CVPR2020 oral | 解决目标检测长尾问题简单方法:Balanced Group Softmax
点击上方“AI算法修炼营”,选择“星标”公众号
精选作品,第一时间送达

本文是中科院、新加坡国立大学联合发表的工作,收录于CVPR2020,并被选为CVPR2020 oral。刚刚开源了最新的代码,并在YouTube上有一个简单的讲解,大家可以参考学习。文章的主要思想是提出了长尾分布目标检测器性能下降主要原因是与类别数量正相关,于是通过分组平均分配类别数的思想,提出了Balanced Group Softmax,这是一个简单的思想,效果很不错,大家可以多尝试。
论文地址:http://openaccess.thecvf.com/content_CVPR_2020/papers/Li_Overcoming_Classifier_Imbalance_for_Long-Tail_Object_Detection_With_Balanced_Group_CVPR_2020_paper.pdf
代码地址:https://github.com/FishYuLi/BalancedGroupSoftmax
视频讲解地址:https://www.youtube.com/watch?v=ikdVuadfUo8
使用基于深度学习的模型来解决长尾 large vocabulary目标检测是一项具有挑战性而艰巨的任务,然而,这项工作尚未得到充分研究。在本文的工作中,首先对针对长尾分布问题所提出SOTA模型的性能进行了系统分析,找出其不足之处。发现当数据集极度偏斜时,现有的检测方法无法对few-shot类别进行建模,这可能导致分类器在参数大小上的不平衡。由于检测和分类之间的内在差异,将长尾分类模型直接应用于检测框架无法解决此问题。因此,在这项工作中,提出了一个新颖的balanced group softmax (BAGS)模块,用于通过逐组训练来平衡检测框架内的分类器。它隐式地调整了头和尾类的训练过程,并确保它们都得到了充分的训练,而无需对来自尾类的instance进行任何额外采样。
在最近的长尾large vocabulary目标识别任务数据集 LVIS上的大量实验表明,本文提出的BAGS大大提高了具有各种主干和框架的检测器在目标检测和实例分割上的性能。它击败了从长尾图像分类中转移过来的所有最新方法,并建立了新的方法。
简介
LVIS 是由facebook AI研究院的研究人员们发布的一个大规模的词汇实例分割数据集(Large Vocabulary Instance Segmentation ),包含了164k图像,并针对超过1000类物体进行了约200万个高质量的实例分割标注。数据集中包含自然图像中的物体分布天然具有长尾属性。
