Flink 入门教程
大数据处理的应用场景
大数据是近些年才出现的吗,人们是近些年才发现大数据的利用价值的吗?其实不然,早在几十年前,数学分析就已经涉猎金融行业了,人们依托于金融和数学知识来建立数学模型,利用金融市场所产的数据来预测金融市场产品收益同风险波动的关系。
到如今,互联网也发展了好些年了,越来越多的数据产生(用户浏览数据、搜索记录、出行记录、消费记录;农作物的成长观察记录;病人的医疗记录等),各行业也开始慢慢的重视起这些数据记录,希望通过对这些数据的分析处理从而得到相应的利益和研究价值。
简单举几个例子,大数据处理可适用在在如下一些场景:
- 医疗大数据、看病更高效(病例病理分析、基因数据分析)
- 电商大数据、精准营销法宝(杀熟、哈哈哈哈或)
- 零售大数据、最懂消费者(用户画像,精准推送)
- 金融大数据、理财利器 (大数据选股)
- 交通大数据、畅通出行 (城市大脑)
…
大数据处理架构
各行各业都开始了大数据之路,大量的数据处理,靠人力那是靠不住的,得依靠计算机来。那这自然是少不了程序猿的。那么程序员GG们是如何简洁高效的处理利用这些大数据的呢?
好比普通的web服务应用,有其对于的微服务架构一样,大数据处理也有其对应的处理架构,且这些架构和微服务处理机构类似,都是为了能够满足现实的要求,那么大数据架构有哪些关键特性是需要满足的,主要如下:
- 容错性和健壮性: 分布式系统所必须的,好比微服务架构,你无法保证肯定不出错但也不能总出错
- 低延迟:很多应用对于读和写操作的延时要求非常高,要求对更新和查询的响应是低延时的。
- 横向扩容:数据的增幅增速是惊人的,系统需要能通过横向拓展满足与日俱增的数据增量
- 可扩展:扩展新功能时付出较少的代价
- 方便查询:大数据系统本质还是需要输出的,输出的数据需要方便查询
- 易于维护
针对上述的这些特性要求,大佬们早已设计出了一些架构和处理框架,让我们一起来了解下。
目前主流的大数据处理架构,这里就讲两个: Lambda Architecture 和 Kappa Architecture
需要注意的是,Lambda 和 Kappa两大架构都不是一个具有实体的软件产品,而是一个指导大数据系统搭建的架构模型。因此,用户可以根据自己的需要,在架构模型中任意集成Hadoop,Hbase,Kafka,Storm,Spark、Flink等各类大数据组件。
Lambda 架构
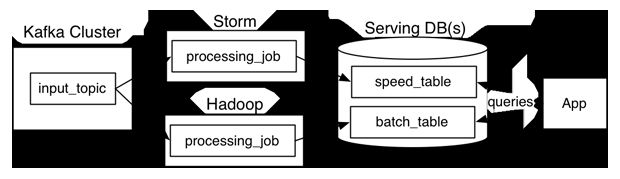
Lambda架构是Nathan Marz提出的一个大数据处理框架。该框架的做法是将大数据系统架构拆分成了三层:

- Batch Layer:该层主要利用分布式处理系统处理大批量的数据,在数据集上预先计算查询函数,并构建查询所对应的Batch View。即所谓的批处理,适合处理离线数据。这一层中常用的框架是 Apache Hadoop这一套,存储一般用 Elephant DB, Apache Impala, SAP HANA 或 Apache Hive
- Speed Layer :该层的目的是提供低延时的 Real-time View,处理的都是实时的增量数据。
这一层中常用的流数据处理框架有Apache Storm, Apache Spark, Apache Flink. 输出通常是存储在高速的 NoSql 数据库中。存储一般用 Elasticsearch - Serving Layer:Serving Layer 用于响应用户的查询请求,它将 Batch Views 和 Real-time Views 的结果进行了合并,得到最后的结果。
这一层通常就是使用的 Apache Druid,存储一般用 Apache Cassandra, Apache HBase, MongoDB
结合框架后,一个可能的架构:
优点:
同时支持实时和批处理业务(既保证了低延迟又保证了准确性)
缺点:
- Lambda 架构需要在两个不同的 API(application programming interface,应用程序编程接口)中对同样的业务逻辑进行两次编程:一次为批量计算的系统,一次为流式计算的系统。针对同一个业务问题产生了两个代码库,各有不同的漏洞。这种系统实际上非常难维护。
- 随着数据增量的增大,T+1 的批处理计算时间可能不够(当天的数据,一个晚上可能处理不完)
- 实时与批量计算结果不一致引起的数据口径问题
Kappa 架构
Lambda 架构需要维护两套代码,两套系统(批处理和实时处理);在某些情况下,这是非常不划算且没必要的,为什么实时流数据用后就丢弃,为什么不用流计算系统来进行全量数据处理从而去除Batch Layer这一层?
