AAAI 2019——基于多层转换约束的联合抽取多三元组模型
AAAI 2019——Jointly Extracting MultipleTriplets with Multilayer franslation Constraints
论文地址:https://www.aaai.org/Papers/AAAI/2019/AAAI-TanZhen.5454.pdf
三元组抽取是自动化构建知识库的关键步骤,传统模型方法一般先处理实体识别,后处理关系分类,忽略了两个任务的关联性,容易造成误差的级联传播;近些年来,基于神经网络的联合方法模型兴起,但是绝大部分的模型只能从一个句子中提取一个三元组。现实场景中一个句子包含多个三元组是很常见的,本文基于上述问题提出了TME模型解决方案。
引言
三元组抽取的目标是抽取句子中实体和确定实体之间的关系。传统的pipeline模型方法存在忽略两个任务之间的关联性从而导致误差级联传播问题。近些年来提出来的联合抽取模型,则是基于不实用的假设约束,即:一个句子只有关系或者一个关系只是与前面的实体相关,以及还有的只是简单产生很多的实体候选集用于关系分类任务。这些模型忽略了现实生活中,一句话普遍存在多个三元组,比如如下图展示的句子:

本论文中,作者为了解决上述问题,提出了“基于多层转换约束的联合抽取多三元组模型”,即简称为“TME”,主要贡献在于以下四个方面:
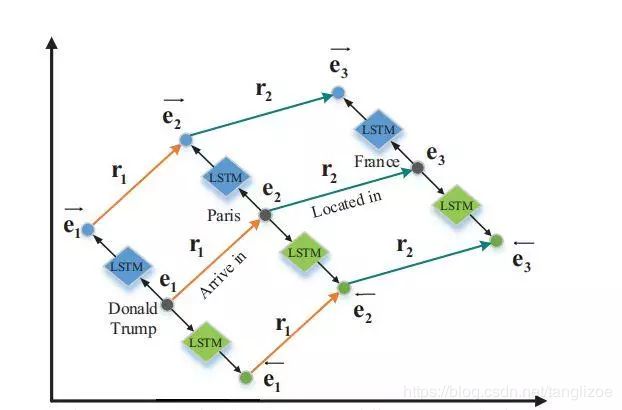
1.提出一个新颖的多层嵌入转换约束机制,用来解决关系中实体对的位置信息,具体如下图:
2.精心设计了一个新的标注方案(tri-part tagging sheme, 参考图1),用来解决区分候选实体集合,去掉不相关的实体,从而减少噪音;
3.设计了一个关系提取的方法,基于转化约束条件的预先设计的关系特征向量,对所有的候选关系进行排序打分,根据阈值来选择top-n triplets;
4.基于负采样的思想,构造相应负样例三元组集合,从而用于模型训练。
模型
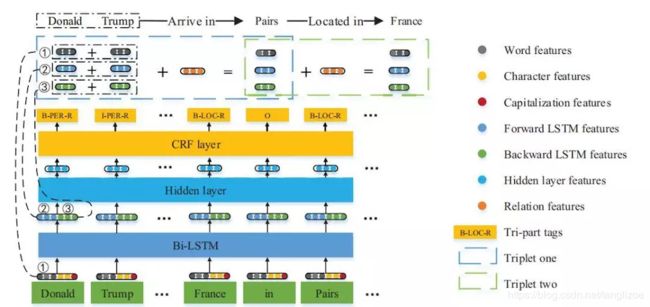
1.Embedding layer: 将序列位置i对应的word embedding, character embedding, capitalization embedding 进行拼接成一个向量,得到成对应位置Bi-LSTM层的input embedding;
2.Bi-LSTM & Hidden layer: 根据input embedding,分别计算出LSTM正向隐藏状态向量和LSTM反向隐藏状态向量,对二者进行拼接得到Hidden layer 某个t时刻的输入向量,该层计算公式如下:
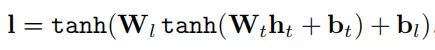
3.CRF layer: 将Hidden layer输出的所有l进行拼接得到矩阵L,其中维度大小为 s × d l s \times {d_l} s×dl(s为标记序列的长度), L i j L_{ij} Lij表示对应句子中第i个词对应的第j个tag对应的概率得分,假设得到标记序列y, 打分公式如下:
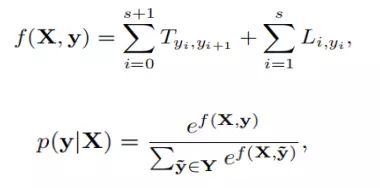
其中T表示转移概率矩阵, T i j T_{ij} Tij表示第i个tag到第j个tag的概率得分,Y表示所有可能的标记序列;
4.Tri-part tagging scheme(TTS): 序列标记方案,形式如B-PER-R, I-LOC-N等,包含三部分:
(1)position part(PP): 用BIO方式来进行位置标记;
(2)type part(TP): 用来标记实体的类型,本文实体类型总共有三种类型,即:PER, LOC, ORG;
