论文笔记:Hierarchy Parsing for Image Captioning
论文链接:Hierarchy Parsing for Image Captioning
本文首发于PaperWeekly
Introduction
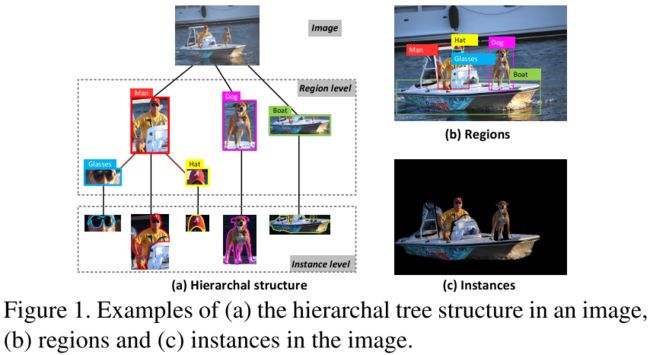
目前大多数的image captioning模型采用的都是encoder-decoder的框架。本文在encoder的部分加入了层次解析(HIerarchy Parsing,HIP)结构。HIP把图片解析成树状结构:根节点是整个图片,中间节点则是通过把图片分解成一系列Region-level的区域来得到的,而叶子节点则是在Region-level的基础上应用图像分割,得到Instance-level的区域,如下图所示。
 由于这样的过程建立起了一个树状的结构,文章应用了Tree-LSTM来增强性能。最后,文章还用了GCN对Region-level和Instance-level之间的关系进行编码,把CIDEr-D提高到了130.6。
由于这样的过程建立起了一个树状的结构,文章应用了Tree-LSTM来增强性能。最后,文章还用了GCN对Region-level和Instance-level之间的关系进行编码,把CIDEr-D提高到了130.6。
文章的主要贡献就是在Image capioning任务中提出了HIP对图像进行层级架构的解析。实际上,文章把HIP认为是一种feature optimizer,对Image-level、Region-level、Instance Level的特征做整合。这也是大多数做image captioning文章的思路,包括各种attention机制、利用更丰富的图像信息等,主要目的都是为了增强图像特征。
本文发表在ICCV 2019上。
Method
Hierarchy Parsing in Images
本节首先介绍如何对图像进行层次解析。
Regions and Instances of Image
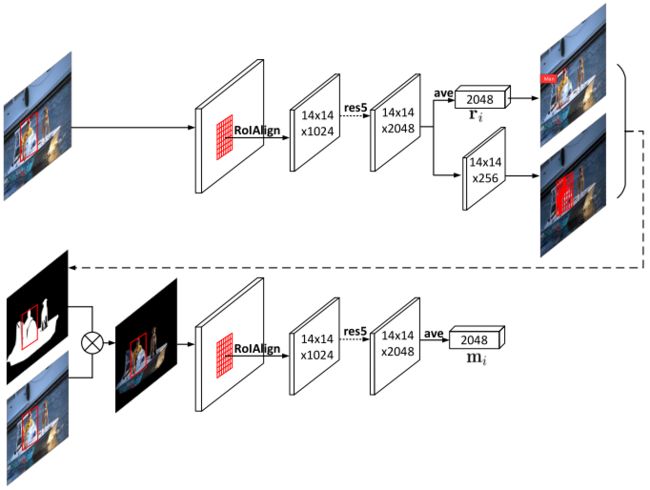
文章分别使用了两个Faster R-CNN来分别提取region和instance的特征。
对于region特征的提取,文章用的就是Up-Down Attention里面的方法:在Visual Genome数据集上训练一个backbone为ResNet-101的Faster R-CNN,提取里面pool5层的特征。
对于instance的特征,文章则是训练了另一个Faster R-CNN来进行提取。如下图所示,首先使用Mask R-CNN提取图像的前景区域图像(通过Mask与原图点乘),然后再用Faster R-CNN来提取对应前景的每个instance的特征。其中两个Faster R-CNN的输入、参数都不共享。
Hierarchy Structure of an Image
对于图像层级关系的建立,文章是通过下列方式确立的:由于图像中的regions会包含一些从属关系(例如,glasses和hat都属于man的区域),如果某个region与比它小的region的IoU大于某个阈值 ϵ \epsilon ϵ,那么这个小的region就成为大的region的子节点。通过对所有region根据面积进行降序排列并遍历后续region计算IoU,可以把图像的层级关系建立起来。最后,再把instance连接到每个region后作为最终的叶子节点。
Image Encoder with Tree-LSTM
