yolov3训练自己的数据集——第一次实操完整记录
参考:
yolov3
darknet
yolo源码解析
bacth参数对性能影响
backpropogation算法
yolo中7*7个grid和rpn中的9个anchors
darknet源码学习
小知识点
- make -j4 表示用4条线程编译(对应自己的电脑,看自己电脑cpu几核几线程)
- make -j32 用32线程编译
- CNN卷积神经网络更新权值共有两步:第一:求梯度。第二:梯度下降。
- 现在backprop就是指上面讲到的更新权值的第一步:求梯度。(链式法则)
- 之所以可以链式法则是因为梯度直观上理解就是一阶近似。所以梯度可以理解为某个变量或者某个中间变量对输出影响的敏感度系数。神经网络中的链式法则几乎都是高维的。
- 现在在大部分主流深度学习框架中的求导都是基于computational graph。computational graph是计算代数中很基础的方法。从计算机的角度看有动态规划的意思。优点是表达式给定的情况下对复合函数中所有变量快速求导。
darknet源码解析
darknet概述
darknet是一个轻型的、完全基于C与CUDA的开源深度学习框架,支持CPU和GPU两种计算方式。
darknet优点
- 完全由c语言实现,没有任何依赖项,只有CUDA。连opencv都可以不用。当然也可以使用opencv,目的是用其来显示图片,为了更好可视化。如果在CPU平台cuda都可以扔了(当然darknet的cup代码并没有做什么优化,跑起来就很慢)。这样可以很easy的将代码移植到其他平台。
- 框架轻型、灵活。(虽然没有tensorflow那么多强大的API)
- darknet的实现与caffe存在相似。
darknet缺点
- 在darknet中,所有层的lr都一样,这对微调造成了很大的困难,因为微调需要把前面几层的lr都设置的很小很小,然后主要训练最后一层的权重。
- darknet的接口很差,想把网络改成inception或者resnet的构架,需要改大量的代码,这对于验证模型可行性来说,非常浪费时间。所以才会把代码移植到mxnet或者caffe上,然后在mxnet上做模型压缩了。
darknet源码总结
- darknet中最重要的三个struct定义是network_state network layer。新版本network_state并入到了network中去。
- 不同种类的网络层都是通过layer里面的函数指针forward backward和update定义本种类的执行规则。如connected_layer就有forward_connected_layer、backward_connected_layer、update_connected_layer三个方法。
- 原子运算只在blas.c和gemm.c,网络的运算在network.c中。最重要的是train_network_datum、train_networks、train_network_batch和network_predict。
- train_network_datum是输入数据用float_pair,就是floatx,floaty结对。
- train_networks是在network_kernel.cu里,以并发线程方式训练,参数是data。
- train_network_datum顺序执行forward_network(逐层正向网络),backward_network逐层逆向网络,满足次数下(*net.seen %subdivisions)执行一次update_network(rate,momentum,decay)
- 对于用户定义的网络参数文件处理在parse_network_cfg。读入训练结果通过load_weights。
- 如果需要参考特别需求的数据源,需要参考data.c入手。
- 对于cfg配置文件,训练时调整重点的全局参数:decay_momentum_rate这三个是与收敛速度有关的。policy是weights策略的,input batch(及相关的subdivisons)。outputs是与数据吞吐维度相关的。
yolov3算法思路概述
- 如上图所示:在训练过程中对于每幅输入图像,yolov3会预测三个不同大小的3D tensor,对应着三个不同的scale,设计这三个scale的目的是为了能检测出不同大小的物体。
- 这里以13 * 13的tensor为例,对于这个scale,原始输入图像会被分割成13 × 13的grid cell,每个grid cell对应着3D tensor中的1x1x255这样一个长条形voxel。255是由3x(4+1+80)而来,由上图可知,公式NxNx[3x(4+1+80)]中NxN表示的是scale size例如上面提到的13x13。3表示的是each grid predict 3 boxes。4表示的是坐标值即(tx,ty,tw,th)。1表示的是置信度,80表示的是类别数目。
- 如果训练集中某一个ground truth对应的bounding box中心恰好落在了输入图像的摸一个grid cell中,那么这个grid cell就负责预测此物体的bounding box,于是这个grid cell所对应的置信度为1,其他grid cell的置信度为0.每个grid cell都会被赋予3个不同大小的prior box,学习过程中,这个grid cell会学会如何选择哪个大小的prior box。作者定义的是只选择与ground truth bounding box的IOU重合度最高的prior box。
- 上面说到的三个预设的不同大小的prior box,这三个大小是如何计算的,首先在训练前,将coco数据集中的所有bbox使用k-means clustering分成9个类别,每3个类别对应一个scale,故总共3个scale,这种关于box大小的先验信息帮助网络准确预测每个box的offset和coordinate。从直观上,大小合适的box会使得网络更精准的学习。
batch参数对性能的影响
- batch_size批尺寸。
- bacth的选择首先决定的是下降的方向。
- 若是小数据集,则可以采用全数据集的形式,即full batch learning。好处有两个:
(1)由全数据集确定的方向能更好的代表样本总体,从而更准确的朝向极值所在的地方。
(2)由于不同权重的梯度值差别巨大,因此选取一个全局的学习率很困难。
综上,full batch learning可以使用Rprop只基于梯度符号并且针对性单独更新各权值。 - 对于更大数据集,上面提到的两个优点变成了两个缺点:
(1)数据集的海量增长和内存限制,一下子导入全部数据不现实。
(2)以Rprop方式迭代,会由于各个batch之间的采样差异性,各次梯度值相互抵消,无法修正。所以后面有了RMSProp的妥协方案。 - 每次只训练一个样本即batch_size=1。即在线学习。
- 线性神经元在均方误差代价函数的错误面是一个抛物面,横截面是椭圆。对于多层神经元、非线性网络,在局部依然近似是抛物面使用在线学习每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政,难以达到收敛。如下图:
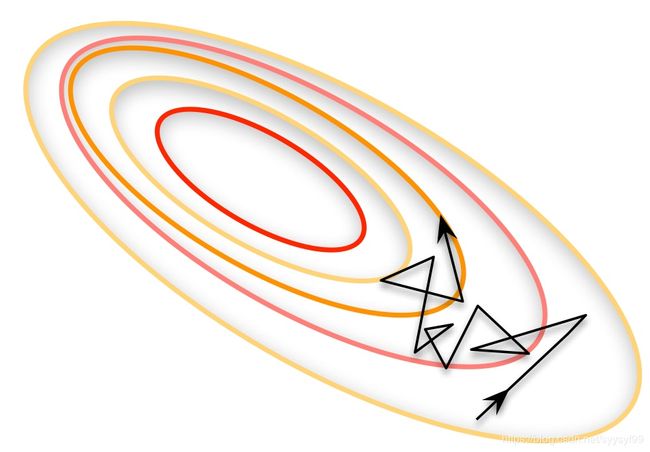
- 综上所以需要选择一个恰当的适中的batch_size值,批梯度下降法(mini_bacthes learning)。使用这个方法,只要数据量充足,那么用一半(甚至少的多的数据量)训练计算出来的梯度与用全部数据量训练计算出来梯度值几乎一样。
- 在合理范围内,增大batch_size的好处:
(1)内存利用率提高了,大矩阵乘法的并行化效率提高。
(2)跑完一次epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
(3)一定范围内,一般来说bacth_size太大,其确定的下降方向越准,引起训练震荡越小。 - 盲目增大batch_size的坏处:
(1)内存利用率提高,但是内存容量遭不住。
(2)跑完一次epoch(全数据集)所需的迭代次数减小,要想达到相同的精度,其所需的时间大大增加,从而对参数的修正也会更加缓慢。