(3)relation part(RP): 用来标记在句子中的实体是否涉及到某种关系,R/N分别表示涉及到某种关系和没有涉及到某种关系,本论文中总共预定义有24种关系。
5.多层转化机制:通过实体的嵌入表示,来构建多层模型,从而捕获关系特征,具体结构图示见图2。其中即为实体的嵌入表示, i表示实体在句子中的开始位置,j表示实体内的第j个单词,表示实体的长度,这里把实体内所有单词的embedding相加得到实体的嵌入表示,embedding layer和Bi-LSTM layer的实体各自的嵌入表示如下:
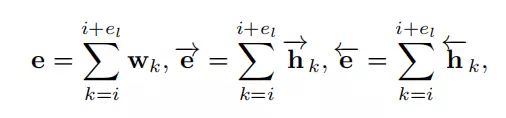
假设r表示relation embedding, 对于句子中某个三元组t=(e1, e2, r)来说,多层转化机制要求e1加上r约等于e2【和trans系列相似】,基于此机制得到embedding layer 和 Bi-LSTM layer各自的打分公式,如下:
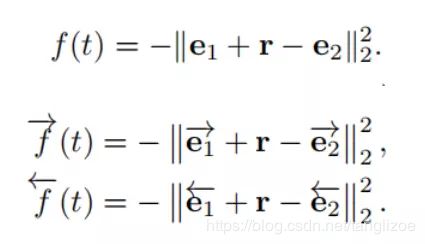
6.目标函数定义
(1)Bi-LSTM + CRF(实体识别部分), 求取最大化对数概率,目标函数定义如下:
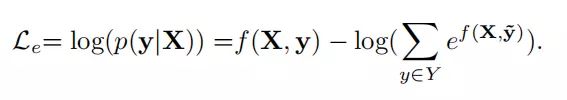
(2)Margin-based Relation Ranker(关系提取部分), 首先构造针对每一个三元组t=(e1, e2, r)构造负样本集合,负样本集合描述如下:
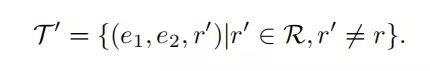
为了尽可能区分正负三元组样本,本论文提出了Margin-based Relation Ranker 方法,embedding layer的最大化loss function 形式化如下:
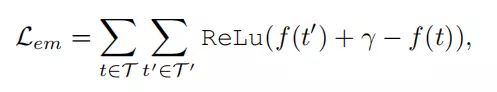
其中 γ \gamma γ> 0, 是一个超参数,用来约束正负三元组的边界。同理,Bi-LSTM layer的loss function 如下:
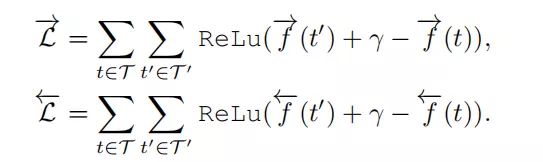
把上述三者相加得到relation ranker的损失函数, 如下:
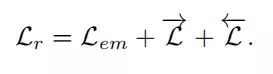
(3)联合训练实体识别和关系抽取,最终目标函数定义为:
![]()
其中 λ \lambda λ是超参数,用来平衡实体识别部分和关系抽取部分,训练方法采用随即梯度下降算法。
7.多三元组抽取:根据上述目标函数训练完成之后,得到相应模型。
- 首先,根据CRF对一个句子预测,得到打分最高的序列标记y; 接着从序列标记结果得到有关系的候选实体集合;
- 然后,对候选的实体对,对所有关系r进行打分,对三者相加得到最终的得分;
- 最后,根据得分对所有候选的三元组进行排序,根据指定的阈值得到top-n triplets。
这种该方法的优势是将关系分类任务转化为关系打分排序任务,使得能够自适应调整.
实验
数据集使用New York Times dataset,该数据集包含24种关系,实验结果如下
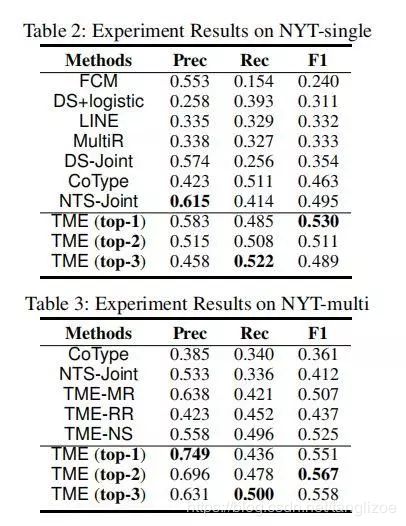
通过对比图中的NYT-single和NYT-multi的数据指标,显示出该模型更擅长于一个句子多三元组的抽取;其次,负采样可以有效提高P、R、F1相关指标。
结论
本论文采用”基于多层转换约束的联合抽取”方法,有效解决一个句子多个三元组抽取的问题,包含情况如下:
1.同一个实体对应多个不同的关系对;
2.同一个关系对应多个不同的实体对;
3.能够去除一些不相关的实体,即该实体并没有涉及到任何关系。
但是,有一点缺陷是,该模型要是用于其他领域数据的多三元组抽取,会面临多数模型都会遇到的问题,即:数据标注代价昂贵,此时可以结合远程监督的方法。