于是,Jay Kreps 在 2014 提出了Kappa 架构,它可以看做是 Lambda 架构的简化版,就是讲 Lambda 架构中的批处理模块移除,移除后如下:
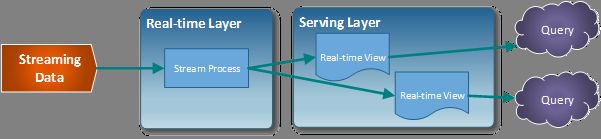
其核心思想就是,使用系统( eg. kafka )保存历史消息数据, 然后通过回放数据,利用 Real-time Layer 这一层的流处理框架( eg. Flink , Spark Streaming , Storm )来完成业务上的批处理需求。核心步骤如下:
- 数据需要可以被重放(重新处理)。例如, 用 Kafka 来保存数据,你需要几天的数据量就保存几天。
- 用新实例重新处理计算重放的数据。即当需要全量重新计算时,重新起一个流计算实例,从头开始读取数据进行处理,并输出到一个新的结果存储中。
- 当新的实例做完后,停止老的流计算实例,并把老的一些结果删除。
Kappa 和 Lambda 对比
| 对比项 | Lambda架构 | Kappa架构 |
|---|---|---|
| 数据处理能力 | 可以处理超大规模的历史数据 | 历史数据处理的能力有限 |
| 机器开销 | 批处理和实时计算需一直运行,机器开销大 | 必要时进行全量计算,机器开销相对较小 |
| 存储开销 | 只需要保存一份查询结果,存储开销较小 | 需要存储新老实例结果,存储开销相对较大 |
| 开发、测试难易度 | 实现两套代码,开发、测试难度较大 | 只需面对一个框架,开发、测试难度相对较小 |
| 运维成本 | 维护两套系统,运维成本大 | 只需维护一个框架,运维成本小 |
Flink 框架在大数据架构中的应用
如上描述,在大数据架构处理中涉及到了流数据处理。特别是在 Kappa 架构中,去除了批处理层,只留下了 Real-time Layer. 所以,支持流数据处理的框架就显得额外的重要,最好是还能支持批处理。在 Kappa 架构中,由于需要使用实时流处理的结果来替代 Lambda 架构中批处理的结果,所以其在选择流数据框架对数据的一致性支持要求会更高。在选择流数据处理框架的时候需要将这个考虑进去。那么目前比较常用的流数据处理框架有哪些呢?各框架又有什么异同呢?
目前主流的流数据处理框架: Storm (Storm Trident)、Spark Streaming、Flink
- Storm:支持低延迟,但是很难实现高吞吐,并且不能保证 exactly-once
- Sparking Streaming ( Storm Trident ):利用微批处理实现的流处理(将连续事件的流数据分割成一系列微小的批量作业),能够实现 exactly-once 语义,但不可能做到完全实时(毕竟还是批处理,不过还是能达到几秒甚至几亚秒的延迟)
- Flink:实时流处理,支持低延迟、高吞吐、exactly-once 语义、有状态的计算、基于事件时间的处理
相对来说,Flink实现了真正的流处理,并且做到了低延迟、高吞吐 和 exactly-once 语义;同时还支持有状态的计算(即使在发生故障时也能准确的处理计算状态) 和 基于事件时间的处理
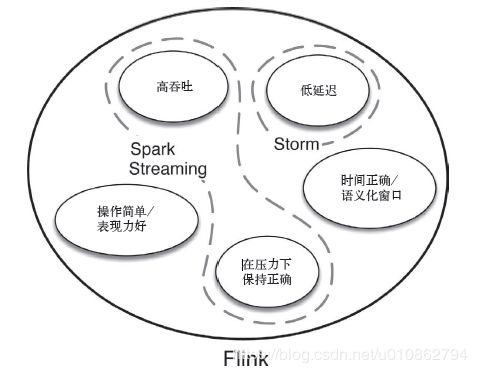
可见,Flink不管是在 Lambda 架构还是 Kappa 架构中都能占有一席之地,特别是在Kappa 架构中,我觉得使用Flink是个不错的选择,下面让我们一起来入门Flink框架.