(3)batch_size增加到一定程度,其确定的下降方向也会不再改变。
(4)如今随着batch normalization的普及,收敛速度已经不再像之前那样需要玄学调参了,现在一般都采取大的batch_size,毕竟有了GPU。batch normalization的坏处就是不能用太小的batch_size,要不然mean和variance就偏了。现在就是显存能放多少就放多少,实际调模型时,数据分布和预处理最重要,数据不行的话再多花招都没用。
yolo中的7*7个grid和PRN中的9个anchors
grid和anchors的唯一作用是为了计算IOU,从而确定正负样本。
其他的detection system
- Deformable parts models(DPM):深度神经网络之前,早期的object detecction是通过提取图像的一些robust特征,例如Haar SIFT HOG等特征。使用DPM模型,用sliding window方式预测具有较高score的bounding box。DPM模型把物体看成了多个组成的部件(例如人脸的鼻子、嘴巴等)。用部件间的关系来描述物体,这个特性符合自然界很多物体的非刚体特性。DPM可以看做是HOG+SVM的扩展,继承了两者的优点,在人脸检测和行人检测上效果很好,但是DPM检测速度很慢。
- R-CNN系列,包括:R-CNN SPP-net Fast R-CNN Faster R-CNN R-FCN等经典网络。
- Deep Multibox:训练一个卷积神经网络来预测感兴趣的区域,而不是使用Selective Saerch的方法直接获得候选区,yolo也是通过训练一个cnn来预测一个bounding box。相比Multibox,yolo是一个完整的系统。
- OverFeat:用CNN统一做分类、定位和检测。使用CNN做早期工作,采用多尺度滑动窗口来分类、定位和检测。OverFeat可以看做是R-CNN的特殊情况,只需要把selective search换成多尺度的滑动窗口,每个类别的边框回归器换成统一的边框回归器,SVM换成多层网络即可。但是OverFeat比R-CNN快9倍,得益于卷积相关的共享计算。
- MultiGrasp:yolo的设计与MutiGrasp相似。但是MultiGrasp主要用于grasp detection,这个任务比object detection简单很多。对于一张包含单个物体的image,Multigrasp只需要预测一个单一的graspable region,且不需要预估object的位置、大小、边界,也不需要预测object属于哪个class。但是yolo的任务需要预测bounding box和概率,对于每个bounding box需要回归(x,y,w,h)和置信度(confidence),而且是多目标、多类别的图像。
实操过程完整记录
对于darknet文件夹,在实践过程中,主要修改的文件有:
- Makefile
- ./cfg目录下的参数配置文件
- ./data目录下的数据
第一步
在自己的指定目录下下载,终端输入
git clone https://github.com/pjreddie/darknet.git
第二步
修改Makefile。GPU环境下的编译配置都是在/darknet/Makefile/中定义的。终端输入
cd darknet
gedit Makefile
在打开的文本上最前面修改
GPU=1
CUDNN=1
OPENCV=1
表示使用GPU CUDNN OPENCV。
更改ARCH配置,根据自己的GPU型号来定。我的GPU是华硕 RTX 2060,计算能力是,GTX1080的计算能力是6.1。故更改为如下:吧前面几行语句注释掉,只保留值为52的那个。
ARCH= # -gencode arch=compute_30,code=sm_30 \
# -gencode arch=compute_35,code=sm_35 \
# -gencode arch=compute_50,code=[sm_50,compute_50] \
-gencode arch=compute_52,code=[sm_52,compute_52]
compute_30表示显卡的计算能力是3.0。
在Makefile51行,有cuda的安装路径,这里指的路径不是你下载安装包时的路径,而是系统自己存放的cude文件夹和cuda软链接文件夹的路径,在其他位置——计算机——usr——local中。所以是不需要修改makefile文件夹中的cuda安装路径,默认就是与系统实际相匹配的。
注意:每次修改完makefile都要重新Make一下才能生效。
第三步
编译,我的cpu是i7-8700,是12线程的6核的,所以使用指令j12,每次使用make指令时都要加上j12,会加快编译速度。终端输入:
make -j12
到这一步时遇到错误,这个错误是在darknet目录下执行make指令显示的错误。显示内容如下:
./src/image_opencv.cpp:5:10: fatal error: opencv2/opencv.hpp: 没有那个文件或目录
#include "opencv2/opencv.hpp"
compilation terminated.
Makefile:86: recipe for target 'obj/image_opencv.o' failed
make: *** [obj/image_opencv.o] Error 1
make: *** 正在等待未完成的任务....
出现上面错误的原因是之前我安装的opencv是python的,即opencv_python。这里模型的训练需要用到c++的opencv。所以这里再装一遍opencv。
我在官网上选择的opencv4.1.0安装的opencv4.1.0
git clone https://github.com/opencv/opencv.git
然后
cd opencv
sudo pip3 install cmake #如果已经安装过cmake,则该步骤省略
#安装依赖库
sudo apt-get install build-essential libgtk2.0-dev libavcodec-dev libavformat-dev libjpeg-dev libswscale-dev libtiff5-dev:i386 libtiff5-dev
创建一个编译文件夹并且进入
mkdir build
cd build/
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local/opencv4 ..
上面的指令修改安装路径到/usr/local/opencv4,可以自己修改到自己需要的位置,如果该命令中不加-D CMAKE_INSTALL_PREFIX=/usr/local/opencv4,则默认各部分分别安装在/usr/local/目录的include/ bin/ lib/3个文件夹下。注意上面指令路径后面还有两个点。
在终端上输入命令时tab键具有补全功能。
会下载ippicv,需要等待比较长时间才能下载完成。
然后进行make编译,需要很久。
make -j12
make编译指令不需要再前面添加sudo,这样的创建的一些文件就需要sudo权限。
进行make install安装
sudo make install
安装完成,配置opencv编译环境。
sudo gedit /etc/ld.so.conf.d/opencv.conf
在打开的空文件末尾添加上:
/usr/local/opencv4/lib
终端输入使配置的路径生效
sudo ldconfig
环境配置完成,进行测试,进入到opencv/samples/cpp/example_cmake目录下。因为更改了opencv的安装路径,所以这里测试前需要CMakeLists.txt文件的14行find_package(OpenCV REQUIRED)前面加上
set(OpenCV_DIR /usr/local/opencv4/lib/cmake/opencv4)
终端在opencv/samples/cpp/example_cmake目录下执行:
cmake .