文章使用了Tree-LSTM来对三个层次的特征进行编码,可以促进层次结构内的上下文信息挖掘,从而通过整体层次结构来增强图像特征。传统的LSTM只通过上一个时刻的隐状态 h j − 1 h_{j-1} hj−1更新记忆单元 c j c_j cj,而Tree-LSTM的更新则是依赖于多个子节点 f j k f_{jk} fjk的的隐状态。如图所示:
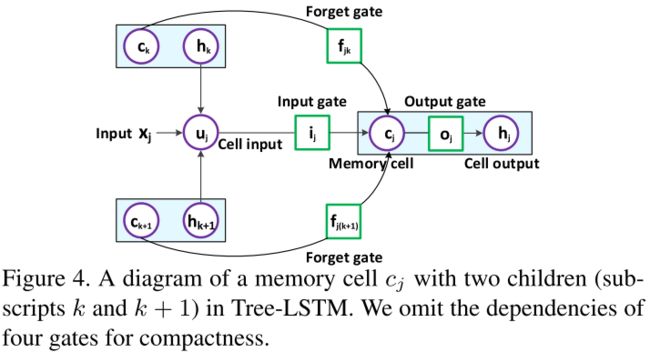 Tree-LSTM公式如下:
Tree-LSTM公式如下:
h ~ j = ∑ k ∈ C ( j ) h k {{\bf{\widetilde{h}}}_j} ~= \sum\limits_{k \in C(j)} {{\bf{h}}_k} h j =k∈C(j)∑hk
u j = ϕ ( W u x j + U u h ~ j + b u ) {{\bf{u}}_j} ~= \phi ({{\bf{W}}_u}{{\bf{x}}_j} + {{\bf{U}}_u} {{\bf{\widetilde{h}}}_j} + {{\bf{b}}_u}) uj =ϕ(Wuxj+Uuh j+bu) , cell input
i j = σ ( W i x j + U i h ~ j + b i ) {{\bf{i}}_j} ~~= \sigma ({{\bf{W}}_i}{{\bf{x}}_j} + {{\bf{U}}_i}{{\bf{\widetilde{h}}}_j} + {{\bf{b}}_i}) ij =σ(Wixj+Uih j+bi) , input gate
f j k = σ ( W f x j + U f h k + b f ) {{\bf{f}}_{jk}} = \sigma ({{\bf{W}}_f}{{\bf{x}}_j} + {{\bf{U}}_f}{{\bf{h}}_k} + {{\bf{b}}_f}) fjk=σ(Wfxj+Ufhk+bf) , forget gate
o j = σ ( W o x j + U o h ~ j + b o ) {{\bf{o}}_j} ~= \sigma ({{\bf{W}}_o}{{\bf{x}}_j} + {{\bf{U}}_o}{{\bf{\widetilde{h}}}_j} + {{\bf{b}}_o}) oj =σ(Woxj+Uoh j+bo) , output gate
c j = u j ⊙ i j + ∑ k ∈ C ( j ) c k ⊙ f j k {{\bf{c}}_j} ~= {\bf{u}}_j \odot {\bf{i}}_j + \sum\limits_{k \in C(j)} {\bf{c}}_k \odot {\bf{f}}_{jk} cj =uj⊙ij+k∈C(j)∑ck⊙fjk , cell state
h j = ϕ ( c j ) ⊙ o j {{\bf{h}}_j} ~= \phi ({\bf{c}}_j) \odot {\bf{o}}_j hj =ϕ(cj)⊙oj , cell output
对于region-level和instance-level的节点,它们的输入则分别是它们的特征 { r i } i = 1 K \{{\bf{r}}_i\}^{K}_{i=1} {ri}i=1K 和 { m i } i = 1 K \{{\bf{m}}_i\}^{K}_{i=1} {mi}i=1K,对于image-level的根节点,它的输入则是region-level和instance-level特征的平均: I = W r r ‾ + W m m ‾ {\bf{I}}={{\bf{W}}_r}\overline {\bf{r}}+{{\bf{W}}_m}\overline {\bf{m}} I=Wrr+Wmm,其中 r ‾ = 1 K ∑ i = 1 K r i \overline {\bf{r}} = \frac{1}{K}\sum\nolimits_{i = 1}^K {{\bf{r}}_i} r=K1∑i=1Kri, m ‾ = 1 K ∑ i = 1 K m i \overline {\bf{m}} = \frac{1}{K}\sum\nolimits_{i = 1}^K {{\bf{m}}_i} m=K1∑i=1Kmi。
最终,通过用Tree-LSTM的方式进行编码,每一个region的输出特征包含了它的instance区域特征以及子节点的region区域特征,表示为 { r i h } i = 1 K \{{\bf{r}}^h_i\}^{K}_{i=1} {rih}i=1K。而image-level的输出特征则表示为 I h {\bf{I}}^h Ih。
Image Captioning with Hierarchy Parsing
接下来,本节介绍如何把解析后的层次特征运用到Image captioning任务里。文章分别把这些特征用到了Up-Down Attention以及GCN-LSTM里,如下图所示。

首先简单回顾一下Up-Down Attention。Up-Down Attention包含两个LSTM,分别是:
- Attention LSTM,接收全局图像特征、上一时刻生成的单词和Language LSTM的隐状态来分配attention权重。
- Language LSTM,接收加权后的区域特征和Attention LSTM的隐状态来产生caption。
把HIP得到的特征应用到Up-Down Attention,其实也就是把两个LSTM的输入作替换。其中Attention LSTM中原来输入的全局图像特征替换为HIP得到的全局图像特征的拼接 [ I h [{\bf{I}}^h [Ih, r ‾ \overline {\bf{r}} r, m ‾ ] \overline {\bf{m}}] m]。每一个region的特征表示为 v i = [ r i h , r i , m i ] {\bf{v}}_i=\left[{\bf{r}}^h_i, {\bf{r}}_i, {\bf{m}}_i \right] vi=[rih,ri,mi],那么Language LSTM原来输入的加权后的区域特征则替换为对加权后的HIP区域特征 v ^ t = ∑ i = 1 K λ t , i v i \hat {\bf{v}}_t = \sum\nolimits_{i = 1}^K {\lambda_{t,i}{\bf{v}}_i} v^t=∑i=1Kλt,ivi,其中 λ t , i \lambda_{t,i} λt,i为对应的注意力权重。
当应用到GCN-LSTM中时,GCN中用到的场景图就是HIP过程中生成的树,然后也是类似Up-Down Attention的方法对特征作替换,不再赘述。
Experiment
文章使用了Visual Genome以及MSCOCO数据集进行训练。值得一提的是,VG数据集包含一些stuff类的bounding box标注,能够提供更丰富的场景信息,但VG数据集并没有给出对应的分割标注。对于这个问题,作者参考了Learning to segment every thing里面partially supervised training的方法来训练Mask R-CNN。其中detection分支的权重由在VG上训练的Faster R-CNN的权重来初始化,然后mask分支以及weight transfer函数则在MSCOCO上训练。
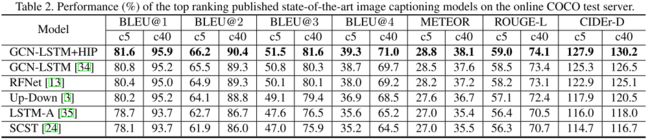
实验效果:可以看到,在COCO test split以及COCO server两个测试集上,加入了HIP以后,Up-Down模型和GCN-LSTM模型的性能都有大幅提升

 文章也进行了消融实验来验证各个部件的性能:
文章也进行了消融实验来验证各个部件的性能:

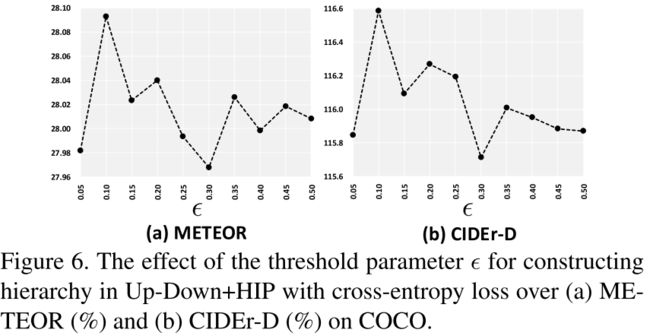
对于IoU的阈值 ϵ \epsilon ϵ,文章也做了实验,效果最好的值是0.1,而 ϵ \epsilon ϵ=0.3的时候效果最差,感觉还是比较反直觉的。
文章还进行了人工评估。通过展示GT、GCN-LSTM+HIP、GCN-LSTM、LSTM的caption,分别做了两组实验:
- 每次展示3个机器生成的caption和三个GT caption,问:机器能产生像人类写的句子吗?
- 每次只展示1个句子,问:能判断出哪些是机器产生的句子,哪些是人类写的句子吗?
通过人工评估的反馈,文章统计了两个指标:
M1:与人类注释相当甚至更好的caption的百分比
M2:通过图灵测试的caption的百分比
GCN-LSTM+HIP、GCN-LSTM和LSTM在M1上的得分分别是76.5%、73.9%和50.7%。
人类注释、GCN-LSTM+HIP、GCN-LSTM和LSTM在M2上的得分分别是91.4%、85.2%、81.5%和57.1%。
两项指标都说明了引入HIP后模型有明显提升。
下图是模型生成的句子示例:
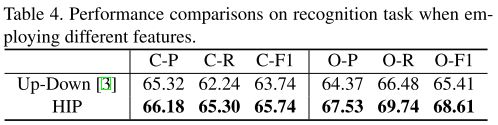
 文章还把HIP扩展到了图像多标签分类问题,把COCO上物体检测的标注作为图像的多标签,并应用Multi-label softmax进行训练。然后分别对每个标签计算precision和recall。最后比较了per-class precision (C-P),pre-class recall (C-R),overall precision (O-P),overall recall (O-R)以及F1值。发现引入HIP后都是有明显提升的。个人认为,其实HIP这种做法与finegrained image recognition中的做法类似。
文章还把HIP扩展到了图像多标签分类问题,把COCO上物体检测的标注作为图像的多标签,并应用Multi-label softmax进行训练。然后分别对每个标签计算precision和recall。最后比较了per-class precision (C-P),pre-class recall (C-R),overall precision (O-P),overall recall (O-R)以及F1值。发现引入HIP后都是有明显提升的。个人认为,其实HIP这种做法与finegrained image recognition中的做法类似。
总结
文章提出了层次解析(HIerarchy Parsing,HIP)的结构,通过对图像进行层次解析,能够丰富所提取的图像特征,并增强模型的可解释性。可以应用到现有的模型当中。文章的实验非常详尽,能够想到把HIP与Tree-LSTM结合、利用partially supervised training来训练Mask R-CNN的想法也是非常新颖。
拓展阅读
Up-Down Attention论文笔记