keras入门——HelloWorld
1.keras是什么?
Keras只是深度学习建模的一个上层建筑,其后端可以灵活使用CNTK、TensorFlow或者Theano。这样就可以避免不同深度学习框架的差异而集中于建模过程。并且可以进行CPU和GPU之间的无缝切换。
我的理解,就像是jQuery是对JavaScript的一层封装,那么Keras就是对机器学习框架CNTK、TensorFlow或者Theano的一层封装,大大简化了代码量。
2.HelloWorld
此程序实现的是一个5分类的功能,所用数据是59维的。
1)引入所需要的包
# 引入序列模型
from keras.models import Sequential
# 引入全连接层、放弃层、激活层(激活层没有直接用到,但是在全连接层里间接用到了。)
from keras.layers import Dense, Dropout, Activation
# 引入SGD优化算法
from keras.optimizers import SGD
# 引入了metrics评估模块
from keras import metrics
# 引入可视化模块
from keras.utils import plot_model
# 引入了keras
import keras
# 使用numpy来模拟生成数据
import numpy as np2)解析数据文件
def get_list(filename): # get train data and label
array = []
array1 = []
i = 0
with open(filename, 'r') as file_to_read:
while True:
lines = file_to_read.readline()
if not lines:
break
pass
p_tmp = [float(i) for i in lines.split()]
if i % 2 == 0:
array.append(p_tmp)
else:
array1.append(p_tmp)
i += 1
pass
array = np.array(array)
array1 = np.array(array1)
pass
return array, array13)准备好训练数据和测试数据
train_label, train_data = get_list('data.txt')
test_label, test_data = get_list('test.txt')
train_label = keras.utils.to_categorical(train_label, num_classes=5)
test_label = keras.utils.to_categorical(test_label, num_classes=5)keras.utils.to_categorical(train_label, num_classes=5)的意思就是把标签转化成one-hot 标签,train_label是一个900x1的矩阵,里面有1,2,3,4,5表示5个分类(不一定包含1-5里面所有的数,在 num_classes 的范围就行)。
4)构建模型
# 构建序列模型
model = Sequential()
# 第一层为全连接层,隐含单元数为64,激活函数为relu,在第一层中一定要指明输入的维度。
model.add(Dense(64, activation='relu', input_dim=59))
# 放弃层,将在训练过程中每次更新参数时随机断开一定百分比(rate)的输入神经元,Dropout层用于防止过拟合。这里是断开50%的输入神经元。
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(5, activation='softmax'))
# 实例化优化算法为sgd优化算法
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)首先这里接触到了model,model在Keras里有两种,一种是序贯模型,一种是函数式模型。
1.序贯模型
序贯模型是多个网络层的线性堆叠,也就是“一条路走到黑”。这也是非常常用的和傻瓜式的方法。
2. 函数式(Functional)模型
Keras函数式模型接口是用户定义多输出模型、非循环有向模型或具有共享层的模型等复杂模型的途径。一句话,只要你的模型不是类似VGG一样一条路走到黑的模型,或者你的模型需要多于一个的输出,那么你总应该选择函数式模型。函数式模型是最广泛的一类模型,序贯模型(Sequential)只是它的一种特殊情况。
下面我们来简单的介绍一下目前用到的几个常用层(Core)。
1. Dense层
keras.layers.core.Dense(
units,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs
)Dense就是常用的全连接层,所实现的运算是output = activation(dot(input, kernel)+bias)。其中activation是逐元素计算的激活函数,kernel是本层的权值矩阵,bias为偏置向量,只有当use_bias=True才会添加。
如果本层的输入数据的维度大于2,则会先被压为与kernel相匹配的大小。
参数的含义如下:
- units:大于0的整数,代表该层的输出维度。
- activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
- use_bias: 布尔值,是否使用偏置项
- kernel_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
- bias_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
- kernel_regularizer:施加在权重上的正则项,为Regularizer对象
- bias_regularizer:施加在偏置向量上的正则项,为Regularizer对象
- activity_regularizer:施加在输出上的正则项,为Regularizer对象
- kernel_constraints:施加在权重上的约束项,为Constraints对象
- bias_constraints:施加在偏置上的约束项,为Constraints对象
2. Activation层
这个激活函数在本例中没有出现,其实不是,它间接的在Dense层中出现过了,预设的激活层常见的有以下几种:
- softmax
这是归一化的多分类,可以把K维实数域压缩到(0,1)的值域中,并且使得K个数值和为1。 - sigmoid
这时归一化的二元分类,可以把K维实数域压缩到近似为0,1二值上。 - relu
这也是常用的激活函数,它可以把K维实数域映射到[0,inf)区间。 - tanh
这时三角双曲正切函数,它可以把K维实数域映射到(-1,1)区间。
还有其他激活函数我们就不一一介绍了。
3. Dropout层
keras.layers.core.Dropout(rate, noise_shape=None, seed=None)为输入数据施加Dropout。Dropout将在训练过程中每次更新参数时随机断开一定百分比(rate)的输入神经元,Dropout层用于防止过拟合。