注意cmake后面有一个点
接着在终端输入
make -j12
输入
./opencv_example
正常结果是:电脑打开了摄像头,在摄像头采集到的图片左上角出现hello opencv字样,即配置成功。
若电脑没有摄像头,则另一种检测方法是终端输入:
python3
import cv2
cv2.__version__
配置成功的结果是显示出opencvz的版本号,注意指令version前后都是有两个_符号。
安装完成opencv4.1.0后,在darknet下编译还是有和之前一样的错误,故使用另一种方法:卸载该版本的opencv,software/opencv/build路径下(从github下载包的路径,不是后来的安装路径)终端输入:因为在这个路径下存在文件cmake_uninstall.cmake。
sudo make uninstall
然后再把local安装路径下和software下载包的路径下把opencv4的文件全部删除。
local文件夹下的需要sudo来删除文件夹。
sudo rm -r opencv4
终端重新安装opencv3.4.6。
同样的安装步骤,这次成功了,原因并不是之前猜测的opencv版本的原因,而是需要创建软链接来解决。(但是有时安装是不用创建软链接的,但是这次这里需要,缺失的步骤是在安装cudnn时,在终端执行完两条如下的cp指令即copy操作后,还需要添加上执行软链接操作)
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
具体的解决办法,添加的软链接语句见安装cudnn笔记
经历过上面的错误后,总结出的在安装上的一个建议是:
如果不会创建软链接,不会在文档中添加各个文件的path,就最好安装在默认路径下,不要像上面一样再自行创建新的文件夹来存储,这里创建的是usr/local/opencv4。
安装成功的步骤如下,与上面的步骤大部分一致。安装的是opencv-3.4.6
~/software/opencv-3.4.6$ mkdir build
~/software/opencv-3.4.6$ cd build/
#这一条指令有变化,没有再自行创建opencv文件夹了
~/software/opencv-3.4.6/build$ cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local ..
~/software/opencv-3.4.6/build$ make -j16
~/software/opencv-3.4.6/build$ sudo make install
~/software/opencv-3.4.6/build$ sudo ldconfig
#注意,这条指令之后出现问题,显示如下
/sbin/ldconfig.real: /usr/local/cuda-10.1/targets/x86_64-linux/lib/libcudnn.so.7 不是符号链接
下面的几条语句就是在安装cudnn时缺少的创建软链接的指令
~/software/opencv-3.4.6/build$ cd /usr/local/cuda-10.1/
/usr/local/cuda-10.1$ cd lib64
/usr/local/cuda-10.1/lib64$ ls libcudnn.*
#执行后显示
libcudnn.so libcudnn.so.7 libcudnn.so.7.6.1
#接着输入
/usr/local/cuda-10.1/lib64$ rm libcudnn.so libcudnn.so.7
#执行后显示
rm:是否删除有写保护的普通文件 'libcudnn.so'? ^C
#接着输入
#添加sudo权限来删除
/usr/local/cuda-10.1/lib64$ sudo rm libcudnn.so libcudnn.so.7
/usr/local/cuda-10.1/lib64$ sudo ln -sf libcudnn.so.7.6.1 libcudnn.so.7
/usr/local/cuda-10.1/lib64$ sudo ln -sf libcudnn.so.7 libcudnn.so
上面三条两条创建软链接指令的解释:
ln命令的功能是为某个文件在另外一个位置建立一个同步的链接,这个命令最常用的参数是-s,具体用法是:ln –s 源文件 目标文件。
当需要在不同的目录用到相同文件时,不需要在每个需要的目录下都放一个相同的文件,只要在某个固定的目录,放上该文件,然后在其它的目录下用ln命令链接(link)它就可以,不必重复的占用磁盘空间。
例如上面用到的:
ln -sf libcudnn.so.7 libcudnn.so
解释:
-s 是代号(symbolic)的意思。对源文件建立符号连接,而非硬连接。
-f或–force 强行建立文件或目录的连接,不论文件或目录是否存在。
这里使用的是两者的叠加-sf。
分析完毕,最后在终端上接着上面的两条创建软链接指令后输入下面一条语句就完成了。
/usr/local/cuda-10.1/lib64$ sudo ldconfig
进入software/darknet目录下,终端输入编译语句,不再出现错误。
make -j12
安装过程有参考该链接
第四步
下载预训练模型。
cd darknet
wget https://pjreddie.com/media/files/yolov3.weights
第五步
修改网络配置文件。修改darknet/cfg/yolov3.cfg,如下,注释掉Training参数,取消注释Testing参数。
终端输入:
cd cfg
gedit yolov3.cfg
打开的文本中修改如下
#Testing
batch=1
subdivisions=1
#Training
#batch=64
#subdivisions=16
第六步 基于 yolo.weights 模型参数来测试单张图片
单张图像检测。运行探测器指令,这是单张图片的测试命令
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
备注:上面的指令要在darknet文件夹路径下的终端运行。
cd darknet
make
编译成功后会生成一个darknet可执行文件,执行./darknet就可以运行。可以修改Makefile的参数,但是注意每次修改都要重新make一下。
指令的解释:
./darknet 是执行当前文件下面已经编译好的darknet文件;
detect 是命令;
后面三个分别是参数;
参数cfg/yolov3.cfg表示网络模型;
参数yolov3.weights表示网络权重;
参数data/dog.jpg表示需要检测的图片。
上面的指令等同于下面的指令,一般使用上面的指令,更简洁。如果是训练情况下,则把下面命令中的test换为train。即detector train
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
运行后会看到这样的输出:
layer filters size input output
0 conv 32 3 x 3 / 1 608 x 608 x 3 -> 608 x 608 x 32 0.639 BFLOPs
1 conv 64 3 x 3 / 2 608 x 608 x 32 -> 304 x 304 x 64 3.407 BFLOPs
2 conv 32 1 x 1 / 1 304 x 304 x 64 -> 304 x 304 x 32 0.379 BFLOPs
3 conv 64 3 x 3 / 1 304 x 304 x 32 -> 304 x 304 x 64 3.407 BFLOPs
4 res 1 304 x 304 x 64 -> 304 x 304 x 64
5 conv 128 3 x 3 / 2 304 x 304 x 64 -> 152 x 152 x 128 3.407 BFLOPs
6 conv 64 1 x 1 / 1 152 x 152 x 128 -> 152 x 152 x 64 0.379 BFLOPs
7 conv 128 3 x 3 / 1 152 x 152 x 64 -> 152 x 152 x 128 3.407 BFLOPs
8 res 5 152 x 152 x 128 -> 152 x 152 x 128
9 conv 64 1 x 1 / 1 152 x 152 x 128 -> 152 x 152 x 64 0.379 BFLOPs
10 conv 128 3 x 3 / 1 152 x 152 x 64 -> 152 x 152 x 128 3.407 BFLOPs
11 res 8 152 x 152 x 128 -> 152 x 152 x 128
12 conv 256 3 x 3 / 2 152 x 152 x 128 -> 76 x 76 x 256 3.407 BFLOPs
13 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs
14 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
15 res 12 76 x 76 x 256 -> 76 x 76 x 256
16 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs
17 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
18 res 15 76 x 76 x 256 -> 76 x 76 x 256
19 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs
20 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
21 res 18 76 x 76 x 256 -> 76 x 76 x 256
22 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs
23 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
24 res 21 76 x 76 x 256 -> 76 x 76 x 256
25 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs
26 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
27 res 24 76 x 76 x 256 -> 76 x 76 x 256
28 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs
29 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
30 res 27 76 x 76 x 256 -> 76 x 76 x 256
31 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs
32 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
33 res 30 76 x 76 x 256 -> 76 x 76 x 256
34 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs
35 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
36 res 33 76 x 76 x 256 -> 76 x 76 x 256
37 conv 512 3 x 3 / 2 76 x 76 x 256 -> 38 x 38 x 512 3.407 BFLOPs
38 conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256 0.379 BFLOPs
39 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs
40 res 37 38 x 38 x 512 -> 38 x 38 x 512
41 conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256 0.379 BFLOPs
42 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs
43 res 40 38 x 38 x 512 -> 38 x 38 x 512
44 conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256 0.379 BFLOPs
45 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs
46 res 43 38 x 38 x 512 -> 38 x 38 x 512
47 conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256 0.379 BFLOPs
48 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs
49 res 46 38 x 38 x 512 -> 38 x 38 x 512
50 conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256 0.379 BFLOPs
51 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs
52 res 49 38 x 38 x 512 -> 38 x 38 x 512
53 conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256 0.379 BFLOPs
54 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs
55 res 52 38 x 38 x 512 -> 38 x 38 x 512
56 conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256 0.379 BFLOPs
57 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs
58 res 55 38 x 38 x 512 -> 38 x 38 x 512
59 conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256 0.379 BFLOPs
60 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs
61 res 58 38 x 38 x 512 -> 38 x 38 x 512
62 conv 1024 3 x 3 / 2 38 x 38 x 512 -> 19 x 19 x1024 3.407 BFLOPs
63 conv 512 1 x 1 / 1 19 x 19 x1024 -> 19 x 19 x 512 0.379 BFLOPs
64 conv 1024 3 x 3 / 1 19 x 19 x 512 -> 19 x 19 x1024 3.407 BFLOPs
65 res 62 19 x 19 x1024 -> 19 x 19 x1024
66 conv 512 1 x 1 / 1 19 x 19 x1024 -> 19 x 19 x 512 0.379 BFLOPs
67 conv 1024 3 x 3 / 1 19 x 19 x 512 -> 19 x 19 x1024 3.407 BFLOPs
68 res 65 19 x 19 x1024 -> 19 x 19 x1024
69 conv 512 1 x 1 / 1 19 x 19 x1024 -> 19 x 19 x 512 0.379 BFLOPs
70 conv 1024 3 x 3 / 1 19 x 19 x 512 -> 19 x 19 x1024 3.407 BFLOPs
71 res 68 19 x 19 x1024 -> 19 x 19 x1024
72 conv 512 1 x 1 / 1 19 x 19 x1024 -> 19 x 19 x 512 0.379 BFLOPs
73 conv 1024 3 x 3 / 1 19 x 19 x 512 -> 19 x 19 x1024 3.407 BFLOPs
74 res 71 19 x 19 x1024 -> 19 x 19 x1024
75 conv 512 1 x 1 / 1 19 x 19 x1024 -> 19 x 19 x 512 0.379 BFLOPs
76 conv 1024 3 x 3 / 1 19 x 19 x 512 -> 19 x 19 x1024 3.407 BFLOPs
77 conv 512 1 x 1 / 1 19 x 19 x1024 -> 19 x 19 x 512 0.379 BFLOPs
78 conv 1024 3 x 3 / 1 19 x 19 x 512 -> 19 x 19 x1024 3.407 BFLOPs
79 conv 512 1 x 1 / 1 19 x 19 x1024 -> 19 x 19 x 512 0.379 BFLOPs
80 conv 1024 3 x 3 / 1 19 x 19 x 512 -> 19 x 19 x1024 3.407 BFLOPs
81 conv 255 1 x 1 / 1 19 x 19 x1024 -> 19 x 19 x 255 0.189 BFLOPs
82 yolo
83 route 79
84 conv 256 1 x 1 / 1 19 x 19 x 512 -> 19 x 19 x 256 0.095 BFLOPs
85 upsample 2x 19 x 19 x 256 -> 38 x 38 x 256
86 route 85 61
87 conv 256 1 x 1 / 1 38 x 38 x 768 -> 38 x 38 x 256 0.568 BFLOPs
88 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs
89 conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256 0.379 BFLOPs
90 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs
91 conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256 0.379 BFLOPs
92 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs
93 conv 255 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 255 0.377 BFLOPs
94 yolo
95 route 91
96 conv 128 1 x 1 / 1 38 x 38 x 256 -> 38 x 38 x 128 0.095 BFLOPs
97 upsample 2x 38 x 38 x 128 -> 76 x 76 x 128
98 route 97 36
99 conv 128 1 x 1 / 1 76 x 76 x 384 -> 76 x 76 x 128 0.568 BFLOPs
100 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
101 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs
102 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
103 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs
104 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs
105 conv 255 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 255 0.754 BFLOPs
106 yolo
Loading weights from yolov3.weights...Done!
data/dog.jpg: Predicted in 0.063622 seconds.
dog: 100%
truck: 92%
bicycle: 99%
Gtk-Message: 20:09:45.990: Failed to load module "canberra-gtk-module"
伴随这输出的还有一张如下的图片

更改检测阈值和检测多张图片的详情见官网
第七步 基于yolo.weights模型参数测试多张图片
不需要给定测试图片的路径,直接输入以下指令,然后程序会提示你输入测试图像路径,直到ctrl+c退出程序。
./darknet detect cfg/yolo.cfg yolo.weights
第八步
基于yolo.weights模型参数,使用“-thresh"参数控制显示的bounding-box个数,darknet默认只显示被检测的物体中confidence大于或者等于0.25的bounding-box,可以通过参数-thresh
第九步 基于 yolo.weights 模型参数来测试摄像头
实时摄像头检测 / webcam检测,使用到cuda和opencv编译darknet。
终端输入:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
第十步 基于 yolo.weights 模型参数来测试video
video检测,使用opencv检测视频。
终端输入:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights 第十一步 train yolo on voc
如果想使用不同的训练方案,可以从头开始训练yolo。这里先训练官网数据集。voc数据集或者coco数据集。
参照官网步骤
- 获取数据
指定文件夹后darknet/VOCdevkit,输入命令
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
指令解释:
(1)wget命令用来从指定的URL下载文件。wget非常稳定,它在带宽很窄的情况下和不稳定网络中有很强的适应性,如果是由于网络的原因下载失败,wget会不断的尝试,直到整个文件下载完毕。如果是服务器打断下载过程,它会再次联到服务器上从停止的地方继续下载。这对从那些限定了链接时间的服务器上下载大文件非常有用。
(2)tar解压命令。-x:解压。-f: 使用档案名字,切记,这个参数是最后一个参数,后面只能接档案名。
上述命令是从作者的数据仓库中下载数据,可能比较慢。可从Pascal_voc的官网下载数据:2007数据集和2012数据集(在development kit中下载)
将三个解压后的文件,放在文件夹VOCdevkit中。
- 为图片创建.txt文件。在终端输入
wget https://pjreddie.com/media/files/voc_label.py
python3 voc_label.py
执行指令查看目前路径下的文件
ls
可以看到包括了如下几个文件
2007_test.txt, 2007_train.txt, 2007_val.txt, 2012_train.txt, 2012_val.txt
- 上面创建出的几个.txt文件,除了test.txt用于test,其他的都用于train。所以执行下面的指令用于把所有的2007 trainval and the 2012 trainval set放在一个大的list里面。
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt
指令解释:cat 命令用于连接文件并打印到标准输出设备上。指令作用是把2007_train.txt 和2007_val.txt 和2012_*.txt的内容全部输出到 train.txt文本中。
- 修改配置文件cfg/voc.data。
将文本中的内容按照自己的数据对照修改,路径也要修改为自己的路径。
classes= 3 #修改为自己的类别数
train = /home/learner/darknet/data/voc/train.txt #修改为自己的路径
valid = /home/learner/darknet/data/voc/2007_test.txt #修改为自己的路径
names = /home/learner/darknet/data/voc.names #修改见voc.names文件
backup = /home/learner/darknet/backup #修改为自己的路径,输出的权重信息将存储这个文件内
- 修改voc.names文件。
head #改为自己需要探测的类别,一行一个
eye
nose
- 下载预训练卷积层权重文件,在前面测试单张图片时也下载过卷积层权重文件,但是这两个文件不一样。不用指令通过官网链接下载也可。
wget https://pjreddie.com/media/files/darknet53.conv.74
- 修改cfg/yolov3-voc.cfg文件,在前面训练单张图片时有修改过,这里可以不再修改。
[net]
# Testing
batch=64
subdivisions=32 #每批训练的个数=batch/subvisions,根据GPU修改,显存不够值就大一些
# Training
# batch=64
# subdivisions=16
……
learning_rate=0.001
burn_in=1000
max_batches = 50200 #训练步数
policy=steps
steps=40000,45000 #开始衰减的步数
scales=.1,.1
[convolutional]
.....
[convolutional]
……
[yolo]
……
classes=3 #修改为自己的类别数
……
[route]
layers = -4
[convolutional]
……
[upsample]
stride=2
[route]
layers = -1, 61
[convolutional]
……
[convolutional]
……
[convolutional]
……
[convolutional]
……
[convolutional]
……
[convolutional]
……
[convolutional]
……
[yolo]
……
classes=3 #修改为自己的类别数
……
[route]
layers = -4
[convolutional]
……
[upsample]
stride=2
[route]
layers = -1, 36
[convolutional]
……
[convolutional]
……
[convolutional]
……
[convolutional]
……
[convolutional]
……
[convolutional]
……
[convolutional]
……
[yolo]
……
classes=3 #修改为自己的类别数
……
- 训练模型
#单GPU训练的指令,除此之外还有多GPU训练
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
第十二步 opencv的gpu模块的调用
- 在执行opencv的内置人脸检测级联分类器时,由于opencv默认使用的cpu,所以导致摄像头实时测试过程中出现卡顿,故需要换用opencv的gpu模块调用。
- 参考:参考资料
- 在编写代码之前第一件事就是连接gpu模块到项目中,包括模块的头文件,所有gpu的函数和数据结构都在以cv命名空间的gpu空间内,例如下面引入的是gpu的结构和方法。
#include
- OpenCV提供的开发包中提供的库没有开启gpu和ocl模块功能,虽然有***gpu.lib/***gpu.dll文件,但不能用。如果调用gpu::getCudaEnableDeviceCount()将会return 0;要开启该功能需要重新编译opencv的库。需要在编译之前安装:CMake用于生成vs工程,Tbb, Qt(gui), cuda tool kit, python 等程序。
第十三步 利用opencv和摄像头将捕获的视频转换为图片
第十二步
安装labelImg
git clone https://github.com/tzutalin/labelImg
sudo apt-get install pyqt4-dev-tools #安装PyQt4
sudo pip3 install lxml#这里应该使用pip指令
cd labelImg
make -j12 all
python3 labelImg.py#这里应该使用python指令
注意在制作自己数据集,标注图片时的类别名称用小写名字,不要用大写字母。
上面的命令执行后出现如下错误:
指令
labelImg$ make -j12
显示
make: pyrcc5: Command not found
Makefile:24: recipe for target 'qt5py3' failed
make: *** [qt5py3] Error 127
ERROR: test_qt (unittest.loader._FailedTest)
ImportError: Failed to import test module: test_qt
ModuleNotFoundError: No module named 'PyQt5'
ModuleNotFoundError: No module named 'sip'
ERROR: test_stringBundle (unittest.loader._FailedTest)
ImportError: Failed to import test module: test_stringBundle
Makefile:11: recipe for target 'testpy3' failed
make: *** [testpy3] Error 1
指令
python3 labelImg.py
显示
ModuleNotFoundError: No module named 'PyQt5'
PyQt是一个用于创建GUI应用程序的跨平台工具包,它将python与Qt库融为一体。Qt是使用c++语言编写的GUI库。PyQt允许python语言调用Qt库中的API。
出现上面的错误后,我就先去验证PyQt4是否安装成功。检查方式是在终端输入:
python
import PyQt4
注意:输入指令时,不要把大写模块名写成小写。
结果,能够导入成功。
我继续验证
python3
import PyQt4
结果:不能导入成功。
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,最初用来搜寻XML文档,同样适用于HTML文档的搜索。检测安装是否成功的方法:
python3
import lxml
总结:出现上面错误的原因是因为PyQt与Python关联,而安装的lxml与Python3关联。解决办法是再重新安装PyQt5,在终端执行:
sudo apt-get install pyqt5-dev-tools
cd labelImg
make qt5py3 # 用make all 会导致先识别pyqt4
python3 labelImg.py
总结:安装labelImg的正确完整步骤:
sudo apt-get install pyqt5-dev-tools
sudo pip3 install lxml
git clone https://github.com/tzutalin/labelImg.git
cd labelImg
make qt5py3 # 用make all 会导致先识别pyqt4
python3 labelImg.py #打开labelImg
labelImg的使用
- 修改默认的xml文件保存路径,路径不能包含中文。
- 标注过程中可以返回修改,后面的标注结果会覆盖前面的。
- 每个图片和标注得到的xml文件,JPEGImages文件夹里面的训练图片,对应Annotations的一个同名xml文件,类别名称用小写字母。
- xml文件包含了图像名称、路径、图像size和深度、标记框的坐标信息。
- txt文件包含了object class和x和y和width和height。
第十三步 自行训练网络
- 建立所需的配置文件cfg/voc.data和cfg/yolov3-voc.cfg和data/voc.names。可以将voc数据集里的这三个文件拷贝过来再修改。
- 修改cfg文件夹下的voc.data.
