论文笔记:Contrastive Learning for Image Captioning
原文链接:Contrastive Learning for Image Captioning
Introduction
本文的提出的Contrastive Learning (CL) 主要是为了解决Image Caption任务中生成的Caption缺少Distinctiveness的问题。
这里的Distinctiveness可以理解为独特性,指的是对于不同的图片,其caption也应该是独特的、易于区分的。**即在所有图片中,这个caption与这幅图片的匹配度是最高的。**然而现在大多数的模型生成的caption都非常死板,尤其是对于那些属于同一类的图片,所生成的caption都非常相似,而且caption并没有描述出这些图片在其他方面的差异。
Contrastive Learning for Image Captioning
Empirical Study
文章提出了一个self-retrieval study,来展示缺少Distinctiveness的问题。作者从MSCOCO test set上随机选取了5000张图片 I 1 , . . . I 5000 I_1, ... I_{5000} I1,...I5000,并且用训练好的Neuraltalk2和AdaptiveAttention分别对这些图片生成对应的5000个caption c 1 , . . . , c 5000 c_1, ..., c_{5000} c1,...,c5000。用 p m ( : , θ ) p_m(:, \theta) pm(:,θ)表示模型,对于每个caption c t c_t ct,计算其对于所有图片的条件概率 p m ( c t ∣ I 1 ) , . . . , p m ( c t ∣ I 5000 ) p_m(c_t | I_1), ..., p_m(c_t | I_{5000}) pm(ct∣I1),...,pm(ct∣I5000),然后对这些概率做一个排序,看这个caption对应的原图片是否在这些排序后的结果的top-k个里。具体可见下图。

可见加入了CL来训练以后,模型的查找准确率明显提高了,并且ROUGE_L以及CIDEr的分数也提高了,并且准确度与这两个评价标准的分数呈正相关关系。说明提高Distinctiveness是可以提高模型的performance的。
Contrastive Learning
先介绍通常使用 Maximum Likelihood Estimation (MLE) 训练的方式,这里借用show and tell论文里面的图:
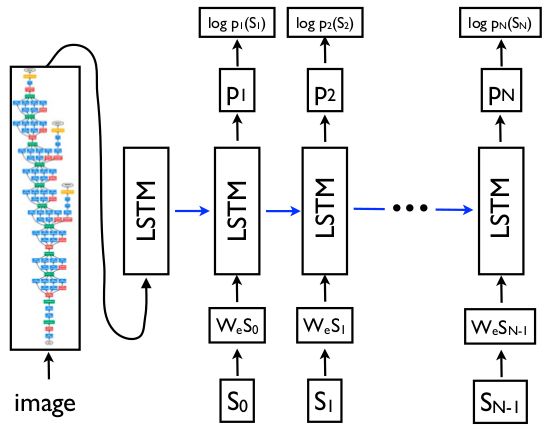
输入一副图片以后,我们会逐个地得到下一个目标单词的概率 p t ( S t ) p_t(S_t) pt(St),我们需要最大化这个概率,而训练目标则通过最小化 L ( I , S ) = − ∑ t = 1 N l o g p t ( S t ) L(I,S)=-\sum_{t=1}^N logp_t(S_t) L(I,S)=−∑t=1Nlogpt(St) 来实现这一目标。
而使用MLE训练会导致缺少Distinctiveness的问题,作者在他之前的文章Towards Diverse and Natural Image Descriptions via a Conditional GAN里面已经解释过了,大家可以读一读。
而CL的中心思想是以一个参考模型 (reference model,如state-of-the-art的模型,本文以Neuraltalk2和AdaptiveAttention为例) 作为baseline,在此基础上提高Distinctiveness,同时又能保留其生成caption的质量。参考模型在训练过程中是固定的。
CL同时还需要正样本和负样本作为输入,正负样本都是图片与ground-truth caption的pair,只不过正样本的caption与图片是匹配的;而负样本虽然图片与正样本相同,但caption却是描述其他图片的。
具体符号:
目标模型 target model: p m ( : , θ ) p_m(:, \theta) pm(:,θ)
参考模型 reference model: p n ( : , ϕ ) p_n(:, \phi) pn(:,ϕ)
正样本 ground-truth pairs: X = ( ( c 1 , I 1 ) , . . . , ( c T m , I T m ) ) X = ((c_1, I_1), ..., (c_{Tm}, I_{Tm})) X=((c1,I1),...,(cTm,ITm))
负样本 mismatched pairs: Y = ( ( c / 1 , I 1 ) , . . . , ( c / T n , I T n ) ) Y = ((c_{/1}, I_1), ..., (c_{/Tn}, I_{Tn})) Y=((c/1,I1),...,(c/Tn,ITn))
目标模型和参考模型都对所有样本给出其估计的条件概率 p m ( c ∣ I , θ ) p_m(c|I,\theta) pm(c∣I,θ)和 p n ( c ∣ I , ϕ ) p_n(c|I,\phi) pn(c∣I,ϕ)
(这里的 p m ( c ∣ I , θ ) p_m(c|I,\theta) pm(c∣I,θ)应该是输入图片后,依次输入caption中的的单词 S 0 , . . . , S N − 1 S_0, ..., S_{N-1} S0,...,SN−1,并且依次把得到的下一个目标单词概率 p 1 ( S 1 ) , . . . , p N ( S N ) p_1(S_1), ..., p_N(S_N) p1(S1),...,pN(SN)相乘所得到的。结合上图看会更清晰。),并且希望对于所有正样本来说, p m ( c ∣ I , θ ) p_m(c|I,\theta) pm(c∣I,θ)大于 p n ( c ∣ I , θ ) p_n(c|I,\theta) pn(c∣I,θ);对于所有负样本, p m ( c / ∣ I , θ ) p_m(c_/|I,\theta) pm(c/∣I,θ)小于 p n ( c ∣ I , ϕ ) p_n(c|I,\phi) pn(c∣I,ϕ)。意思就是目标模型对于正样本要给出比参考模型更高的条件概率,对于负样本要给出比参考模型更低的条件概率。
定义 p m ( c ∣ I , θ ) p_m(c|I,\theta) pm(c∣I,θ)和 p n ( c ∣ I , ϕ ) p_n(c|I,\phi) pn(c∣I,ϕ)的差为 D ( ( c , I ) ; θ , ϕ ) = p m ( c ∣ I , θ ) − p n ( c ∣ I , ϕ ) D((c, I);\theta,\phi) = p_m(c|I,\theta) -p_n(c|I,\phi) D((c,I);θ,ϕ)=pm(c∣I,θ)−pn(c∣I,ϕ)
而loss function为 L ′ ( θ ; X , Y , ϕ ) = ∑ t = 1 T m D ( ( c t , I t ) ; θ , ϕ ) − ∑ t = 1 T n D ( ( c / t , I t ) ; θ , ϕ ) \mathcal{L}'(\theta; X, Y, \phi) = \sum_{t=1}^{T_m}D((c_t, I_t);\theta,\phi) - \sum_{t=1}^{T_n}D((c_{/t}, I_t);\theta,\phi) L′(θ;X,Y,ϕ)=∑t=1TmD((ct,It);θ,ϕ)−∑t=1TnD((c/t,It);θ,ϕ)
这里应该是最大化loss进行求解。
然而实际上这里会遇到几个问题:
首先 p m ( c ∣ I , θ ) p_m(c|I,\theta) pm(c∣I,θ)和 p n ( c ∣ I , ϕ ) p_n(c|I,\phi) pn(c∣I,ϕ)都非常小(~ 1e-8),可能会产生numerical problem。因此分别对 p m ( c ∣ I , θ ) p_m(c|I,\theta) pm(c∣I,θ)和 p n ( c ∣ I , ϕ ) p_n(c|I,\phi) pn(c∣I,ϕ)取对数,
