java字节码文件结构解析
目录
魔数与版本
常量池
类、父类和接口索引集合
字段表集合
方法表集合
属性表集合
Class文件(即字节码文件)以8位字节为基础单位的二进制流,各个数据项目严格按照顺序紧凑地排列, 中间没有分隔符,没有一个字节是多余的。文件格式是使用一种类似于C语言中的结构体来描述和存储数据的,其中包括无符号数和表。无符号数是一种采用u1、u2、u4和u8来分别表示1个字节、2个字节、4个字节和8个字节的数据类型,是方便用来表示字节的长度的一种类型。而表则是由多个无符号数或者其他表组合而成的复合类型,习惯以“_info”结尾,如常量表CONSTANT_utf8_info。数据存储的字节码顺序是采用大端法表示的,所谓大端法是最高有效字节在最前面,如0x1234,0x1地址在0x101,0x2地址在0x102,以此类推。
辅助工具:jdk8、notepad++(HEX_Editor插件)、javap、bytecode-viewer。notepad++需要安装hex_editor插件,这是一个把二进制转化为十六进制的一个插件,bytecode-viewer是一个字节码解析工具,方便我们去验证解析结果正确与否。
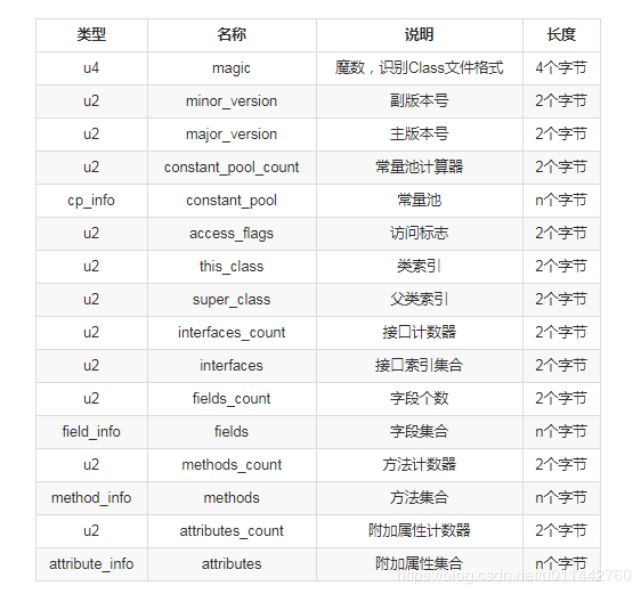
在一个字节码文件中,可能有多个属性表或者多个无符号数,所以在字节码里会先给出一个数量计数器,以表示接下来会有多少个类型,这样一系列连续的类型就组成了某一类的数据集合,而字节码就是由下图中的个种类型集合组成。
为了方便讲述问题,我们采用的代码尽量简单,故采用以下代码作为demo
package org.javersoft.clazz;
public class TestClass {
private int m;
public int inc() {
return m + 1;
