任务式对话系统总结(1)---自然语言理解
任务式对话系统基本框架如下图所示,这里我对语音领域不是很熟悉,所以本文不做具体介绍,因此任务式对话系统基本框架主要包括自然语言理解(NLU),对话管理器( DM) 、语言生成(NLG)。下面内容就具体介绍下这几个组件。
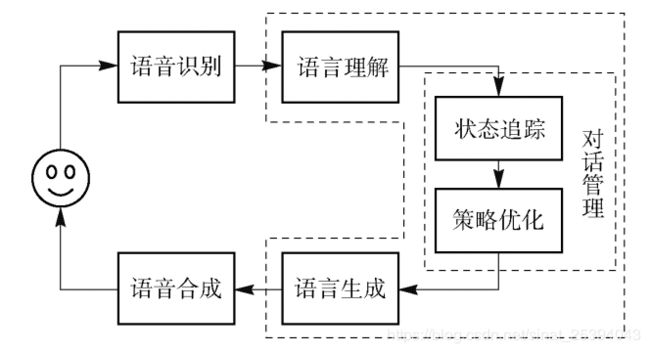
1 自然语言理解NLU
完成的具体任务在不同对话系统中差异较大,比较共性的能力包括领域识别、意图识别、对话行为识别、槽位识别和槽位值抽取。
领域识别是将用户文字输入或者ASR输出的文本分类到各个子领域,如查询天气,订机票等。
用户意图指用户想要完成的具体任务,通常同具体任务紧密相关,如一个账单相关意图包括查询账单、账单投诉、账单比较等.
对话行为也是用于描述用户意图, 但不像用户意图那样从具体完成的任务流程角度来定义意图, 而是从对话本身更通用的角度来识别用户当前对话的主要目的,如用户提问、用户确认一个问题、陈述一个事实等。
槽位识别和槽位信息的提取是一个典型序列标注问题,对输入句子中的每一个字标注相应的槽位标识.下文将会从算法的角度进一步说明这些问题目前都是如何被解决的
1.1 领域识别/意图识别
意图识别问题在NLP领域可以当作文本分类任务来解决。目前应用在文本分类领域传统的机器学习模型有 k 近邻( k-nearest neighbor, kNN)、朴素贝叶斯、SVM等。神经网络兴起后, 一些基于深度学习模型的研究也取得了不俗的效果,主要是运用了CNN模型, 以及CNN 和 RNN相结合的模型。
当对话系统cover的领域很多时,可能意图会多达成百上千,这时候意图识别模型的决策空间变得过大,且各个意图共享同一个模型,每增加一个新意图就要重训模型,导致其他意图也受影响了。不仅导致意图识别模型难训,而且会导致系统变得难以维护。因此一种更好的办法是在意图识别之前再加一级领域分类(domain classification)。
1.2 槽填充
虽然对于一个对话session,用户的意图往往只有一个,但是如前所述,一个意图中往往包含很多个槽位。因此可以很自然的将槽位解析任务建模为序列标注任务或者干脆简化为文本多标签分类任务(一个slot-value pair是一个类别)。而意图识别跟槽位解析任务又明显息息相关的,甚至说高度互相依赖的,因此这两个任务joint training也是近来热门的方法。
关于序列标注,通常使用的方法主要为线性统计方法与深度学习方法以及统计学习-深度学习结合方法:
线性统计方法包括条件随机场(Conditional Random Fields, CRF)、隐马尔可夫模型(Hidden Markov Models, HMM)、最大熵马尔可夫模型(Maximum Entropy Markov Models, MEMM)等。线性统计方法主要依靠手工制定任务资源,开发成本高.
