大数据技术之_19_Spark学习_07_Spark 性能调优 + 数据倾斜调优 + 运行资源调优 + 程序开发调优 + Shuffle 调优 + GC 调优 + Spark 企业应用案例
大数据技术之_19_Spark学习_07
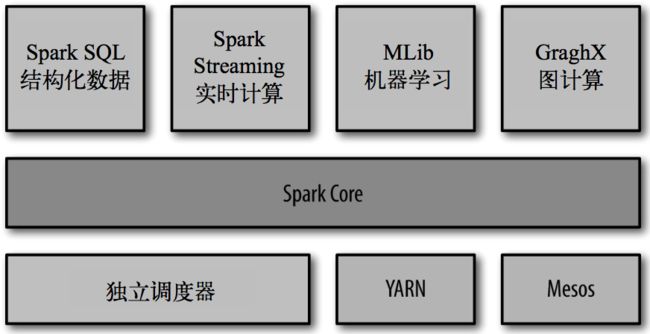
- 第1章 Spark 性能优化
- 1.1 调优基本原则
- 1.1.1 基本概念和原则
- 1.1.2 性能监控方式
- 1.1.3 调优要点
- 1.2 数据倾斜优化
- 1.2.1 为何要处理数据倾斜(Data Skew)
- 1.2.2 如何定位导致数据倾斜的代码
- 1.2.3 如何缓解/消除数据倾斜
- 1.3 运行资源调优
- 1.3.1 运行资源调优概述
- 1.3.2 Spark 作业基本运行原理
- 1.3.3 运行资源中的几种情况
- 1.3.4 运行资源参数调优
- 1.4 程序开发调优
- 1.4.1 原则一:避免创建重复的 RDD
- 1.4.2 原则二:尽可能复用同一个 RDD
- 1.4.3 原则三:对多次使用的 RDD 进行持久化
- 1.4.4 原则四:尽量避免使用 shuffle 类算子
- 1.4.5 原则五:使用 map-side 预聚合 shuffle 操作
- 1.4.6 原则六:使用高性能的算子
- 1.4.7 原则七:广播大变量
- 1.4.8 原则八:使用 Kryo 优化序列化性能
- 1.4.9 原则九:预分区 Shuffle 优化
- 1.4.10 原则十:优化数据结构
- 1.5 Shuffle 调优
- 1.5.1 Shuffle 调优概述
- 1.5.2 ShuffleManager 发展概述
- 1.5.3 HashShuffleManager 运行原理
- 1.5.4 SortShuffleManager 运行原理
- 1.5.5 shuffle 相关参数调优
- 1.6 GC 调优
- 1.6.1 JVM 虚拟机
- 1.6.2 GC 算法原理
- 1.6.3 Spark 的内存管理
- 1.6.4 选择垃圾收集器
- 1.6.5 根据日志进一步调优
- 第2章 Spark 企业应用案例
- 2.1 京东商城基于 Spark 的风控系统的实现
- 2.1.1 风控系统背景
- 2.1.2 什么是“天网”
- 2.1.3 前端业务风控系统
- 2.1.4 后台支撑系统
- 2.1.5 风控数据支撑系统
- 2.2 Spark 在美团的实践
- 2.2.1 应用需求
- 2.2.2 Spark 交互式开发平台
- 2.2.3 Spark 作业 ETL 模板
- 2.2.4 基于 Spark 的用户特征平台
- 2.2.5 Spark 数据挖掘平台
- 2.2.6 Spark 在交互式用户行为分析系统中的实践
- 2.2.7 Spark 在 SEM 投放服务中的应用
- 2.3 数据处理平台架构中的 SMACK 组合:Spark、Mesos、Akka、Cassandra 以及 Kafka
- 2.3.1 综述
- 2.3.2 存储层:Cassandra
- 2.3.3 处理层:Spark
- 2.3.4 Mesos 架构
- 2.3.5 将 Spark、Mesos 以及 Cassandra 加以结合
- 2.3.6 定期与长期运行任务之执行机制
- 2.3.7 数据提取
- 2.3.8 Kafka 充当输入数据之缓冲机制
- 2.3.9 数据消费:Spark Streaming
- 2.3.10 故障设计:备份与补丁安装
- 2.3.11 宏观构成
- 2.4 大数据架构选择
- 2.4.1 简介
- 2.4.2 大数据处理框架是什么?
- 2.4.3 批处理系统
- 2.4.4 流处理系统
- 2.4.5 混合处理系统:批处理和流处理
- 2.4.6 结论
第1章 Spark 性能优化
1.1 调优基本原则
1.1.1 基本概念和原则
首先,要搞清楚 Spark 的几个基本概念和原则,否则系统的性能调优无从谈起:
每一台 host 上面可以并行 N 个 worker,每一个 worker 下面可以并行 M 个 executor,task 们会被分配到 executor 上面去执行。stage 指的是一组并行运行的 task,stage 内部是不能出现 shuffle 的,因为 shuffle 就像篱笆一样阻止了并行 task 的运行,遇到 shuffle 就意味着到了 stage 的边界。
CPU 的 core 数量,每个 executor 可以占用一个或多个 core,可以通过观察 CPU 的使用率变化来了解计算资源的使用情况,例如,很常见的一种浪费是一个 executor 占用了多个 core,但是总的 CPU 使用率却不高(因为一个 executor 并不总能充分利用多核的能力),这个时候可以考虑让一个 executor 占用更少的 core,同时 worker 下面增加更多的 executor,或者一台 host 上面增加更多的 worker 来增加并行执行的 executor 的数量,从而增加 CPU 利用率。但是增加 executor 的时候需要考虑好内存消耗,因为一台机器的内存分配给越多的 executor,每个 executor 的内存就越小,以致出现过多的数据 spill over 甚至 out of memory 的情况。
partition 和 parallelism,partition 指的就是数据分片的数量,每一次 task 只能处理一个 partition 的数据,这个值太小了会导致每片数据量太大,导致内存压力,或者诸多 executor 的计算能力无法利用充分;但是如果太大了则会导致分片太多,执行效率降低。在执行 action 类型操作的时候(比如各种 reduce 操作),partition 的数量会选择 parent RDD 中最大的那一个。而 parallelism 则指的是在 RDD 进行 reduce 类操作的时候,默认返回数据的 paritition 数量(而在进行 map 类操作的时候,partition 数量通常取自 parent RDD 中较大的一个,而且也不会涉及 shuffle,因此这个 parallelism 的参数没有影响)。所以说,这两个概念密切相关,都是涉及到数据分片的,作用方式其实是统一的。通过spark.default.parallelism可以设置默认的分片数量,而很多 RDD 的操作都可以指定一个 partition 参数来显式控制具体的分片数量。
看这样几个例子:
(1)实践中跑的 Spark job,有的特别慢,查看 CPU 利用率很低,可以尝试减少每个 executor 占用 CPU core 的数量,增加并行的 executor 数量,同时配合增加分片,整体上增加了 CPU 的利用率,加快数据处理速度。
(2)发现某 job 很容易发生内存溢出,我们就增大分片数量,从而减少了每片数据的规模,同时还减少并行的 executor 数量,这样相同的内存资源分配给数量更少的 executor,相当于增加了每个 task 的内存分配,这样运行速度可能慢了些,但是总比 OOM 强。
(3)数据量特别少,有大量的小文件生成,就减少文件分片,没必要创建那么多 task,这种情况,如果只是最原始的 input 比较小,一般都能被注意到;但是,如果是在运算过程中,比如应用某个 reduceBy 或者某个 filter 以后,数据大量减少,这种低效情况就很少被留意到。
最后再补充一点,随着参数和配置的变化,性能的瓶颈是变化的,在分析问题的时候不要忘记。例如在每台机器上部署的 executor 数量增加的时候,性能一开始是增加的,同时也观察到 CPU 的平均使用率在增加;但是随着单台机器上的 executor 越来越多,性能下降了,因为随着 executor 的数量增加,被分配到每个 executor 的内存数量减小,在内存里直接操作的越来越少,spill over 到磁盘上的数据越来越多,自然性能就变差了。
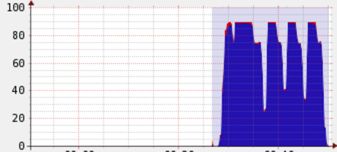
下面给这样一个直观的例子,当前总的 cpu 利用率并不高:
但是经过根据上述原则的的调整之后,可以显著发现 cpu 总利用率增加了:
其次,涉及性能调优我们经常要改配置,在 Spark 里面有三种常见的配置方式,虽然有些参数的配置是可以互相替代,但是作为最佳实践,还是需要遵循不同的情形下使用不同的配置:
1、设置环境变量,这种方式主要用于和环境、硬件相关的配置;
2、命令行参数,这种方式主要用于不同次的运行会发生变化的参数,用双横线开头;
3、代码里面(比如 Scala)显式设置(SparkConf 对象),这种配置通常是 application 级别的配置,一般不改变。
举一个配置的具体例子。slave、worker 和 executor 之间的比例调整。我们经常需要调整并行的 executor 的数量,那么简单说有两种方式:
• 1、每个 worker 内始终跑一个 executor,但是调整单台 slave 上并行的 worker 的数量。比如,SPARK_WORKER_INSTANCES可以设置每个 slave 的 worker 的数量,但是在改变这个参数的时候,比如改成 2,一定要相应设置SPARK_WORKER_CORES的值,让每个 worker 使用原有一半的 core,这样才能让两个 worker 一同工作;
• 2、每台 slave 内始终只部署一个 worker,但是 worker 内部署多个 executor。我们是在 YARN 框架下采用这个调整来实现 executor 数量改变的,一种典型办法是,一个 host 只跑一个 worker,然后配置spark.executor.cores为 host 上 CPU core 的 N 分之一,同时也设置spark.executor.memory为 host 上分配给 Spark 计算内存的 N 分之一,这样这个 host 上就能够启动 N 个 executor。
有的配置在不同的 MR 框架/工具下是不一样的,比如 YARN 下有的参数的默认取值就不同,这点需要注意。
明确这些基础的事情以后,再来一项一项看性能调优的要点。

1.1.2 性能监控方式

Spark Web UI
Spark 提供了一些基本的 Web 监控页面,对于日常监控十分有用。
通过 http://hadoop102:4040(默认端口是 4040,可以通过 spark.ui.port 修改)我们可以获得运行中的程序信息,如下:
(1)stages 和 tasks 调度情况;
(2)RDD 大小及内存使用;
(3)系统环境信息;
(4)正在执行的 executor 信息。
如果想当 Spark 应用退出后,仍可以获得历史 Spark 应用的 stages 和 tasks 执行信息,便于分析程序不明原因挂掉的情况。可以开启 History Server。配置方法如下:
(1)$SPARK_HOME/conf/spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.retainedApplications=50
Dspark.history.fs.logDirectory=hdfs://hadoop102:9000/directory"
说明:
spark.history.retainedApplica-tions #仅显示最近50个应用
spark.history.fs.logDirectory #Spark History Server 页面只展示该路径下的信息
(2)$SPARK_HOME/conf/spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:9000/directory #应用在运行过程中所有的信息均记录在该属性指定的路径下
spark.eventLog.compress true
(3)HistoryServer 启动
$SPARK_HOMR/bin/start-histrory-server.sh
(4)HistoryServer 停止
$SPARK_HOMR/bin/stop-histrory-server.sh
同时 Executor 的 logs 也是查看的一个出处:
• Standalone 模式:$SPARK_HOME/logs
• YARN 模式:在 yarn-site.xml 文件中配置了 YARN 日志的存放位置:yarn.nodemanager.log-dirs,或使用命令获取 yarn logs -applicationId。
同时通过配置 ganglia,可以分析集群的使用状况和资源瓶颈,但是默认情况下 ganglia 是未被打包的,需要在 mvn 编译时添加 -Pspark-ganglia-lgpl,并修改配置文件 $SPARK_HOME/conf/metrics.properties。
参考文章链接:https://www.cnblogs.com/chenmingjun/p/10745505.html#_label1_4
其他监控工具
• Nmon(http://nmon.sourceforge.net/pmwiki.php)
Nmon:输入,c:CPU ,n:网络 ,m:内存 ,d:磁盘
• Jmeter(http://jmeter.apache.org/)
通常使用 Jmeter 做系统性能参数的实时展示,JMeter 的安装非常简单,从官方网站上下载,解压之后即可使用。运行命令在 %JMETER_HOME%/bin 下,对于 Windows 用户,直接使用 jmeter.bat 即可。
启动 jmeter:创建测试计划,设置线程组设置循环次数。
添加监听器:jp@gc - PerfMon Metrics Collector。
设置监听器:监听主机端口及监听内容,例如 CPU。
启动监听:可以实时获得节点的 CPU 状态信息,从下图可看出 CPU 已出现瓶颈。
• Jprofiler(http://www.ej-technologies.com/products/jprofiler/overview.html)
JProfiler 是一个全功能的 Java 剖析工具(profiler),专用于分析 J2SE 和 J2EE 应用程式。它把 CPU、线程和内存的剖析组合在一个强大的应用中。JProfiler 的 GUI 可以更方便地找到性能瓶颈、抓住内存泄漏(memory leaks),并解决多线程的问题。例如分析哪个对象占用的内存比较多;哪个方法占用较大的 CPU 资源等;我们通常使用 Jprofiler 来监控 Spark 应用在 local 模式下运行时的性能瓶颈和内存泄漏情况。
1.1.3 调优要点
内存调整要点
Memory Tuning,Java 对象会占用原始数据 2~5 倍甚至更多的空间。最好的检测对象内存消耗的办法就是创建 RDD,然后放到 cache 里面去,然后在 UI 上面看 storage 的变化。使用-XX:+UseCompressedOops选项可以压缩指针(8 字节变成 4 字节)。在调用 collect 等 API 的时候也要小心–大块数据往内存拷贝的时候心里要清楚。内存要留一些给操作系统,比如 20%,这里面也包括了 OS 的 buffercache,如果预留得太少了,会见到这样的错误:
“Required executor memory (235520+23552 MB) is above the max threshold (241664MB) of this cluster! Please increase the value of ‘yarn.scheduler.maximum-allocation-mb’.
