Flink reduce 作用 实例
reduce作用:把2个类型相同的值合并成1个,对组内的所有值连续使用reduce,直到留下最后一个值!
package reduce;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
/**
* @Author you guess
* @Date 2020/6/17 20:52
* @Version 1.0
* @Desc
*/
public class DataStreamReduceTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource> src1 = env.addSource(new SourceFunction>() {
@Override
public void run(SourceContext> ctx) throws Exception {
ctx.collect(Tuple3.of("Lisi", "Math", 1));
ctx.collect(Tuple3.of("Lisi", "English", 2));
ctx.collect(Tuple3.of("Lisi", "Chinese", 3));
ctx.collect(Tuple3.of("Zhangsan", "Math", 4));
ctx.collect(Tuple3.of("Zhangsan", "English", 5));
ctx.collect(Tuple3.of("Zhangsan", "Chinese", 6));
}
@Override
public void cancel() {
}
}, "source1");
// src1.print();
// 7> (Zhangsan,Chinese,6)
// 4> (Lisi,Chinese,3)
// 2> (Lisi,Math,1)
// 5> (Zhangsan,Math,4)
// 3> (Lisi,English,2)
// 6> (Zhangsan,English,5)
/**
* 代码段2
*/
// src1.keyBy(0).reduce(new ReduceFunction>() {
// @Override
// public Tuple3 reduce(Tuple3 value1, Tuple3 value2) throws Exception {
// return Tuple3.of(value1.f0, "总分:", value1.f2 + value2.f2);
// }
// }).print();
// 1> (Lisi,Math,1)
// 11> (Zhangsan,Math,4)
// 1> (Lisi,总分:,3)
// 11> (Zhangsan,总分:,9)
// 1> (Lisi,总分:,6)
// 11> (Zhangsan,总分:,15)
/**
* 代码段3,与代码段2 同义
*/
src1.keyBy(0).reduce((value1, value2) -> Tuple3.of(value1.f0, "总分:", value1.f2 + value2.f2)).print();
// 1> (Lisi,Math,1)
// 11> (Zhangsan,Math,4)
// 1> (Lisi,总分:,3)
// 11> (Zhangsan,总分:,9)
// 1> (Lisi,总分:,6)
// 11> (Zhangsan,总分:,15)
env.execute("Flink DataStreamReduceTest by Java");
}
}
前面几个aggregation是几个较为特殊的操作,对分组数据进行处理更为通用的方法是使用reduce算子。
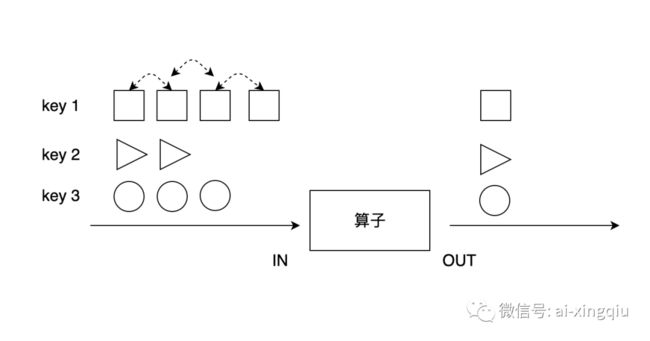
上图展示了reduce算子的原理:reduce在按照同一个Key分组的数据流上生效,它接受两个输入,生成一个输出,即两两合一地进行汇总操作,生成一个同类型的新元素。
https://mp.weixin.qq.com/s/2vcKteQIyj31sVrSg1R_2Q
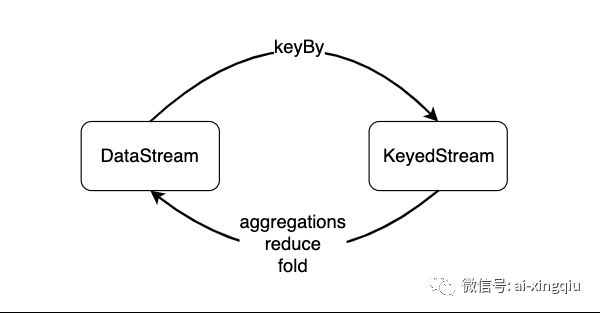
DataStreamSource没有aggregate(min minby max maxby sum等)、reduce操作;
KeyedStream、AllWindowedStream、DataSet有aggregate(min minby max maxby sum等)、reduce操作;
Flink ,Min MinBy Max MaxBy sum实例




flink 1.9.2,java1.8
源码:注意看注释:
/**
* Base interface for Reduce functions. Reduce functions combine groups of elements to
* a single value, by taking always two elements and combining them into one. Reduce functions
* may be used on entire data sets, or on grouped data sets. In the latter case, each group is reduced
* individually.
*
* For a reduce functions that work on an entire group at the same time (such as the
* MapReduce/Hadoop-style reduce), see {@link GroupReduceFunction}. In the general case,
* ReduceFunctions are considered faster, because they allow the system to use more efficient
* execution strategies.
*
*
The basic syntax for using a grouped ReduceFunction is as follows:
*
{@code
* DataSet input = ...;
*
* DataSet result = input.groupBy().reduce(new MyReduceFunction());
* }
*
* Like all functions, the ReduceFunction needs to be serializable, as defined in {@link java.io.Serializable}.
*
* @param Type of the elements that this function processes.
*/
@Public
@FunctionalInterface
public interface ReduceFunction extends Function, Serializable {
/**
* The core method of ReduceFunction, combining two values into one value of the same type.
* The reduce function is consecutively applied to all values of a group until only a single value remains.
*
* @param value1 The first value to combine.
* @param value2 The second value to combine.
* @return The combined value of both input values.
*
* @throws Exception This method may throw exceptions. Throwing an exception will cause the operation
* to fail and may trigger recovery.
*/
T reduce(T value1, T value2) throws Exception;
}
DataSet下:
