图片分类比赛总结
0.拿到数据集后别急着建模型,先分析数据可视化数据。
在大多数机器学习任务中,我们首先要做的(也是最重要的任务)就是在使用算法之前分析数据集。这一步骤之所以重要,是因为它能够让我们对数据集的复杂度有深入的了解,这最终将有助于算法的设计。
因此,我决定使用 t 分布随机邻域嵌入(https://lvdmaaten.github.io/tsne/)可视化技术来查看图片的分布。t 分布随机邻域嵌入(t—SNE)是一种特别适合对高维数据集进行可视化的降维技术。这种技术可以通过「Barnes-Hut」近似算法来实现,这使得它能够被应用于大型的真实数据集。[14]
1.训练集和测试集一定要打乱!!吃过大苦头
2.先训练出最优的单模型,再进行模型集成。别一开始就用很多个烂模型集成,浪费时间。
3.微调模型优先于重新训练,因为你从一个预训练模型微调迭代无数多次后(最烂情况)就相当于重新训练。
4.先不用数据增强得到一个基准模型。再用数据增强。
一旦准备好了对比基准,我们就需要开始对其进行改进。首先,我们可以进行数据增强处理,增加数据集中的图像数。
没有数据,就没有机器学习!
现实生活中的数据集往往都是不平衡的,而模型在样本数量较少的类别上的性能并不太好。所以,将一个具有少数样本的类误分类为一个样本数量较多的类的成本通常要比将数量较多的类误分类高得多。
由此,我们尝试使用两种方法来平衡数据:
针对不平衡学习的自适应样本合成方法(ADASYN):ADASYN 为样本较少的类生成合成的数据,这种方法会生成更多较难学习的数据集样本。ADASYN 的核心思想是,根据学习的困难程度,对样本数少的类别实例使用加权分布。ADASYN 通过两种方法提高了对数据分布的学习效果:(1)减少类别的不平衡所带来的偏差。(2)自适应地将分类的决策边界转换为更困难的样本。
少数类过采样技术(SMOTE):SMOTE 包括对少数类的过采样和多数类的欠采样,从而得到最佳抽样结果。我们对少数(异常)类进行过采样并对多数(正常)类进行欠采样的做法可以得到比仅仅对多数类进行欠采样更好的分类性能(在 ROC 空间中)。
5.结果可视化
在最后一步,我们将对结果进行可视化,看看模型对哪个类别的预测结果最好、对哪个类别的预测结果最差,并且我们还可以采取必要的措施进一步改进结果。
构造一个混淆矩阵是理解模型结果的好方法。
在机器学习领域,特别是统计分类问题中,混淆矩阵(也称为误差矩阵)是一个特定的表格,它能够将算法的性能可视化,这种算法通常是监督学习算法,在非监督学习领域它通常被称为匹配矩阵。矩阵中的每一行代表预测类别中的一个实例,而每一列则代表真实类别中的一个实例(反之亦然)。这个矩阵之所以被称为「混淆矩阵」,是因为它能够让人很容易地看到系统是否混淆了两个类(即通常将一个类错误标记为另一个类)。
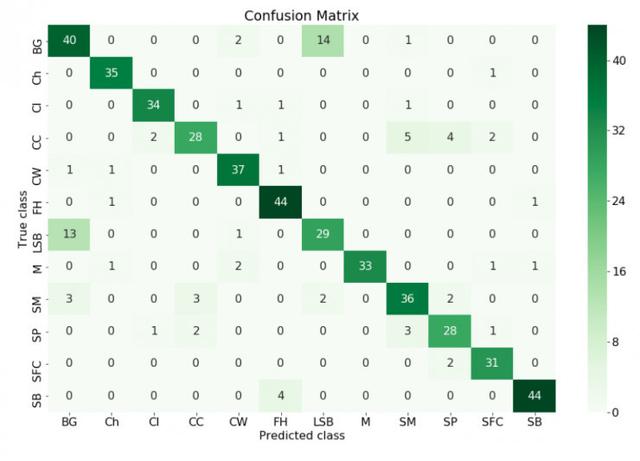
混淆矩阵中真正的类别和预测出的类别
从混淆矩阵中我们可以看到所有的模型预测类别和真实类别不符的情况,我们可以采取措施去改进模型。例如,可以做更多的数据增强工作,试着让模型更好地学习到分类规则。
最后,我们将验证集与训练数据合并,并通过已经得到的超参数,对模型进行最后一次训练,在最终提交结果之前对测试数据集进行评估。
6.提升排名的若干技巧
一旦我们训练好了模型,我们就用这个模型预测那些测试图片的类别了,论坛中predict.py中的代码就是预测鱼类的并且生成提交文件。这里我们给大家分享一下在机器学习和图像识别类竞赛中常见的两个技巧,简单而有效。它们的思想都是基于平均和投票思想。其背后的原理用一句话总结就是:群众的眼睛是雪亮的!
技巧1:同一个模型,平均多个测试样例
这个技巧指的是,当我们训练好某个模型后,对于某张测试图片,我们可以使用类似数据扩增的技巧生成与改张图片相类似的多张图片,并把这些图片送进我们训练好的网络中去预测,我们取那些投票数最高的类别为最终的结果。Github仓库中的predict_average_augmentation.py实现的就是这个想法,其效果也非常明显。
技巧2:交叉验证训练多个模型
还记得我们之前说到要把三千多张图片分为训练集和验证集吗?这种划分其实有很多种。一种常见的划分是打乱图片的顺序,把所有的图片平均分为K份,那么我们就可以有K种<训练集,验证集>的组合,即每次取1份作为验证集,剩余的K-1份作为训练集。因此,我们总共可以训练K个模型,那么对于每张测试图片,我们就可以把它送入K个模型中去预测,最后选投票数最高的类别作为预测的最终结果。我们把这种方式成为“K折交叉验证”(K-Fold Cross-Validation)。图9表示的就是一种5折交叉验证的数据划分方式。

图9. 五折交叉验证
当然,技巧1和2也可以联合在一起使用。假设我们做了5折交叉验证,并且对于每一张测试图片都用5次数据扩增,那么不难计算,每一张测试图片的投票数目就是25个。采用这种方式,我们的排名可以更进一步。