型,获得了一系列EfficientNets模型。该系列模型在效率和准确性上战胜了之前所有的卷积神经网络模型。尤其是EfficientNet-B7在ImageNet数据集上得到了top-1准确率84.4%和top-5准确率97.1%的结果。且它和当时准确率最高的其它模型对比,大小缩小了8.4倍,效率提高了6.1倍。且通过迁移学习,EfficientNets在多个知名数据集上均达到了当时最先进的水平。
2.1.2、EfficientNet网络模型结构
1)移动翻转瓶颈卷积
移动翻转瓶颈卷积也是通过神经网络架构搜索得到的,该模块结构与深度分离卷积(depthwise separable convolution)相似,该移动翻转瓶颈卷积首先对输入进行1x1的逐点卷积并根据扩展比例(expand ratio)改变输出通道维度(如扩展比例为3时,会将通道维度提升3倍。但如果扩展比例为1,则直接省略该1x1的逐点卷积和其之后批归一化和激活函数)。
接着进行kxk的深度卷积(depthwise convolution)。如果要引入压缩与激发操作,该操作会在深度卷积后进行。再以1x1的逐点卷积结尾恢复原通道维度。
最后进行连接失活(drop connect)和输入的跳越连接(skip connection),这一做法源于论文《Deep networks with stochastic depth》,它让模型具有了随机的深度,剪短了模型训练所需的时间,提升了模型性能(注意,在EfficientNets中,只有当相同的移动翻转瓶颈卷积重复出现时,才会进行连接失活和输入的跳越连接,且还会将其中的深度卷积步长变为1),连接失活是一种类似于随机失活(dropout)的操作,并且在模块的开始和结束加入了恒等跳越。注意该模块中的每一个卷积操作后都会进行批归一化,激活函数使用的是Swish激活函数。总流程如图1所示,是扩展比例为6,深度卷积大小为5x5,步长为2x2(MBConv6,k5x5,stride2x2)的移动翻转瓶颈卷积模块。
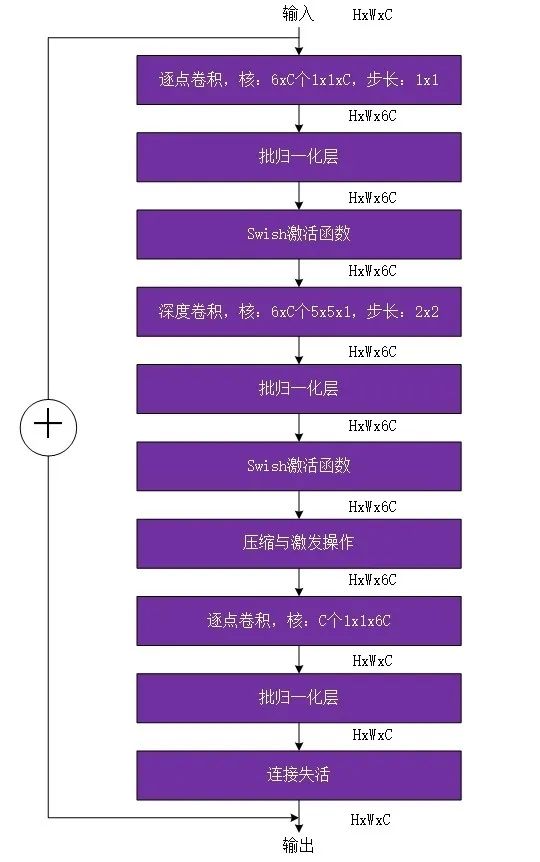
图 MBConv6,k5x5,stride2x2结构示意图
PyTorch实现MBConv模块:
class MBConvBlock(nn.Module):
"""
Mobile Inverted Residual Bottleneck 模块
Args:
block_args (namedtuple): 模型模块参数
global_params (namedtuple): 全局参数
Attributes:
has_se (bool): 是否存在SENet
"""
def __init__(self, block_args, global_params):
super().__init__()
self._block_args = block_args # EfficientNet全局参数
self._bn_mom = 1 - global_params.batch_norm_momentum # 训练时的动量参数
self._bn_eps = global_params.batch_norm_epsilon # BN的参数
self.has_se = (self._block_args.se_ratio is not None) and (0 < self._block_args.se_ratio <= 1)
self.id_skip = block_args.id_skip # 连接失活和跳跃连接
# 恒等宽高卷积操作
Conv2d = get_same_padding_conv2d(image_size=global_params.image_size)
# 通道拓展操作
inp = self._block_args.input_filters # number of input channels
oup = self._block_args.input_filters * self._block_args.expand_ratio # number of output channels
if self._block_args.expand_ratio != 1:
self._expand_conv = Conv2d(in_channels=inp, out_channels=oup, kernel_size=1, bias=False)
self._bn0 = nn.BatchNorm2d(num_features=oup, momentum=self._bn_mom, eps=self._bn_eps)
# 深度卷积操作
k = self._block_args.kernel_size
s = self._block_args.stride
# groups用于设置depthwise卷积(一个卷积核负责一个通道)
self._depthwise_conv = Conv2d(in_channels=oup, out_channels=oup, groups=oup, kernel_size=k, stride=s, bias=False)
