【论文笔记】Weakly supervised multiple instance learning histopathological tumor segmentation
这篇文章太过抽象,如果有纰漏之处,还望指出 ,不胜感激。
这篇文章是属于多实例学习(MIL)的一个病理组织学方面的应用创新。创新贡献点在于:
1)从WSI(whole slide image)二进制值(binary values)生成标签,用来训练分割模型
2)通过只训练二进制值WSI标注来生成实例级别的预测模型
3)公开可用的肿瘤标注库TCGA已经发布,含6481个样本比之前的多出一个数量级
4)WSI预处理工具的开源
讲完这里,我依然是一头雾水,我会提出以下问题:
(1)什么是WSI,为什么和二值有关系
(2)MIL与WSI场景是怎么结合起来的
(3)怎么形成预测模型
下面将通过不断查资料与阅读来转换我自己的理解。
文章理解
- 预备知识
- 一、 WSI
- 预处理
- WSI的应用之肿瘤患者预后的预测
- WSI的应用之病理癌转移检测
- 二、 WSI与MIL结合
- 初认识MIL
- 文章摘要
- 文章思路
- 具体步骤
- 模型框架
预备知识
一、 WSI
什么是wsi,全程是whole slide image,实际上,他也有专业术语叫全视野数字切片【1】【2】,主要应用与病理学细胞图像领域。WSI 是利用数字扫描仪对传统的病理片扫描,采集具有高分辨率的数字图像,再通过计算机将得到的碎片化图像进行无缝拼接整合,制作可视化数字图像的一项技术。与传统载玻片相比,很好地解决了传统的玻璃切片易损坏、易褪色、易丢片、检索困难的问题。换句话说WSI是对传统载波片进行数字化。
由于是全视野,因此它将包含多尺度的切片在一个文件上面。因此WSI将使用到金字塔模型满足其支持不同分辨率的特性以放缩图片。
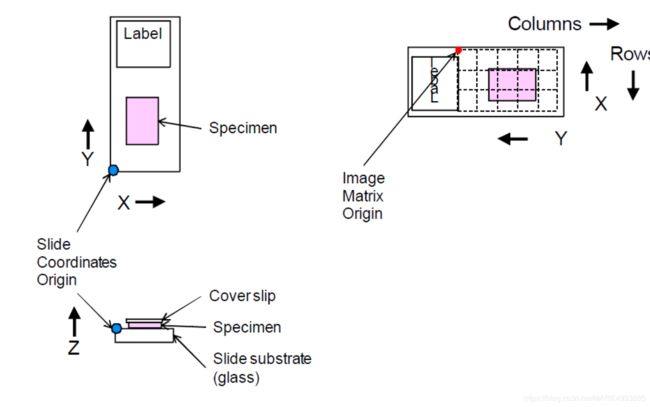
可以看出,一个WSI里面装有样本(specimen),标签(label),盖片(cover slip),滑动基底(slide substrate),这使得联想到在显微镜下看细胞核就是类似这个样子。
预处理
一般wsi的预处理主要是在标记方面下手。主要是标记文件获取、标记mask获取、patch生成。具体demo请借鉴【1】
WSI的应用之肿瘤患者预后的预测
Kather 等利用经训练的 CNN 模型对来自 TCGA 数据库中 500 例Ⅰ~Ⅳ 期结直肠癌(CRC)患者的 862 张 WSI 图像进行自动识别,提出“deep stroma score”是 CRC 患者一个独立的预后预测因子;
并在来自德国 DACHS 队列中 409 例Ⅰ~Ⅳ期 CRC 患者研究中进行验证,结果提示 CNN 算法可直接从组织病理学图像评价肿瘤微环境并预测预后。
Veta 等组织 TUPAC16 比赛(tumor proliferation assessment challenge 2016),利用 821 张乳腺癌 WSI 测试 CNN 算法模型完成自动检测细胞有丝分裂、预测基于 PAM50 增殖评分的基因表达两个任务,以此评估乳腺癌增殖情况判断患者预后。
Harder 等研究纳入 31 例患有Ⅳ期恶性黑色素瘤的患者,利用 CNN 算法识别病理图像特征,预测可以从 ipilimumab(抗 CTLA-4 抗体)免疫治疗中获益的患者人群,研究结果显示 CNN 算法模型区分病理切片中 CD3+、黑色素及非特异性染色的准确率可以分别达到 99.4%、96.0% 和 99%;