Flink简介

Apache Flink 是由 Apache 软件基金会开发的开源流处理框架,其核心是用 Java 和 Scala 编写的分布式流数据处理引擎。Flink 以数据并行和流水线方式执行任意流数据程序,Flink 的流水线运行时系统可以执行批处理和流处理程序。此外,Flink 的运行时本身也支持迭代算法的执行。
Flink 提供高吞吐量、低延迟的流数据处理引擎以及对事件-时间处理和状态管理的支持。Flink应用程序在发生机器故障时具有容错能力,并且支持exactly-once语义。
Flink 并不提供自己的数据存储系统,但为Amazon Kinesis、Apache Kafka、HDFS、Apache Cassandra和ElasticSearch等系统提供了数据源和接收器 1
Flink 基本架构

Flink主要有两类进程: JobManager 和 TaskManager
- JobManager(masters): 协调分布式计算、任务调度,协调checkpoints,错误调度等,相当于一个指挥官吧(实际部署时,至少需要一个 JobManager,实际生产环境部署时都会做HA,部署多个JobManager;这个时候,只有一个leader,其他都是standby模式)
- TaskManager(workers):真正执行dataflow的,并对streams进行缓存和交换
总的来说,运行中的 Flink 集群至少有一个 JobManager 进程和一个 TaskManager 进程。如果将客户端也算进去的话,那么还有一个 Client 进程。各个进程一般部署在不同的机子上,不过也可以部署在同一台机子上,就比如说在本地启动一个集群时( Local 模式,通常用于开发调试 ), JobManager 进程和 TaskManager 进程就是跑在同一台服务器上。Flink 是基于 Akka Actor 实现的 JobManager 和 TaskManager,所以JobManager和 TaskManager 以及 Client 之间的信息交互都会通过事件的方式来进行处理的。
一个简单的流程就是,Client 提交任务作业给 JobManager ,JobManager 负责该作业的调度和资源分配(在 Flink 集群中,计算资源被定义为 Task Slot。每个 TaskManager 会拥有一个或多个 Slots),随后将作业分给对应的 TaskManager,TaskManager 收到任务后,启动线程去执行,并向 JobManager 报告任务状态和自身运行状态等。当任务结束后, JobManager 将收到通知,并统计数据后发送给 Client。
简单部署实验(Windows 系统)
- 下载 Flink1.7.2
按需选择即可,这边下载的是flink-1.7.2-bin-scala_2.12.tgz - 解压进入到 bin 目录,执行
start-cluster.bat
注意直接启动可能会有端口冲突导致启动不成,这时候可以 conf 目录下的flink-conf.yaml# The port under which the web-based runtime monitor listens. # A value of -1 deactivates the web server. #rest.port: 8081 rest.port: 9091 - 进入web页面查看集群的任务情况(由于刚刚改了端口,所以应该是访问 http://localhost:9091/)
D:\Program Files\Apache\flink-1.7.2\bin>start-cluster.bat Starting a local cluster with one JobManager process and one TaskManager process. You can terminate the processes via CTRL-C in the spawned shell windows. Web interface by default on http://localhost:8081/.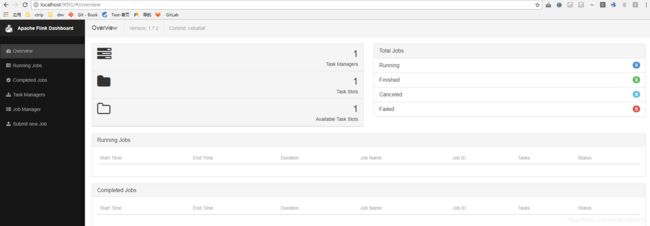
Flink 核心特性
编程模型
Flink 处理数据流的时候,一般遵循如下模型:
构建 Flink 程序最基本的模块就是数据流和算子( transformations ),数据流就是永不终止的数据记录,而算子将数据流作为输入,进行特定操作后,再产生新的流数据。
通常,其处理流程为 Source -> Transformations -> Sink . 其数据流构成一个有向无环图(DAG)。

其中 Transformation Operators 有多种,DataSet API 和 DataStream API 支持的不完全相同,通常支持的有如下几种,更详细的可以参考官方文档;
| Transformations | 描述 |
|---|---|
| Map (DataSet 和 DataStream 都有) | 将一个元素经过特定处理映射成另一个 |
| Filter (DataSet 和 DataStream 都有) | 经过特性函数处理,过滤数据 |
| KeyBy (Only DataStream ) | 将数据根据特定的属性字段分区 |
| Window | 按需将KeyedStreams分组处理 |
Source 为待处理数据的输入地,而 Sink 为处理后的输出地,目前 Flink 支持的 Source 和 Sink 有:
- Apache Kafka (source/sink)
- Apache Cassandra (sink)
- Amazon Kinesis Streams (source/sink)
- Elasticsearch (sink)
- Hadoop FileSystem (sink)
- RabbitMQ (source/sink)
- Apache NiFi (source/sink)
- Twitter Streaming API (source)
- Apache ActiveMQ (source/sink)
- Apache Flume (sink)
- Redis (sink)
- Akka (sink)
- Netty (source)
对时间的处理
一般来说,在流数据处理中,可以将时间分成三类:
- 事件时间:事件实际发生的时间(流记录中本身包含对应的时间戳)
- 处理时间:事件被处理的时间(被流处理器处理的时间)
- 进入时间:事件进入流处理框架的时间(缺乏真实事件时间的数据会被流处理器附上时间戳,即流处理器第一次看到他的时间)
Flink 允许用户根据自己所需来选择三者中的任何一种来定义时间窗口。那么什么是时间窗口呢?