其参数含义如下:
- rate:0~1的浮点数,控制需要断开的神经元的比例。
- noise_shape:整数张量,为将要应用在输入上的二值Dropout mask的shape,例如你的输入为(batch_size, timesteps, features),并且你希望在各个时间步上的Dropout mask都相同,则可传入noise_shape=(batch_size, 1, features)。
- seed:整数,使用的随机数种子
还有几个常用层,我们会在接下来的讲解中讲到。这里不再赘述。
优化算法
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)它就是随机梯度下降法,支持动量参数,支持学习衰减率,支持Nesterov动量。这几个参数就是SGD的几个改进,优化算法那章我们会讲到。
其参数含义如下:
- lr:大于0的浮点数,学习率
- momentum:大于0的浮点数,动量参数
- decay:大于0的浮点数,每次更新后的学习率衰减值
- nesterov:布尔值,确定是否使用Nesterov动量
5)对模型进行预编译
# 对模型进行预编译,其损失函数为多类别交叉熵,优化算法为sgd,
# 评估方法为多类别准确度和平均绝对误差。
model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=[metrics.categorical_accuracy, metrics.mae]
)在训练模型之前,我们需要通过compile来对学习过程进行配置。compile接收三个参数:
- 优化器optimizer:该参数可指定为已预定义的优化器名,如rmsprop、adagrad,或一个Optimizer类的对象,详情见optimizers
- 损失函数loss:该参数为模型试图最小化的目标函数,它可为预定义的损失函数名,如categorical_crossentropy、mse,也可以为一个损失函数。详情见losses
- 指标列表metrics:对分类问题,我们一般将该列表设置为metrics=[‘accuracy’]。指标可以是一个预定义指标的名字,也可以是一个用户定制的函数.指标函数应该返回单个张量,或一个完成metric_name - > metric_value映射的字典.请参考性能评估
6)训练模型
model.fit(train_data, train_label, epochs=50, batch_size=100)原型为
fit(self,
x,
y,
batch_size=32,
epochs=10,
verbose=1,
callbacks=None,
validation_split=0.0,
validation_data=None,
shuffle=True,
class_weight=None,
sample_weight=None,
initial_epoch=0
)- x:输入数据。如果模型只有一个输入,那么x的类型是numpy array,如果模型有多个输入,那么x的类型应当为list,list的元素是对应于各个输入的numpy array
- y:标签,numpy array
- batch_size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
- epochs:整数,训练的轮数,每个epoch会把训练集轮一遍。
- verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
- callbacks:list,其中的元素是keras.callbacks.Callback的对象。这个list中的回调函数将会在训练过程中的适当时机被调用,参考回调函数
- validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。注意,validation_split的划分在shuffle之前,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不均匀。
- validation_data:形式为(X,y)的tuple,是指定的验证集。此参数将覆盖validation_spilt。
- shuffle:布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺序。若为字符串“batch”,则是用来处理HDF5数据的特殊情况,它将在batch内部将数据打乱。
- class_weight:字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)
- sample_weight:权值的numpy array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了sample_weight_mode=’temporal’。
- initial_epoch: 从该参数指定的epoch开始训练,在继续之前的训练时有用。
fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况,如果有验证集的话,也包含了验证集的这些指标变化情况。
7)评估模型
# 评估模型
score = model.evaluate(test_data, test_label, batch_size=128)原型为:
evaluate(self, x, y, batch_size=32, verbose=1, sample_weight=None)它最终返回的是一个score,第0维为编译中的loss指标,剩下的就是metrics中的指标了。
参数含义如下:
- x:输入数据,与fit一样,是numpy array或numpy array的list
- y:标签,numpy array
- batch_size:整数,含义同fit的同名参数
- verbose:含义同fit的同名参数,但只能取0或1
- sample_weight:numpy array,含义同fit的同名参数
8)模型可视化
plot_model(model, to_file='model.png', show_shapes=True)- show_shapes:指定是否显示输出数据的形状,默认为False
- show_layer_names:指定是否显示层名称,默认为True
本例的模型为:
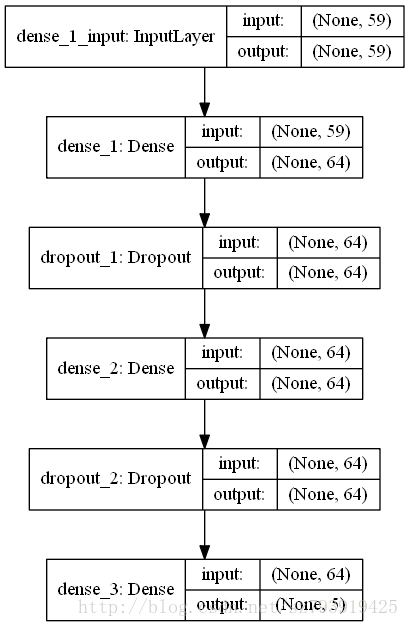
注意事项:
调用可视化的时候可能会报错如下:
RuntimeError: Failed to import pydot. You must install pydot and graphviz for
pydotprintto work
解决办法:
- 在命令行输入pip install pydot;pip install pydot-ng;pip install graphviz
- 下载graphviz安装包

解压后把bin目录添加到环境变量path中,重启pycharm。
9)程序所需要的训练数据和测试数据,(自制采集数据不容易,且下且珍惜)
感谢刘炫320 的博客