self._bn1 = nn.BatchNorm2d(num_features=oup, momentum=self._bn_mom, eps=self._bn_eps)
# SENet模块
if self.has_se:
num_squeezed_channels = max(1, int(self._block_args.input_filters * self._block_args.se_ratio))
self._se_reduce = Conv2d(in_channels=oup, out_channels=num_squeezed_channels, kernel_size=1)
self._se_expand = Conv2d(in_channels=num_squeezed_channels, out_channels=oup, kernel_size=1)
# 最终输出模块
final_oup = self._block_args.output_filters
self._project_conv = Conv2d(in_channels=oup, out_channels=final_oup, kernel_size=1, bias=False)
self._bn2 = nn.BatchNorm2d(num_features=final_oup, momentum=self._bn_mom, eps=self._bn_eps)
self._swish = MemoryEfficientSwish()
def forward(self, inputs, drop_connect_rate=None):
"""
MBConv模块的流程:
0、输入
1、深度卷积操作
2、批归一化操作
3、Swish激活函数操作
4、深度卷积操作
5、批归一化操作
6、Swish激活函数操作
7、SENet操作
8、Depthwise Convolution操作
9、批归一化操作
10、连接失活和跳越连接操作
11、输出
"""
# 0、输入
x = inputs
# 1+2+3、深度卷积+批归一化+Swish操作
if self._block_args.expand_ratio != 1:
x = self._swish(self._bn0(self._expand_conv(inputs)))
# 4+5+6、Depthwise Convolution+批归一化+Swish操作
x = self._swish(self._bn1(self._depthwise_conv(x)))
# 7、SENet操作
if self.has_se:
x_squeezed = F.adaptive_avg_pool2d(x, 1)
x_squeezed = self._se_expand(self._swish(self._se_reduce(x_squeezed)))
x = torch.sigmoid(x_squeezed) * x
# 8+9、批归一化+Depthwise Convolution
x = self._bn2(self._project_conv(x))
# 10、连接失活和跳越连接操作
input_filters, output_filters = self._block_args.input_filters, self._block_args.output_filters
if self.id_skip and self._block_args.stride == 1 and input_filters == output_filters:
if drop_connect_rate:
x = drop_connect(x, p=drop_connect_rate, training=self.training) # 连接失活
x = x + inputs # 跳越连接操作
# 11、输出
return x
2)EfficientNet-B0结构说明
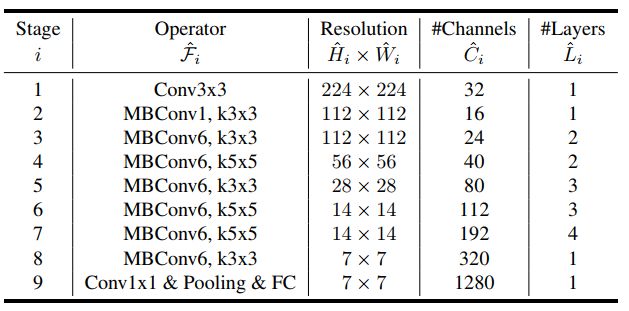
EfficientNet-B0结构由16个移动翻转瓶颈卷积模块,2个卷积层,1个全局平均池化层和1个分类层构成。其结构如图所示,图中不同的颜色代表了不同的阶段。
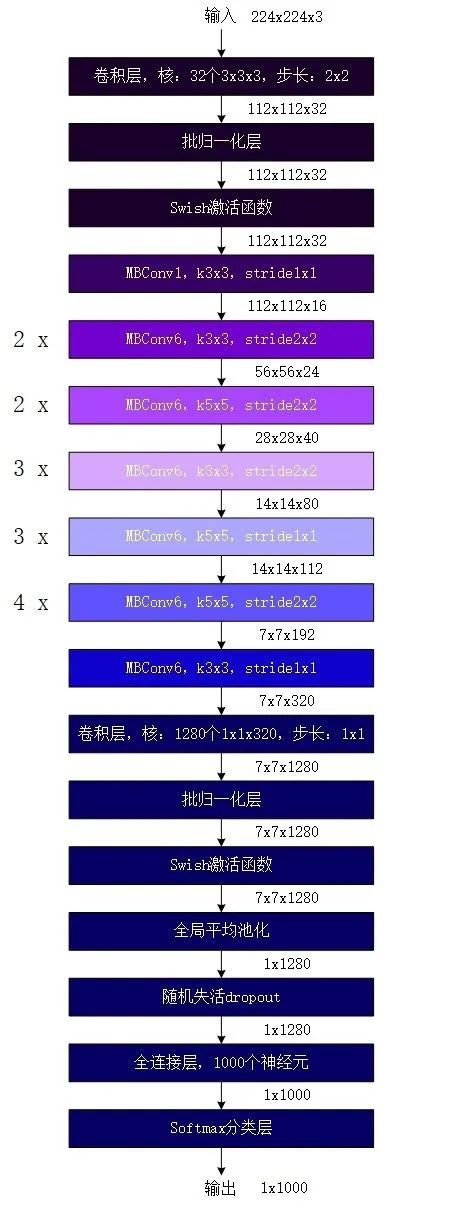
图 EfficientNet-B0结构图
第一阶段:对输入的224x224x3的图像按顺序进行以下操作得到第一阶段的结果:
1) 卷积(卷积核为32核3×3×3,步长为2×2,填充为“same”即输出的宽和高缩小一半),该卷积运算的输出是一个维度为(112×112×32)的特征图。因该层不含偏置项,故该层需要训练学习的参数共计864(32x3x3x3)个。
2) 批归一化层(Batch Normalization,BN),该层输入为(112×112×32)的特征图,故该层含参数总数为128个(32x4),其中需要训练学习的参数为64个。
3) Swish激活函数
第一阶段,总计参数128+864=992个,需要训练学习的参数928个。
第二阶段:对前一阶段输出的112x112x32的特征图进行移动翻转瓶颈卷积
一次移动翻转瓶颈卷积(扩张比例为1,深度卷积核大小为3x3,核步长为1x1,包含压缩与激发操作,无连接失活和连接跳越),并输出第二阶段的结果:
1) 由于扩张比例为1,故跳过一开始的逐点卷积,直接进行深度卷积(卷积核为32核3×3×3,步长为1×1,填充为“same”即输出的宽和高不变)。深度卷积输出是一个维度为(112×112×32)的特征图。因该层不含偏置项,故该层需要训练学习的参数共计288(32x3x3x1)个。
2) 批归一化层(Batch Normalization,BN),该层输入为(112×112×32)的特征图,故该层含参数总数为128个(32x4),其中需要训练学习的参数为64个。
3) Swish激活函数。
4) 全局平均池化层(global average pooling),该层在通道维度方向上进行全局平均池化,输出为(1x1x32)的特征图。
5) 卷积(压缩与激发模块中的第一个卷积,卷积核为8核1x1x32,步长为1×1,填充为“same”即输出的宽和高不变),该卷积运算的输出是一个维度为(1×1×8)的特征图。因该层包含偏置项,故该层需要训练学习的参数共计264(8x1x1x32+8)个。
6) Swish激活函数。
7) 卷积(压缩与激发模块中的第二个卷积,卷积核为32核1x1x8,步长为1×1,填充为“same”即输出的宽和高不变),该卷积运算的的输出是一个维度为(1×1×32)的特征图。因该层包含偏置项,故该层需要训练学习的参数共计288(32x1x1x8+32)个。
8) Sigmoid激活函数
9) 与步骤3)的结果相乘,得到112x112x32的特征图。
10) 逐点卷积(卷积核为16核1×1×32,步长为1×1,填充为“same”即输出的宽和高不变)该卷积运算的输出是一个维度为(112×112×16)的特征图。因该层不含偏置项,故该层需要训练学习的参数共计512(16x1x1x32)个。
11) 批归一化层(Batch Normalization,BN),该层输入为(112×112×16)的特征图,故该层含参数总数为64个(16x4),其中需要训练学习的参数为32个。
第二阶段,总计参数288+128+264+288+512+64=1544个,需要训练学习的参数1448个。
第三阶段:对前一阶段输出的112x112x16的特征图进行两次移动翻转瓶颈卷积
第一个(扩张比例为6,深度卷积核大小为3x3,核步长为2x2,包含压缩与激发操作,无连接失活核连接跳越);
第二个(扩张比例为6,深度卷积核大小为3x3,核步长为1x1,包含压缩与激发操作,有连接失活和连接跳越),并输出第二阶段的结果;
第三阶段,总计参数17770个,需要训练学习的参数16705个。
第四阶段:对前一阶段输出的56x56x24的特征图进行两次移动翻转瓶颈卷积
第一个(扩张比例为6,深度卷积核大小为5x5,核步长为2x2,包含压缩与激发操作,无连接失活核连接跳越);
第二个(扩张比例为6,深度卷积核大小为5x5,核步长为1x1,包含压缩与激发操作,有连接失活和连接跳越);
输出是一个28x28x40的特征图。总计参数48336个,需要训练学习的参数46640个。
第五阶段:对前一阶段输出的28x28x40的特征图进行三次移动翻转瓶颈卷积
第一个(扩张比例为6,深度卷积核大小为3x3,核步长为2x2,包含压缩与激发操作,无连接失活核连接跳越);
第二个(扩张比例为6,深度卷积核大小为3x3,核步长为1x1,包含压缩与激发操作,有连接失活核连接跳越);
第三个(扩张比例为6,深度卷积核大小为3x3,核步长为1x1,包含压缩与激发操作,有连接失活核连接跳越);
输出是一个14x14x80的特征图。总计参数248210个,需要训练学习的参数242930个。
第六阶段:对前一阶段输出的14x14x80的特征图进行三次移动翻转瓶颈卷积
第一个(扩张比例为6,深度卷积核大小为5x5,核步长为1x1,包含压缩与激发操作,无连接失活核连接跳越);
第二个(扩张比例为6,深度卷积核大小为5x5,核步长为1x1,包含压缩与激发操作,有连接失活核连接跳越);
第三个(扩张比例为6,深度卷积核大小为5x5,核步长为1x1,包含压缩与激发操作,有连接失活核连接跳越);
输出是一个14x14x112的特征图。总计参数551116个,需要训练学习的参数543148个。
第七阶段:对前一阶段输出的14x14x112的特征图进行四次移动翻转瓶颈卷积
第一个(扩张比例为6,深度卷积核大小为5x5,核步长为2x2,包含压缩与激发操作,无连接失活核连接跳越);
第二个(扩张比例为6,深度卷积核大小为5x5,核步长为1x1,包含压缩与激发操作,有连接失活核连接跳越);
第三个(扩张比例为6,深度卷积核大小为5x5,核步长为1x1,包含压缩与激发操作,有连接失活核连接跳越);
