Flink:RetractStreamTableSink 自定义sink写数据到Phoenix
文章目录
- 目标
- Sink定义
- 使用自定义Sink
- 测试
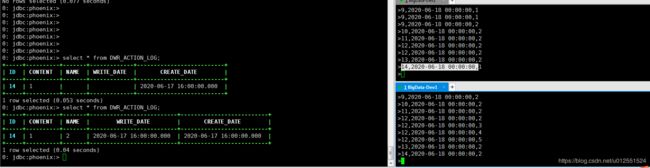
目标
两张表left join的结果更新写入Phoenix
数据样例:
(true,12,2,3,2020-06-18T00:00,2020-06-18T00:00)
(true,12,2,5,2020-06-18T00:00,2020-06-18T00:00)
(true,12,2,2,2020-06-18T00:00,2020-06-18T00:00)
(true,12,2,4,2020-06-18T00:00,2020-06-18T00:00)
(true,13,2,null,2020-06-18T00:00,null)
(false,13,2,null,2020-06-18T00:00,null)
(true,13,2,2,2020-06-18T00:00,2020-06-18T00:00)
Sink定义
由于数据Phoenix可以不考虑删除的操作,所以只用处理Boolean为ture的数据,示例如下:
class PhoenixSinkFunction<IN> extends RichSinkFunction<IN> {
final JDBCUpsertOutputFormat outputFormat;
PhoenixSinkFunction(JDBCUpsertOutputFormat outputFormat) {
this.outputFormat = outputFormat;
}
@Override
public void invoke(IN value) throws Exception {
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
RuntimeContext ctx = getRuntimeContext();
outputFormat.setRuntimeContext(ctx);
outputFormat.open(ctx.getIndexOfThisSubtask(), ctx.getNumberOfParallelSubtasks());
}
@Override
public void close() throws Exception {
super.close();
}
}
public class PhoenixJDBCRetractStreamTableSink implements RetractStreamTableSink<Row>, Serializable {
private TableSchema tableSchema;
private JDBCUpsertOutputFormat outputformat;
public PhoenixJDBCRetractStreamTableSink(){}
public PhoenixJDBCRetractStreamTableSink(String[] fieldNames, TypeInformation[] typeInformations, JDBCUpsertOutputFormat outputformat){
this.tableSchema=new TableSchema(fieldNames,typeInformations);
this.outputformat = outputformat;
}
//重载
public PhoenixJDBCRetractStreamTableSink(String[] fieldNames, DataType[] dataTypes){
this.tableSchema=TableSchema.builder().fields(fieldNames,dataTypes).build();
}
//Table sink must implement a table schema.
@Override
public TableSchema getTableSchema() {
return tableSchema;
}
@Override
public DataStreamSink<?> consumeDataStream(DataStream<Tuple2<Boolean, Row>> dataStream) {
JDBCUpsertOutputFormat phoenixOutputformat = this.outputformat;
return dataStream.addSink(new PhoenixSinkFunction<Tuple2<Boolean, Row>>(phoenixOutputformat) {
@Override
public void invoke(Tuple2<Boolean, Row> value) throws Exception {
//自定义Sink
// f0==true :插入新数据
// f0==false:删除旧数据
if(value.f0){
//数据写入phoenix
phoenixOutputformat.writeRecord(value);
}
}
});
}
//接口定义的方法
@Override
public TypeInformation<Row> getRecordType() {
return new RowTypeInfo(tableSchema.getFieldTypes(),tableSchema.getFieldNames());
}
//接口定义的方法
@Override
public TableSink<Tuple2<Boolean, Row>> configure(String[] strings, TypeInformation<?>[] typeInformations) {
return null;
}
//接口定义的方法
@Override
public void emitDataStream(DataStream<Tuple2<Boolean, Row>> dataStream) {
}
}
使用自定义Sink
代码示例:
package flinkDatawarehouse.entiy.join
import java.util.Properties
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.io.jdbc.{JDBCOptions, JDBCUpsertOutputFormat}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.scala.StreamTableEnvironment
import org.apache.flink.table.api.{DataTypes, EnvironmentSettings, TableSchema, Types}
import org.apache.flink.table.descriptors.{Csv, Kafka, Schema}
/*
* 1、结果数据写到phoenix
* 2、数据源:kafka
*
*
* */
object LeftJoinTest {