先从窗口说起,窗口是一种机制,其将许多事件按照时间或者其他特征分组,从而将每一组作为整体进行分析。Flink 目前默认支持有时间窗口,计数窗口,会话窗口。用户可根据自己需要的情况选择对应的窗口处理。
时间窗口
时间窗口,应该算是比较常用的一个窗口处理了。比如说,每分钟统计一次某商品的点击数啊;或者每分钟统计一次一个小时内点击数最高的前十个产品之类的需求。只要是按照时间划分的,都可以使用时间窗口。
时间窗口又分为滚动时间窗口和滑动时间窗口两种。
下面图解下滚动窗口和滑动窗口的区别 :
滚动窗口:

RT,定义一个一分钟的滚动窗口:
stream.timeWindow(Time.minutes(1))
滑动窗口:

RT,定义一个窗口大小为一小时,滑动周期为一分钟的滑动窗口:
stream.timeWindow(Time.minutes(60), Time.minutes(1))
计数窗口
技术窗口和时间窗口类似,只不过分组依据不是时间而是数据个数,同样也分滚动计数窗口和滑动计数窗口,这里不再细说。
RT,代码实例:
stream.countWindow(100); // 滚动计数窗口
stream.countWindow(100, 10); // 滑动计数窗口
使用计数窗口需要考虑,万一最终的数据量一直无法满足窗口大小的量,那么该程序可能就无法终止,最好设置超时。
会话窗口
不像前两种,这个比较特别。需要先理解什么算一个会话: 会话指的是活动阶段,其前后都是非活动阶段,那么这一活动阶段就是一个有效的会话。会话阶段通常需要有自己的处理机制,可以想象,会话的定义比较灵活,很难有固定的会话定义。Fink 也支持一些简单的定义直接使用,RT
stream.window(SessionWindows.withGap(Time.minutes(5)); // 五分钟内没有活动的话,则认为会话结束
时间和水印(Watermarks)
支持事件时间的流处理器需要明确的知道何时才是事件事件的终止。就好比一个一小时的时间窗口操作,我们需要知道何时才是真正的结束时间,否则窗口无法被正确的关闭( 因为实际,基于事件时间的事件其由于网络等原因,其到达的顺序并不一定就是其事件发生时间的顺序 )。另外,在 Kappa 架构中, 流数据处理框架需要支持处理回放的数据,那么同一组数据重新运行同样的程序,需要得到相同的结果,这也需要其支持事件时间,因为如果窗口的设定是根据系统时间而不是事件自带的时间戳,那么每次运行同样的程序,都会得到不同的结果。
可见支持事件时间对于流处理架构而言至关重要,因为事件时间能保证结果正确,并使流处理架构拥有重新处理数据的能力。那么 Flink 是如何做到对事件时间的支持的? 其实际是通过 Watermarks 机制来实现的。
Watermark 机制:
The mechanism in Flink to measure progress in event time is watermarks. Watermarks flow as part of the data stream and carry a timestamp t. A Watermark(t) declares that event time has reached time t in that stream, meaning that there should be no more elements from the stream with a timestamp t’ <= t (i.e. events with timestamps older or equal to the watermark)
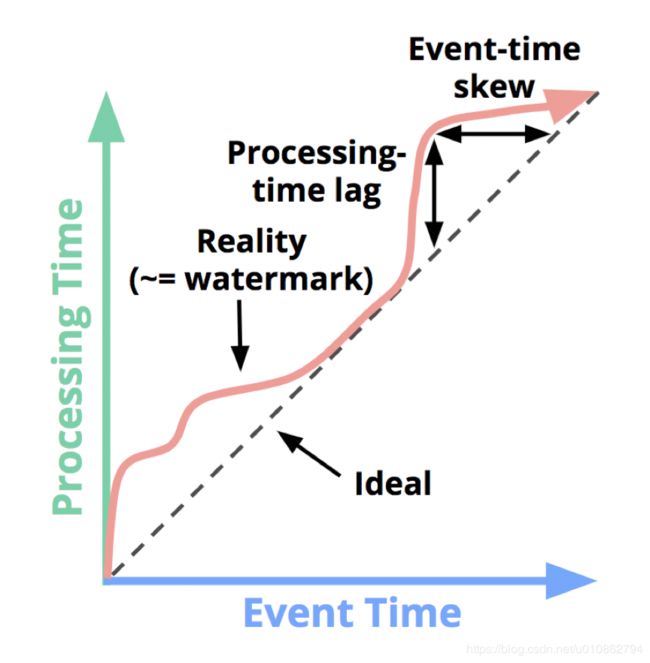
大意就是说,Watermarks 作为数据流中的一部分,包含一个时间戳 t,当处理器处理到这个 Watermark(t) 的时候,就认为所有事件时间小于该水印时间的事件数据都已经到达。
但是即使如此,依然可能会有些事件数据在 Watermark 之后到达,这时 Watermark 机制也无法起到对应的作用,针对这一情况 Flink 支持了 Late Elements 处理,详情查看官网 Allowed-lateness。
最后,如果对于水印还是不明白的,可以阅读下Flink Event Time Processing and Watermarks 和 Streaming System 有个更深的了解.