受《Decou-pling representation and classifier for long-tailed recognition》的启发,首先将检测框架中的representation 和分类模块解耦,发现不同类别相对应的proposal 分类器的weight norm严重失衡,因为low-shot类别被激活的机会很少。通过分析,这是长尾检测器性能差的直接原因,而长尾检测器性能本质上是由数据不平衡引起的。
如图1所示,分别根据训练集中实例的数量对在COCO和LVIS上训练的模型的类别分类器权重范数进行排序。对于COCO,除了背景类(类别ID = 0)以外,相对平衡的数据分布导致所有类别的weight norm相对平衡。而对于LVIS,很明显类别weigh norm是不平衡的,并且与训练实例的数量呈正相关。这种不平衡将使low-shot 类别(尾类)的分类分数比many-shot 类别(头部类)的分类分数小得多。在标准softmax函数之后,这种不平衡会被进一步放大,因此分类器错误地抑制了预测为low-shot 类别的proposal 。
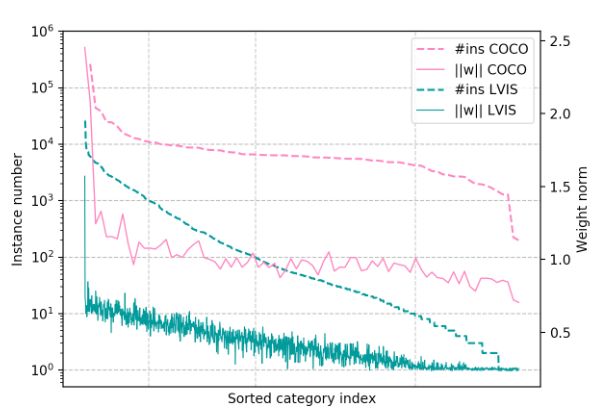
图1. COCO和LVIS训练集中类别的训练实例(#ins)的排序数量,以及在COCO和LVIS上训练的Faster R-CNN模型的相应分类器权重范数“ w”。x轴表示COCO和LVIS的分类索引。将80类COCO与1230类LVIS对齐,以获得更好的可视化效果。类别0表示背景。
长尾分布问题一般解决方法
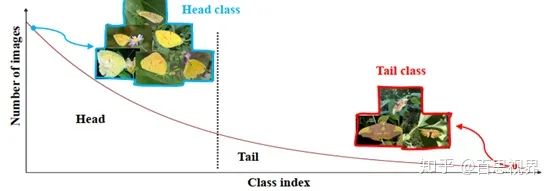
在实际的视觉相关任务中,数据都存在如上图所示的长尾分布,少量类别占据了绝大多少样本,如图中Head部分,大量的类别仅有少量的样本,如图中Tail部分。解决长尾问题的方案一般分为4种:
1、Re-sampling:主要是在训练集上实现样本平衡,如对tail中的类别样本进行过采样,或者对head类别样本进行欠采样。基于重采样的解决方案适用于检测框架,但可能会导致训练时间增加以及对tail类别的过度拟合风险。
2、Re-weighting:主要在训练loss中,给不同的类别的loss设置不同的权重,对tail类别loss设置更大的权重。但是这种方法对超参数选择非常敏感,并且由于难以处理特殊背景类(非常多的类别)而不适用于检测框架。
3、Learning strategy:有专门为解决少样本问题涉及的学习方法可以借鉴,如:meta-learning、metric learning、transfer learing。另外,还可以调整训练策略,将训练过程分为两步:第一步不区分head样本和tail样本,对模型正常训练;第二步,设置小的学习率,对第一步的模型使用各种样本平衡的策略进行finetune。
4、综合使用以上策略
本文的解决方法
