Cinder-Volume如何实现AA高可用——分布式锁以及在Openstack上的应用
作者简介
付广平,云极星创研发工程师,从事Nova、Cinder研发工作,Openstack代码贡献者。北京邮电大学硕士毕业,曾先后在华为北研所2012实验室、英特尔中国研究院,以及阿里巴巴技术保障部实习,从事大数据和云计算相关工作。
责编:孙浩峰,关注云计算、大数据、运维、安全等领域,寻求报道或者投稿请发邮件至[email protected]。
锁(Lock),在我们生活当中再熟悉不过了,它的主要作用就是锁住某个物体或者某个区域空间,一方面阻止无锁者进入查看受隐私保护的东西,二来阻止恶意者实施破坏。比如我们都会对手机加锁来防止别人偷窥自己的隐私,我们通过锁门来阻止坏人进入家里偷窃等等。
在计算机的世界,锁同样重要,并且功能和我们生活当中的锁基本是一样的,只是管理的对象不一样而已。计算机的锁是为了锁住某个计算机资源或者数据,不允许其他用户或者进程随意访问读取,或者保护数据不被其他程序恶意篡改。除此之外,锁还具有同步的功能,即保证A任务完成之后才能执行B任务,而不能顺序颠倒,也不能在A完成到一半时,B就开始执行。
我们的服务器几乎都是使用多用户分时操作系统,这意味着同一时间有多个用户执行多个进程并且同时运行着,即使是同一进程,也有可能包含有多个线程跑着。如果我们不对一些互斥访问的资源进行加锁,势必会乱套,试想下同时多个程序不加控制的使用同一台打印机会造成什么恶果。除了资源,对数据的加锁保护也同样重要,如果没有锁,数据就会各种紊乱,比如你的记账管理系统,开始总额有5000元,入账5000元,此时总额应该就有10000元了,但还没有来得及更新到数据库中去,此时,你的另一个进程开始读取总额,由于之前入账的5000块还没有更新,取出来的总额还是原来的5000元,显然读取的这5000元是过时的老数据,在操作系统术语中称为脏数据。更诡秘的是,此时你的第二个进程开始出账3000块,此时开始写入剩余总额2000元。此时你的两个进程可能同时在写数据,假设你的进程一先写完(写入10000),你的第二个进程写入2000元覆盖掉了刚刚写入的10000元,最后你的总额为2000元,你刚刚入账的5000元莫名其妙地蒸发了。以上情况就是事务处理中ACID的数据不一致性问题。
阅读本文读者只需要知道锁的作用即可,更多关于并发控制的有关概念(比如幻读、不可重复读、原子性、持久性等)以及各种锁的概念(互斥锁、共享锁、乐观锁、悲观锁、死锁等)不是本文讨论的重点,感兴趣的读者请自行Google之。
锁的实现的非权威解读
生活当中的锁原理其实很简单,传统的机械锁可以当作是一种机关,通过匹配形状齿轮触发机关某个部位而解锁。而现代的锁原理更简单,加锁其实就是设置一种状态,而要解除该状态只需要比对信息,比如数字密码、指纹等。
计算机中的锁,根据运行环境可以大体分为以下三类:
•同一个进程。此时主要管理该进程的多个线程间同步以及控制并发访问共享资源。由于进程是共享内存空间的,一个最简单的实现方式就是使用一个整型变量作为flag,这个flag被所有线程所共享,其值为1表示已上锁,为0表示空闲。使用该方法的前提是设置(set)和获取(get)这个flag变量的值都必须是原子操作,即要么成功,要么失败,并且中间不允许有中断,也不允许出现中间状态。可幸的是,目前几乎所有的操作系统都提供了此类原子操作,并已经引入了锁机制,所以以上前提是可以满足的。
•同一个主机。此时需要控制在同一个操作系统下运行的多个进程间如何协调访问共享资源。不同的进程由于不共享内存空间,因此不能通过设置变量来实现。既然内存不能共享,那磁盘是共享的,因此我们自然想到可以通过创建一个文件作为锁标记。进程只需要检查文件是否存在来判断是否有锁。
•不同主机。此时通常跑的都是分布式应用,如何保证不同主机的进程同步和避免资源访问冲突。有了前面的例子,相信很多人都想到了,使用共享存储不就可以了,这样不同主机的进程也可以通过检测文件是否存在来判断是否有锁了。[机智表情]
以上介绍了锁的非权威实现,为了解释得更简单通俗,其实隐瞒了很多真正实现上的细节,甚至可能和实际的实现方式并不一致。要想真正深入理解操作系统的锁机制以及单主机的锁机制实现原理,请查阅更多的文献。本文接下来将重点讨论分布式锁,也就是前面提到的不同主机的进程间如何实现同步以及控制并发访问资源。
分布式锁以及DLM
分布式锁主要解决的是分布式资源访问冲突的问题,保证数据的一致性。前面提到使用共享存储文件作为锁标记,这种方案只有理论意义,实际上几乎没有人这么用,因为创建文件并不能保证是原子操作。另一种可行方案是使用传统数据库存储锁状态,实现方式也很简单,检测锁时只需要从数据库中查询锁状态即可。当然,可能使用传统的关系型数据库性能不太好,因此考虑使用KV-Store缓存数据库,比如Redis、Memcached等。但都存在问题:
•不支持堵塞锁。即进程获取锁时,不会自己等待锁,只能通过不断轮询的方式判断锁的状态,性能不好,并且不能保证实时性。
•不支持可重入。所谓可重入锁就是指当一个进程获取了锁时,在释放锁之前能够无限次重复获取该锁。试想下,如果锁是不可重入的,一个进程获取锁后,运行过程中若再次获取锁时,就会不断循环获取锁,可实际上锁就在自己的手里,因此将永久进入死锁状态。当然也不是没法实现,你可以顺便存储下主机和进程ID,如果是相同的主机和进程获取锁时则自动通过,还需要保存锁的使用计数,当释放锁时,简单的计数-1,只有值为0时才真正释放锁。
另外,锁需要支持设置最长持有时间。想象下,如果一个进程获取了锁后突然挂了,如果没有设置最长持有时间,锁就永远得不到释放,成为了该进程的陪葬品,其他进程将永远获取不了锁而陷入永久堵塞状态,整个系统将瘫痪。使用传统关系型数据库可以保存时间戳,设置失效时间,实现相对较复杂。而使用缓存数据库,通常这类数据库都可以设置数据的有效时间,因此相对容易实现。不过需要注意不是所有的场景都适合通过锁抢占方式恢复,有些时候事务执行一半挂了,也不能随意被其他进程强制介入。
支持可重入和设置锁的有效时间其实都是有方法实现,但要支持堵塞锁,则依赖于锁状态的观察机制,如果锁的状态一旦变化就能立即通知调用者并执行回调函数,则实现堵塞锁就很简单了。庆幸的是,分布式协调服务就支持该功能,Google的Chubby就是非常经典的例子,Zookeeper是Chubby的开源实现,类似的还有后起之秀Etcd等。这些协调服务有些类似于KV-Store,也提供get、set接口,但也更类似于一个分布式文件系统。以Zookeeper为例,它通过瞬时有序节点标识锁状态,请求锁时会在指定目录创建一个瞬时节点,节点是有序的,Zookeeper会把锁分配给节点最小的服务。
Zookeeper支持watcher机制,一旦节点变化,比如节点删除(释放锁),Zookeeper会通知客户端去重新竞争锁,从而实现了堵塞锁。另外,Zookeeper支持临时节点的概念,在客户进程挂掉后,临时节点会自动被删除,这样可实现锁的异常释放,不需要给锁增加超时功能了。
以上提供锁服务的应用我们通常称为DLM(Distributed lock manager),对比以上提到的三种类型的DLM:
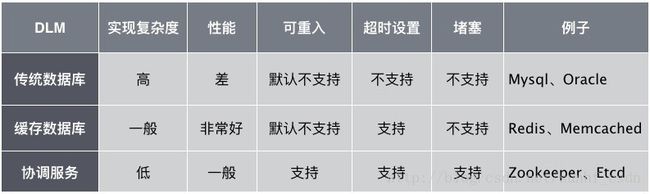
注: 以上支持度仅考虑最简单实现,不涉及高级实现,比如传统数据库以及缓存数据库也是可以实现可重入的,只是需要花费更多的工作量。
OpenStack Tooz为何而生?
前面介绍了很多实现分布式锁的方式,但也只是提供了实现的可能和思路,而并未达到拿来即用的地步。开发者仍然需要花费大量的时间完成对分布式锁的封装实现。使用不同的后端,可能还有不同的实现方式。如果每次都需要重复造轮子,将浪费大量的时间,并且质量难以保证。
你一定会想,会不会有人已经封装了一套锁管理的库或者框架,只需要简单调用lock、trylock、unlock即可,不用关心底层内部实现细节,也不用了解后端到底使用的是Zookeeper、Redis还是Etcd。Curator库实现了基于Zookeeper的分布式锁,但不够灵活,不能选择使用其他的DLM。OpenStack社区为了解决项目中的分布式问题,开发了一个非常灵活的通用框架,项目名为Tooz,它实现了非常易用的分布式锁接口,本文接下来将详细介绍该项目。
Tooz是一个python库,提供了标准的coordination API。最初由eNovance几个工程师编写,其主要目标是解决分布式系统的通用问题,比如节点管理、主节点选举以及分布式锁等,更多Tooz背景可参考Distributed group management and locking in Python with tooz。Tooz抽象了高级接口,支持对接十多种DLM驱动,比如Zookeeper、Redis、Mysql、Etcd、Consul等,其官方描述为:
The Tooz project aims at centralizing the most common distributed primitives like group membership protocol, lock service and leader ?election by providing a coordination API helping developers to build distributed applications.
使用Tooz也非常方便,只需要三步:
1与后端DLM建立连接,获取coordination实例。
2声明锁名称,创建锁实例
3使用锁
官方给出了一个非常简单的实例,如下:
coordinator = coordination.get_coordinator('zake://', b'host-1')
coordinator.start()
#Create a lock
lock = coordinator.get_lock("foobar")
with lock:
...
print("Do something that is distributed")
coordinator.stop()由于该项目最先是由Ceilometer项目Core开发者发起的,因此Tooz最先在Ceilometer中使用,主要用在alarm-evaluator服务。目前Cinder也正在使用该库来实现Cinder-volume的Active/Active高可用,将在下文重点介绍。
Cinder的“硬伤”与“进化”
Cinder是OpenStack的核心组件之一,为云主机提供可扩展可伸缩的块存储服务,用于管理volume数据卷资源,类似于AWS的EBS服务。cinder-volume服务是Cinder最关键的服务,负责对接后端存储驱动,管理volume数据卷生命周期,它是真正干活的服务。
显然volume数据卷资源也需要处理并发访问的冲突问题,比如防止删除一个volume时,另一个线程正在基于该volume创建快照,或者同时有两个线程同时执行挂载操作等。cinder-volume也是使用锁机制实现资源的并发访问,volume的删除、挂载、卸载等操作都会对volume加锁。在OpenStack Newton版本以前,Cinder的锁实现都是基于本地文件实现的,该方法在前面已经介绍过,只不过并不是根据文件是否存在来判断锁状态,而是使用了Linux的flock工具进行锁管理。Cinder执行加锁操作默认会从配置指定的lockpath目录下创建一个命名为cinder-volume_uuid-{action}的空文件,并对该文件使用flock加锁。flock只能作用于同一个操作系统的文件锁,即使使用共享存储,另一个操作系统也不能判断是否有锁,一句话说就是Cinder使用的是本地锁。
我们知道OpenStack的大多数无状态服务都可以通过在不同的主机同时运行多个实例来保证高可用,即使其中一个服务挂了,只要还存在运行的实例就能保证整个服务是可用的,比如nova-api、nova-scheduler、nova-conductor等都是采用这种方式实现高可用,该方式还能实现服务的负载均衡,增加服务的并发请求能力。而极为不幸的是,由于Cinder使用的是本地锁,导致cinder-volume服务长期以来只能支持Active/Passive(主备)HA模式,而不支持Active/Active(AA,主主)多活,即对于同一个backend,只能同时起一个cinder-volume实例,不能跨主机运行多个实例,这显然存在严重的单点故障问题,该问题一直以来成为实现Cinder服务高可用的痛点。
因为cinder-volume不支持多实例,为了避免该服务挂了导致Cinder服务不可用,需要引入自动恢复机制,通常会使用pacemaker来管理,pacemaker轮询判断cinder-volume的存活状态,一旦发现挂了,pacemaker会尝试重启服务,如果依然重启失败,则尝试在另一台主机启动该服务,实现故障的自动恢复。该方法大多数情况都是有效的,但依然存在诸多问题:
•在轮询服务状态间隔内挂了,服务会不可用。即不能保证服务的连续性和服务状态的实时性。
•有时cinder-volume服务启动和停止都比较慢,导致服务恢复时间较长,甚至出现超时错误。
•不支持负载均衡,极大地限制了服务的请求量。
•有时运维不当或者pacemaker自身问题,可能出现同时起了两个cinder-volume服务,出现非常诡秘的问题,比如volume实例删不掉等。
总而言之,cinder-volume不支持Active/Active HA模式是Cinder的一个重大缺陷。
玩过三国杀的都知道,很多武将最开始都比较脆弱,经过各种虐杀后会触发觉醒技能,又如pokemon完成一次进化,变得异常强大。cinder-volume不支持AA模式一直受人诟病,社区终于在Newton版本开始讨论实现cinder-volume的AA高可用,准备引入分布式锁替代本地锁,这可能意味着Cinder即将完成一次功能突发变强的重大进化。
Cinder引入分布式锁,需要用户自己部署和维护一套DLM,比如Zookeeper、Etcd等服务,这无疑增加了运维的成本,并且也不是所有的存储后端都需要分布式锁。社区为了满足不同用户、不同场景的需求,并没有强制用户部署固定的DLM,而是采取了非常灵活的可插除方式,使用的正是前面介绍Tooz库。当用户不需要分布式锁时,只需要指定后端为本地文件即可,此时不需要部署任何DLM,和引入分布式锁之前的方式保持一致,基本不需要执行大的变更。当用户需要cinder-volume支持AA时,可以选择部署一种DLM,比如Zookeeper服务。
Cinder对Tooz又封装了一个单独的coordination模块,其源码位于cinder/coordination.py,需要使用同步锁时,只需要在函数名前面加上@coordination.synchronized装饰器即可(有没有突然想到Java的synchronized关键字 ),方便易用,并且非常统一,而不像之前一样,不同的函数需要加不同的加锁装饰器。比如删除volume操作的使用形式为:
@coordination.synchronized('{volume.id}-{f_name}')
@objects.Volume.set_workers
def delete_volume(self, context, volume, unmanage_only=False,
cascade=False):
...为了便于管理多存储后端,Cinder同时还引入了cluster的概念,对于使用同一存储后端的不同主机置于一个cluster中,只有在同一个cluster的主机存在锁竞争,不同cluster的主机不存在锁竞争。
不过截至到刚刚发布的Ocata版本,cinder-volume的AA模式还正处于开发过程中,其功能还没有完全实现,还不能用于生产环境中部署。我们期待cinder-volume能够尽快实现AA高可用功能,云极星创也会持续关注该功能的开发进度,并加入社区,与更多开发者一起完善该功能的开发。
参考文献
1.Building a Distributed Lock Revisited: Using Curator’s InterProcessMutex.
2.Distributed lock manager.
3.并发控制.
4.Ocata Series Release Notes.
5.Distributed group management and locking in Python with tooz.
6.Cinder Volume Active/Active support - Manager Local Locks.
7.etcd API: Waiting for a change.
8.The Chubby lock service for loosely-coupled distributed systems.
9.OpenStack中tooz介绍及实践.
10.A Cinder Road to Active/Active HA.