用 G ( ( c , I ) ; θ , ϕ ) = l n p m ( c ∣ I , θ ) − l n p n ( c ∣ I , ϕ ) G((c, I);\theta,\phi) = ln p_m(c|I,\theta) - ln p_n(c|I,\phi) G((c,I);θ,ϕ)=lnpm(c∣I,θ)−lnpn(c∣I,ϕ)来取代 D ( ( c , I ) ; θ , ϕ ) D((c, I);\theta,\phi) D((c,I);θ,ϕ)。
其次,由于负样本是随机采样的,不同的正负样本所产生的 D ( ( c , I ) ; θ , ϕ ) D((c, I);\theta,\phi) D((c,I);θ,ϕ)大小也不一样,有些D可能远远大于0,有些D则比较小,而在最大化loss的过程中更新较小的D则更加有效,因此作者使用了一个logistic function (其实就是sigmoid) r v ( z ) = 1 1 + ν e x p ( − z ) r_v(z) = \frac 1 {1+\nu exp(-z)} rv(z)=1+νexp(−z)1,来saturate这些影响,其中 ν = T n / T m \nu = T_n/T_m ν=Tn/Tm, 并且$ T_n = T_m 来 平 衡 正 负 样 本 的 数 量 。 所 以 来平衡正负样本的数量。所以 来平衡正负样本的数量。所以D((c, I);\theta,\phi)$又变成了:
h ( ( c , I ) ; θ , ϕ ) = r ν ( G ( ( c , I ) ; θ , ϕ ) ) ) h((c, I);\theta,\phi) = r_\nu(G((c, I);\theta,\phi))) h((c,I);θ,ϕ)=rν(G((c,I);θ,ϕ)))
因为 h ( ( c , I ) ; θ , ϕ ) ∈ ( 0 , 1 ) h((c, I);\theta,\phi) \in (0, 1) h((c,I);θ,ϕ)∈(0,1),所以loss function变成了
L ( θ ; X , Y , ϕ ) = ∑ t = 1 T m l n [ h ( ( c t , I t ) ; θ , ϕ ) ] + ∑ t = 1 T n l n [ 1 − h ( ( c / t , I t ) ; θ , ϕ ) ] \mathcal{L}(\theta; X, Y, \phi) = \sum_{t=1}^{T_m}ln[h((c_t, I_t);\theta,\phi)] + \sum_{t=1}^{T_n}ln[1 - h((c_{/t}, I_t);\theta,\phi)] L(θ;X,Y,ϕ)=∑t=1Tmln[h((ct,It);θ,ϕ)]+∑t=1Tnln[1−h((c/t,It);θ,ϕ)]
等式的第一项保证了ground-truth pairs的概率,第二项抑制了mismatched pairs的概率,强制模型学习出Distinctiveness。
另外,本文把X复制了K次,来对应K个不同的负样本Y,这样可以防止过拟合,文中选择K=5。
最终的loss function: J ( θ ) = 1 K 1 T m ∑ k = 1 K L ( θ ; X , Y k , ϕ ) J(\theta) = \frac 1 K \frac 1 {T_m} \sum_{k=1}^K \mathcal{L}(\theta; X, Y_k, \phi) J(θ)=K1Tm1∑k=1KL(θ;X,Yk,ϕ)
以上的这些变换的主要受Noise Contrastive Estimation (NCE) 的启发。
理想情况下,当正负样本能够被完美分辨时, J ( θ ) J(\theta) J(θ)的上界是0。即目标模型会对正样本 p ( c t ∣ I t ) p(c_t | I_t) p(ct∣It)给出高概率,负样本 p ( c / t ∣ I t ) p(c_{/t} | I_t) p(c/t∣It)给出低概率。此时