或者干脆就没有这样的错误,但是依然有因为内存不足导致的问题,有的会有警告,比如这个:
“16/01/13 23:54:48 WARN scheduler.TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient memory
有的时候连这样的日志都见不到,而是见到一些不清楚原因的 executor 丢失信息:
“Exception in thread “main” org.apache.spark.SparkException: Job aborted due to stage failure: Task 12 in stage 17.0 failed 4 times, most recent failure: Lost task 12.3 in stage 17.0 (TID 1257, ip-10-184-192-56.ec2.internal): ExecutorLostFailure (executor 79 lost)
Reduce Task 的内存使用。在某些情况下 reduce task 特别消耗内存,比如当 shuffle 出现的时候,比如 sortByKey、groupByKey、reduceByKey 和 join 等,要在内存里面建立一个巨大的 hash table。其中一个解决办法是增大 level of parallelism,这样每个 task 的输入规模就相应减小。另外,注意 shuffle 的内存上限设置,有时候有足够的内存,但是 shuffle 内存不够的话,性能也是上不去的。我们在有大量数据 join 等操作的时候,shuffle 的内存上限经常配置到 executor 的 50%。
注意原始 input 的大小,有很多操作始终都是需要某类全集数据在内存里面完成的,那么并非拼命增加 parallelism 和 partition 的值就可以把内存占用减得非常小的。我们遇到过某些性能低下甚至 OOM 的问题,是改变这两个参数所难以缓解的。但是可以通过增加每台机器的内存,或者增加机器的数量都可以直接或间接增加内存总量来解决。
另外,有一些 RDD 的 API,比如 cache、persist,都会把数据强制放到内存里面,如果并不明确这样做带来的好处,就不要用它们。
内存优化有三个方面的考虑:对象所占用的内存、访问对象的消耗以及垃圾回收所占用的开销。
1、对象所占内存,优化数据结构
Spark 默认使用 Java 序列化对象,虽然 Java 对象的访问速度更快,但其占用的空间通常比其内部的属性数据大2-5倍。为了减少内存的使用,减少 Java 序列化后的额外开销,下面列举一些 Spark 官网提供的方法。
(1)使用对象数组以及原始类型(primitive type)数组以替代 Java 或者 Scala 集合类(collection class)。fastutil 库为原始数据类型提供了非常方便的集合类,且兼容 Java 标准类库。
(2)尽可能地避免采用含有指针的嵌套数据结构来保存小对象。
(3)考虑采用数字 ID 或者枚举类型以便替代 String 类型的主键。
(4)如果内存少于 32GB,设置 JVM 参数-XX:+UseCom-pressedOops以便将 8 字节指针修改成 4 字节。与此同时,在 Java 7 或者更高版本,设置 JVM 参数-XX:+UseCompressedStrings以便采用 8 比特来编码每一个 ASCII 字符。
2、内存回收
(1)获取内存统计信息:优化内存前需要了解集群的内存回收频率、内存回收耗费时间等信息,可以在spark-env.sh中设置SPARK_JAVA_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps $ SPARK_JAVA_OPTS"来获取每一次内存回收的信息。
(2)优化缓存大小:默认情况 Spark 采用运行内存(spark.executor.memory)的 60% 来进行 RDD 缓存。这表明在任务执行期间,有 40% 的内存可以用来进行对象创建。如果任务运行速度变慢且 JVM 频繁进行内存回收,或者内存空间不足,那么降低缓存大小设置可以减少内存消耗,可以降低spark.storage.memoryFraction的大小。
3、频繁 GC 或者 OOM
针对这种情况,首先要确定现象是发生在 Driver 端还是在 Executor 端,然后在分别处理。
Driver 端:通常由于计算过大的结果集被回收到 Driver 端导致,需要调大 Driver 端的内存解决,或者进一步减少结果集的数量。
Executor 端:
(1)以外部数据作为输入的 Stage:这类 Stage 中出现 GC 通常是因为在 Map 侧进行 map-side-combine 时,由于 group 过多引起的。解决方法可以增加 partition 的数量(即 task 的数量)来减少每个 task 要处理的数据,来减少 GC 的可能性。
(2)以 shuffle 作为输入的 Stage:这类 Stage 中出现 GC 的通常原因也是和 shuffle 有关,常见原因是某一个或多个 group 的数据过多,也就是所谓的数据倾斜,最简单的办法就是增加 shuffle 的 task 数量,比如在 SparkSQL 中设置SET spark.sql.shuffle.partitions=400,如果调大 shuffle 的 task 无法解决问题,说明你的数据倾斜很严重,某一个 group 的数据远远大于其他的 group,需要你在业务逻辑上进行调整,预先针对较大的 group 做单独处理。
集群并行度调整要点
在 Spark 集群环境下,只有足够高的并行度才能使系统资源得到充分的利用,可以通过修改 spark-env.sh 来调整 Executor 的数量和使用资源,Standalone 和 YARN 方式资源的调度管理是不同的。
在 Standalone 模式下:
(1)每个节点使用的最大内存数:SPARK_WORKER_INSTANCES * SPARK_WORKER_MEMORY
(2)每个节点的最大并发 task 数:SPARK_WORKER_INSTANCES * SPARK_WORKER_CORES
在YARN模式下:
(1)集群 task 并行度:SPARK_ EXECUTOR_INSTANCES * SPARK_EXECUTOR_CORES
(2)集群内存总量:(executor 个数) * (SPARK_EXECUTOR_MEMORY + spark.yarn.executor.memoryOverhead) + (SPARK_DRIVER_MEMORY + spark.yarn.driver.memoryOverhead)。