Zhou 等利用 TCGA 数据库中 368 张 WSI 测试 CNN 算法性能,证明经训练后的 CNN 模型可通过区分前列腺癌分级预测患者预后,可靠度达 75%;
Yu 等的研究中纳入从 TCGA 数据库中获得的 2186 张肺癌 WSI 图像和 TMA 数据库中的 294 张附加图像,利用机器学习算法提取图像特征,有效地将短期幸存者与Ⅰ期腺癌或鳞状细胞癌的长期幸存者区分开,研究结果表明,利用机器学习算法自动获得的图像特征可以预测肺癌患者的预后,从而有助于精确的肿瘤诊断。
Beck 等开发并利用 C-Path(computational pathologist)系统收集乳腺癌上皮和基质的定量特征集(6642 个特征),构建乳腺癌预后预测模型。该模型应用于两个乳腺癌患者独立队列,共 576 例患者的病理图像分析,证明 C-Path 生成的预后模型评分与队列中患者 OS 密切相关,显微基质结构是乳腺癌的一个独立的预后因素。除此之外,CNN 算法在脑部肿瘤、滤泡性淋巴瘤等肿瘤患者预后方面也可以进行有效预测
WSI的应用之病理癌转移检测
图1

该项目的输入为WSIs以及其标注XML类型文件,输出为wsi热力图。
从这个图,我能推断这个binary values是一种数字化的数据,类似与图像由像素矩阵组成那样。因此它的第一个点说从WSI的二进制值提取标签,有点像上图的第一步从ROI中提取出能代表这片组织病理特性的标签,好与不好。。。
二、 WSI与MIL结合
这里的点是在于上图1所示那样我在WSI这个夹有多层细胞组织的样本中取出一层作为检测样本,标上标签,然后做相应的任务。但是我们都知道我们能再显微镜下看到病理组织主要还是因为我们知道它病理组织的特点,但同时也是由于病理组织它从表面上看起来包含了很多元素,这些元素给一个只懂得检测简单的前景背景的网络模型肯定是不行的。所以MIL恰好能解决样本中对象过多的问题。
初认识MIL
MIL(multiple instance learning)多实例学习,顾名思义就是多个实例一起学习,听起来像是多线程一起做一个事情,根据【3】所介绍的,确实如此,不过其最核心的原理以及目的是在于它将一个样本再次进行语义分割,分割出若干的instance,并且用bag多实例包进行封装,在不做这样分包处理的时候,通常是将这个样本向量化,然后放入网络训练,但是向量化时候,会带入一部分非代表性特征进入,比如要进行动物分类,那提取每个动物的样本时候,其背景或者样本附近的实例会成为这个样本的噪声。因此将样本再次进行实例分割,每个分割区域看作一个示例instance,而将该样本作为一个多实例包(bag)。


分完之后,可知的是多实例包bag的label,而包内的各个实例是没有label的,我们的任务是在正类(有肿瘤)多实例bag和负类(无肿瘤)多实例包的基础上,建立分类器,区分正类多实例包和负类多实例包。
文章摘要
待解决的问题是:在完成组织病理学图像分割中,在预处理时都需要进行手动标注样本中各个实例的语义,从而尽可能使得样本在一种标准内进行。
因此本文提出一种基于弱标准临床实践标注的弱监督的框架来做实例标注;此处用到了MIL为每个实例提供标签,建立WSI的细节分割。
文章思路
传统的分割通过逐像素或逐patch的Ground Truth的标注为分割依据,不过在病理组织学中并不适用,因为手工标注量不足以满足分割需求,而MIL可以减少标注的工作量,又可以达到分割的需求。在MIL中有两种不同的MIL,分别是分类包和训练实例分类(分割)模型。
具体步骤
1)设置WSI的训练集S,每个Si都对应标签T=0,1,0表示正常,1表示不正常。这个标签T是由二值标签构成(binary labels)目标是学习出肿瘤分割模型亦或者是基于patch的分类器,训练依据就是这些标签。
2)对WSI中特性用α和β表示。其中α是正类占比,β为负类占比。用这两个变量来表示这个包里面的情况。
3)损失函数:用的是平均二值交叉熵,目标是最小化训练集S中的经验风险:

其中![]()
定义为从一个slide Si(实例包)中提取的patch集合,其中的预测概率是取决于预测函数
![]()
中Pmin和Pmax的占比,c0和c1是对于每一个批次平均常数(constants for batch averaging)、对于每个类的类不平衡性、Tsi是WSI的二值GT。
最小化经验风险将引导模型有效关注正类(肿瘤斑块Rα)而不会过于关注Rβ。
这条公式用于大范围的机器学习模型,包括基于patch的预测任务。到这里已经可以解惑第三个问题,预测问题。
模型框架
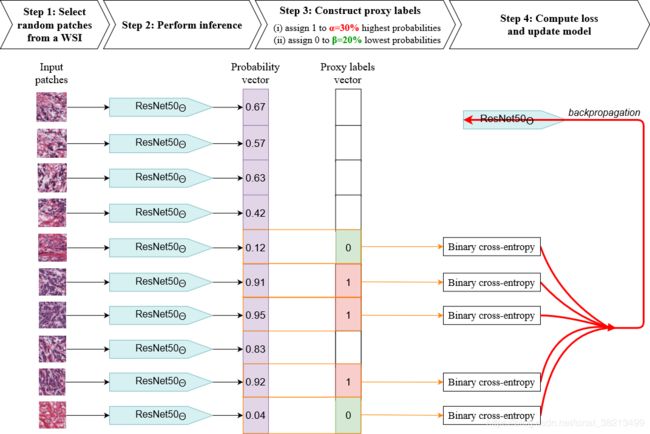

首先开辟空间F,F是从0,采用增量为0.2,构建起的参数空间。其中α=0的丢弃,因为这意味着框架只提供0个标签,这些标签会与经验风险中Tsi=1假设相矛盾
每个条路径配置ResNet50,作者觉得适合这个任务(作者说好就好吧,哈哈)用ImageNet做预训练,每一个epoch,每个训练实例包都只采样一次,然后在中取样时,在WSI组织区域中以20倍的magnification 进行随机取样,取出150个patch。然后做数据增强,包括随机翻转,逐通道RGB规范化。
接着模型就对这150个patch进行推理,如图所示,由10个patch经过resnet50生成对应的概率值,再由概率值构建代理向量(proxy-vector);
对应的150个masking vector对多实例包patch进行填充,使得没有属性化标签的patch直接丢弃。
然后proxy-vector和masking vector结合起来,通过计算二值交叉熵得出平均损失值,并追溯传播所有没有被bask的预测样本。
最后,每次梯度后将常数c0和c1置为1
参考:
【1】https://blog.csdn.net/weixin_41787032/article/details/79782472
【2】https://blog.csdn.net/MARK4993885/article/details/105385078
【3】https://blog.csdn.net/m0_37565948/article/details/88287828
【4】https://mp.weixin.qq.com/s?src=11×tamp=1588298147&ver=2311&signature=UU8M9Gdem-i7H7T5TDn75Yb3TFd34yYdq358w7a3CapRqDeM-ycLALIvJR8vd4JfD-O4pwj02*2UqHf1TDUfsZUeWl52u1eW-ijrbAiBWLSWXU4klBKZFdfdq7yiPFo1&new=1
(人工智能卷积神经网络在全视野数字切片图像分析中的应用进展)