在本文中,为了解决分类器的不平衡问题,将一个简单而有效的balanced group softmax(BAGS)模块引入到检测框架的分类head中。本文建议将训练实例数量相似的目标对象类别放在同一组中,并分别计算分组的softmax交叉熵损失。分别处理具有不同实例编号的类别可以有效地减轻head类对tail类的控制。但是,由于每次小组训练都缺乏不同的负样本,结果模型会有太多的误报。因此,BAGS还在每个组中添加了一个其他类别,并将背景类别作为一个单独的组引入,这可以通过减轻head类对tail类的压制来保持分类器的类别平衡,同时防止分类背景和其他类别的false positives。
实验发现BAGS的效果非常好。在长尾目标识别任务数据集LVIS上,使用各种框架包括Faster R-CNN、CascadeR-CNN、Mask R-CNN和HTC与ResNet-50-FPN和ResNeXt-101-x64x4d-FPN,其tail类性能提升了9%-19%,整体mAP提升了约3%-6%。
长尾数据集性能下降原因探索
当训练集遵循长尾分布时,当前表现良好的检测模型通常无法识别尾巴类别。本文通过对代表性示例(COCO和LVIS)进行对比实验,尝试研究从均衡数据集到长尾数据集这种性能下降的背后机制。
通过所设计的对比实验发现(具体的实验细节可以参考论文原文),tail类的预测得分会先天性地低于head类,tail类的proposals 在softmax计算中与head类的proposals 竞争后,被选中的可能性会降低。这就解释了为什么目前的检测模型经常在tail类上失效。由于head类的训练实例远多于tail类的训练实例(例如,在某些极端情况下,10000:1),tail类的分类器权重更容易(频繁)被head类的权重所压制,导致训练后的weight norm不平衡。
因此,可以看出为什么重采样方法能够在长尾目标分类和分割任务中的使得tail类受益。它只是在训练过程中增加了tail类proposals 的采样频率,从而可以平等地激活或抑制不同类别的权重,从而在一定程度上平衡tail类和head类。同样,损失重新加权方法也可以通过类似的方式生效。尽管重采样策略可以减轻数据不平衡的影响,但实际上会带来新的风险,例如过度拟合tail类和额外的计算开销。同时,损失重新加权对每个类别的损失加权设计很敏感,通常在不同的框架,backbone和数据集之间会有所不同,因此很难在实际应用中进行部署。而且,基于重新加权的方法不能很好地处理检测问题中的背景类。因此,本文提出了一种简单而有效的解决方案,无需繁重的超参数工程即可平衡分类器weight norm。
本文方法:Balanced Group Softmax
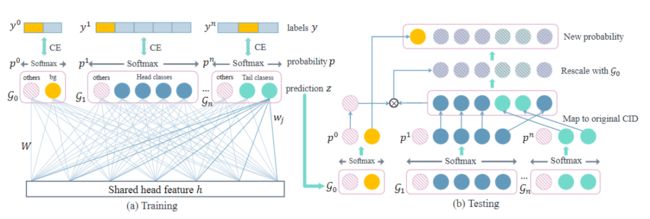
图2.Balanced Group softmax模块的框架。(a)训练:将包含类似训练实例的类别分组在一起。类别 others被添加到每个组。G0表示背景组。Softmax交叉熵损失函数(CE)损失分别应用于每个组。(b)测试:使用新的预测z,将softmax应用于每个组,并按其原始类别ID的概率排序,并用前景概率重新缩放,从而为后续的后期处理环节生成新的概率向量。