重点强调:Spark 对 Executor 和 Driver 额外添加堆内存大小:
Executor 端:由 spark.yarn.executor.memoryOverhead 设置,默认值 executorMemory * 0.07 与 384 的最大值。
Driver 端:由 spark.yarn.driver.memoryOverhead 设置,默认值 driverMemory * 0.07 与 384 的最大值。
通过调整上述参数,可以提高集群并行度,让系统同时执行的任务更多,那么对于相同的任务,并行度高了,可以减少轮询次数。举例说明:如果一个 stage 有 100task,并行度为 50,那么执行完这次任务,需要轮询两次才能完成,如果并行度为 100,那么一次就可以了。
但是在资源相同的情况,并行度高了,相应的 Executor 内存就会减少,所以需要根据实际请况协调内存和 core。此外,Spark 能够非常有效的支持短时间任务(例如:200ms),因为会对所有的任务复用 JVM,这样能减小任务启动的消耗,Standalone 模式下,core 可以允许 1-2 倍于物理 core 的数量进行超配。
Level of Parallelism。指定它以后,在进行 reduce 类型操作的时候,默认 partition 的数量就被指定了。这个参数在实际工程中通常是必不可少的,一般都要根据 input 和每个 executor 内存的大小来确定。设置level of parallelism或者属性spark.default.parallelism来改变并行级别,通常来说,每一个 CPU 核可以分配 2~3 个 task。
CPU core 的访问模式是共享还是独占。即 CPU 核是被同一 host 上的 executor 共享还是瓜分并独占。比如,一台机器上共有 32 个 CPU core 的资源,同时部署了两个 executor,总内存是 50G,那么一种方式是配置spark.executor.cores为 16,spark.executor.memory为 20G,这样由于内存的限制,这台机器上会部署两个 executor,每个都使用 20G 内存,并且各使用 “独占” 的 16 个 CPU core 资源;而在内存资源不变的前提下,也可以让这两个 executor “共享” 这 32 个 core。根据测试,独占模式的性能要略好与共享模式。
GC调优。打印 GC 信息:-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps。要记得默认 60% 的 executor 内存可以被用来作为 RDD 的缓存,因此只有 40% 的内存可以被用来作为对象创建的空间,这一点可以通过设置spark.storage.memoryFraction改变。如果有很多小对象创建,但是这些对象在不完全 GC 的过程中就可以回收,那么增大 Eden 区会有一定帮助。如果有任务从 HDFS 拷贝数据,内存消耗有一个简单的估算公式–比如 HDFS 的 block size 是 64MB,工作区内有 4 个 task 拷贝数据,而解压缩一个 block 要增大 3 倍大小,那么估算内存消耗就是:4364MB。另外,还有一种情况:GC 默认情况下有一个限制,默认是 GC 时间不能超过 2% 的 CPU 时间,但是如果大量对象创建(在 Spark 里很容易出现,代码模式就是一个 RDD 转下一个 RDD),就会导致大量的 GC 时间,从而出现 “OutOfMemoryError: GC overhead limit exceeded”,对于这个,可以通过设置-XX:-UseGCOverheadLimit关掉它。
序列化和传输
Data Serialization,默认使用的是 Java Serialization,这个程序员最熟悉,但是性能、空间表现都比较差。还有一个选项是 Kryo Serialization,更快,压缩率也更高,但是并非支持任意类的序列化。在 Spark UI 上能够看到序列化占用总时间开销的比例,如果这个比例高的话可以考虑优化内存使用和序列化。
Broadcasting Large Variables。在 task 使用静态大对象的时候,可以把它 broadcast 出去。Spark 会打印序列化后的大小,通常来说如果它超过 20KB 就值得这么做。有一种常见情形是,一个大表 join 一个小表,把小表 broadcast 后,大表的数据就不需要在各个 node 之间疯跑,安安静静地呆在本地等小表 broadcast 过来就好了。
Data Locality。数据和代码要放到一起才能处理,通常代码总比数据要小一些,因此把代码送到各处会更快。Data Locality 是数据和处理的代码在屋里空间上接近的程度:PROCESS_LOCAL(同一个 JVM)、NODE_LOCAL(同一个 node,比如数据在 HDFS 上,但是和代码在同一个 node)、NO_PREF、RACK_LOCAL(不在同一个 server,但在同一个机架)、ANY。当然优先级从高到低,但是如果在空闲的 executor 上面没有未处理数据了,那么就有两个选择:
(1)要么等如今繁忙的 CPU 闲下来处理尽可能“本地”的数据,
(2)要么就不等直接启动 task 去处理相对远程的数据。
默认当这种情况发生 Spark 会等一会儿(spark.locality),即策略(1),如果繁忙的 CPU 停不下来,就会执行策略(2)。
代码里对大对象的引用。在 task 里面引用大对象的时候要小心,因为它会随着 task 序列化到每个节点上去,引发性能问题。只要序列化的过程不抛出异常,引用对象序列化的问题事实上很少被人重视。如果,这个大对象确实是需要的,那么就不如干脆把它变成 RDD 好了。绝大多数时候,对于大对象的序列化行为,是不知不觉发生的,或者说是预期之外的,比如在我们的项目中有这样一段代码:
rdd.map(r => {
println(BackfillTypeIndex)
})
其实呢,它等价于这样:
rdd.map(r => {
println(this.BackfillTypeIndex)
})
不要小看了这个 this,有时候它的序列化是非常大的开销。
对于这样的问题,一种最直接的解决方法就是:
val dereferencedVariable = this.BackfillTypeIndex