}
}魔数与版本
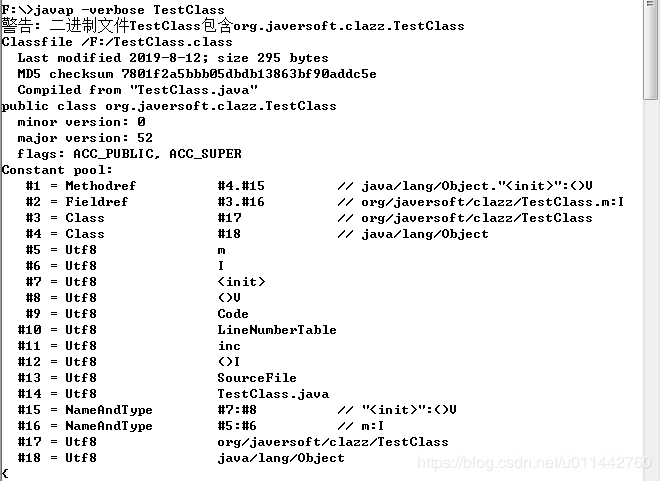
每个Class文件的头4个字节称为魔数,确定这个文件是否为一个能否被虚拟机接 受的Class文件,紧接着魔数的4个字节是Class文件的版本号,第5和第6个字节是次版本号,第7和 第8个字节是主版本号。如下图,编译后得到的class文件,有notepadd++打开,并用HEX_Editor插件转换。

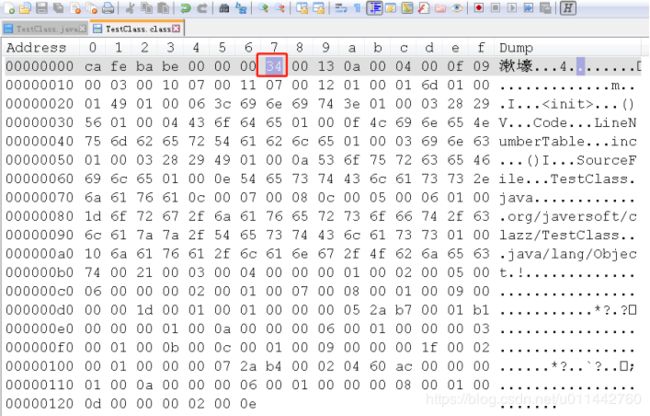
头4个字节是cafebabe,而接下来4个字节就是版本号,主版本号是0x0034,换做十进制就是52,也就是jdk8的主版本。
常量池
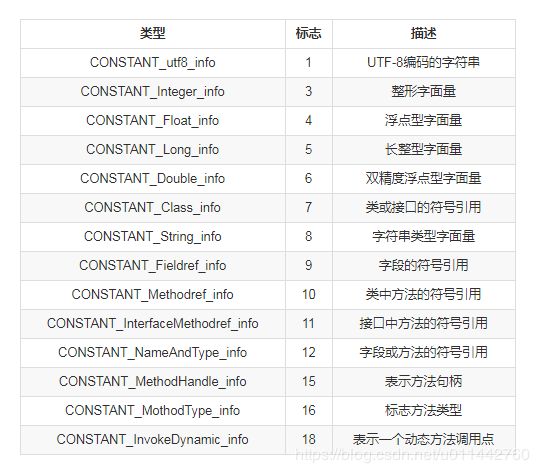
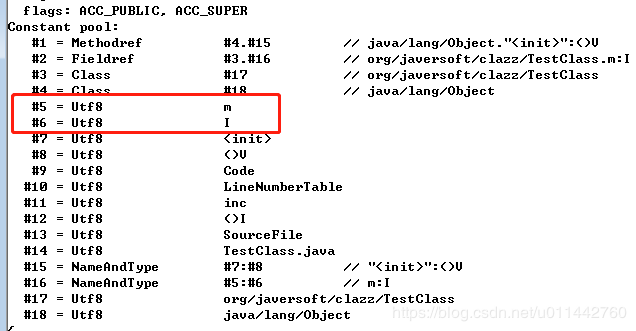
常量池中主要存放两大类常量:字面量和符号引用。字面量可理解为java语言层面的常量概念,符号引用包括3类常量,类和接口的全限定名、字段的名称和描述符、方法的名称和描述符。每个常量都有自己的标志,如下图
紧接着主次版本号之后的是常量池的入口,常量池可以理解为Class文件之中的资源仓库,先直观看看,这个class文件都有哪些常量
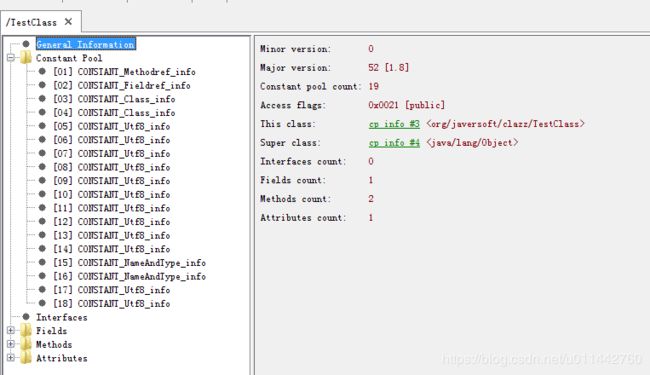
常量池中常量的数量不固定,需在入口处放置一项u2类型的数据,以表示常量池容量计数值,从1开始,0空出来表示特殊情况,下面会有讲到,以表示“不需要引用任何一个常量池项目”。
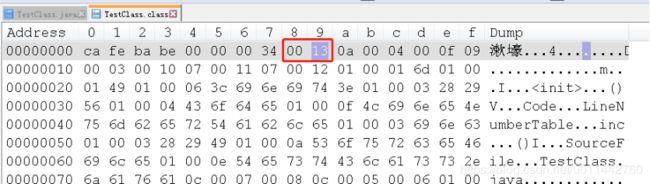
主次版本之后的一项u2类型的数据是0x0013,换做十进制是19,就表示接下来会有19个常量,下面会接着一个个讲,在讲之前需要先了解一下常量池中常用的结构类型是怎样的
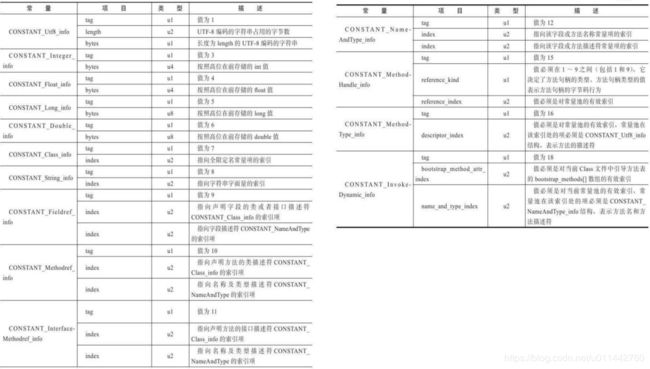
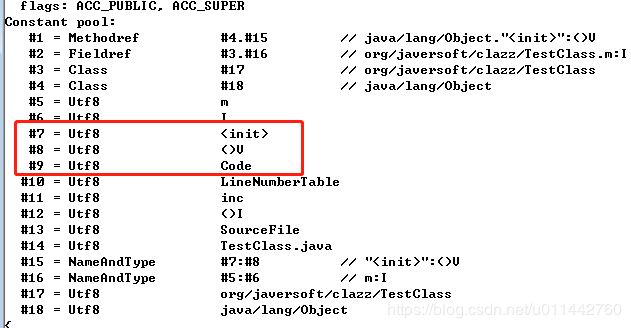
比如第一个CONSTANT_Utf8_info类型,用来描述字符串,第一项是tag,tag的作用是标识常量类型的,而1就表示CONSTANT_Utf8_info类型,占一个u1类型长度,即用1个字节来表示;第二项length用来表示后面字符串所占的长度,其本身所能表示的长度是u2,即2个字节所能表示的最大值;第三项就是长度为length的utf-8编码的字符串。后面的常量类型也是这样理解。且看第一个常量:


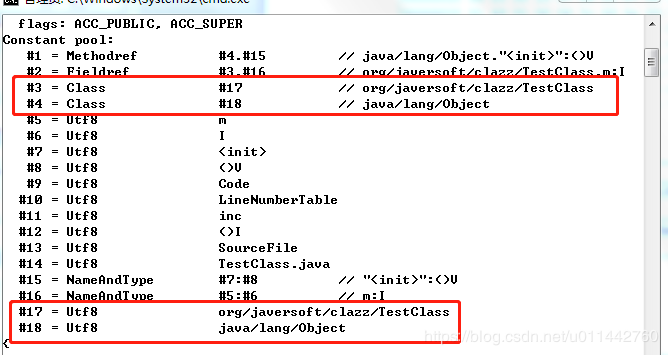
第一个tag值为10,对应的是CONSTANT_Methodref_info常量,第一个u2类型字节是0x0004,表示的是索引值为4的常量,其指向java.lang.Object类描述符,第二个u2类型字节是0x00f,表示的是索引值为15的常量,其指向init()实例构造器的名称描述符,代码并没有init()方法,是编译器自动生成的,用javap命令查看得知。
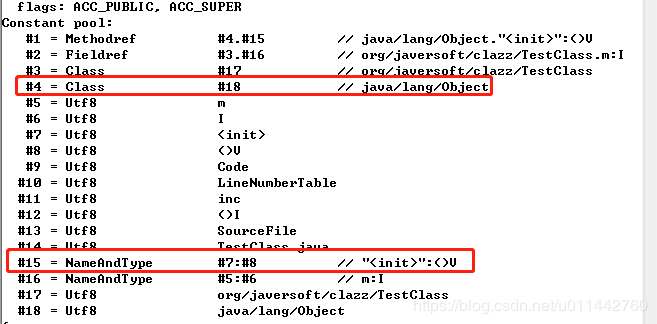
到此,第一个常量已经解析出来,接下来看第二个常量。
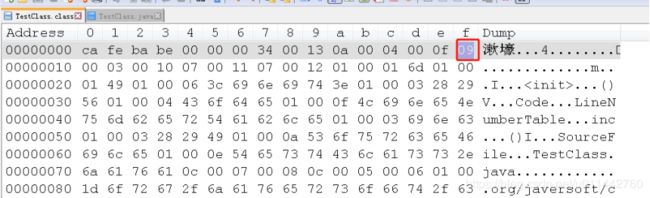

第二个常量tag值为9,对应CONSTANT_Fieldref_info,第一个u2是0x0003,指向索引值为3,索引3是一个CONSTANT_Class_info类型,CONSTANT_Class_info的index又指向索引17,表示一个类的全限定名,即org.javersoft.clazz.TestClass; 第二个u2是0x0010,指向索引值为16,索引是6是一个CONSTANT_NameAndType_info常量,其第一个index指向索引5,表示指向字段m的名称常量项,第二个index索引指向6,表示指向字段描述符I,关于描述符后面再讲。