深度学习方法主要为RNN模型及其变体,如长短期记忆网络(Long Short-Term Memory, LSTM)、门控制循环单元(Gated Recurrent Unit, GRU)使用分布式表示作为输入取代手工制定的特征,减小了开发成本且绝对误差更小。RNN 的变体例如长短记忆网络通过三个门结构(输入门、遗忘门和输出门)可以学习长距离的依赖关系,得到了广泛应用。
统计学习-深度学习结合的方法:由于基于 RNN 的模型存在输出独立性问题而采用的方法,例如具有条件随机场层的双向长短记忆网络(Bi-LSTM+CRF),不但可以有效地利用过去和未来的信息,还可以使用句子级标记信息。
2 对话管理
对话管理是对话系统的“大脑”,控制着整个对话系统的流程。DM的输入是自然语言理解的三元组输出,并需要考虑历史对话信息和上下文的语境等信息进行全面地分析,决定系统要采取的相应的动作,其中包括追问、澄清和确认等。 DM的任务主要有:对话状态跟踪和生成对话策略。
2.1 对话状态追踪 Dialogue State Tracking
对话状态是一种将 t 时刻的对话表示为可供系统选择下一时刻动作信息的数据结构,可以看作每个槽值的取值分布情况。 DST以当前的动作  、前n-1轮的对话状态和相应的系统动作作为输入,输出其对当前对话状态
、前n-1轮的对话状态和相应的系统动作作为输入,输出其对当前对话状态 的估计。对话策略的选择依赖于DST估计的对话状态,因此DST至关重要。同时,DST也非常具有挑战性,因为ASR和NLU模块的识别往往会出错,可能导致对话系统无法准确理解用户语义。所以, ASR 和 NLU 模块通常输出N-best列表,DST通过多轮对话不断修改和完善来修正 ASR 和 NLU 识别的错误。
的估计。对话策略的选择依赖于DST估计的对话状态,因此DST至关重要。同时,DST也非常具有挑战性,因为ASR和NLU模块的识别往往会出错,可能导致对话系统无法准确理解用户语义。所以, ASR 和 NLU 模块通常输出N-best列表,DST通过多轮对话不断修改和完善来修正 ASR 和 NLU 识别的错误。
DST 主要分为三类方法:基于人工规则、基于生成式模型和基于判别模式模型。
- 基于人工规则的方法,如有限状态机(Finite State Machine, FSM)需要人工预先定义好所有的状态和状态转移的条件, 使用分数或概率最高的NLU 模块解析结果进行状态更新。目前,大多数商业应用中的对话系统都使用基于人工规则的状态更新方法来选择最有可能的结果。该方法不需要训练集,且很容易将领域的先验知识编码到规则中,与其对应的是其相关参数需要人工制定且无法自学习, ASR 和 NLU 模块的识别错误没有机会得以纠正。这种限制促进了生成式模型和判别式模型的发展。
- 生成式模型是从训练数据中学习相关联合概率密度分布,计算出所有对话状态的条件概率分布作为预测模型。统计学学习算法将对话过程映射为一个统计模型,并引入强化学习算法来计算对话状态的条件概率分布,例如贝叶斯网络、部分可观测马尔可夫模型(POMDP)等。虽然生成式模型的效果优于基于人工规则的方法,且该方法可以自动进行数据训练,减少了人工成本。但是生成式模型无法从 ASR、 NLU 等模块 挖掘大量潜在信息特征,也无法精确建模特征之间的依赖关系。此外,生成式模型进行了不必要的独立假设,在实际应用中假设往往过于理想。
- 基于判别式模型展现出更为有利的优势,它把 DST 当作分类任务,结合深度学习等方法进行自动特征提取,从而对对话状态进行精准建模。与生成式模型相比,判别式模型善于从 ASR、NLU 等模块提取重要特征,直接学习后验分布从而对模型进行化。
下表为各个方法的总结:

2.2 对话策略 Dialogue Police
对话策略根据 DST 估计的对话状态,通过预设的候选动作集,选择系统动作或策略 。DP 性能的优劣决定着人机对话系统的成败。 DP 模型可以通过监督学习、强化学习和模仿学习得到。
。DP 性能的优劣决定着人机对话系统的成败。 DP 模型可以通过监督学习、强化学习和模仿学习得到。
1.监督学习需要专家手工设计对话策略规则,通过上一步生成的动作进行监督学习。由于 DP的性能受特定域的特性、语音识别的鲁棒性、任务的复杂程度等影响,因此手工设计对话策略规则比较困难,而且难以拓展到其他领域。
2.强化学习是通过一个马尔可夫决策过程(Markov Decision Process, MDP),寻找最优策略的过程。MDP 可以描述为五元组(S, A, P, R,  ):
):
S:表示所有可能状态(States)的集合,即状态集;
A:针对每个状态,做出动作(Actions)的集合,即动作集;
P:表示各个状态之间的转移概率,例如