rdd.map(r => println(dereferencedVariable)) // "this" is not serialized
相关地,注解 @transient 用来标识某变量不要被序列化,这对于将大对象从序列化的陷阱中排除掉是很有用的。另外,注意 class 之间的继承层级关系,有时候一个小的 case class 可能来自一棵大树。
文件读写
文件存储和读取的优化。比如对于一些 case 而言,如果只需要某几列,使用 rcfile 和 parquet 这样的格式会大大减少文件读取成本。再有就是存储文件到 S3 上或者 HDFS 上,可以根据情况选择更合适的格式,比如压缩率更高的格式。另外,特别是对于 shuffle 特别多的情况,考虑留下一定量的额外内存给操作系统作为操作系统的 buffer cache,比如总共 50G 的内存,JVM 最多分配到 40G 多一点。
文件分片。比如在 S3 上面就支持文件以分片形式存放,后缀是 partXX。使用 coalesce 方法来设置分成多少片,这个调整成并行级别或者其整数倍可以提高读写性能。但是太高太低都不好,太低了没法充分利用 S3 并行读写的能力,太高了则是小文件太多,预处理、合并、连接建立等等都是时间开销啊,读写还容易超过 throttle。
任务调整要点
Spark 的 Speculation。通过设置spark.speculation等几个相关选项,可以让 Spark 在发现某些 task 执行特别慢的时候,可以在不等待完成的情况下被重新执行,最后相同的 task 只要有一个执行完了,那么最快执行完的那个结果就会被采纳。
减少Shuffle。其实 Spark 的计算往往很快,但是大量开销都花在网络和 IO 上面,而 shuffle 就是一个典型。举个例子,如果 (k, v1) join (k, v2) => (k, v3),那么,这种情况其实 Spark 是优化得非常好的,因为需要 join 的都在一个 node 的一个 partition 里面,join 很快完成,结果也是在同一个 node(这一系列操作可以被放在同一个 stage 里面)。但是如果数据结构被设计为 (obj1) join (obj2) => (obj3),而其中的 join 条件为 obj1.column1 == obj2.column1,这个时候往往就被迫 shuffle 了,因为不再有同一个 key 使得数据在同一个 node 上的强保证。在一定要 shuffle 的情况下,尽可能减少 shuffle 前的数据规模,比如这个避免 groupByKey 的例子。下面这个比较的图片来自 Spark Summit 2013 的一个演讲,讲的是同一件事情:
Repartition。运算过程中数据量时大时小,选择合适的 partition 数量关系重大,如果太多 partition 就导致有很多小任务和空任务产生;如果太少则导致运算资源没法充分利用,必要时候可以使用 repartition 来调整,不过它也不是没有代价的,其中一个最主要代价就是 shuffle。再有一个常见问题是数据大小差异太大,这种情况主要是数据的 partition 的 key 其实取值并不均匀造成的(默认使用 HashPartitioner),需要改进这一点,比如重写 hash 算法。测试的时候想知道 partition 的数量可以调用rdd.partitions().size()获知。
Task时间分布。关注 Spark UI,在 Stage 的详情页面上,可以看得到 shuffle 写的总开销,GC 时间,当前方法栈,还有 task 的时间花费。如果你发现 task 的时间花费分布太散,就是说有的花费时间很长,有的很短,这就说明计算分布不均,需要重新审视数据分片、key 的 hash、task 内部的计算逻辑等等,瓶颈出现在耗时长的 task 上面。

重用资源。有的资源申请开销巨大,而且往往相当有限,比如建立连接,可以考虑在 partition 建立的时候就创建好(比如使用 mapPartition 方法),这样对于每个 partition 内的每个元素的操作,就只要重用这个连接就好了,不需要重新建立连接。
同时 Spark 的任务数量是由 stage 中的起始的所有 RDD 的 partition 之和数量决定,所以需要了解每个 RDD 的 partition 的计算方法。以 Spark 应用从 HDFS 读取数据为例,HadoopRDD 的 partition 切分方法完全继承于 MapReduce 中的 FileInputFormat,具体的 partition 数量由 HDFS 的块大小、mapred.min.split.size 的大小、文件的压缩方式等多个因素决定,详情需要参见 FileInputFormat 的代码。
开启推测机制
推测机制后,如果集群中,某一台机器的几个 task 特别慢,推测机制会将任务分配到其他机器执行,最后 Spark 会选取最快的作为最终结果。在 spark-default.conf 中添加:
spark.speculation true。
推测机制与以下几个参数有关:
(1)spark.speculation.interval 100 #检测周期,单位毫秒
(2)spark.speculation.quantile 0.75 #完成 task 的百分比时启动推测
(3)spark.speculation.multiplier 1.5 #比其他的慢多少倍时启动推测
1.2 数据倾斜优化
1.2.1 为何要处理数据倾斜(Data Skew)
**什么是数据倾斜?**对 Spark/Hadoop 这样的大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。
何谓数据倾斜?数据倾斜指的是,并行处理的数据集中,某一部分(如 Spark 或 Kafka 的一个 Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈。
如果数据倾斜没有解决,完全没有可能进行性能调优,其他所有的调优手段都是一个笑话。数据倾斜是最能体现一个 spark 大数据工程师水平的性能调优问题。
数据倾斜如果能够解决的话,代表对 spark 运行机制了如指掌。数据倾斜俩大直接致命后果。
(1)数据倾斜直接会导致一种情况:Out Of Memory。
(2)运行速度慢,特别慢,非常慢,极端的慢,不可接受的慢。
我们以 100 亿条数据为列子。
个别 Task(80 亿条数据的那个 Task)处理过度大量数据。导致拖慢了整个 Job 的执行时间。这可能导致该 Task 所在的机器 OOM,或者运行速度非常慢。
数据倾斜是如何造成的呢?
在 Shuffle 阶段。同样 Key 的数据条数太多了。导致了某个 key(上图中的 80 亿条)所在的 Task 数据量太大了。远远超过其他 Task 所处理的数据量。
而这样的场景太常见了。二八定律可以证实这种场景。
搞定数据倾斜需要:
(1)搞定 shuffle
(2)搞定业务场景
(3)搞定 cpu core 的使用情况
(4)搞定 OOM 的根本原因等
所以搞定了数据倾斜需要对至少以上的原理了如指掌。所以搞定数据倾斜是关键中的关键。
一个经验结论是:一般情况下,OOM 的原因都是数据倾斜。某个 task 任务数据量太大,GC 的压力就很大。这比不了 Kafka,因为 kafka 的内存是不经过 JVM 的,是基于 Linux 内核的 Page。
数据倾斜的原理很简单:在进行 shuffle 的时候,必须将各个节点上相同的 key 拉取到某个节点上的一个 task 来进行处理,比如按照 key 进行聚合或 join 等操作。此时如果某个 key 对应的数据量特别大的话,就会发生数据倾斜。比如大部分 key 对应 10 条数据,但是个别 key 却对应了 100 万条数据,那么大部分 task 可能就只会分配到 10 条数据,然后 1 秒钟就运行完了;但是个别 task 可能分配到了 100 万数据,要运行一两个小时。因此,整个 Spark 作业的运行进度是由运行时间最长的那个 task 决定的。
因此出现数据倾斜的时候,Spark 作业看起来会运行得非常缓慢,甚至可能因为某个 task 处理的数据量过大导致内存溢出。
下图就是一个很清晰的例子:hello 这个 key,在三个节点上对应了总共 7 条数据,这些数据都会被拉取到同一个 task 中进行处理;而 world 和 you 这两个 key 分别才对应 1 条数据,所以另外两个 task 只要分别处理 1 条数据即可。此时第一个 task 的运行时间可能是另外两个 task 的 7 倍,而整个 stage 的运行速度也由运行最慢的那个 task 所决定。
[外链图片转存失败(img-iBF1PXvk-1562758075577)(https://s2.ax1x.com/2019/05/04/Eame8e.png)]
由于同一个 Stage 内的所有 Task 执行相同的计算,在排除不同计算节点计算能力差异的前提下,不同 Task 之间耗时的差异主要由该 Task 所处理的数据量决定。

1.2.2 如何定位导致数据倾斜的代码
数据倾斜只会发生在 shuffle 过程中。这里给大家罗列一些常用的并且可能会触发 shuffle 操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition 等。出现数据倾斜时,可能就是你的代码中使用了这些算子中的某一个所导致的。
1、某个 task 执行特别慢的情况
首先要看的,就是数据倾斜发生在第几个 stage 中。
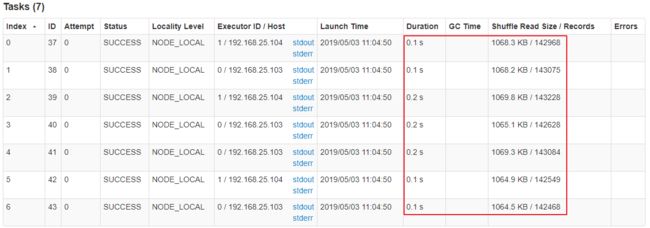
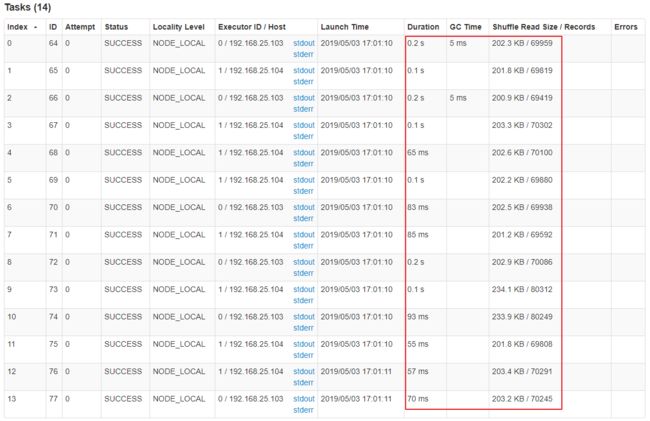
可以通过 Spark Web UI 来查看当前运行到了第几个 stage,看一下当前这个 stage 各个 task 分配的数据量,从而进一步确定是不是 task 分配的数据不均匀导致了数据倾斜。
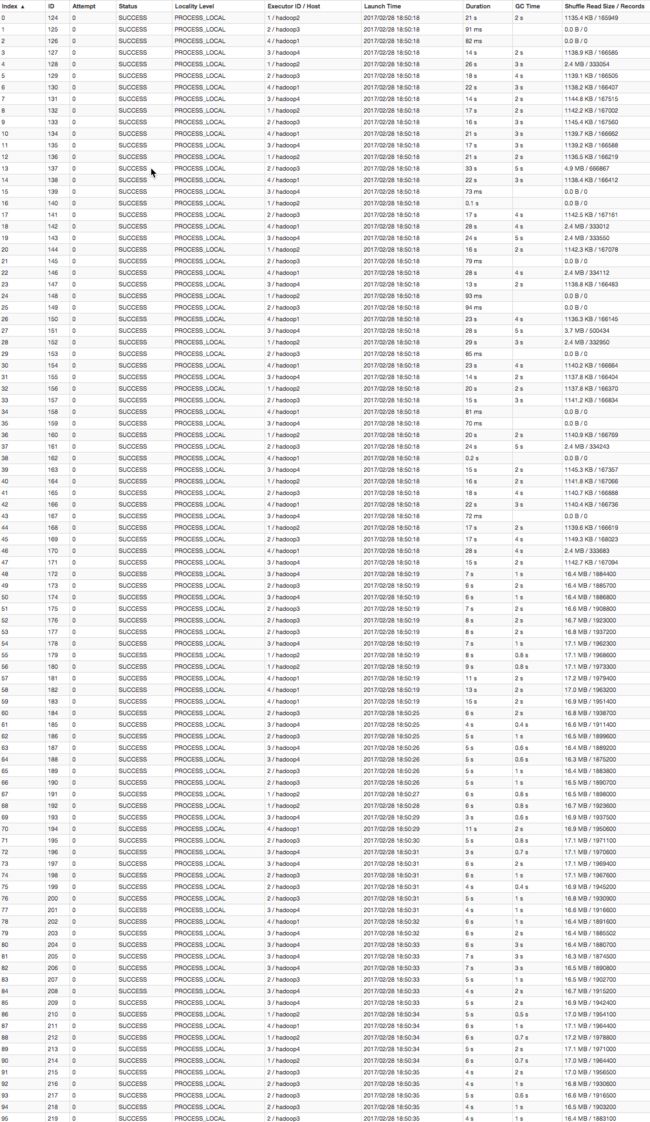
比如下图中,倒数第三列显示了每个 task 的运行时间。明显可以看到,有的 task 运行特别快,只需要几秒钟就可以运行完;而有的 task 运行特别慢,需要几分钟才能运行完,此时单从运行时间上看就已经能够确定发生数据倾斜了。此外,倒数第一列显示了每个 task 处理的数据量,明显可以看到,运行时间特别短的 task 只需要处理几百 KB 的数据即可,而运行时间特别长的 task 需要处理几千 KB 的数据,处理的数据量差了 10 倍。此时更加能够确定是发生了数据倾斜。
知道数据倾斜发生在哪一个 stage 之后,接着我们就需要根据 stage 划分原理,推算出来发生倾斜的那个 stage 对应代码中的哪一部分,这部分代码中肯定会有一个 shuffle 类算子。精准推算 stage 与代码的对应关系,这里介绍一个相对简单实用的推算方法:只要看到 Spark 代码中出现了一个 shuffle 类算子或者是 Spark SQL 的 SQL 语句中出现了会导致 shuffle 的语句(比如 group by 语句),那么就可以判定,以那个地方为界限划分出了前后两个 stage。
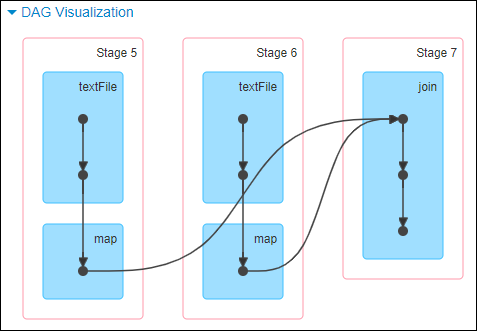
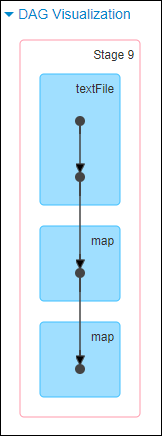
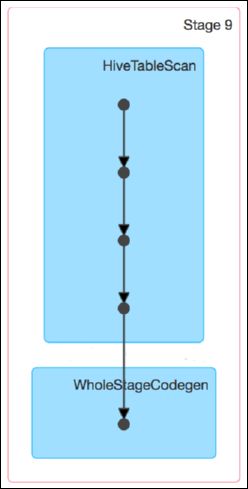
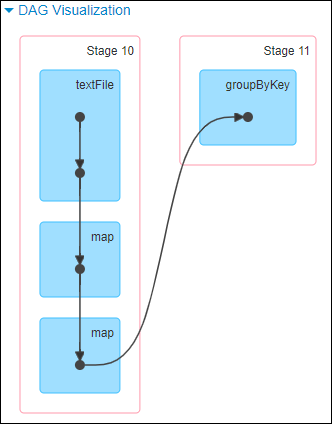
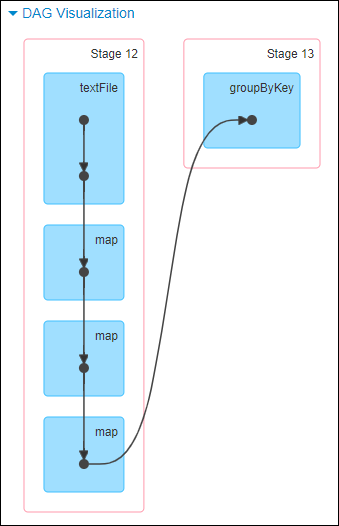
这里我们就以 Spark 最基础的入门程序–单词计数来举例,如何用最简单的方法大致推算出一个 stage 对应的代码。如下示例,在整个代码中,只有一个 reduceByKey 是会发生 shuffle 的算子,因此就可以认为,以这个算子为界限,会划分出前后两个 stage。
stage0,主要是执行从 textFile 到 map 操作,以及执行 shuffle write 操作。shuffle write 操作,我们可以简单理解为对 pairs RDD 中的数据进行分区操作,每个 task 处理的数据中,相同的 key 会写入同一个磁盘文件内。
stage1,主要是执行从 reduceByKey 到 collect 操作,stage1 的各个 task 一开始运行,就会首先执行 shuffle read 操作。执行 shuffle read 操作的 task,会从 stage0 的各个 task 所在节点拉取属于自己处理的那些 key,然后对同一个 key 进行全局性的聚合或 join 等操作,在这里就是对 key 的 value 值进行累加。stage1 在执行完 reduceByKey 算子之后,就计算出了最终的 wordCounts RDD,然后会执行 collect 算子,将所有数据拉取到 Driver 上,供我们遍历和打印输出。

示例代码:
val conf = new SparkConf()
val sc = new SparkContext(conf)
val lines = sc.textFile("hdfs://...")
val words = lines.flatMap(_.split(" "))
val pairs = words.map((_, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.collect().foreach(println(_))
通过对单词计数程序的分析,希望能够让大家了解最基本的 stage 划分的原理,以及 stage 划分后 shuffle 操作是如何在两个 stage 的边界处执行的。然后我们就知道如何快速定位出发生数据倾斜的 stage 对应代码的哪一个部分了。比如我们在 Spark Web UI 或者本地 log 中发现,stage1 的某几个 task 执行得特别慢,判定 stage1 出现了数据倾斜,那么就可以回到代码中定位出 stage1 主要包括了 reduceByKey 这个 shuffle 类算子,此时基本就可以确定是由 reduceByKey 算子导致的数据倾斜问题。比如某个单词出现了 100 万次,其他单词才出现 10 次,那么 stage1 的某个 task 就要处理 100 万数据,整个 stage 的速度就会被这个 task 拖慢。
2、某个 task 莫名其妙内存溢出的情况
这种情况下去定位出问题的代码就比较容易了。我们建议直接看 yarn-client 模式下本地 log 的异常栈,或者是通过 YARN 查看 yarn-cluster 模式下的 log 中的异常栈。一般来说,通过异常栈信息就可以定位到你的代码中哪一行发生了内存溢出。然后在那行代码附近找找,一般也会有 shuffle 类算子,此时很可能就是这个算子导致了数据倾斜。
但是大家要注意的是,不能单纯靠偶然的内存溢出就判定发生了数据倾斜。因为自己编写的代码的 bug,以及偶然出现的数据异常,也可能会导致内存溢出。因此还是要按照上面所讲的方法,通过 Spark Web UI 查看报错的那个 stage 的各个 task 的运行时间以及分配的数据量,才能确定是否是由于数据倾斜才导致了这次内存溢出。
3、查看导致数据倾斜的 key 的数据分布情况
知道了数据倾斜发生在哪里之后,通常需要分析一下那个执行了 shuffle 操作并且导致了数据倾斜的 RDD/Hive 表,查看一下其中 key 的分布情况。这主要是为之后选择哪一种技术方案提供依据。针对不同的 key 分布与不同的 shuffle 算子组合起来的各种情况,可能需要选择不同的技术方案来解决。
此时根据你执行操作的情况不同,可以有很多种查看 key 分布的方式:
如果是 Spark SQL 中的 group by、join 语句导致的数据倾斜,那么就查询一下 SQL 中使用的表的 key 分布情况。
如果是对 Spark RDD 执行 shuffle 算子导致的数据倾斜,那么可以在 Spark 作业中加入查看 key 分布的代码,比如 RDD.countByKey()。然后对统计出来的各个 key 出现的次数,collect/take 到客户端打印一下,就可以看到 key 的分布情况。
举例来说,对于上面所说的单词计数程序,如果确定了是 stage1 的 reduceByKey 算子导致了数据倾斜,那么就应该看看进行 reduceByKey 操作的 RDD 中的 key 分布情况,在这个例子中指的就是 pairs RDD 。如下示例,我们可以先对 pairs 采样 10% 的样本数据,然后使用 countByKey 算子统计出每个 key 出现的次数,最后在客户端遍历和打印样本数据中各个 key 的出现次数。
