利用Anaconda安装TensorFlow
相关概念
1、人工智能:作为计算机的一个分支,目的在于利用机器模仿人类智能去完成一定的任务,从上世纪五十年代开始发展,经过多次起落,直到最近又一次掀起了人工智能的热潮。
2、机器学习:作为实现人工智能的一种方法,在上世纪八十年代出现。研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,进而重新组织已有的知识结构使之不断改善自身的性能。与人类的学习过程类似,通过对机器模型输入大量的相关数据进行训练,使得机器可以自己对新的输入做出正确反应。
3、深度学习:是机器学习的一种方法,通过建立具有阶层结构的人工神经网络,在计算系统中实现人工智能。从2010年以后开始变得火热。
4、机器学习的分类:
- 有监督的学习:事先需要准备好输入和正确的输入相配套的训练数据,让机器进行学习。例如,回归问题是预测连续的输入数据对应的输出值。分类问题的输出结果为离散的种类。
- 无监督的学习:输入数据只有特征没有标记,让机器自己抽取数据包含的模式与规则。对于给定的无标签数据集,无监督的聚类算法可以根据数据内部的联系自动将数据分成不同的聚类。例如聚类算法可以通过大量的用户数据将用户自动化分为不同的细分市场,在这之前我们并不知道要划分成哪些类别。
- 半监督的学习:输入数据大部分没有标记,通过对小部分有标记的数据规律总结,推广应用到其他数据
- 强化学习:无需初始数据,而是由机器根据激励函数通过接收环境对动作的奖励(反馈)获得学习信息并更新模型参数,错误惩罚或正确进行奖励,以取得最大化的预期利益。
5、人工神经网络(Artificial Neural Networks)
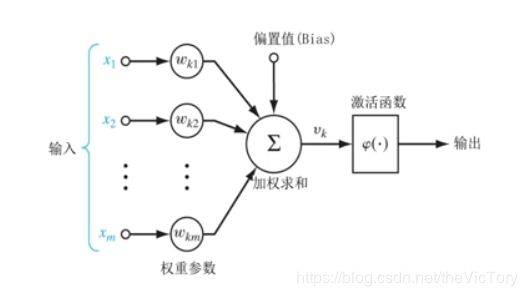
生物体的神经元通过树突感受外界刺激,产生信号经过轴突的判断与处理传递到下一个神经元,直到最后对外界刺激做出相应的反应。受此启发产生了神经元模型,通过对输入的自变量经权重参数的处理加权求和,再通过激活函数判断,产生输出。
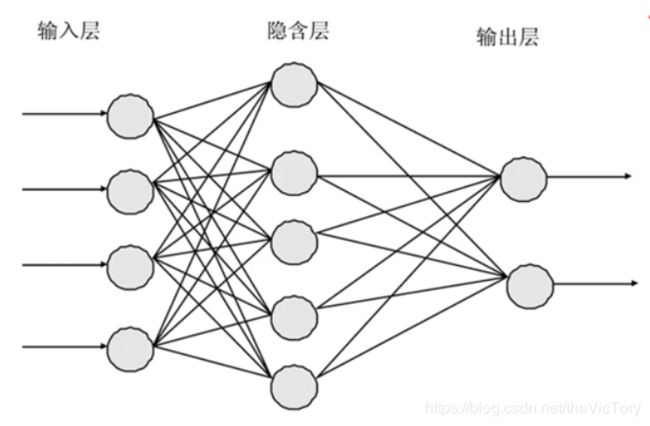
神经网络由多个神经元组成,在输入层接受输入数据后经过处理传递到下一层神经元,经过多个隐含层神经元处理后传递到输出层。
激活函数:神经元在处理数据后需要判断是否达到输出的阈值,满足则输出。常见的激活函数有S型、修正线性单元激活函数
配置Anaconda环境
1、Anaconda的安装:Anaconda是一个开源的包、环境管理器,其包含了conda、Python等180多个科学包及其依赖项,而且还包括Jupyter、Spyder等多个python开发所需工具。由于实际中需要使用不同的python环境,可以通过anaconda创建与管理不同的环境来运行项目。
在anaconda官网下载Windows版本的安装包,根据提示点击下一步完成安装。
2、添加清华的anaconda镜像源,通过国内镜像源下载更快
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/通过如下命令查看conda已经添加的镜像源
conda config --get channels3、创建与启动名为tensorflow的python环境。anaconda默认一个名为base的python环境。
conda create -n tensorflow python=3.7
conda activate tensorflow4、安装TensorFlow
查看tensorflow包信息
