论文笔记,物体六自由度位姿估计,DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion
论文笔记,物体六自由度位姿估计,DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion
- 链接
- 摘要
- 1,引言
- 2,模型
- 2.1,整体架构
- 2.2,步骤a:color embedding
- 2.3,步骤b:geometry embedding
- 2.4,步骤c:feature fusion & pose estimation
- 2.4,步骤d:Iterative Refinement
- 3,实验
链接
论文下载地址:https://arxiv.org/abs/1901.04780
主页地址(代码视频):https://sites.google.com/view/densefusion/
GIthub代码地址:https://github.com/j96w/DenseFusion
Youtube视频地址:https://youtu.be/SsE5-FuK5jo
摘要
从RGB-D图像中进行6D目标姿态估计的一个关键技术挑战是充分利用彩色和深度这两个互补的数据源。以前的工作要么从RGB图像和深度中单独提取信息,要么使用昂贵的后处理步骤,限制了它们在高度混乱的场景和实时应用程序中的性能。
在这项工作中,我们提出了一种用于从RGBD图像中估计一组已知对象的6D位姿的通用框架DenseFusion。DenseFusion是一种异构的体系结构,它分别处理两个数据源,并使用一种新的dense fusion network (DenseNet介绍1)来提取像素级的 dense feature embedding(Embedding层介绍2),并从中估计姿态。此外,我们整合了一个端到端迭代的位姿细化过程,进一步改进了位姿估计,同时实现了近乎实时的处理速度。实验结果表明,该方法在YCB-Video和LineMOD两种数据集上均优于现有的方法。我们还将所提出的方法应用到一个真实的机器人上,根据所估计的姿态来抓取和操纵物体。
1,引言
6D 目标姿态估计对许多重要的现实应用都很关键,例如机器人抓取与操控、自动导航、增强现实等。理想情况下,该问题的解决方案要能够处理具有各种形状、纹理的物体,且面对重度遮挡、传感器噪声、灯光条件改变等情况都极为稳健,同时还要有实时任务需要的速度。RGB-D 传感器的出现,使得在弱灯光环境下推断低纹理目标姿态的准确率比只用 RGB 方法的准确率更高。尽管如此,已有的方法难以同时满足姿态估计准确率和推断速度的需求。
传统方法首先从 RGB-D 数据中提取特征,完成对应的分组和假设验证。但是,对手动特征的依赖和固定的匹配程序限制了它们在重度遮挡、灯光变化环境下的表现。近来在视觉识别领域取得的成果激发了一系列数据驱动方法,即使用 PoseCNN 和 MCN 这样的深度网络对 RGB-D 输入做姿态估计。
然而 PoseCNN 和 MCN 这些方法需要一个精心制作的后处理步骤,这样会导致两个问题:
- 这些微调步骤又不能与最终目标函数联合优化;
- 对于实时应用程序来说速度非常慢。
在自主驾驶的背景下,有一种第三方解决方案被提出,它能够通过 PointNet 和 PointFusion 这样的端到端深度模型很好地利用 RGB-D 数据中颜色和深度信息的进行补充。这些模型取得了非常好的表现,也有很好的实时推理能力。但是,根据经验可知,这些方法在重度遮挡环境下效果不好,而重度遮挡又在实际情况中非常常见。
在本文中,研究者提出一种端到端的深度学习方法,对 RGB-D 输入的已知物体进行 6D 姿态估计。该方法的核心是在像素级别嵌入和融合 RGB 值和点云,而不是使用以前通过图像裁剪来计算全局特性或2D边界框的方法。这种像素级融合方法使得本文的模型能够明确地推理局部外观和几何信息,这对处理重度遮挡情况至关重要。此外,研究者还提出了一种迭代方法,能够在端到端学习框架中完成姿态微调。这极大地提高了模型性能,同时保证了实时推理速度。
研究者在两个流行的 6D 姿态估计基准——YCB-Video 和 LineMOD 上评估了他们的方法。结果表明,在经过 ICP 改进后,该方法的性能超越了当前最佳的 PoseCNN,其姿态估计准确率提高了 3.5%,推断速度提高了 200 倍。值得一提的是,新方法在高度杂乱的场景中表现出了鲁棒性。最后,研究者还在一个真实的机器人任务中展示了它的用途,在这项任务中,机器人估计目标的姿态并抓取它们以清理桌面。
本文认为有两点主要贡献:
- 提出了一种将RGB-D输入的颜色和深度信息融合起来的基础方法。利用嵌入空间中的2D信息来增加每个3D点的信息,并使用这个新的颜色深度空间来估计6D位姿。
- 在神经网络架构中集成了一个迭代的微调过程,消除了之前后处理ICP步骤的依赖性。
2,模型
研究者的目标是在混乱场景的 RGB-D 图像中估计出一组已知目标的 6D 姿态。通常情况下,将 6D 姿势视为齐次变化矩阵,p ∈ SE(3)。既然是从拍摄图像中对目标进行 6D 姿态的估计,那么目标姿态就要相对于相机的坐标框架来定义。要想在不利的条件下(例如,重度遮挡,光线不足等)估计已知目标的姿态,只有结合颜色和深度图像通道中的信息才有可能。但是,这两个数据源是不同空间的。因此,从异质数据源中提取特征并把它们恰当地融合在一起是这个领域中的主要技术挑战。
研究者通过以下方式来应对这一挑战:(1)一个能够分别处理颜色和深度图像信息并且可以保留每个数据源原始结构的异质框架;(2)一个通过利用数据源间的内在映射融合颜色-深度图像信息的密集像素级融合网络。最后,姿态估计可以通过可微分的迭代微调模块进一步微调。相较于昂贵的后处理步骤,本文中的微调模块能够和主架构一起训练,并且耗时很少。
2.1,整体架构

上述模型的架构主要包含两个阶段。第一个阶段将彩色图像作为输入,为每个已知的目标类别执行语义分割。接下来,对于每个分割后的目标,研究者将masked深度像素(转换为 3D 点云)及边框裁剪的图像块导入到第二阶段。
第二个阶段处理分割的结果并估计目标的 6D 姿态。它包含四个部分:a)一个处理颜色信息的全卷积网络,该网络将图像块中的每个像素映射到一个颜色特征embedding;b)一个基于 PointNet 的网络,该网络将带有masked 3D 点云中的每个点处理为一个几何特征embedding;c)一个像素级的 fusion 网络,该网络将两个embeddings 结合起来并基于无监督置信度得分输出目标的 6D 姿态估计;d)一个迭代的自微调方法,该方法以课程学习的方式对网络进行训练,并迭代地微调估计结果。前三个步骤见上图,最后一个步骤见下图。
2.2,步骤a:color embedding
通过CNN将 H × W × 3 的图像映射到 H × W × d 的 embedding 空间,embedding 层的每个像素都是一个d维向量,表示输入图像在相应位置的外观信息。没什么毛病,常规操作。
2.3,步骤b:geometry embedding
作者认为在处理深度信息时,之前的方法都是使用CNN将深度图像作为额外的图像通道进行处理。这种方法忽略掉了深度信息所对应的三维结构。所以作者加了一个步骤,通过相机内参将深度图转换为空间点云,然后用处理点云的方式来提取几何特征,这里作者用的是PointNet的一个变体,将PointNet上实现置换不变性3的最大池化改为了平均池化。(虽然这种方式从信息量上来说仅仅是在深度信息上加入了相机内参的信息,可能并不能带来多少好处。更大的优势可能是PointNet这种处理三维点云的框架比以CNN处理二维图像的框架更能有针对性地挖掘深度图中的三维特征。)
2.4,步骤c:feature fusion & pose estimation
作者认为如果仅仅做一个常规操作:从分割区域的密集颜色和深度特征中生成全局特征 ,是不够的。特别是在出现遮挡和物体分割时存在错误的情况下,很容易降低性能。针对这样的问题,作者提出一种新的融合方法,其密集融合网络的核心思想是局部逐像素融合,而不是全局融合,这样就可以根据每个融合的特征进行预测。通过这种方法,可以选择基于对象可见部分的预测,并最小化遮挡和分割噪声的影响。:
首先在像素级别做了一个color embeddings和geometry embeddings的concatenate,concatenate的结果作为per-pixel feature。
然后将per-pixel feature通过一个多层感知机+平均池化后输出一个global feature,全局特征的作用作者是这么说的:“虽然我们避免使用单一的全局特性进行估计,但是在这里,我们使用全局的紧密融合特性来丰富每个密集的像素特性,从而提供一个全局上下文。”
最后将global feature与每个像素的per-pixel feature再进行一次concatenate,得到最终像素的特征。
这样每个像素的融合特征就成为了一个由三部分组成的向量:

其中:
红色部分:当前像素的彩色特征。
蓝色部分:当前像素的空间几何特征(深度)。
绿色部分:通过多层感知机求出的全局特征,这部分每个像素应该是一样的。
然后将每个像素的特征输入一个最终的网络,这个网络可以预测物体的6D姿态。
2.4,步骤d:Iterative Refinement
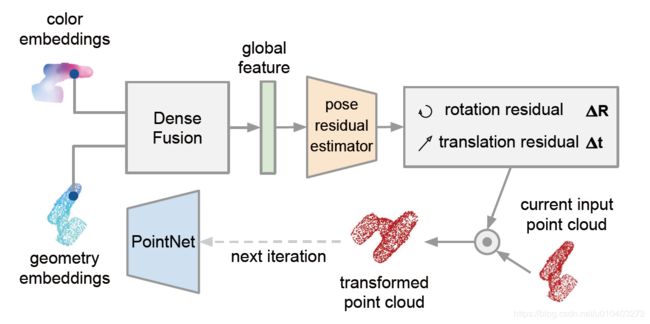
【步骤d】:如上图,这是一个迭代过程,利用了上一帧计算出来的位姿,对当前帧输入的点云进行位移和旋转变换,并输入到下一帧去,进入PointNet提取embeddings。文章将这个迭代器称为位姿残差估计器,认为它可以与主网络联合训练。然而,训练开始时的姿态估计噪声太多,以至于它无法学到任何有意义的东西。因此,在实践中,要在主网络收敛之后再对位姿残差估计器进行学习。从作者的实验结果看,这一个步骤非常重要,对准确率的提高很明显。
3,实验
在实验部分,文章回答了以下问题:
- (1)与单纯的全局级联融合相比,密集融合网络是如何实现的?
- (2)密集融合预测方案对强遮挡和分割误差鲁棒吗?
- (3)迭代细化模块是否改善了最终的姿态估计?
- (4)我们的方法对于机器人抓取等下游任务是否足够健壮和有效?
为了回答前三个问题,我们在两个具有挑战性的6D对象姿态估计数据集上评估了我们的方法: YCB-Video Dataset 和 LineMOD 。YCB-Video数据集具有不同遮挡条件下不同形状和纹理层次的对象。因此,这对于我们这个抗遮挡的多模态融合方法是一个理想的实验平台。LineMOD数据集是一个广泛使用的数据集,它允许我们与更广泛的现有方法进行比较。
我们将我们的方法与最先进的方法 Ssd-6d 和 Posecnn 以及模型变体进行比较。
为了回答最后一个问题,我们将我们的模型部署到一个真实的机器人平台上,并利用模型中的预测来评估机器人抓取任务的性能。
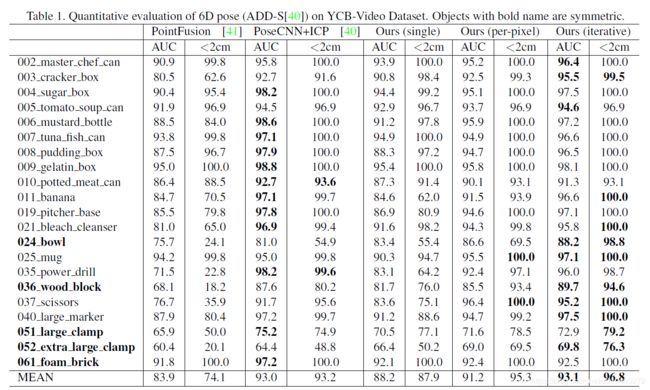
表 1:在 YCB-Video 数据集上对 6D 姿态(ADD-S)进行定量评估。加粗的目标是对称的。
文章和PoseCNN一样估计了ADD-S曲线下的面积(AUC4)。文章按照之前的工作,将AUC的最大阈值设置为0.1m。文章还报告了小于2cm (<2cm)的ADD-S的百分比,它测量了机器人操作的最小公差下的预测(大多数机器人夹持器为2cm)。
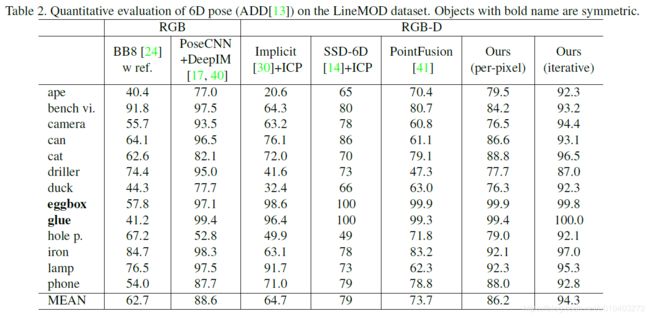
表 2:在 LineMOD 数据集上对 6D 姿态(ADD)进行定量估计。加粗的目标是对称的。

遮挡程度不断加大时模型性能的变化。通过计算图像帧中每个目标不可见表面的百分比来估计遮挡程度。与基线方法相比,本文的方法在重度遮挡的情况下表现更稳健。

表 3:运行时分解(YCBVideo 数据集上每帧的秒数)。本文的方法几乎比 PoseCNN+ICP 快了 200 倍。Seg 表示 Segmentation(分割),PE 表示 Pose Estimation(姿态估计)。
DenseNet介绍 ↩︎
Embedding层介绍 ↩︎
基于点云的置换不变性介绍 ↩︎
AUC和ROC介绍 ↩︎