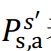 表示在状态s下采取动作a之后转移到状态s’的概率;
表示在状态s下采取动作a之后转移到状态s’的概率;
R:表示各个状态之间的转换获得的对应回报,即奖励函数(Reward Function)。每个状态对应一个值,或者一个状态-动作对(State-Action)对应一个奖励值,例如![]() 表示状态s下采取动作a获得的回报;:表示为折扣因子,用来计算累计奖励。取值范围是0~1。一般随着时间的延长作用越来越小,表明越远的奖励对当前的贡献越少。
表示状态s下采取动作a获得的回报;:表示为折扣因子,用来计算累计奖励。取值范围是0~1。一般随着时间的延长作用越来越小,表明越远的奖励对当前的贡献越少。
DP需要基于目前状态和可能的动作来选择最高累计奖励的动作。该过程仅需要定义奖励函数,例如:预订餐厅的对话中,用户成功预订则获得正奖励值,反之则获得负奖励值。
传统的强化学习需要在较多训练数据的情况下,需要计算整个行动轨迹获得的整体回报来寻找最高回报对应的最优策略,才能获得较好的结果。因此在序列多步决策问题中,强化学习需要频繁地试错,来获得稀疏的奖励,这种“随机”方式的不但搜索空间非常巨大,而且前期收敛速度非常慢。
3.模仿学习(Imitation Learning)能够很好的解决多步决策问题。模仿学习的原理是通过给智能体提供先验知识,从而学习、模仿人类行为。 先验知识提供 m 个专家的决策样本{![]() },每个样本定义为一个状态 s 和动作 a 行动轨迹:
},每个样本定义为一个状态 s 和动作 a 行动轨迹:

将所有[状态-动作]对抽取出来构造新的集合D:
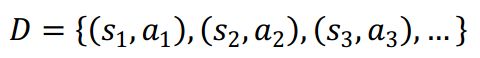
把集合D的状态视为训练数据中的特征,动作视为训练数据中的标签,通过回归连续的动作和分类离散的动作,来得到最优的策略模型。模仿学习需要专家提供较多数据或提供的数据覆盖最优结果,需要花费大量的时间和精力。
下表为方法总结:



3 自然语言生成
自然语言生成的主要任务是将 DM模块输出的抽象表达转换为句法合法、 语义准确的自然语言句子。一个好的应答语句应该具有上下文的连贯性、回复内容的精准性、可读性和多样性。
NLG 的方法可以话分为: 基于规则模板/句子规划的方法、基于语言模型的方法和基于深度学习的方法。基于深度学习的模型还多处于研究阶段,实际应用中还是多采用基于规则模板的方法。
1.基于模板的方法需要人工设定对话场景, 并根据每个对话场景设计对话模板,这些模板的某些成分是固定的,而另一部分需要根据 DM 模块的输出填充模板。例如,使用一个简单的模板对电影票预订领域的相关问题生成回复:
[主演人 1]、 [主演人 2]、 […]主演的[电影名称]电影将于[放映日期]的[放映时间]点在[影院名称]进行放映。
该模板中, [**]部分需要根据 DM 模块的输出进行填充。这种方法简单、回复精准,但是其输出质量完全取决于模板集,即使在相对简单的领域,也需要大量的人工标注和模板编写。需要在创建和维护模板的时间和精力以及输出的话语的多样性和质量之间做不可避免的权衡。因此使用基于模板的方法难以维护,且可移植性差,需要逐个场景去扩展。
2.基于句子规划的方法的效果与基于模板的方法接近。基于句子规划的方法将NLG拆分为三个模块:内容规划、句子规划、表层生成。其过程如下图所示,将输入的语义符号映射为类似句法树的中间形式的表示,如句子规划树(Sentence Planning Tree,SPT)。然后通过表层实现把这些中间形式的结构转换为最终的回复。基于句子规划的方法可以建模复杂的语言结构,同样需要大量的领域知识,并且难以产生比基于人工模板方法更高质量的结果。

3.基于类的语言模型将基于句子规划的方法进行改进:对于内容规划模块,构建话语类、词类的集合,计算每个类的概率,决定哪些类应该包含在话语中;对于表面实现模块,使用n-gram语言模型随机生成每一个对话。从该方法生成的文本在正确性、流畅度有明显提高,且规则简单,容易理解,该方法是的瓶颈在于这些类的集合的创建过于复杂,且需要计算集合中每一个类的概率,因此计算效率低。上述的方法都难以摆脱手工制定模板的缺陷,限制了它们应用于新领域或新产品的可拓展性。基于短语的方法也使用了语言模型,但不需要手工制定规则,比基于类的语言模型方法更高效、准确率也更高。由于实现短语依赖于控制该短语的语法结构,并且需要很多语义对齐处理,因此该方法也难以拓展。
4.深度神经网络可以从海量的数据源中归纳、抽取特征和知识来学习,从而避免人工提取特征带来的复杂性和繁重问题。目前,基于深度学习的 NLG 模型普遍以编码器 -解码器(Encoder-Decoder) 作为基础框架。
References