anaconda show anaconda/tensorflow 根据包信息最后的提示进行安装:
conda install –channel https://conda.anaconda.org/anaconda tensorflow5、测试
打开Jupyter Notebook,在右上角new新建一个python3文件,输入如下代码,按下Ctrl+Enter,运行显示TensorFLow版本
import tensorflow as tf
tf.__version__6、修改pip源
python的包管理工具是pip,通过pip可以对包依赖进行管理与下载,可以修改pip源地址使得下载速度更快,例如使用清华的镜像下载sklearn包:
pip install sklearn -i https://pypi.tuna.tsinghua.edu.cn/simple也可以修改pip设置一劳永逸地设置镜像源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple安装Tensor FLow的GPU版本
1、安装tensorflow-gpu
使用TensorFlow时,通过GPU进行运算与CPU相比在速度上具有明显的提升,因此可以安装另一个GPU版本的TensorFLow用于比较复杂的机器学习训练。
首先通过Anaconda创建并激活一个新的环境,之后命令行切换到新的环境下(tensorflow-gpu) C:\Users\Super>:
conda create -n tensorflow-gpu python=3.7
conda activate tensorflow-gpu通过conda info --env可以看到已经创建的环境,其中带*的为当前使用的环境:

通过pip包管理工具安装tensorflow-gpu版本:
pip install --ignore-installed --upgrade tensorflow-gpu 2、安装CUDA驱动
此时以及安装完成tensorflow-gpu版本,但是这时import tensorflow会报错,提示需要安装CUDA驱动。CUDA是英伟达显卡公司推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。不同的Tensor Flow版本需要不同的CUDA版本,其要求可以在Tensor FLow的官网介绍查到:https://www.tensorflow.org/install/gpu#software_requirements
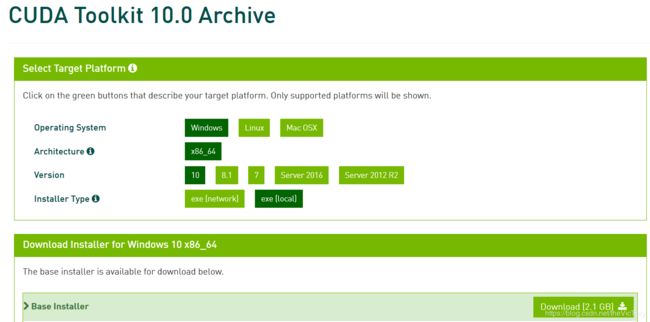
我的tensorflow是1.14版本,选择CUDA10.0,在CUDA官网:https://developer.nvidia.com/cuda-toolkit-archive选择对应的版本下载安装包并按照指示一步一步操作完成安装。
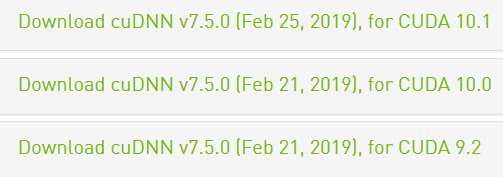
接着需要安装cuDNN,NVIDIA cuDNN是用于深度神经网络的GPU加速库,它强调性能、易用性和低内存开销,cuDNN可以集成到更高级别的机器学习框架中。在官网https://developer.nvidia.com/rdp/cudnn-archive选择CUDA对应的版本(如左下图),下载到本地后解压,产生如下右图文件夹
将每个文件夹下的内容复制到CUDA对应的安装目录下。例如将其中bin下的文件对应复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\bin目录下。