classes= 3 #有几类就改成几类
train = /自己的路径/VOCdevkit/VOC2012/2012_train.txt
valid = /自己的路径/VOCdevkit/VOC2012/2012_test.txt
names = /自己的路径/data/voc.names
backup = /自己的路径/results
- 修改cfg文件夹下的yolov3-voc.cfg
重点修改learning_rate和max_batches等参数。在训练阶段,注释掉testing和打开train。共三个yolo层都要改,yolo层中的class为类别数,每一个yolo层前的conv层的conv层中的filter=(列别+5)×3,电脑内存不够的话设置random=0。类似这样的位置共有三处。 - 修改data/voc.names。改为自己的自定义类别。
- 开始训练。终端下执行:
cd darknet
./darknet detector train wp_data/cfg/voc.data wp_data/cfg/yolov3-voc.cfg 2>&1 | tee wp_data/visualization/train_yolov3.log #保存训练日志
#上条代码解释:./darknet表示编译后的执行文件,detector train是指令,train表示是训练的过程。wp_data/cfg/voc.data表示的是wp_data/cfg路径下的文件voc.data。wp_data/cfg/yolov3-voc.cfg表示的是wp_data/cfg路径下的文件yolov3-voc.cfg。2>&1 | tee wp_data/visualization/train_yolov3.log表示保存日志,为了后续绘制loss曲线。若没有这条语句就不会保存日志。
- 训练完后的权重文件.weights保存到了darknet/backup下。其中保存的这个模型可以用于继续训练。
第十四步 测试网络
训练好后可以在backup看到权重文件,尝试test前要修改cfg文件,切换到test状态。注释掉train,打开test。输入测试的终端命令:
./darknet detector test cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc.weights
代码解释:命令detector test后面是三个参数:
cfg/voc.data表示cfg路径下的voc.data
cfg/yolov3-voc.cfg表示cfg路径下的yolov3-voc.cfg
backup/yolov3-voc.weights表示backup路径下的yolov3-voc.weights
执行后测试集里的图片会一张张显示出测试结果。
第十五步 计算准确率
参考计算准确率
darknet分类没有像caffe一样训练的同时,日志文件输出测试集的准确率,但提供了valid函数来输出top-1的准确率。
终端命令如下:
./darknet classifier valid cfg/door.data cfg/darknet19.cfg classify_result/darknet19_18.weights
用相同的数据集对比caffe pytorch框架,用近似的网络训练,darknet框架训练的平均loss更低,准确率更高,模型的泛化能力更好,对比caffe,没有第三方库,c也更方便移植到嵌入式平台。
第十六步 在训练过程中细节总结
- subdivisions:这个参数让你的batch不是一下子丢进网络里,而是分成subdivision数字对应的份数,一份一份跑完后,再一起打包算作一次iteration。这样可以降低显存的使用情况,如果这个参数值为1则表示一次将所有的batch的图片丢进网络里。subdivision意义是降低对GPU memory的要求。
- learning_rate是初始学习率,训练时的真正学习率和学习率的策略和初始学习率有关。
训练发散的话可以降低这个值,学习遇到瓶颈,loss不变的话也可以降低这个初始学习率值。 - momentum是动量,在训练时加入动量可以帮助走出local minima以及saddle point。
- decay是权重衰减正则项,用来防止过拟合。
- bacth的值等于cfg文件中的batch/subdivions再乘以time_steps。time_steps的值在yolo中默认值是1,在cfg文件中没有配置,故是默认值,因此batch就是cfg文件中的batch/subdivision。batch的意义是每batch个样本更新一次参数。每一次迭代送到网络的图片数量,也叫作批数量,增大bacth值可以让网络在较少的迭代次数内完成一个epoch。在固定最大迭代次数的前提下,增加batch会延长训练时间,但会更好地寻找到梯度下降的方向,如果显存够大,可以适当增大这个值来提高内存利用率。这个值过小的话让训练不够收敛,过大会陷入局部最优。
- policy:学习策略,包括一下几种:
fixed:保持base_lr不变
step:若设置为step,则还要设置一个stepsize,返回base_lrgamma^(floor(iter/stepsize)),
其中iter表示当前的迭代次数。
exp:返回base_lrgamma^iter,iter是当前迭代次数。
inv:若设置为inv,还要设置一个stepvalue,这个参数和step相似,step是均等间隔变化,
而multistep是根据stepvalue值变化。
poly:学习率进行多项式误差,返回base_lr(1-iter/max_iter)^(power)
sigmoid:学习率进行sigmoid衰减,返回base_lr(1/(1+exp(-gamma*(iter-stepsize)))) - step,scales:这两个是组合一起的。learn_rate:0.001,step:100,25000,35000,
scales:10,.1,.1这组数据的意思是:在0-100次iteration期间learning rate为原始0.001,在100到25000次iteration期间learning rate为原始的10倍即0.01,在25000到35000次iteration期间learning rate为当前值的0.1倍即0.001。在35000到最大iteration期间使用learning rate为当前值的0.1倍即0.0001。随着iteration增加,降低学习率使得模型更有效的学习,即降低train loss。 - 最后一层卷积层filters数值是5*(类别数+1*5)。
- random若设置为1,那么训练时每一张batch图片都会随机改成320-640(32整数倍)大小的图片,目的和色度、曝光度一样,都是为了样本多样性。若random=0则所有图片都只修改成默认大小416*416。如果这个值设置为1的话,可能出现obj noobj全为0的情况,设置为0后一切正常。
训练过程中输出的参数的意义
- Avg IOU:预测出的bbox和实际标注的bbox的交集除以它们的并集,这个值越大说明预测的效果越好。
- Avg Recall:平均召回率,检测出的物体个数除以标注的所有物体个数。
- count:前面写的大写的Count也是这个参数,一般都是写的小写。这个参数表示标注的所有物体的个数,例如:如果count=6,recall=0.66667,就表示一共有6个物体(可能包含不同类别,这里不考虑类别)。如果预测出4个,那么recall=4/6=0.66667。
- train loss和Avg train loss这两个参数应该随着iteration增加而降低,如果loss增大到几百就说明是发散了,如果loss在一段时间内不变,就需要降低learning_rate和改变batch来加强学习效果,但是也有可能是训练已经充分。
第十七步 darknet 卷积层浅层特征可视化
参考:darknet卷积层浅层可视化
- 使用python读取图片有一个好处,就是可以将灰度图转化为热力图,这样更容易观察。(备注:这些备用的零碎的python代码都放在home/syy/python_project中。)
- 代码见GrayToThermalMap的python文件。
第十八步 yolo v3的可视化
参考测试结果可视化
- yolo v3训练日志的可视化,主要是loss和iou曲线的可视化,是查看训练效果的依据,有时可能没等训练结束,模型就开始发散了。训练结束需要测试指标是否达到预期。
- 可视化训练过程中的中间参数,需要用到前面终端命令保存的日志文件。终端命令中的日志文件的存储路径视自己情况而定。如下:
cd darknet
./darknet detector train wp_data/cfg/voc.data wp_data/cfg/yolov3-voc.cfg 2>&1 | tee wp_data/visualization/train_yolov3.log
- 格式化训练的日志文件。在使用脚本绘制变化曲线之前,需要先使用ExtractLog.py格式化log,把生成的新的log文件用可视化工具绘图。格式化log的脚本文件和日志文件放在同一目录下。
ExtractLog.py代码如下:(备注:这些备用的零碎的python代码都放在home/syy/python_project中。)
'''
该文件用来提取训练log,去除不可解析的log后使log文件格式化,生成新的log文件再用可视化工具绘图
'''
import inspect
import os
import random
import sys
def extract_log(log_file,new_log_file,key_word):
with open(log_file.'r')as f:
with open(new_log_file,'w')as train_log:
for line in f:
# 去除多gpu的同步log
if 'Syncing' in line:
continue
# 去除除零错误的bug
if 'nan' in line:
continue
if key_word in line:
train_log.write(line)
f.close()
train_log.close()
# 运行后会解析出log文件的loss行和iou行得到两个txt文件。
extract_log('train_yolov3.log','train_log_loss.txt','images')
extract_log('train_yolov3.log','train_log_iou.txt','IOU')
- 可视化训练日志中的loss(使用TrainLossVisualization.py脚本)
(备注:这些备用的零碎的python代码都放在home/syy/python_project中。)
测试时脚本文件放在与日志同一目录下。
'''
可视化yolo v3-darknet训练过程日志中的loss
运行该程序后会在脚本所在路径生成avg_loss.png,可以通过分析损失变化函数,修改cfg中的学习率变化策略
'''
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 根据train_log_loss.txt的行数修改lines值
lines=25100
result=pd.read_csv('train_log_loss.txt',skiprows=[x for x in range(lines)],error_bad_lines=False,names=['loss','avg','rate','seconds','images'])
result.head()
result['loss']=result['loss'].str.split('').str.get(1)
result['avg']=result['avg'].str.split('').str.get(1)
result['rate']=result['rate'].str.split('').str.get(1)
result['seconds']=result['seconds'].str.split('').str.get(1)
result['images']=result['images'].str.split('').str.get(1)
result.head()
result.tail()
import numpy as np
import matplotlib.pyplot as plt
lines=9873
result=pd.read_csv('train_log_loss.txt',skipows=[x for x in range(lines) if((x<1000))],error_vad_lines=False,names=['loss','avg','rate','seconds','images'])
result.head()
result['loss']=result['loss'].str.split('').str.get(1)
result['avg']=result['avg'].str.split('').str.get(1)
result['rate']=result['rate'].str.split('').str.get(1)
result['seconds']=result['seconds'].str.split('').str.get(1)
result['images']=result['images'].str.split('').str.get(1)
result.head()
result.tail()
print(result['loss'])
print*result['avg']
print(result['rate'])
print(result['seconds'])
print(result['images'])
result['loss']=pd.to_numeric(result['loss'])
result['avg']=pd.to_numeric(result['avg'])
result['rate']=pd.to_numeric(result['seconds'])
result['images']=pd.to_numeric(result['images'])
result.dtypes
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(result['avg'].values,label='avg_loss')
ax.legend(loc='best')
ax.set_title('The loss curves')
ax.set_xlabel('batches')
fig.savefig('avg_loss')
print(result['loss'])
print(result['avg'])
print(result['rate'])
print(result['seconds'])
print(result['images'])
result['loss']=pd.to_numeric(result['loss'])
result['avg']=pd.to_numeric(result['avg'])
result['rate']=pd.to_numeric(result['rate'])
result['seconds']=pd.to_numeric(result['seconds'])
result['images']=pd.to_numeric(result['images'])
result.dtypes
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(result['avg'].values,label='avg_loss')
ax.legend(loc='best')
ax.set_title('The loss curves')
ax.set_xlabel('batches')
fig.savefig('avg_loss')
# 修改上面代码中的lines为train_log_loss.txt中的行数,并且根据需要修改要跳过的行数。
skiprows=[x for x in range(lines) if (x%10!=9)|(x<1000)]
- 可视化训练日志中的参数(使用TrainIouVisualization.py文本)
(备注:这些备用的零碎的python代码都放在home/syy/python_project中。)
测试时脚本文件放在与日志同一目录下。可以可视化的参数包括:Region Avg IOU / Class / Obj / No Obj / Avg Recall / Count等
'''
可视化yolo v3-darknet训练过程日志中的参数
可以可视化的参数包括:Region Avg IOU / Class / Obj / No Obj / Avg Recall / Count等
运行该程序会在脚本所在路径生成相应的曲线图
'''
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 根据train_log_iou.txt的行数值来修改lines值
lines=122956
result=pd.read_csv('train_log_iou.txt',skiprows=[x for x in range(lines) if(x%10==0 or x%10==9)],error_bad_lines=False,names=['Region Avg IOU','Class','Obj','No Obj','Avg Recall','Count'])
result.head()
result['Region Avg IOU']=result['Region Avg IOU'].str.get(1)
result['class']=result['class'].str.split(':').str.get(1)
result['Obj']=result['Obj'].str.split(':').str.get(1)
result['No Obj']=result['No Obj'].str.split(':').str.get(1)
result['Avg Recall']=result['Avg Recall'].str.split(':').str.get(1)
result['Count']=result['Count'].str.split(':').str.get(1)
result.head()
result.tail()
print(result['Region Avg IOU'])
result['Region Avg IOU']=pd.to_numeric(result['Region Avg IOU'])
result['class']=pd.to_numeric(result['Class'])
result['Obj']=pd.to_numeric(result['Obj'])
result['No ObJ']=pd.to_numeric(result['No Obj'])
result['Avg Recall']=pd.to_numeric(result['Avg Recall'])
result['Count']=pd.to_numeric(result['Count'])
result.dtypes
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(result['Region Avg IOU'].values,label='Region Avg IOU')
ax.legend(loc='best')
ax.set_title('The Region Avg IOU curves')
ax.set_xlabel('batches')
fig.savefig('Region Avg IOU')
- 对于detection,不要盲目用loss来判断模型的好坏,loss应该用做在训练当中判断训练是否正常进行。例如用来这样判断训练过程:如果loss一直升高,最后NAN,说明学习率大了。
最后,关于实践过程中可能出现的问题以及解决措施
- 参考可能出现的问题及办法
- 官网给出的程序不能实现将检测后的视频保存下来,在这个链接上在官网程序的基础上修改了两个文件,故使得不管是本地视频还是摄像头检测的视频通过yolo v3测试后的结果视频都能保存下来。
附录:参考文档
- yolo配置文件的解析
- yolo v2训练自己的数据集
重要知识点的补充
关于yolo中所使用到的数据扩增手段:
- 数据扩增的流程如下:
第一步:加载原始图像
第二步:随机增加、或者减去原始图片大小的20%来选择新的宽度和高度
第三步:按照新大小裁剪图像,如果新图像在一个或多个边上大于原始图像,则用0填充。
第四步:将图像resize到416*416,使其成为正方形
第五步:随机翻转图像的色调、饱和度曝光(亮度)
第六步:通过移动和缩放边界框坐标来调整边界框,以适应前面所做的裁剪和调整大小,以及水平翻转等操作。 - 旋转是常见数据扩增技术,但是这是很麻烦的,因为牵涉到旋转边界框。所以通常不采用旋转来扩增数据。
- 数据扩增中的随机裁剪可能导致物体的部分或者全部落在裁剪图像之外。因此只希望保留中心位于该裁剪区域某个位置的边界框,不希望保留中心位于裁剪区域之外的框。
若在yolo中使用到voc数据集,要注意数据集中图片的高宽比
- 因为yolo模型的预测是在13 * 13的正方形网格上,输入图像也是正方形(416 * 416)。但是训练数据集中的图片通常不是正方形,并且测试图片一般也不是,图片的大小也会各种各样。
- 因为yolo网络的输入是416 * 416的正方形图像,因此必须将训练图像放在该正方形中,有如下三种方法:
方法一:直接将图像resize到416 * 416。缺点会挤压图像
方法二:将最小边调整为416,然后从图像中裁剪出416 * 416区域,缺点:通过裁剪虽然高宽比保持不变,但可能切掉图像的重要部分。
方法三:将最大边调整为416,用0去填充另外的短边,缺点可能会使物体太小而无法检测。 - 在训练yolo前,将边界框的xmin和xmax除以图像宽度,ymin和ymax除以图像高度,以归一化坐标,目的是为了使训练独立于每个图像的实际像素大小。但是输入的图像通常不是正方形的,所以x坐标除以一个与y坐标不同的数字,根据图像的尺寸和高宽比,每个图像的除数是不一样的,这影响到如何处理边界框坐标和先验框。
- 在上面提到的方法一直接将图像resize到416 * 416 ,这种虽然会挤压图像,但是这种方法简单粗暴,对于那些如果大部分图像都有相似高宽比或者是高宽比不太极端的情况下,神经网络仍然是可以适用的。CNN网络对于物体的厚度变化相当健壮,也就是说当物体受到挤压时(方法一实施时)CNN依然有效。
- 对于上面提到的方法二裁剪和方法三用0填充,这两种方法下在归一化边界框坐标时都要记住高宽比。
- 在上面的方法二中,有可能边界框比输入图像大,因为只是对裁剪部分进行预测,由于物体可能部分落在图像之外,边界框也可能部分落在图像之外。一些先验框可能部分落在图像之外,但至少它们的高宽比真正代表了训练数据中的物体。
- 方法二裁剪的缺点是可能丢失图像重要部分,这个缺点比方法一的缺点挤压物体更严重。但是若采用方法一时,存在挤压情况的话,计算出的先验框并不能真正代表真正的框,不同的高宽比会被忽略,这是因为每张训练图片的挤压方式都可能出现不同。所以若采用方法一,存在挤压情况的话,先验框更像是在不同的扭曲图像中求平均结果。
yolo模型的训练过程
- 该模型直接使用卷积神经网络进行预测,然后将这些预测数字转换为边界框,数据集中包含了真实框,所以训练这个yolo模型就需要设计损失函数将预测框与真实框作比较。
- 不同的图片的真实框数量是不同的,图像中框存在的位置也是不定的,有些可能会重叠。所以在训练时,要将每个检测器与这些真实框中的某一个相匹配,从而使得可以计算每个预测框的回归损失。
- 如果采用如下两种匹配方法:
第一种:将第一个真实框分配给第一个检测器,将第二个真实框分配给第二个检测器,以此类推。
第二种:随机将真实框分配给检测器。 - 上面这两种匹配方法:都会使得每个检测器都将被训练来预测各种各样的物体,有些是较大的物体,有些是较小物体,有些位置在图像一角,有些在中间位置等。所以为了解决这个问题,采用带有固定大小网络的检测器,其中每个检测器都只负责检测位于特定位置且是特定大小的物体。
- 在yolo中,图像中的每个物体仅仅由一个检测器来预测,需要找到边界框中心落在哪个网格单元,而其他的网格单元若预测了该物体则会被损失函数惩罚。
- voc数据集给出的边界框标注为xmin/ymin/xmax/ymax,由于需要知道边界框的中心,所以需要将边界框坐标转化为center x/center y/width/height。一般要先将边界框坐标归一化到0 1之间,这是因为训练图像的大小不一致。
- 每个网格单元都有多个检测器,只需要其中一个检测器来查找物体,需要选择其先验框与物体的真实框最匹配的检测器,采用IOU来衡量。所以只有那个单元中的特定检测器才可以预测这个物体。这个规则使得不同的检测器专注于处理形状和大小与先验框相似的物体。
- 模型的输出是13 * 13 * 125的张量,所以损失函数的目标张量也是 13 * 13 *125,数字125来自5个检测器,每个检测器预测类别的20个概率值+4个边界框坐标+1个置信度得分。
- 在损失函数的目标张量中,对应正例,给出物体的边界框坐标和oneshot编码的类别向量,置信度为1.0,因为100%确定这是一个真实物体。对于负例,目标张量的所有值为0,边界框坐标和类向量不重要了,因为它们被损失函数忽略,置信度得分为0,因为100%确定这里没有物体。
- 训练的每个迭代过程需要的是一个batch * 416 * 416 *3的图像张量,还有一个batch * 13 * 13 的目标张量,这个目标张量中元素大多是0,因为大多数检测器不负责预测一个特定物体。
- 关于如何避免两个物体需要相同检测器的问题:yolo的解决办法是:每次随机打乱真实框,每个单元只选择第一个进入它中心的物体,所以,当一个新的真实框与一个已经负责另一个物体的检测器相匹配时,也只能忽略掉了。这样就避免了两个物体需要相同检测器的情况。万一检测到了,是会受到惩罚的。
- SSD对于如何避免两个物体需要相同检测器的情况采用的方法是:将一个真实框与多个检测器匹配,首先选择具有最佳IOU值的检测器,然后选择那些与这个真实框之间的IOU值超过0.5但是还没有匹配的检测器,SSD中检测器与先验框是一一对应的。这里的IOU指的是检测器的先验框与物体的边界框之间的重叠。这种解决办法使得模型更容易学习,因为这种方法不必在哪个检测器应该预测这个物体的过程中进行唯一选择,毕竟多个检测器可以预测某个对象是很常见的现象。
- 比较yolo和SSD,yolo将一个物体只分配给一个检测器,而该单元的其他检测器则是无物体。以帮助检测器更加专注,但是SSD中多个检测器可以预测同一个物体,SSD专注的是形状而不是大小。
- 对于任何一个检测器,有两种可能:
情况一:这个检测器没有与之相关的真实框,这是负例,这个检测器不应该检测到任何物体,也就是它应该预测一个置信度为0的边界框。
情况二:这个检测器匹配到一个真实框,即正例,这个检测器负责检测到物体。 - 对于不应该检测到物体的检测器,当它预测出置信度大于0的边界框时要惩罚这个检测器,因为它给出的检测是假阳性,图像上的这个位置并没有真实物体。
- 若检测器是正例,当出现:坐标错误或者置信度太低或者分类错误时要惩罚这个检测器。
- 理想情况:检测器应预测出一个与真实框完全重叠的框,类别也应该一致,并且具有较高的置信度,当置信度得分低时,预测结果视为假阴性false negative,即说明此时模型没有找到真正的物体。
- 若置信度得分高,但坐标不准确或者分类错误,则预测视为假阳性false positive。
- 若预测被判定为假阴性,则会降低模型的召回率,若预测被视为假阳性,则会降低模型的准确度。
- 只有当坐标、置信度、类别都正确的时候,预测才被视为真阳性true pisitive。
- 在yolo的损失函数中采用sigmoid来将置信度的取值范围限制在0和1之间。
- 一个trick:如果一个检测器被认为不应该预测一个物体,但是实际上却预测出了一个不错的结果,那么最好是忽略它,或者是鼓励它预测物体,也许应该让这个检测器与这个物体匹配,这是一个小trick,深度学习中经常会有一些无法讲清楚原因的trick。
- SSD将背景类看成是一个特殊类,如果检测器预测出是背景类,那么这个检测器被认为是没有检测到物体。
- yolo中采用平方和误差而不是常见的用于回归的均方差,也不是常见的用于分类的交叉熵,一个可能原因是每张图片物体数量并不相同,如果取平均,那么包含10个物体的图片与包含1个物体的图片的loss的重要性一样,这是不好的,而若采用求和,那么包含10个物体的图片的重要性约等于是只包含1个物体的图片的重要性的10倍,这样的话会更公平。
- yolo中为不同大小的物体训练了5个独立的分类器(同一个网格中的每个检测器的份额利器是不同的)。
- yolov3在计算损失函数时,将问题看成是多标签分类问题,所以不采用softmax,因为softmax会导致类别互斥,而是使用sigmoid,这样允许预测多个标签。
- 由于SSD不预测置信度,所以增加一个背景类别,如果检测器预测是背景,则此检测器没有检测到物体,即忽略这个预测。
- 由于对同一个物体进行多次预测是受到惩罚的,所以最好先进行NMS,使得可以先尽可能去除重复的预测,最好也扔掉那些置信度较低的预测(如低于0.3),注意这里是直接扔掉这些,否则会被当做FP。
- yolo模型给出845个预测,SSD给出1917个预测,这远远多于真实物体,因为大部分图像只含有1到3个物体。