1、Group softmax
如前所述,weight norm与训练样本数之间的正相关关系损害了检测器的性能。为了解决这个问题,本文将类别划分为几个不相交的组,并分别执行softmax操作,以使只有具有相似训练实例数量的类在每个组中彼此竞争。这样,可以在训练期间将包含大量不同实例的类彼此隔离。head类将基本上不抑制tail类的分类器权重。
根据训练实例数量将所有类别分为N组:
![]()
其中N(j)是训练集中类别J的标签中边界框的数量,而sl和sh是确定每组的最小和最大实例数的超参数。文中,分为四组N = 4,sl1 = 0,sl2 = 10,sl3 = 102,sl4 = 103,sh4 = +∞。
此外,手动将G0设置为仅包含背景的类别,因为它拥有最多的训练实例(通常比目标类别多10-100倍)。对G0采用sigmoid cross entropy损失,因为它仅包含一个预测,而对于其他组采用softmax cross entropy,选择softmax的原因是softmax函数具有将每个类彼此抑制的能力,并且很少会产生大量的误报。
2、Calibration via category “others”
但是,发现上述group softmax设计存在以下问题:在测试过程中,对于一个proposal,由于其类别未知将使用所有组进行预测,因此,每个组至少有一个类别将获得较高的预测分数,并且很难决定我们应该采用哪种分组预测,从而导致大量误报。为了解决这个问题,在每个组中添加了一个类别,以校准组之间的预测并抑制误报。此类别包含当前组中未包含的类别,可以是其他组中的背景类别或前景类别。
3、Balancing training samples in groups
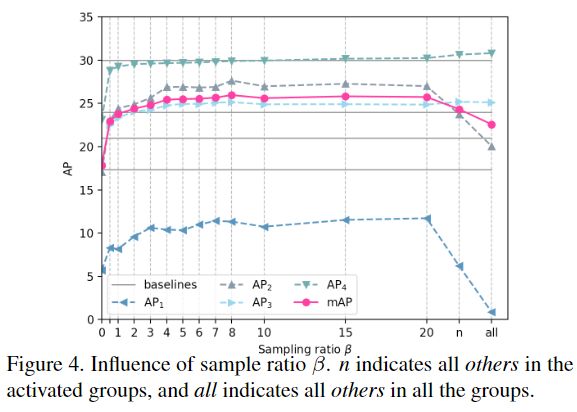
在以上处理中,新添加的类别others将通过抑制众多实例,再次成为占主导地位的outlier 。为了平衡每组的训练样本数,仅对一定数量的others proposals进行训练,由采样率β控制。
在包含标签真值的类别组中,将根据mini-batch of K proposals来按比例采样others实例。如果一组中没有激活正常类别,则所有others实例都不会激活,该组则被忽略。这样,每个组都可以保持平衡,且误报率低。添加others类别会使baseline提高2.7%。
4、Inference
在推理过程中,首先使用训练好的模型生成z,然后在每个组中应用softmax。 除G0外,其他所有节点均被忽略,所有类别的概率均按原始类别ID排序。G0中的p0可被视为前景proposals的概率。最后,使用![]() 重新缩放正常类别的所有概率。这个新的概率向量将被送到后续的后处理步骤(如NMS),以产生最终的检测结果。应该注意的是,从概念上来说
重新缩放正常类别的所有概率。这个新的概率向量将被送到后续的后处理步骤(如NMS),以产生最终的检测结果。应该注意的是,从概念上来说![]() 不是真正的概率向量,因为它的总和不等于1,但它起着原始概率向量的作用,该向量通过选择最终boxes框来指导模型。
不是真正的概率向量,因为它的总和不等于1,但它起着原始概率向量的作用,该向量通过选择最终boxes框来指导模型。
实验与结果
数据集:LVIS,根据训练实例数量将LVIS验证集中的类别划分为4个等级,以更清楚地评估头和尾类的模型性能。
评价指标:mAP,APr(APfor rare classes), APc(AP for common classes), APf(AP for frequent classes)
1、Main results on LVIS
将长尾分类的多种最新方法转移至Faster R-CNN框架,包括对tail类进行微调,重复因子采样(RFS),类别损失重新加权,Focal Loss,NCM 和τ归一化。
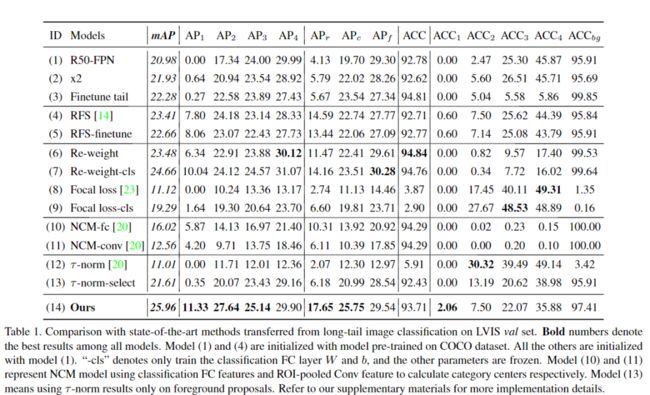
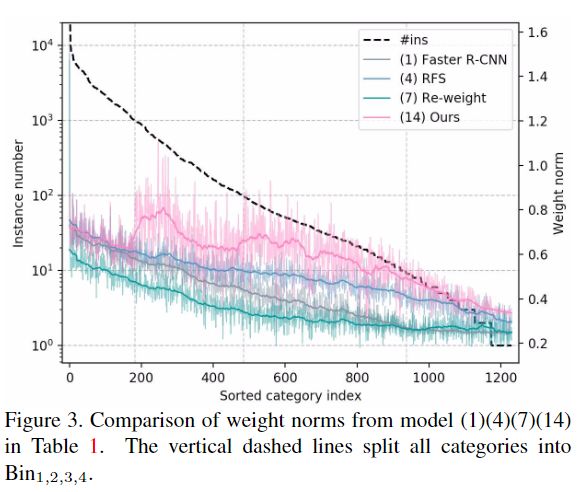
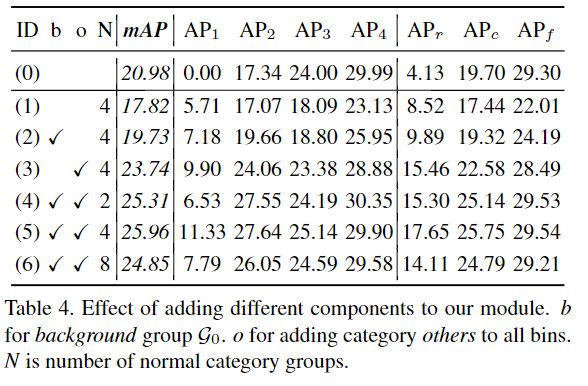
采用以ResNet-50-FPN为主干网络的FasterR-CNN作为baseline(表中的模型(1)),可达到20.98%的mAP但0%的AP1。baseline模型由于其他类别的支配而错过了大多数tail类别。针对tail训练样本对模型(1)微调后得到的模型(3)仅将AP2显着增加,而将AP4减少2.5%,并且AP1保持为0。这表明当训练次数增加时,原始softmax分类器不能很好地适应于实例数量太小的情况。
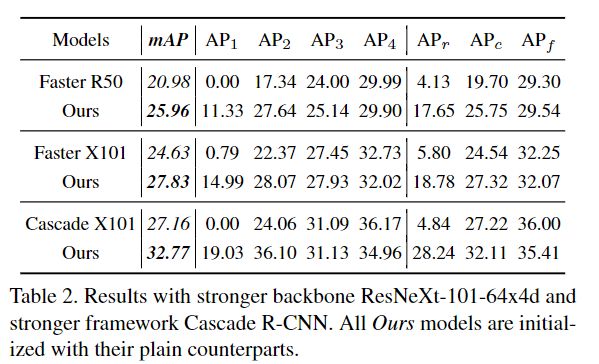
为了进一步验证方法的通用性,将FasterR-CNN主干更改为ResNeXt-101-64x4d,结果展示于表2。在这个更强大的主干上,本文的方法仍然获得了3.2%的改进。然后,将本文的方法应用于最新的Cascade R-CNN框架,并在3个阶段将所有3个softmax分类器更改为BAGS模块。总体mAP显着提高了5.6%。
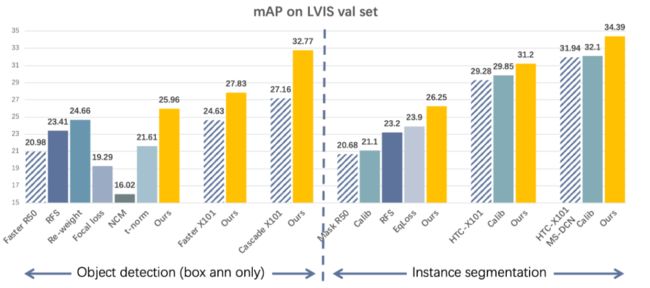
2、Results for instance segmentation
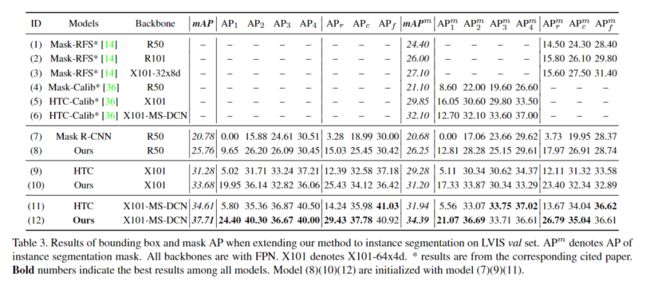
3、消融实验
分组数量N的选取
采样率β的选取
更多实验细节,可以参考原文。
参考:
https://zhuanlan.zhihu.com/p/127791648