安装完成后重启电脑。
通过如下命令查看设备情况:
from tensorflow.python.client import device_lib
device_lib.list_local_devices()输出内容如下:
name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 17000744802228690105, name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 3146829004
locality {
bus_id: 1
links {
}
}
incarnation: 13189553194108047445
physical_device_desc: "device: 0, name: GeForce GTX 1050 Ti, pci bus id: 0000:01:00.0, compute capability: 6.1"]3、配置jupyter notebook
现在我们有两个anaconda环境,一个是系统自带的base,另一个是我们创建的tensorflow-gpu,base中自带安装了jupyter notebook而新环境中没有。如果我们希望通过jupyter notebook使用新环境有两种方法--在新环境中再安装一个notebook或者在base环境中调用新环境。这里选择第二种,为此我们需要为新环境tensorflow-gpu安装ipykernel:
conda activate tensorflow-gpu # 启动对应的tensorflow-gpu环境
conda install ipykernel # 在环境中安装ipykernel在base环境中的jupyter notebook中注入tensorflow-gpu的内核:
conda activate base # 切换回base环境
python -m ipykernel install --user --name tensorflow-gpu --display-name "TF-GPU"查看jupyter中的kernel
jupyter kernelspec list删除指定kernel:
jupyter kernelspec remove kernelname修改jupyter notebook默认工作目录
首先输入如下命令,生成设置文件 C:\Users\Super\.jupyter\jupyter_notebook_config.py:
jupyter notebook --generate-config找到该配置文件,将如下语句修改为默认工作目录位置:
c.NotebookApp.notebook_dir = 'D:\\Python\\jupyter'
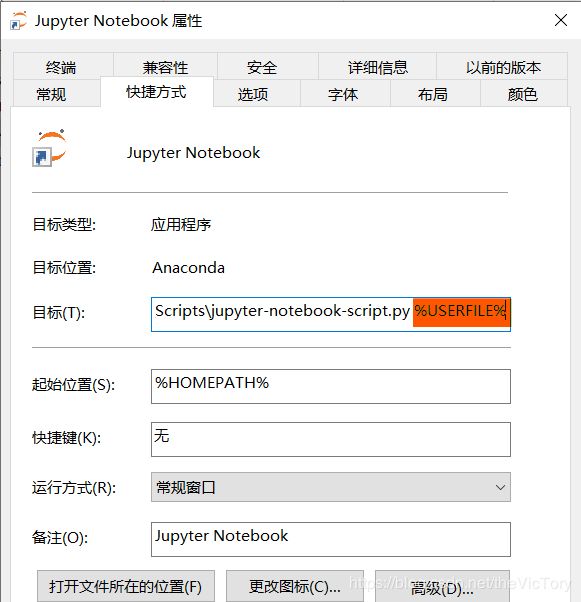
最后修改桌面快捷方式的启动位置,右键jupyter notebook快捷方式,选择属性弹出如下界面,将目标最后的%USERFILE%删去,保存后点击快捷方式启动,工作目录就是设置的D:\\Python\\jupyter
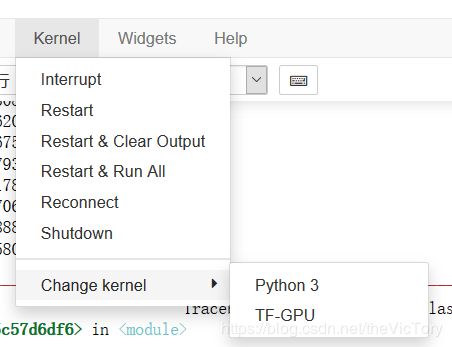
启动jupyter notebook并打开项目,可见其中的kernel可以进行切换
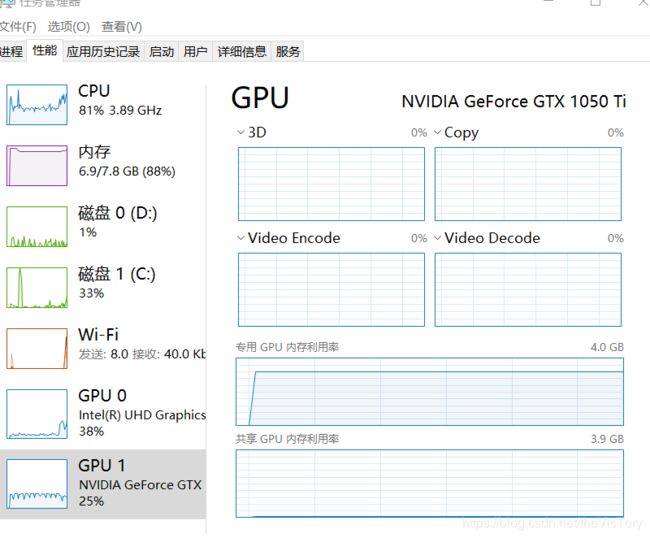
通过GPU版本的Tensor FLow运行卷积神经网络,速度明显加快,而且可以看到GPU参与运算,并且cpu的负载减少