G ( ( c t , I t ) ; θ , ϕ ) = → ∞ G((c_t, I_t);\theta,\phi) = \rightarrow \infty G((ct,It);θ,ϕ)=→∞, G ( ( c / t , I t ) ; θ , ϕ ) → − ∞ G((c_{/t}, I_t);\theta,\phi) \rightarrow - \infty G((c/t,It);θ,ϕ)→−∞,
h ( ( c t , I t ) ; θ , ϕ ) = 1 h((c_t, I_t);\theta,\phi) =1 h((ct,It);θ,ϕ)=1, h ( ( c / t , I t ) ; θ , ϕ ) = 0 h((c_{/t}, I_t);\theta,\phi) = 0 h((c/t,It);θ,ϕ)=0,
J ( θ ) J(\theta) J(θ)取得上界0。
但实际上,当目标模型对正样本给出最高概率1时,我认为 G ( ( c t , I t ) ; θ , ϕ ) 应 该 等 于 l n p n ( c ∣ I , ϕ ) G((c_t, I_t);\theta,\phi) 应该等于 ln p_n(c|I,\phi) G((ct,It);θ,ϕ)应该等于lnpn(c∣I,ϕ),因此 h ( ( c t , I t ) ; θ , ϕ ) < 1 h((c_t, I_t);\theta,\phi) <1 h((ct,It);θ,ϕ)<1, J ( θ ) J(\theta) J(θ)的上界应该是小于0的。
实验结果
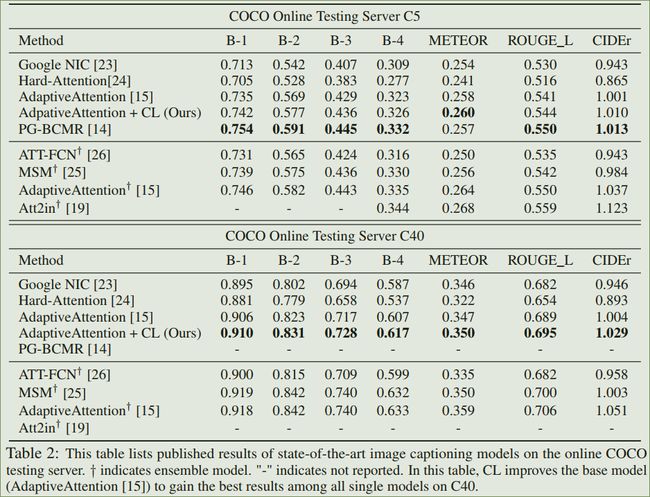
如上图,可以看到,加入CL以后,模型的表现有较大提升。

上图为CL与原模型的一些可视化结果。
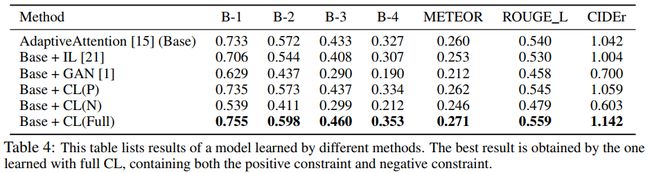
文章还对比了CL跟GAN、IL(Introspective Learning)之间的区别:
- IL把target model自身作为reference,并且是通过比较 ( I , c ) , ( I / , c ) (I, c), (I_/, c) (I,c),(I/,c)来进行学习的。
IL的负样本 ( I / , c ) (I_/, c) (I/,c)通常是预定义且固定的,而CL的负样本则是动态采样的。 - GAN中的evaluator直接测量Distinctiveness,而不能保证其准确性。
另外,加入IL和GAN后模型的准确性都有所下降,说明模型为了提高Distinctiveness而牺牲了准确性。但CL在保持准确性的同时又能提高Distinctiveness。
上图还对比了分别只有正负样本的训练情况。可以看到:
- 只有正样本的情况下模型的表现只稍微提升了一些。我认为,这是因为参考模型是固定的,其对于每个正样本给出的概率也都是固定的,而正样本没有负样本的随机采样过程,所有的样本也是确定的,所以参考模型给出的概率和是恒定的,去掉负样本以后的损失函数就相当于MLE的损失函数再减去一个常数,与MLE是等价的,因此相当于在原来的模型的基础上多进行了一些训练。
- 只有负样本的情况下模型的表现是大幅下降的(因为没有指定正样本,且负样本是随机抽取的)。
而只有两个样本都参与训练的时候能给模型带来很大的提升。
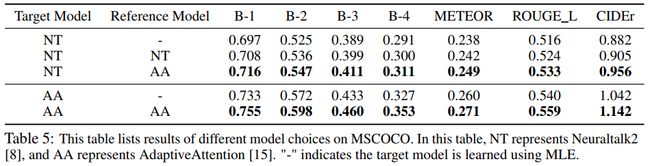
上图测试了CL的泛化能力。“-”表示模型使用MLE训练。可以看到,通过选择更好的模型(AA)作为reference,NT的提升更大。(但是却没有超过AA本身,按理说不是应该比reference模型更好嘛?)
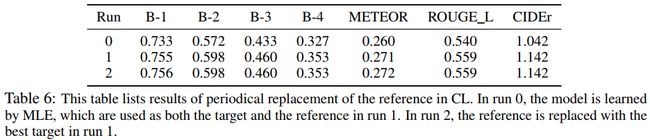
另外,还可以通过周期性地以训练好的目标模型作为更好的参考模型,来提升模型的下界。然而在Run 2进行第二次替换的时候提升已经不大,证明没有必要多次替换。
总结
总的来说,本文主要的贡献在于提出了Contrastive Learning的方法,构造损失函数利用了负样本来参与训练,提高模型的Distinctiveness。另外本文提出的self-retrieval实验思路在同类论文里也是挺特别的。