第四个(扩张比例为6,深度卷积核大小为5x5,核步长为1x1,包含压缩与激发操作,有连接失活核连接跳越);
输出是一个7x7x192的特征图。总计参数2044396个,需要训练学习的参数2026348个。
第八阶段,对前一阶段输出的7x7x192的特征图进行一次移动翻转瓶颈卷积
(扩张比例为6,深度卷积核大小为3x3,核步长为1x1,包含压缩与激发操作,无连接失活核连接跳越);
输出是一个7x7x320的特征图。总计参数722480个,需要训练学习的参数717232个。
第九阶段:对输入的7x7x320的图像按顺序进行以下操作得到模型最终的结果:
1) 卷积(卷积核为1280核1×1×320,步长为1×1,填充为“same”即输出的宽和高不变),该卷积运算的输出是一个维度为(7×7×1280)的特征图。因该层不含偏置项,故该层需要训练学习的参数共计409600(1280x1x1x320)个。
2) 批归一化层(Batch Normalization,BN),该层输入为(7×7×1280)的特征图,故该层含参数总数为5120个(1280x4),其中需要训练学习的参数为2560个。
3) Swish激活函数
4) 全局平均池化层(global average pooling),该层在通道维度方向上进行全局平均池化,输出为(1x1x1280)的特征图。
5) 随机失活dropout
6) 全连接层,该层有1000个神经元。因该层包含偏置项,总参数个数为1281000(1000x1280+1000)
7) Softmax激活函数,输出分类结果。
第九阶段,总计参数1695720个,需要训练学习的参数1693160个。
除了EfficientNet-B0外,EfficientNet系列还有其它7个网络B0-B7,主要涉及三个参数深度参数、广度参数和输入分辨率参数,通过这三个参数来控制模型的缩放。
其中:
深度参数通过与EfficientNet-B0中各阶段的模块重复次数相乘,得到更深层的网络架构;
广度系数通过与EfficientNet-B0中各卷积操作输入的核个数相乘,得到表现能力更强的网络模型;
输入分辨率参数控制的则是网络的输入图片的长宽大小。
PyTorch实现EfficientNet-B0模型:
class EfficientNet(nn.Module):
"""
EfficientNet model框架流程(B0为例):
输入 ——>
——> 第一阶段:卷积层 ——> 批归一化 ——> Swish激活函数
——> 第二阶段:1个MBConvBlock
——> 第三阶段:2个MBConvBlock
——> 第四阶段:2个MBConvBlock
——> 第五阶段:3个MBConvBlock
——> 第六阶段:3个MBConvBlock
——> 第七阶段:4个MBConvBlock
——> 第八阶段:1个MBConvBlock
——> 第九阶段:卷积层 ——> 批归一化 ——> Swish激活函数 ——> 全局平均池化 ——> 随机失活 ——> 全连接层 ——> Softmax 层
——> 输出
"""
def __init__(self, blocks_args=None, global_params=None):
super().__init__()
assert isinstance(blocks_args, list), 'blocks_args should be a list'
assert len(blocks_args) > 0, 'block args must be greater than 0'
self._global_params = global_params
self._blocks_args = blocks_args
# 恒等宽高卷积操作
Conv2d = get_same_padding_conv2d(image_size=global_params.image_size)
# BN参数
bn_mom = 1 - self._global_params.batch_norm_momentum
bn_eps = self._global_params.batch_norm_epsilon
in_channels = 3 # rgb
# 输出通道数目
out_channels = round_filters(32, self._global_params)
self._conv_stem = Conv2d(in_channels, out_channels, kernel_size=3, stride=2, bias=False)
self._bn0 = nn.BatchNorm2d(num_features=out_channels, momentum=bn_mom, eps=bn_eps)
# 建立ModuleList of MBConvBlock 模块,方便多次使用和调用
self._blocks = nn.ModuleList([])
for i in range(len(self._blocks_args)):