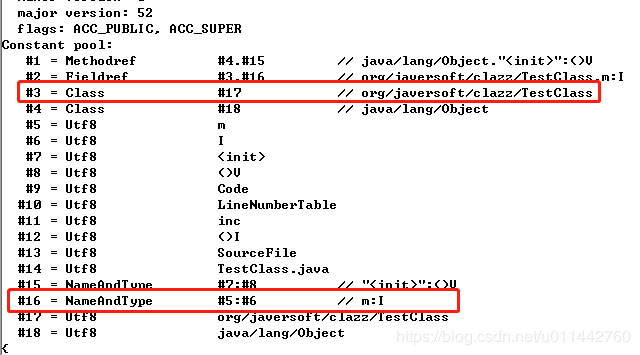
到此,第二个常量也解析出来了,接下来看第三个常量。
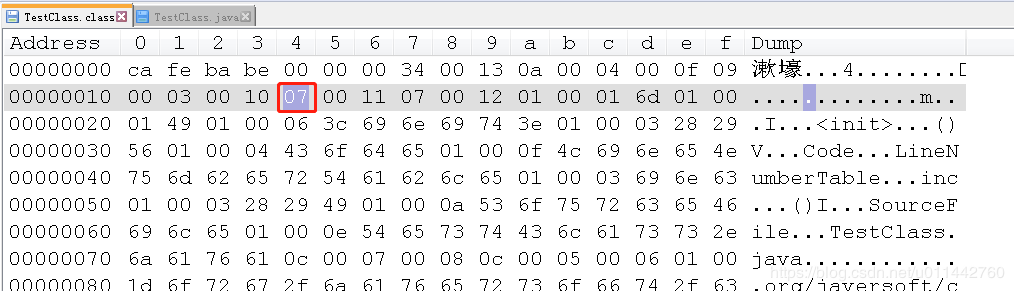

第三个常量tag值为7,表示CONSTANT_Class_info类型,后面0x0011指向索引17,索引17是一个CONSTANT_Utf8_info常量,表示TestClass类的全限定名。
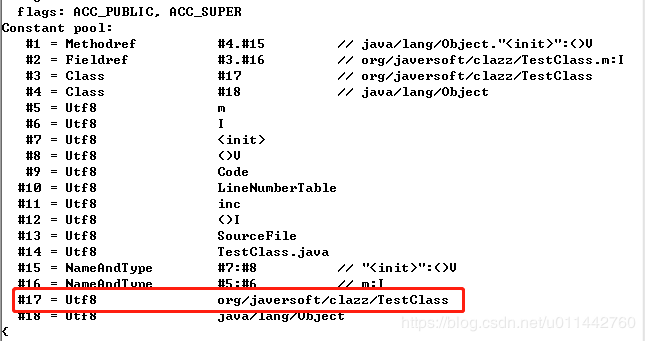
第四个常量跟第三个常量一样解析即可,接下来看第五个常量。


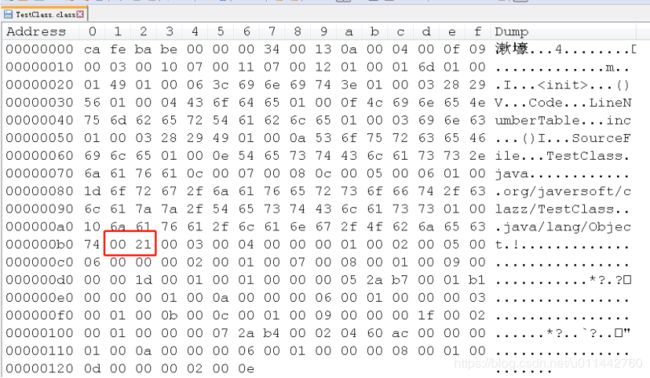
这个字符串的length值是0x0001,也就是长1个字节,即“0x6d”,按utf-8编码,内容为“m”。Class文件中的方法、字段等都需要引用CONSTANTS_Utf8_info型常量来描述名称,从这里也看出,一个类的字段名和方法名长度不能超过0xFFFF个字节。到此5个常量已经解析出来了,后面的13个常量也是这样解析即可。我给每个常量划分了一下,如下图,就是说,18个常量,到0x74为止。
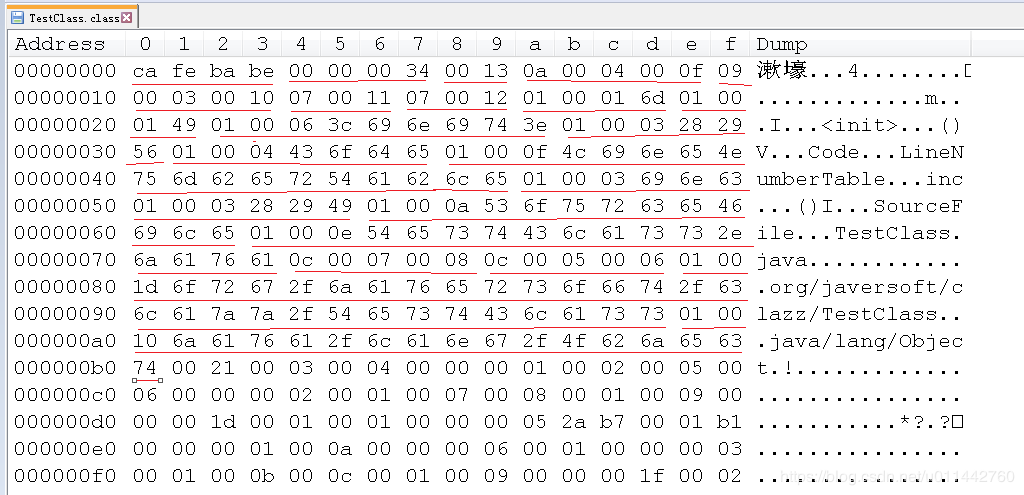
访问标志,用两个字节代表访问标志,用于识别一些类或者接口层次的访问信息,包括:这个Class是类还是接口;是否定义为public类型;是否定义为abstract类型;如果是类的话,是否被声明为final等
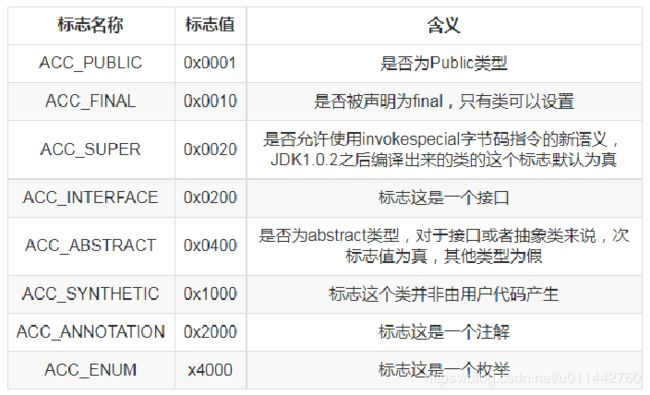
0x0021,即除了ACC_PUBLIC和ACC_SUPER为真,其余为假,表示这个类的修饰符是public
类、父类和接口索引集合
类索引:u2类型,用于确定这个类的全限定名
父类索引:u2类型,用于确定这个类的父类的全限定名(除java.lang.Object外,所有java类 都有父类索引都不为0)
接口索引:一组u2类型的数据的集合,用于描述这个类实现了哪些接口,入口第一项(u2 类型)表示索引表的容量

第一个0x0003,表示类索引,全限定名是索引17指向的常量;第二个0x0004,表示父类索引,全限定名是索引18指向的常量,即基类Object;第三个0x0000,索引为0,就是上面所说的,0的特殊情况,这里表示没有接口索引集合,也就没有实现任何接口。
字段表集合
字段表用于描述接口或者类中声明的变量(包括类变量和实例变量,但不包括方法内部声明的局部变量),字段能描述的信息有字段的作用域(public、protected和private修饰符)、是实例变量还是类变量(static修饰符)、可变性(final)、并发可见性(volatile修饰符)、 可否被序列化(transient修饰符)、字段数据类型(基本类型、对象、数据)、字段名称,各个修饰符都是布尔值,字段数据类型和名称无法固定,因此只能引用常量池的常量来描述


上图为字段表结构和字段访问标志,讲字段表之前,再了解一下描述符。描述符用于描述字段的数据类型、方法的参数列表(包括数量、类型和顺序)和返回值 基本类型和void类型都用一个大写字母来表示,对象用L加全限定名来表示。如下图

数组表示:每一维度使用一个前置的“[”表示,如 “java.lang.String[][]” 记录为“[[Ljava/lang/String”; 一个整型数组 “int[]” 记录为 “[I”。
方法表示:先参数列表后返回值,如void inc()记录为 “()V”,int indexOf(char[] source, int sourceOffset, int sourceCount,char[] target, int targetOffset, int targetCount,int fromIndex) 记录为“([CII[CIII)I”。

根据字段表结构,上图画出了每项的含义,第一项fields_count,表示后面字段表的数量,此处值为1,表示接下来只有一个字段表。这个字段表的access_flags为2,表示private,name_index为5,指向索引5,即字段名称为 m,descitor_index为6,指向索引6的描述符为I,即Integer类型,最终的结果表示:private int m。在字节码里,只要两个字段的描述符不一致,就算重名也是合法的,这个编译器编译规则不一样。接下来的attributes_count为0,表示没有属性表。
方法表集合

方法表的描述与字段表的描述完全一致,结构也是一致。
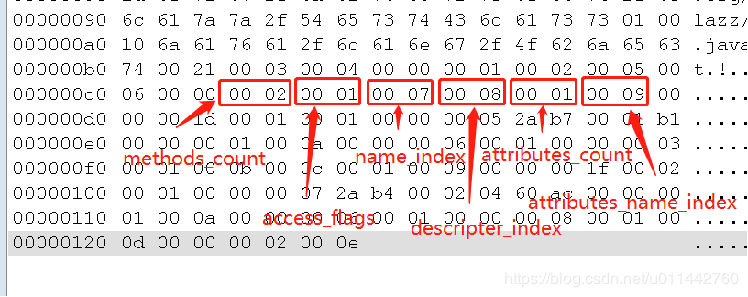
methods_count值为2,可以想象到一个是实例构造器init(),一个是inc()方法。根据字段表解析方法,就可以解析出这个方法是 public void inc()。
疑问???
方法的定义可以通过访问标志、名称索引、描述符索引表达清楚,但方法里面的 代码去哪里了?
答案:方法里的java代码,经过编译器编译成字节码指令后,存放在方法属性表集合中一个名为“Code”的属性里
属性表集合
接下来attributes_count值为1,表示当前方法有1个属性表。

在Class文件、字段表、方法表都可以携带自己的属性表集合,用以描述某些场景专有的信息,对于每个属性,名称需要从常量池中引用一个CONSTANT_utf8_info类型的常量来表示,而属性值的结构则是完全自定义的,只需要通过一个u4的长度属性去说明属性值所占用的位数即可。
Java虚拟机规范预定义了23种属性。
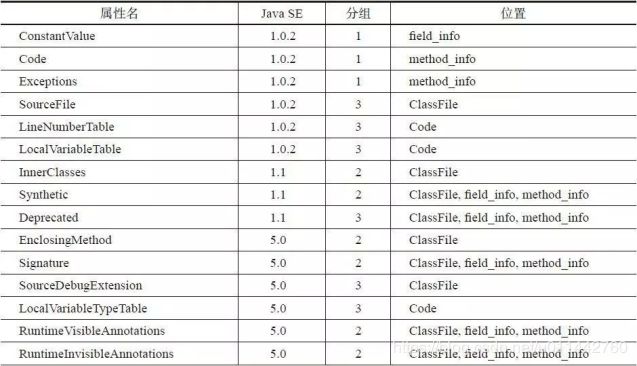
继续上面的属性表,attribute_name_index值为0x0009,名称为Code,即Code属性表,Code属性表结构如下图
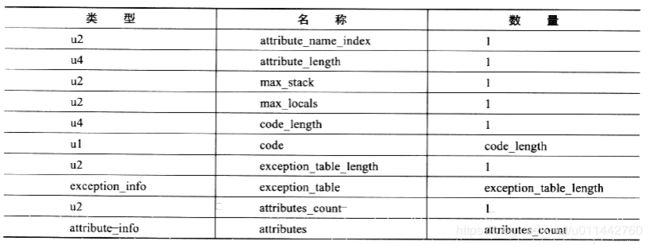
java方法体中的代码经过javac编译器处理后,最终变成字节码指令存储在Code属性内, 接口和抽象类方法不存在Code属性,如果一个程序中的信息分为代码(Code,方法体内的java代码)和元数据(metadata, 包括类、字段、方法定义及其他信息)两部分,那么在Class文件中,Code属性用于描述代码,其他数据项目都用于描述元数据。
attribute_name_index: 指向CONSTANTS_utf8_info型常量型的索引,常量值固定为“Code”, 代表该属性的属性名称
attribute_length:表示属性值得长度,由于属性名称索引和属性长度一共占6个字节,那属 性值的长度固定为整个属性表长度减去6字节
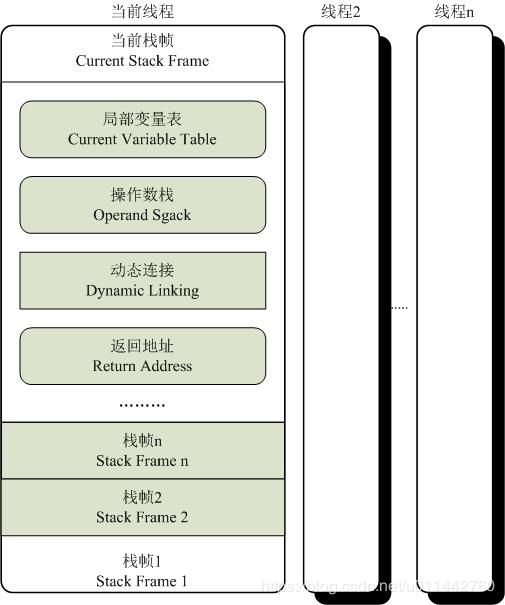
max_stack: 操作数栈深度的最大值,方法执行的任意时刻,操作数栈都不会超过这个深度, 虚拟机运行时需根据这个值来分配栈帧中的操作栈深度
max_locals:局部变量表所需的存储空间,单位是Slot(虚拟机为局部变量分配内存所使用的最小单位),局部变量表中的Slot可以重用,当代码执行超出一个局部变量的作用域时,即被重用,javac编译器根据作用域来分配Slot给各个变量使用,然后计算出max_locals的大小
code_length:字节码长度 code:字节码指令的一系列字节流,一个指令是u1类型,范围为0x00~0xFF(0~255) exception_table_length:异常表长度
exceptin_table:异常表,这里的异常是指代码捕获的异常
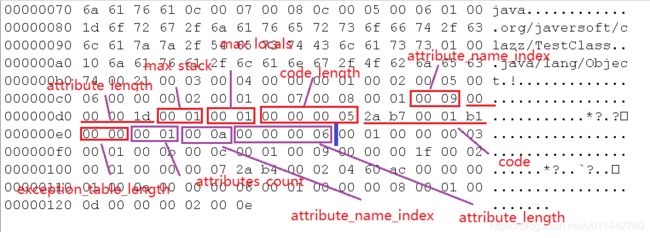
attribute_name_index: 0x0009,指向Code
attribute_length:0x0000001d,十进制为29
max_stack: 0x0001
max_locals:0x0001
code_length:0x00000005
code:0x2ab70001b1,字节码指令
exception_table_length:0x0000,没有异常信息
| 指令码 |
操作码 |
操作数 |
描述(栈指操作数栈) |
| 0x2a |
aload_0 |
|
从局部变量0中装载引用类型值入栈 |
| 0xb7 |
invokespecial |
0x00, 0x01 |
编译时方法绑定调用方法 |
| 0xb1 |
return; |
|
void函数返回 |

Code属性是最重要的一个属性,其他的属性也可以按照这样的思路继续解析
总结:
本文参照规范大概解析字节码文件结构,字节码文件主要是由一系列表集合组成,只是每个集合有各自含义,在描述集合前总会有一个容器计数器来说明后面有多少个集合,以此划分。由字节码文件可知,所有类文件信息,都存储在常量池里,上面的所有描述,都是通过索引引用常量池常量。了解字节码结构,对了解类加载过程有一定的帮助。
参考文献
[1] 周志明.深入理解Java虚拟机.JVM高级特性与最佳实践:机械工业出版社,2018.