def main(args: Array[String]): Unit = {
val senv = StreamExecutionEnvironment.getExecutionEnvironment
val fsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build()
val tblEnv = StreamTableEnvironment.create(senv, fsSettings)
val properties = new Properties()
properties.setProperty("bootstrap.servers", "bigdata-dev1:9092,bigdata-dev2:9092,bigdata-dev3:9092")
properties.setProperty("zookeeper.connect", "bigdata-dev1:2181,bigdata-dev2:2181,bigdata-dev3:2181")
/*
* kafka topic:
* action_log,action_log_detail
*
* 读取两张数据表:
* action_log action_log_detail
* */
tblEnv.connect(
new Kafka()
.version("universal")
.topic("action.log")
.startFromEarliest()
.property("bootstrap.servers", properties.getProperty("bootstrap.servers"))
.property("zookeeper.connect", properties.getProperty("zookeeper.connect"))
).withFormat(
new Csv()
.deriveSchema()
.fieldDelimiter(',')
.lineDelimiter("\n")
.ignoreParseErrors()
).withSchema(
new Schema()
.field("id", Types.STRING())
.field("write_date",Types.SQL_TIMESTAMP())
.field("name", Types.STRING())
).inAppendMode().registerTableSource("action_log")
tblEnv.connect(
new Kafka()
.version("universal")
.topic("action.log.detail")
.property("bootstrap.servers", properties.getProperty("bootstrap.servers"))
.property("zookeeper.connect", properties.getProperty("zookeeper.connect"))
).withFormat(
new Csv()
.deriveSchema()
.fieldDelimiter(',')
.lineDelimiter("\n")
.ignoreParseErrors()
).withSchema(
new Schema()
.field("id", Types.STRING())
.field("create_date", Types.SQL_TIMESTAMP())
.field("content", Types.STRING())
).inAppendMode().registerTableSource("action_log_detail")
/*
* 1、action_log_detail left join action_log
*
* 2、数据延迟区间一个小时
*
* */
var sqlQuery =
"""
|SELECT id,content,name,create_date,write_date from(
|SELECT
| o.id,
| o.content,
| p.name,
| o.create_date,
| p.write_date
|FROM
| action_log_detail AS o LEFT JOIN action_log AS p ON o.id = p.id AND
| p.write_date BETWEEN create_date - INTERVAL '1' HOUR AND create_date + INTERVAL '1' HOUR) a
|""".stripMargin
//执行sql
val res = tblEnv.sqlQuery(sqlQuery)
//使用phoenix sink
val options = JDBCOptions.builder()
.setDBUrl("jdbc:phoenix:192.168.10.16:2181:/hbase-unsecure;autocommit=true")
.setDriverName("org.apache.phoenix.jdbc.PhoenixDriver")
.setTableName("DWR_ACTION_LOG")
.build
val tableSche:TableSchema = TableSchema.builder()
.field("id",DataTypes.STRING().notNull())
.field("cnt",DataTypes.BIGINT()).build()
val outputformat = JDBCUpsertOutputFormat.builder()
.setOptions(options)
.setFieldNames(Array[String]("id","CONTENT","NAME","CREATE_DATE","WRITE_DATE"))
.setFieldTypes(Array[Int](java.sql.Types.VARCHAR,java.sql.Types.VARCHAR,java.sql.Types.VARCHAR,java.sql.Types.TIMESTAMP,java.sql.Types.TIMESTAMP))
.setMaxRetryTimes(5)
.setFlushMaxSize(1000)
.setFlushIntervalMills(1000)
.setKeyFields(Array[String]("id"))
.build()
val sink = new PhoenixJDBCRetractStreamTableSink(Array[String]("id","CONTENT","NAME","CREATE_DATE","WRITE_DATE"),
Array[TypeInformation[_]](Types.STRING,Types.STRING,Types.STRING,Types.SQL_TIMESTAMP,Types.SQL_TIMESTAMP),outputformat)
tblEnv.registerTableSink("LeftJoinSink",sink)
res.insertInto("LeftJoinSink")
senv.execute()
}
}
测试