# Update block input and output filters based on depth multiplier.
self._blocks_args[i] = self._blocks_args[i]._replace(
input_filters=round_filters(self._blocks_args[i].input_filters, self._global_params),
output_filters=round_filters(self._blocks_args[i].output_filters, self._global_params),
num_repeat=round_repeats(self._blocks_args[i].num_repeat, self._global_params))
self._blocks.append(MBConvBlock(self._blocks_args[i], self._global_params))
if self._blocks_args[i].num_repeat > 1:
self._blocks_args[i] = self._blocks_args[i]._replace(input_filters=self._blocks_args[i].output_filters, stride=1)
for _ in range(self._blocks_args[i].num_repeat - 1):
self._blocks.append(MBConvBlock(self._blocks_args[i], self._global_params))
# 输出模块
in_channels = self._blocks_args[len(self._blocks_args)-1].output_filters
out_channels = round_filters(1280, self._global_params)
self._conv_head = Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
self._bn1 = nn.BatchNorm2d(num_features=out_channels, momentum=bn_mom, eps=bn_eps)
# 最后的全连接层以及输出阶段
self._avg_pooling = nn.AdaptiveAvgPool2d(1)
self._dropout = nn.Dropout(self._global_params.dropout_rate)
self._fc = nn.Linear(out_channels, self._global_params.num_classes)
self._swish = MemoryEfficientSwish()
def set_swish(self, memory_efficient=True):
"""Sets swish function as memory efficient (for training) or standard (for export)"""
self._swish = MemoryEfficientSwish() if memory_efficient else Swish()
for block in self._blocks:
block.set_swish(memory_efficient)
def extract_features(self, inputs):
""" Returns output of the final convolution layer """
# 第一阶段
x = self._swish(self._bn0(self._conv_stem(inputs)))
P = []
index = 0
num_repeat = 0
# 第二、三、四、五、六、七、八阶段
for idx, block in enumerate(self._blocks):
drop_connect_rate = self._global_params.drop_connect_rate
if drop_connect_rate:
drop_connect_rate *= float(idx) / len(self._blocks)
x = block(x, drop_connect_rate=drop_connect_rate)
# x = self._swish(self._bn1(self._conv_head(x)))
num_repeat = num_repeat + 1
if num_repeat == self._blocks_args[index].num_repeat:
num_repeat = 0
index = index + 1
P.append(x)
return P
def forward(self, inputs):
""" Calls extract_features to extract features, applies final linear layer, and returns logits. """
bs = inputs.size(0)
# Convolution layers
x = self.extract_features(inputs)
# Pooling and final linear layer
# x = self._avg_pooling(x)
# x = x.view(bs, -1)
# x = self._dropout(x)
# x = self._fc(x)
return x
@classmethod
# 自身的预训练模型加载
def from_name(cls, model_name, override_params=None):
cls._check_model_name_is_valid(model_name)
blocks_args, global_params = get_model_params(model_name, override_params)
return cls(blocks_args, global_params)
@classmethod
# 下载的预训练模型加载
def from_pretrained(cls, model_name, num_classes=1000, in_channels=3):
model = cls.from_name(model_name, override_params={'num_classes': num_classes})
load_pretrained_weights(
model, model_name, load_fc=(num_classes == 1000))
if in_channels != 3:
Conv2d = get_same_padding_conv2d(image_size=model._global_params.image_size)
out_channels = round_filters(32, model._global_params)
model._conv_stem = Conv2d(in_channels, out_channels, kernel_size=3, stride=2, bias=False)
return model
@classmethod
# load预训练权重
def from_pretrained(cls, model_name, num_classes=1000):
model = cls.from_name(model_name, override_params={'num_classes': num_classes})
load_pretrained_weights(model, model_name, load_fc=(num_classes == 1000))
return model
@classmethod
# 获取图像的shape
def get_image_size(cls, model_name):
cls._check_model_name_is_valid(model_name)
_, _, res, _ = efficientnet_params(model_name)
return res
