【ELK】ELK6.2.2全文检索

婷婷@洋葱OMALL 点击打开链接
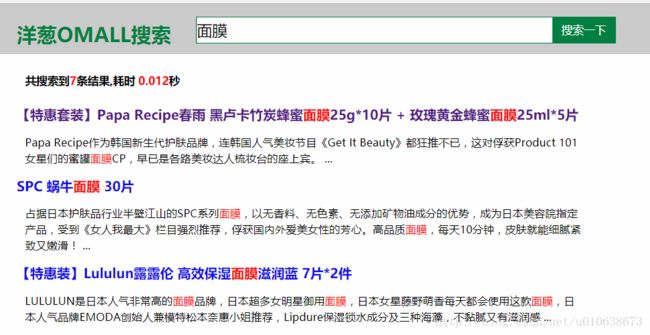
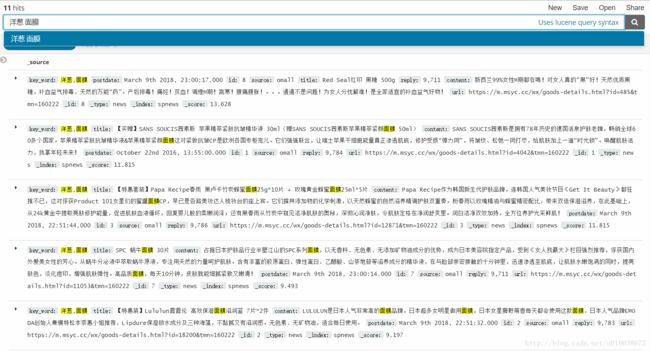
做了个海外购检索案例,项目演示


服务器搭建平台管理
安装软件包
| 序号 | 版本名称 | 软件下载 |
| 1 | elasticsearch-6.2.2.tar.gz | https://www.elastic.co/downloads/elasticsearch |
| 2 | elasticsearch-head-6.2.2.zip | https://github.com/mobz/elasticsearch-head |
| 3 | elasticsearch-analysis-ik-6.2.2.zip | https://github.com/medcl/elasticsearch-analysis-ik/releases |
| 4 | jdk1.8.0_155 | http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html |
| 5 | kibana-6.2.2-linux-x86_64.tar | https://www.elastic.co/downloads/kibana |
| 6 | logstash-6.2.2.zip | https://www.elastic.co/downloads/logstash |
| 7 | x-pack-6.2.2.zip | https://www.elastic.co/downloads/x-pack |
| 8 | fuse-2.8.5.tar.gz | https://www.fusetools.com/downloads |
本人是在虚拟机Linux6.8_64位进行安装的
一、ELK6服务器部署搭建-JDK1.8.0_155
使用Xftp工具,登录hadoop用户,将文件上传到 /elk/install 文件夹下面,如果忘记使用了root用户上传的话,
可以使用命令修改: chown -R hadoop.hadoop /elk/install/
1.说明 (#代表root用户,$代表hadoop自己创建的用户,【】代表注意强调)
2、创建用户和赋权
新建文件:
# mkdir -p /elk/install
新建用户和组:
# groupadd -g 800 hadoop
# useradd -u 800 -g 800 hadoop
# passwd hadoop
赋予文件夹 权限
# chown -R hadoop.hadoop /elk
# chown -R hadoop.hadoop /elk/install/
3、JDK安装配置(本人使用hadoop登录进行安装)
3.1.DK1.8.0_安装配置
$ cd /elk/install
$ tar zxvf jdk-8u151-linux-x64.tar.gz
$ vim ~/.bash_profile 【shift+“:”中英切换,使用英文冒号;wq保存退出;q!不保存强制退出;】
#set java path for weblogic
export JAVA_HOME=/elk/install/jdk1.8.0_151
export CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
$ source ~/.bash_profile 【立即生效】
查看效果
$ java -version
$ javac

二、ELK6服务器部署搭建-Elasticsearch6.2.2
将文件上传到 /elk/文件夹下面
$ cd /elk/
$ chmod 755 *.gz *.zip
$ tar zxvf elasticsearch-6.2.2.tar.gz
$ vim /elk/elasticsearch-6.2.2/config/elasticsearch.yml
$ mkdir -pv /elk/data_es/elasticsearch/{data,logs}
切换到root账号进行修改
#vim /etc/security/limits.conf 添加
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
# vim /etc/sysctl.conf 添加
vm.max_map_count= 655360
sysctl -p 【进行立即生效,如果启动报错可能是未生效,进行logout注销账号重新登入启动,就没事了】
vi /etc/security/limits.d/90-nproc.conf
max number of threads [1024] for user [elsearch] likely too low, increase to at least [4096]修改如下内容:
* soft nproc 1024
#修改为
* soft nproc 4096
注销 logout
用hadoop登录,进行修改elasticsearch配置文件
$ vim /elk/elasticsearch-6.2.2/config/elasticsearch.yml 【编写时候名称与值之间是冒号+空格,小心别敲错!!!】
#cluster.name指定集群的名称,主要设置集群,同一个集群的节点要设置在同一个集群名称。如果不配置该项,系统默认取elasitcsearch
cluster.name: my-application
#node.name指定节点的名称,同一集群的节点名称不能相同,如果不配置该项,系统会随机分配一个名称
node.name: node-185
#关于数据和日志的存放路径的,后期版本升级,如果程序与数据分离,将非常容易实现
path.data: /elk/elasticsearch-6.2.2/data/elasticsearch/data
path.logs: /elk/elasticsearch-6.2.2/data/elasticsearch/logs
#启动后是否锁定内存,提高ES的性能
bootstrap.memory_lock: false
#bootstrap.system_call_filter为true进行检测,导致检测失败,失败后直接导致ES不能启动
bootstrap.system_call_filter: false
#关网络的设置,比如RESTful接口,包括curl、浏览器、Kibana等HTTP连接过来
#network.host设置对外的网关IP,默认本地回环。
network.host: 192.168.56.185
#http.port设置对外的端口,端口建议重新设置,提高安全性。默认9200
http.port: 9200
#transport.tcp.port 设置TCP传输端口,这个端口也非常重要,首先,下面Discovery部分的设置,
#集群内节点发现走的就是这个端口,发现后,节点之前传输数据也是走这个TCP端口。
#另外,官方提供的ES JAVA API也是通过这个端口传输数据的。
discovery.zen.fd.ping_timeout: 120s
discovery.zen.fd.ping_retries: 6
discovery.zen.fd.ping_interval: 30s
cluster.routing.allocation.cluster_concurrent_rebalance: 40
cluster.routing.allocation.node_concurrent_recoveries: 40
cluster.routing.allocation.node_initial_primaries_recoveries: 40
http.host: 192.168.56.185http.cors.enabled: true
http.cors.allow-origin: "*"
#指定是否为主节点。该属性可不指定,节点之间自主选择。
node.master: false
#指定是否存储数据(数据节点)
node.data: true
#node.ingest: false
#search.remote.connect: false
#主要设置集群的节点之间的连接,
#discovery.zen.ping.unicast.hosts设置集群内节点的主机,比如集群内有两台机192.168.56.185,192.168.56.184,TCP端口都设置为9300
#discovery.zen.ping.unicast.hosts: ["192.168.56.185"]
#dbUrl: jdbc:mysql://192.168.56.100:3306/solr_doc
#dbUser: root
#dbPwd: Xutao123
#dbTable: t_es_ik_dic
#extField: ext_word
#stopField: stop_word
#flushTime: 500000
#autoLoadIkDic: true
只查看配置文件中未被注释的有效配置行
$ grep '^[^#]' /elk/elasticsearch-6.2.2/config/elasticsearch.yml
假如设置了bootstrap.memory_lock: true
需要在/etc/security/limit.conf文件最后追加两行
* soft memlock unlimited
* hard memlock unlimited
然后开始启动
[hadoop@localhost bin]$ ./elasticsearch
[2018-03-09T13:00:16,286][INFO ][o.e.n.Node ] [node-185] initializing ...
.........
[2018-03-09T13:00:22,289][INFO ][o.e.n.Node ] [node-185] starting ...
[2018-03-09T13:00:22,503][INFO ][o.e.t.TransportService ] [node-185] publish_address {192.168.56.185:9300}, bound_addresses {192.168.56.185:9300}
[2018-03-09T13:00:22,516][INFO ][o.e.b.BootstrapChecks ] [node-185] bound or publishing to a non-loopback address, enforcing bootstrap checks
[2018-03-09T13:00:25,559][WARN ][o.e.d.z.ZenDiscovery ] [node-185] not enough master nodes discovered during pinging (found [[]], but needed [-1]), pinging again
[2018-03-09T13:00:28,562][WARN ][o.e.d.z.ZenDiscovery ] [node-185] not enough master nodes discovered during pinging (found [[]], but needed [-1]), pinging again
红色信息一直后台刷,原因是需要一个master节点,需要把
node.master: false
改成
node.master: true
因为本人master是另外一台端口9201上面,自行修改重新启动
使用最新google浏览器进行查看
{
"name" : "node-185",
"cluster_name" : "my-application", 【Cluster集群名称,可自行修改集群时候对应上】
"cluster_uuid" : "_na_", 【UUDI】
"version" : {
"number" : "6.2.2", 【es版本信息】
"build_hash" : "10b1edd",
"build_date" : "2018-02-16T19:01:30.685723Z",
"build_snapshot" : false,
"lucene_version" : "7.2.1", 【Lucene版本信息】
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}午休,后续....
三、ELK6服务器部署搭建-Elasticsear-head
四、ELK6服务器部署搭建-Kibana