python 爬虫实战项目--爬取京东商品信息(价格、优惠、排名、好评率等)
利用splash爬取京东商品信息
一、环境
- window7
- python3.5
- pycharm
- scrapy
- scrapy-splash
- MySQL
二、简介
为了体验scrapy-splash 的动态网页渲染效果,特地编写了利用splash爬取京东商品信息的爬虫,当然站在爬取效率和稳定性方面来说,动态网页爬取首先应该考虑的还是动态页面逆向分析。
三、环境搭建
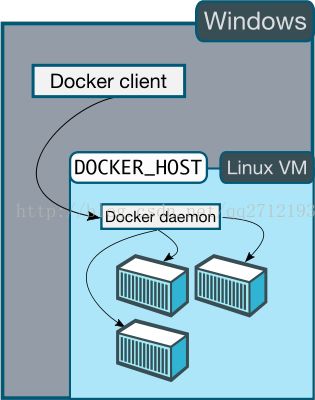
在网上的教程中,大多数是建议利用linux来安装docker,原因如下图:

输入安装splash的命令:$docker pull scrapinghub/splash
运行命令:$docker run -p 8050:8050 -p 5023:5023 scrapinghub/splash ,开启8050连接端口和5023监控端口或者只开启8050端口。
最后在scrapy项目中安装scrapy-splash组件,在settings.py中添加
#用来支持cache_args(可选),splash设置
SPIDER_MIDDLEWARES = {
#'e_commerce.middlewares.ECommerceSpiderMiddleware': 543,
'scrapy_splash.SplashDeduplicateArgsMiddleware' : 100 ,
}
DOWNLOADER_MIDDLEWARES = {
#'e_commerce.middlewares.ECommerceDownloaderMiddleware': 543,
'scrapy_splash.SplashCookiesMiddleware' : 723 ,
'scrapy_splash.SplashMiddleware' : 725 ,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware' : 810 ,
}
#设置去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
SPLASH_URL = 'http://192.168.99.100:8050'环境配置完成。
四、京东网页分析与爬虫编程实现
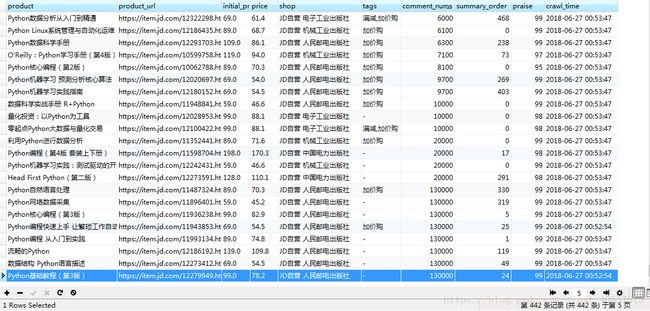
此次主要爬取京东商品的以下参数:
product:商品名
product_url : 商品链接
initial_price : 原价
price : 实际价格
shop : 店家
tags : 优惠活动
comment_nums : 累计评论数
summary_order : 京东排名
praise : 好评度
爬取京东商品信息首先得有商品信息入口,以商品书籍python(关键字)为例,
url:https://search.jd.com/Search?keyword=python&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=python&page=159&s=4732&click=0
简化为:https://search.jd.com/Search?keyword=python&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=python&page=1查看多页发现url里的几个重要关键字:
keyword:搜索关键字
wq:搜索关键字
page:页数(呈奇数递增)
故可以构建请求url:
https://search.jd.com/Search?keyword={1}&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq={1}&page={0}分析网页源码发现各商品信息:

通过css或XPath很容易就可以提取出商品信息,不过发现这里并没有我们想要的所有信息,故还得找出每个商品的url。
这里存在的一个问题是京东一页的商品是分批显示的,通过F12分析网络里的XHR就会发现,新加载的商品是通过向服务器发送请求url:
https://search.jd.com/s_new.php?keyword=python&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=python&page=160&s=4762&scrolling=y&log_id=1530076904.20294&tpl=2_M&show_items=28950919364,12082834672,28883808237,29290652302,29291203091,27895583715,29089172884,28884416666,28938172051,28938903145,26066239470,29090468719,29094523735,28949599627,29291004039,28041915738,26232273814,26400554950,28494562293,29361448498,26291836439,19942582293,15348519021,19580125836,29251686387,27859110321,27880583607,29185119165,28738281855,29184203799
重要关键字page是在原来的基础上加1,直接对该url进行模拟浏览器请求应该是会简便很多,但现在我们不讨论这种逆向分析方法,我们这里采用的是splash中的execute 端点对动态网页进行渲染,就是执行一条javascript语句模拟浏览器跳转到页面下方位置,从而达到完全加载商品的目的。

请求方法:
![]()
商品的url可以在这里提取到:
![]()
构造每个商品url请求:https:// + url,当对该url进行请求时发现商品的价格、优惠信息、图书排名等需要的信息都没有提取出,分析发现需要进行动态渲染才能得到,所以我们这里采用splash的render.html端点对该url网页进行渲染,请求方法:
![]()
此时再去提取相应的信息,提取成功。
但最后还是有一项参数没能成功提取,那就是好评率,躲在这里:
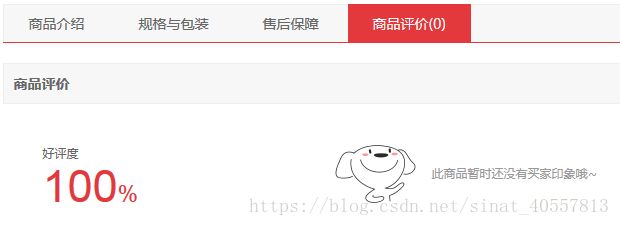
在浏览器中需要点击【商品评价】才能看到,分析网页源码发现该信息也是在点击【商品评价】后向服务器发送请求

请求url:
https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv1516&productId=12186192&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
可简化为:https://sclub.jd.com/comment/productPageComments.action?&productId=12186192&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
构造请求url:https://sclub.jd.com/comment/productPageComments.action?&productId={0}&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
只要传入product_id便可以通过该url请求获得需要的好评度

当然也可以继续提取商品的评论或者是评论情况,这里我觉得好评度已经能说明该商品的好坏了,当然还得结合评论数来做出判断。
关键代码:
def crawl_commentInfo(self , response):
total_product_info = response.css('.gl-item')
for product_info in total_product_info:
product_url = 'https:' + product_info.css('.gl-i-wrap .p-img a::attr(href)').extract_first()
#comment_info crawl firstly
headers = self.headers.copy()
headers.update({
'Referer' : 'https://item.jd.com/12330816.html' ,
'Host': 'sclub.jd.com',
})
match_obj = re.match('.*/(\d+).html', product_url)
if match_obj:
product_id = match_obj.group(1)
yield scrapy.Request(self.start_urls[1].format(product_id) , headers = headers ,
meta= {'product_url' : product_url} , callback= self.parse_product)
print('Now crawl commentInfo url is' , self.start_urls[1].format(product_id))
# break
match_obj = re.match('.*page=(\d+)$', response.url)
if match_obj:
page_num = int(match_obj.group(1)) + 2
else:
page_num = 3
if '下一页' in response.text:
yield SplashRequest(self.start_urls[0].format(page_num, 'python'), endpoint='execute',
callback=self.crawl_commentInfo , splash_headers= self.headers ,
args={'lua_source': self.lua_script, 'image' : 0 , 'wait': 1}, cache_args=['lua_source'])
print('Now page_url is :', self.start_urls[0].format(page_num, 'python')) def parse_product(self, response):
product_url = response.meta.get('product_url')
praise = 0
praise_match = re.match('.*"goodRateShow":(\d+),.*' , response.text)
if praise_match:
praise = praise_match.group(1)
headers = self.headers.copy()
headers.update({
'Upgrade-Insecure-Requests': 1,
'Host' : 'item.jd.com' ,
})
yield SplashRequest(product_url, endpoint='render.html', splash_headers = headers,
args={'image' : 0, 'timeout' : 15 , 'wait' : 1 } , meta={'praise' : praise}
)
print('Now request url is:', product_url)爬取结果: