Java程序员需要掌握的计算机底层知识(一):CPU基本组成、指令乱序执行、合并写技术、非同一访问内存 NUMA
一些书籍
读书的原则:不求甚解,观其大略
你如果进到庐山里头,二话不说,蹲下头来,弯下腰,就对着某棵树某棵小草猛研究而不是说先把庐山的整体脉络跟那研究清楚了,那么你的学习方法肯定效率巨低而且特别痛苦,最重要的还是慢慢地还打击你的积极性,说我的学习怎么那么不happy啊,怎么那么特没劲那,因为你的学习方法错了,大体读明白,先拿来用,用着用着,很多道理你就明白了
▪《编码:隐匿在计算机软硬件背后的语言》
▪《深入理解计算机系统》
▪语言:C JAVA K&R《C程序设计语言》《C Primer Plus》
▪ 数据结构与算法: – 毕生的学习 leetCode
–《Java数据结构与算法》《算法》
–《算法导论》《计算机程序设计艺术》//难
▪操作系统:Linux内核源码解析 Linux内核设计与实现 30天自制操作系统
▪网络:机工《TCP/IP详解》卷一 翻译一般
▪编译原理:机工 龙书 《编译原理》 《编程语言实现模式》马语
▪数据库:SQLite源码 Derby - JDK自带数据库
硬件基础知识
CPU的制作过程
Intel cpu的制作过程
https://haokan.baidu.com/v?vid=11928468945249380709&pd=bjh&fr=bjhauthor&type=video
CPU是如何制作的(文字描述)
https://www.sohu.com/a/255397866_468626

汇编语言(机器语言)的执行过程
汇编语言的本质:机器语言的助记符 其实它就是机器语言
计算机通电 -> CPU读取内存中程序(电信号输入)
->时钟发生器不断震荡通断电 ->推动CPU内部一步一步执行
(执行多少步取决于指令需要的时钟周期)
->计算完成->写回(电信号)->写给显卡输出(sout,或者图形)
量子计算机
量子比特,同时表示1 0
CPU的基本组成
PC -> Program Counter 程序计数器 (记录当前指令地址)
Registers -> 暂时存储CPU计算需要用到的数据
ALU -> Arithmetic & Logic Unit 运算单元
CU -> Control Unit 控制单元
MMU -> Memory Management Unit 内存管理单元
Java相关硬件知识
cache 缓存
一致性协议:https://www.cnblogs.com/z00377750/p/9180644.html
缓存行:
缓存行越大,局部性空间效率越高,但读取时间慢
缓存行越小,局部性空间效率越低,但读取时间快
取一个折中值,目前多用:64字节

证明缓存行的存在:
T01_CacheLinePadding.java
package com.mashibing.juc.c_028_FalseSharing;
import java.util.Random;
public class T01_CacheLinePadding {
private static class T {
public volatile long x = 0L;
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(()->{
for (long i = 0; i < 1000_0000L; i++) {
arr[0].x = i;
}
});
Thread t2 = new Thread(()->{
for (long i = 0; i < 1000_0000L; i++) {
arr[1].x = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start)/100_0000);
}
}
// 输出:1163
T02_CacheLinePadding.java
package com.mashibing.juc.c_028_FalseSharing;
public class T02_CacheLinePadding {
private static class Padding {
public volatile long p1, p2, p3, p4, p5, p6, p7;
}
private static class T extends Padding {
public volatile long x = 0L;
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(()->{
for (long i = 0; i < 1000_0000L; i++) {
arr[0].x = i;
}
});
Thread t2 = new Thread(()->{
for (long i = 0; i < 1000_0000L; i++) {
arr[1].x = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start)/100_0000);
}
}
// 输出:548
以上两个小例子证明了缓存行的存在。
缓存行对齐:对于有些特别敏感的数字,会存在线程高竞争的访问,为了保证不发生伪共享,可以使用缓存航对齐的编程方式
JDK7中,很多采用long padding提高效率
JDK8,加入了@Contended注解(实验)需要加上:JVM -XX:-RestrictContended
CPU 的乱序执行
乱序执行的意思,实际上是在同时执行。本质上是在提高效率。
一个小例子,证明乱序的存在:
package com.mashibing.jvm.c3_jmm;
public class T04_Disorder {
private static int x = 0, y = 0;
private static int a = 0, b =0;
public static void main(String[] args) throws InterruptedException {
int i = 0;
for(;;) {
i++;
x = 0; y = 0;
a = 0; b = 0;
Thread one = new Thread(new Runnable() {
public void run() {
//由于线程one先启动,下面这句话让它等一等线程two. 读着可根据自己电脑的实际性能适当调整等待时间.
//shortWait(100000);
a = 1;
x = b;
}
});
Thread other = new Thread(new Runnable() {
public void run() {
b = 1;
y = a;
}
});
one.start();other.start();
one.join();other.join();
String result = "第" + i + "次 (" + x + "," + y + ")";
if(x == 0 && y == 0) {
System.err.println(result);
break;
} else {
//System.out.println(result);
}
}
}
public static void shortWait(long interval){
long start = System.nanoTime();
long end;
do{
end = System.nanoTime();
}while(start + interval >= end);
}
}
执行结果:出现了 0,0,证明了乱序的存在


上面这个小例子来源于外国人写的一个博客:
https://preshing.com/20120515/memory-reordering-caught-in-the-act/
乱序可能存在的问题:
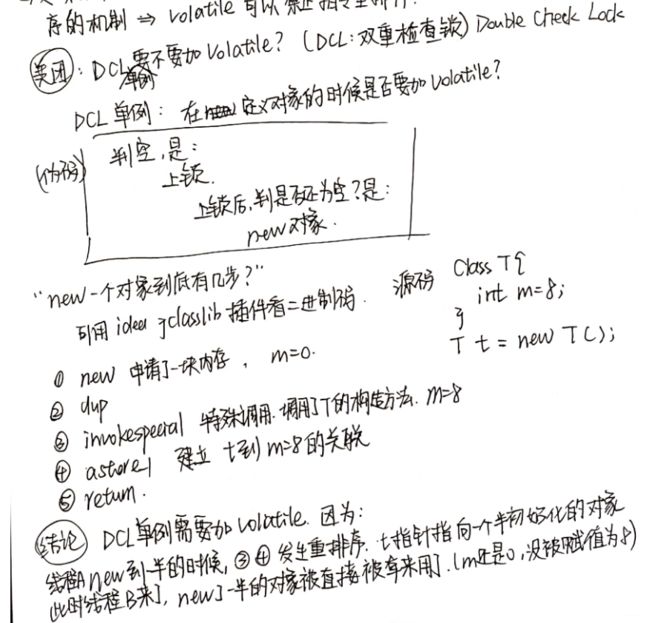
如何禁止乱序
CPU层面:
(1)使用原语
Intel CPU 的实现方式是,使用原语(汇编指令mfence lfence sfence 或者锁总线(都属于硬件实现)

(2)Intel lock 汇编指令

JVM层面
因为不是所有的CPU都有汇编指令的实现,因此JVM在实现的时候使用的是lock指令。
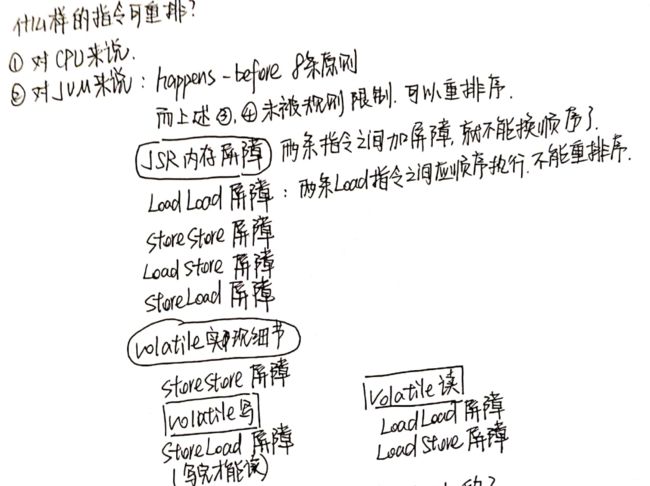
JVM层级:8个hanppens-before原则、4个内存屏障 (LL LS SL SS)
名词as-if-serial 的含义: 不管硬件什么顺序,单线程执行的结果不变,看上去就像是顺序执行的一样。
拓展:很多请求打进来,如果想要顺序执行,可以使用SingleThreadPool。为了避免内存溢出,有界队列满了可以采取拒绝策略 。
JVM在写操作和读操作前后都加了屏障。而屏障的实现,就是使用lock指令。
合并写技术 Write Combining
寄存器和L1缓存之间还有一个buffer,空间特别小。另外还有一个WC(Write Combining)Buffer,一般是4个字节
由于ALU速度太快,所以在写入L1的同时,写入一个WC Buffer,满了之后,写满4个字节之后,才会一次性刷到缓存L2里。可以用程序证明。
证明 WC 的存在:
package com.mashibing.juc.c_029_WriteCombining;
public final class WriteCombining {
private static final int ITERATIONS = Integer.MAX_VALUE;
private static final int ITEMS = 1 << 24;
private static final int MASK = ITEMS - 1;
private static final byte[] arrayA = new byte[ITEMS];
private static final byte[] arrayB = new byte[ITEMS];
private static final byte[] arrayC = new byte[ITEMS];
private static final byte[] arrayD = new byte[ITEMS];
private static final byte[] arrayE = new byte[ITEMS];
private static final byte[] arrayF = new byte[ITEMS];
public static void main(final String[] args) {
for (int i = 1; i <= 3; i++) {
System.out.println(i + " SingleLoop duration (ns) = " + runCaseOne());
System.out.println(i + " SplitLoop duration (ns) = " + runCaseTwo());
}
}
public static long runCaseOne() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
}
return System.nanoTime() - start;
}
public static long runCaseTwo() { // 一次正好写满一个四字节的 Buffer,比上面的循环效率更高
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
}
i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
}
return System.nanoTime() - start;
}
}
非同一访问内存 NUMA
UMA:同一内存访问。多个CPU通过一条总线,访问同一个内存。
现在很多服务器的架构是使用NUMA的,因为UMA不以拓展:随着CPU的数量增多,许多时间被浪费在CPU争抢内存资源上。
NUMA:非同一访问内存。每个CPU有自己专属的内存,CPU对于自己插槽上的内存访问是有优先级的。
ZGC 可以做到 NUMA aware,如果探测到计算机实现了NUMA的话,分配内存会优先分配该线程所在CPU的最近内存。