有状态的计算
流计算一般分为有状态和无状态两种,无状态计算指的是处理过程中不依赖于之前的数据处理结果或其他中间数据;而有状态的计算会维护状态,并基于最新数据和当前状态生成输出结果。
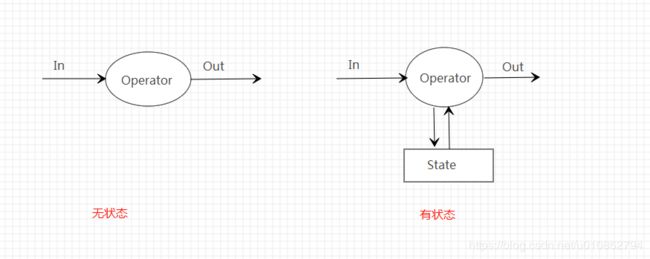
有状态的计算引入了状态,所有引入了状态的分布式系统都会遇到一个数据一致性的问题。流处理或消息系统中,通常将其定义为 “正确性级别”, 通常来说会有三个级别:
- at-most-once: 数据可能会丢失
- at-least-once:数据最少处理一次
- exactly-once:数据均被且只被处理一次
Flink 的话支持 exactly-once 语义,且还能保持低延迟和高吞吐的处理能力,这是 Flink 的一个重大优势。Flink 保证 exactly-once 主要是通过他的 checkpoint 和 savepoint 机制。
checkpoint: Flink 自动周期生成,用于用户程序出故障时,使其重置回到正确的状态,主要需做两件事
- 保存source中流的偏移量( eg. kafka数据的便宜量,以便数据重放)
- 保存中间的计算状态( 即StateBackend,这个保存的位置可以选择,后面再讲)
Flink 检查点算法的正式名称是异步屏障快照(asynchronous barrier snapshotting)。该算法大致基于Chandy-Lamport 分布式快照算法。
其中,有一个核心的概念:Barrier(屏障)
在数据流中,屏障和普调标记类似;他们都由算子处理,但是不参与计算,而是会触发与检查点相关的行为。当读取输入流的数据源遇到检查点屏障时,它将其在输入流的位置保存到文档存储中(eg. kafka的偏移量)。当算子处理完记录并收到了屏障时,它们会将状态异步保存到稳定存储中,当状态备份和检查点位置备份都被确认后,则认为该检查点已完成。
总结下:
- Souce 遇到屏障保存数据位置
- 算子遇到屏障异步保存状态
- 保存结束后确认检查点完成
savepoint: 需要应用自己手动生成,通常用于状态版本控制。依赖于checkpoint机制。
上述流程中涉及到保存状态,Flink 可以支持多种状态存储。大致有以下几种StateBackend
- MemoryStateBackend
快速,但是不稳定,重启就没了。 - RocksDBStateBackend
支持增量,支持大状态长窗口的大数据存储,但是存储和读取时都需要序列化(会耗时) - FsStateBackend
支持大状态长窗口的大数据存储,但是还是会保存一份在 TaskManager 的 Memory 中,所以状态的大小不能超过 TaskManager 的内存
参考:
- 《 Flink 基础教程》
- Kappa Architecture
- Lambda Architecture
- Flink 官方文档
Apache Flink Wikipedia ↩︎