@classmethod
# 检验预训练模型的名称是否正确
def _check_model_name_is_valid(cls, model_name, also_need_pretrained_weights=False):
""" Validates model name. None that pretrained weights are only available for
the first four models (efficientnet-b{i} for i in 0,1,2,3) at the moment. """
num_models = 4 if also_need_pretrained_weights else 8
valid_models = ['efficientnet-b'+str(i) for i in range(num_models)]
if model_name not in valid_models:
raise ValueError('model_name should be one of: ' + ', '.join(valid_models))
# 获取卷积后的特征图
def get_list_features(self):
list_feature = []
for idx in range(len(self._blocks_args)):
list_feature.append(self._blocks_args[idx].output_filters)
return list_feature
2.2、BiFPN模块
如下图所示,BiFPN在图e的基础上增加了shortcut,这些都是在现有的一些工作的基础上添砖加瓦。
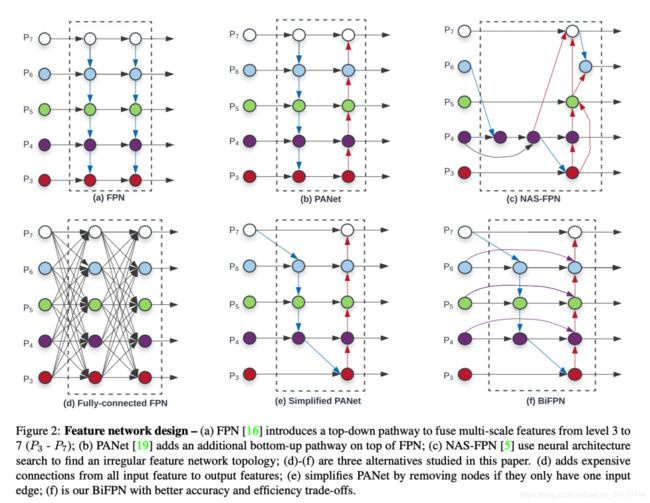
图 BiFPN与其他的特征融合方法的比较
但是,以往的特征融合方法对所有输入特征一视同仁,在BiFPN中则引入了加权策略,下边介绍本文提出来的加权策略(类似attention机制)。
最直白的思想,加上一个可学习的权重即可,如下:
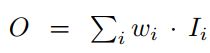
其中wi可以是一个标量(对每一个特征),可以是一个向量(对每一个通道),也可以是一个多维度的tenor(对每一个像素)。
但是如果不对wi对限制容易导致训练不稳定,于是很自然的想到对每一个权重用softmax:
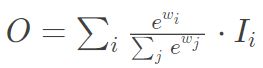
但是计算softmax速度较慢,于是作者提出了快速的限制方法:
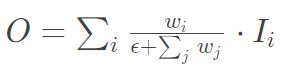
为了保证weight大于0,weight前采用relu函数。以上图BiFPN结构中第6层为例:
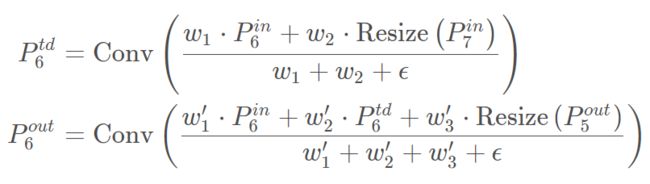
PyTorch实现BiFPN模型:
import torch.nn as nn
import torch.nn.functional as F
from .module import ConvModule, xavier_init
import torch
class BIFPN(nn.Module):
def __init__(self,
in_channels,
out_channels,
num_outs,
start_level=0,
end_level=-1,
stack=1,
add_extra_convs=False,
extra_convs_on_inputs=True,
relu_before_extra_convs=False,
no_norm_on_lateral=False,
conv_cfg=None,
norm_cfg=None,
activation=None):
super(BIFPN, self).__init__()
assert isinstance(in_channels, list)
self.in_channels = in_channels
self.out_channels = out_channels
self.num_ins = len(in_channels)
self.num_outs = num_outs
self.activation = activation
self.relu_before_extra_convs = relu_before_extra_convs
self.no_norm_on_lateral = no_norm_on_lateral
self.stack = stack
if end_level == -1:
self.backbone_end_level = self.num_ins
assert num_outs >= self.num_ins - start_level
else:
# if end_level < inputs, no extra level is allowed
self.backbone_end_level = end_level
assert end_level <= len(in_channels)
assert num_outs == end_level - start_level
self.start_level = start_level
self.end_level = end_level
self.add_extra_convs = add_extra_convs
self.extra_convs_on_inputs = extra_convs_on_inputs
self.lateral_convs = nn.ModuleList()
self.fpn_convs = nn.ModuleList()
self.stack_bifpn_convs = nn.ModuleList()
for i in range(self.start_level, self.backbone_end_level):
l_conv = ConvModule(
in_channels[i],
out_channels,
1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg if not self.no_norm_on_lateral else None,
activation=self.activation,
inplace=False)
self.lateral_convs.append(l_conv)
for ii in range(stack):
self.stack_bifpn_convs.append(BiFPNModule(channels=out_channels,
levels=self.backbone_end_level-self.start_level,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
activation=activation))
# add extra conv layers (e.g., RetinaNet)
extra_levels = num_outs - self.backbone_end_level + self.start_level
if add_extra_convs and extra_levels >= 1:
for i in range(extra_levels):
if i == 0 and self.extra_convs_on_inputs:
in_channels = self.in_channels[self.backbone_end_level - 1]
else:
in_channels = out_channels
extra_fpn_conv = ConvModule(
in_channels,
out_channels,
3,
stride=2,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
activation=self.activation,
inplace=False)
self.fpn_convs.append(extra_fpn_conv)
self.init_weights()
# default init_weights for conv(msra) and norm in ConvModule
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
xavier_init(m, distribution='uniform')
def forward(self, inputs):
assert len(inputs) == len(self.in_channels)
# build laterals
laterals = [
lateral_conv(inputs[i + self.start_level])
for i, lateral_conv in enumerate(self.lateral_convs)
]
# part 1: build top-down and down-top path with stack
used_backbone_levels = len(laterals)
for bifpn_module in self.stack_bifpn_convs:
laterals = bifpn_module(laterals)
outs = laterals
# part 2: add extra levels
if self.num_outs > len(outs):
# use max pool to get more levels on top of outputs
# (e.g., Faster R-CNN, Mask R-CNN)
if not self.add_extra_convs:
for i in range(self.num_outs - used_backbone_levels):
outs.append(F.max_pool2d(outs[-1], 1, stride=2))
# add conv layers on top of original feature maps (RetinaNet)
else:
if self.extra_convs_on_inputs:
orig = inputs[self.backbone_end_level - 1]
outs.append(self.fpn_convs[0](orig))
else:
outs.append(self.fpn_convs[0](outs[-1]))
for i in range(1, self.num_outs - used_backbone_levels):
if self.relu_before_extra_convs:
outs.append(self.fpn_convs[i](F.relu(outs[-1])))
else:
outs.append(self.fpn_convs[i](outs[-1]))
return tuple(outs)
class BiFPNModule(nn.Module):
def __init__(self,
channels,
levels,
init=0.5,
conv_cfg=None,
norm_cfg=None,
activation=None,
eps=0.0001):
super(BiFPNModule, self).__init__()
self.activation = activation
self.eps = eps
self.levels = levels
self.bifpn_convs = nn.ModuleList()
# weighted
self.w1 = nn.Parameter(torch.Tensor(2, levels).fill_(init))
self.relu1 = nn.ReLU()
self.w2 = nn.Parameter(torch.Tensor(3, levels - 2).fill_(init))
self.relu2 = nn.ReLU()
for jj in range(2):
for i in range(self.levels-1): # 1,2,3
fpn_conv = nn.Sequential(
ConvModule(
channels,
channels,
3,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
activation=self.activation,
inplace=False)
)
self.bifpn_convs.append(fpn_conv)
# default init_weights for conv(msra) and norm in ConvModule
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
xavier_init(m, distribution='uniform')
def forward(self, inputs):
assert len(inputs) == self.levels
# build top-down and down-top path with stack
levels = self.levels
# w relu
w1 = self.relu1(self.w1)
w1 /= torch.sum(w1, dim=0) + self.eps # normalize
w2 = self.relu2(self.w2)
w2 /= torch.sum(w2, dim=0) + self.eps # normalize
# build top-down
idx_bifpn = 0
pathtd = inputs
inputs_clone = []
for in_tensor in inputs:
inputs_clone.append(in_tensor.clone())
for i in range(levels - 1, 0, -1):
pathtd[i - 1] = (w1[0, i-1]*pathtd[i - 1] + w1[1, i-1]*F.interpolate(
pathtd[i], scale_factor=2, mode='nearest'))/(w1[0, i-1] + w1[1, i-1] + self.eps)
pathtd[i - 1] = self.bifpn_convs[idx_bifpn](pathtd[i - 1])
idx_bifpn = idx_bifpn + 1
# build down-top
for i in range(0, levels - 2, 1):
pathtd[i + 1] = (w2[0, i] * pathtd[i + 1] + w2[1, i] * F.max_pool2d(pathtd[i], kernel_size=2) +
w2[2, i] * inputs_clone[i + 1])/(w2[0, i] + w2[1, i] + w2[2, i] + self.eps)
pathtd[i + 1] = self.bifpn_convs[idx_bifpn](pathtd[i + 1])
idx_bifpn = idx_bifpn + 1
pathtd[levels - 1] = (w1[0, levels-1] * pathtd[levels - 1] + w1[1, levels-1] * F.max_pool2d(
pathtd[levels - 2], kernel_size=2))/(w1[0, levels-1] + w1[1, levels-1] + self.eps)
pathtd[levels - 1] = self.bifpn_convs[idx_bifpn](pathtd[levels - 1])
return pathtd
2.3、EfficientDet结构
组合了backbone(使用了EfficientNet)和BiFPN(特征网络)和Box prediction net,整个框架就是EfficientDet的基本模型,结构如下图:
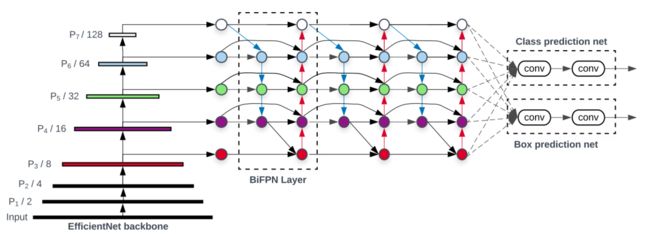
主干网络采用的是 EfficientNet 网络,BiFPN 是基于其 3~7 层的特征图进行的,融合后的特征喂给一个分类网络和 box 网络,分类与 box 网络在所有特征级上权重是共享的。
PyTorch实现EfficientDet结构:
class EfficientDet(nn.Module):
def __init__(self,
num_classes,
network='efficientdet-d0',
D_bifpn=3,
W_bifpn=88,
D_class=3,
is_training=True,
threshold=0.01,
iou_threshold=0.5):
super(EfficientDet, self).__init__()
self.backbone = EfficientNet.from_pretrained(MODEL_MAP[network])
self.is_training = is_training
self.neck = BIFPN(in_channels=self.backbone.get_list_features()[-5:],
out_channels=W_bifpn,
stack=D_bifpn,
num_outs=5)
self.bbox_head = RetinaHead(num_classes=num_classes, in_channels=W_bifpn)
self.anchors = Anchors()
self.regressBoxes = BBoxTransform()
self.clipBoxes = ClipBoxes()
self.threshold = threshold
self.iou_threshold = iou_threshold
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
self.freeze_bn()
self.criterion = FocalLoss()
def forward(self, inputs):
if self.is_training:
inputs, annotations = inputs
else:
inputs = inputs
x = self.extract_feat(inputs)
outs = self.bbox_head(x)
classification = torch.cat([out for out in outs[0]], dim=1)
regression = torch.cat([out for out in outs[1]], dim=1)
anchors = self.anchors(inputs)
if self.is_training:
return self.criterion(classification, regression, anchors, annotations)
else:
transformed_anchors = self.regressBoxes(anchors, regression)
transformed_anchors = self.clipBoxes(transformed_anchors, inputs)
scores = torch.max(classification, dim=2, keepdim=True)[0]
scores_over_thresh = (scores > self.threshold)[0, :, 0]
if scores_over_thresh.sum() == 0:
print('No boxes to NMS')
# no boxes to NMS, just return
return [torch.zeros(0), torch.zeros(0), torch.zeros(0, 4)]
classification = classification[:, scores_over_thresh, :]
transformed_anchors = transformed_anchors[:, scores_over_thresh, :]
scores = scores[:, scores_over_thresh, :]
anchors_nms_idx = nms(
transformed_anchors[0, :, :], scores[0, :, 0], iou_threshold=self.iou_threshold)
nms_scores, nms_class = classification[0, anchors_nms_idx, :].max(
dim=1)
return [nms_scores, nms_class, transformed_anchors[0, anchors_nms_idx, :]]
2.4、模型复合扩张
主干网络部分:这部分直接把 EfficientNet 缩放拿过来用即可,即 EfficientNet B0-B6,借助其现成的 checkpoints,就不折腾了;
BiFPN 网络部分:这部分借鉴 EfficientNet,在 Channel 上直线指数级增加,在深度上线性增加,具体的缩放系数公式为:
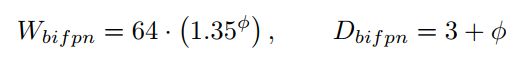
Box/class 预测网络部分:其宽度与 BiFPN 部分保持一致,深度方面采用
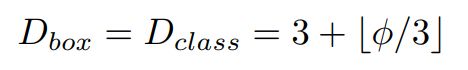
图片分辨率部分: 因为特征提取选择的是 3~7 层,第 7 层的大小为原始图片的1/2^7,所以输入图像的大小必须是 128 的倍数
![]()
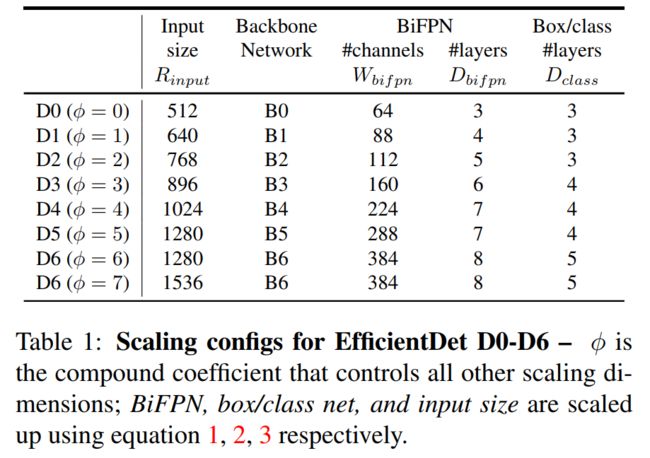
D7 明显是超出内存大小了,只是在 D6 基础上增加了分辨率大小。
2.5、EfficientDet结构总结
BiFPN和模型复合扩张策略都非常有效,BiFPN和综合平衡分辨率、深度和宽度提升性能。但是一方面BiFPN除了Feature map的加权组合是新的提的,PANet和shortcut的思路其他论文也都提过,另一方面就是平衡三者的方法完全是个经验值,并没有理论上的分析或者指导,可能最后还是要依靠NAS来给出最优的策略。
2.6、训练过程与测试结果

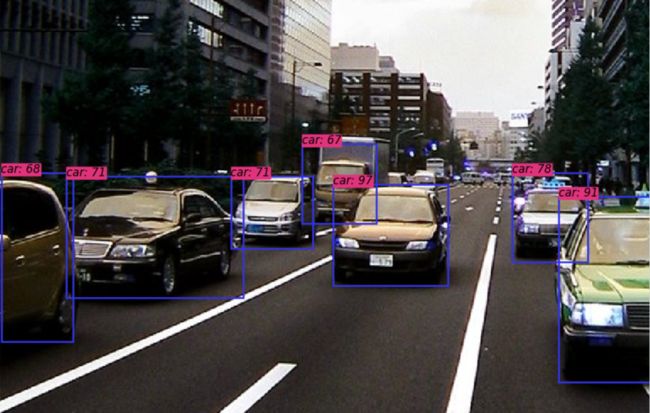
参考:
https://zhuanlan.zhihu.com/p/111115509
https://blog.csdn.net/weixin_37179744/article/details/103217305
https://zhuanlan.zhihu.com/p/96773680
注意:数据集为voc2012与coco2014数据集,可以自行下载。
目标检测系列秘籍一:模型加速之轻量化网络秘籍二:非极大值抑制及回归损失优化秘籍三:多尺度检测秘籍四:数据增强秘籍五:解决样本不均衡问题秘籍六:Anchor-Free视觉注意力机制系列Non-local模块与Self-attention之间的关系与区别?视觉注意力机制用于分类网络:SENet、CBAM、SKNetNon-local模块与SENet、CBAM的融合:GCNet、DANetNon-local模块如何改进?来看CCNet、ANN
语义分割系列一篇看完就懂的语义分割综述最新实例分割综述:从Mask RCNN 到 BlendMask超强视频语义分割算法!基于语义流快速而准确的场景解析CVPR2020 | HANet:通过高度驱动的注意力网络改善城市场景语义分割
基础积累系列卷积神经网络中的感受野怎么算?
图片中的绝对位置信息,CNN能搞定吗?理解计算机视觉中的损失函数深度学习相关的面试考点总结
自动驾驶学习笔记系列 Apollo Udacity自动驾驶课程笔记——高精度地图、厘米级定位 Apollo Udacity自动驾驶课程笔记——感知、预测 Apollo Udacity自动驾驶课程笔记——规划、控制自动驾驶系统中Lidar和Camera怎么融合?
竞赛与工程项目分享系列如何让笨重的深度学习模型在移动设备上跑起来基于Pytorch的YOLO目标检测项目工程大合集目标检测应用竞赛:铝型材表面瑕疵检测基于Mask R-CNN的道路物体检测与分割
SLAM系列视觉SLAM前端:视觉里程计和回环检测视觉SLAM后端:后端优化和建图模块视觉SLAM中特征点法开源算法:PTAM、ORB-SLAM视觉SLAM中直接法开源算法:LSD-SLAM、DSO视觉SLAM中特征点法和直接法的结合:SVO
2020年最新的iPad Pro上的激光雷达是什么?来聊聊激光SLAM