示例代码:
val sampledPairs = pairs.sample(false, 0.1)
val sampledWordCounts = sampledPairs.countByKey()
sampledWordCounts.foreach(println(_))
1.2.3 如何缓解/消除数据倾斜
1、尽量避免数据源的数据倾斜
• 比如数据源是Kafka
以 Spark Stream 通过 DirectStream 方式读取 Kafka 数据为例。由于 Kafka 的每一个 Partition 对应 Spark 的一个 Task(Partition),所以 Kafka 内相关 Topic 的各 Partition 之间数据是否平衡,直接决定 Spark 处理该数据时是否会产生数据倾斜。
Kafka 某一 Topic 内消息在不同 Partition 之间的分布,主要由 Producer 端所使用的 Partition 实现类决定。如果使用随机 Partitioner,则每条消息会随机发送到一个 Partition 中,从而从概率上来讲,各 Partition 间的数据会达到平衡。此时源 Stage(直接读取 Kafka 数据的 Stage)不会产生数据倾斜。
但很多时候,业务场景可能会要求将具备同一特征的数据顺序消费,此时就需要将具有相同特征的数据放于同一个 Partition 中。一个典型的场景是,需要将同一个用户相关的 PV 信息置于同一个 Partition 中。此时,如果产生了数据倾斜,则需要通过其它方式处理。
• 比如数据源是Hive
导致数据倾斜的是 Hive 表。如果该 Hive 表中的数据本身很不均匀(比如某个 key 对应了 100 万数据,其他 key 才对应了10条数据),而且业务场景需要频繁使用 Spark 对 Hive 表执行某个分析操作,那么比较适合使用这种技术方案。
方案实现思路:此时可以评估一下,是否可以通过 Hive 来进行数据预处理(即通过 Hive ETL 预先对数据按照 key 进行聚合,或者是预先和其他表进行 join),然后在 Spark 作业中针对的数据源就不是原来的 Hive 表了,而是预处理后的 Hive 表。此时由于数据已经预先进行过聚合或 join 操作了,那么在 Spark 作业中也就不需要使用原先的 shuffle 类算子执行这类操作了。
方案实现原理:这种方案从根源上解决了数据倾斜,因为彻底避免了在 Spark 中执行 shuffle 类算子,那么肯定就不会有数据倾斜的问题了。但是这里也要提醒一下大家,这种方式属于治标不治本。因为毕竟数据本身就存在分布不均匀的问题,所以 Hive ETL 中进行 group by 或者 join 等 shuffle 操作时,还是会出现数据倾斜,导致 Hive ETL 的速度很慢。我们只是把数据倾斜的发生提前到了 Hive ETL 中,避免 Spark 程序发生数据倾斜而已。
方案优点:实现起来简单便捷,效果还非常好,完全规避掉了数据倾斜,Spark 作业的性能会大幅度提升。
方案缺点:治标不治本,Hive ETL 中还是会发生数据倾斜。
方案实践经验:在一些 Java 系统与 Spark 结合使用的项目中,会出现 Java 代码频繁调用 Spark 作业的场景,而且对 Spark 作业的执行性能要求很高,就比较适合使用这种方案。将数据倾斜提前到上游的 Hive ETL,每天仅执行一次,只有那一次是比较慢的,而之后每次 Java 调用 Spark 作业时,执行速度都会很快,能够提供更好的用户体验。
项目实践经验:在美团·点评的交互式用户行为分析系统中使用了这种方案,该系统主要是允许用户通过 Java Web 系统提交数据分析统计任务,后端通过 Java 提交 Spark 作业进行数据分析统计。要求 Spark 作业速度必须要快,尽量在 10 分钟以内,否则速度太慢,用户体验会很差。所以我们将有些 Spark 作业的 shuffle 操作提前到了 Hive ETL 中,从而让 Spark 直接使用预处理的 Hive 中间表,尽可能地减少 Spark 的 shuffle 操作,大幅度提升了性能,将部分作业的性能提升了 6 倍以上。
2、调整并行度:分散同一个 Task 的不同 Key
方案适用场景:如果我们必须要对数据倾斜迎难而上,那么建议优先使用这种方案,因为这是处理数据倾斜最简单的一种方案。
方案实现思路:在对 RDD 执行 shuffle 算子时,给 shuffle 算子传入一个参数,比如 reduceByKey(1000),该参数就设置了这个 shuffle 算子执行时 shuffle read task 的数量。对于 Spark SQL 中的 shuffle 类语句,比如 group by、join 等,需要设置一个参数,即spark.sql.shuffle.partitions,该参数代表了 shuffle read task 的并行度,该值默认是 200,对于很多场景来说都有点过小。
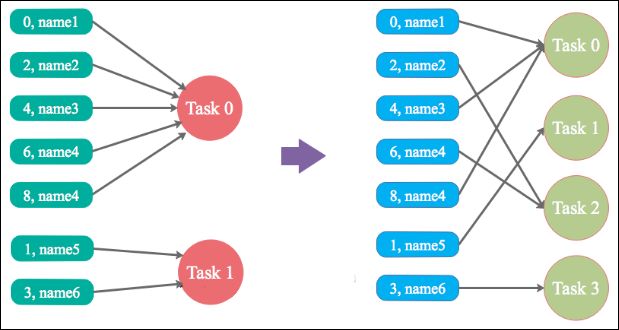
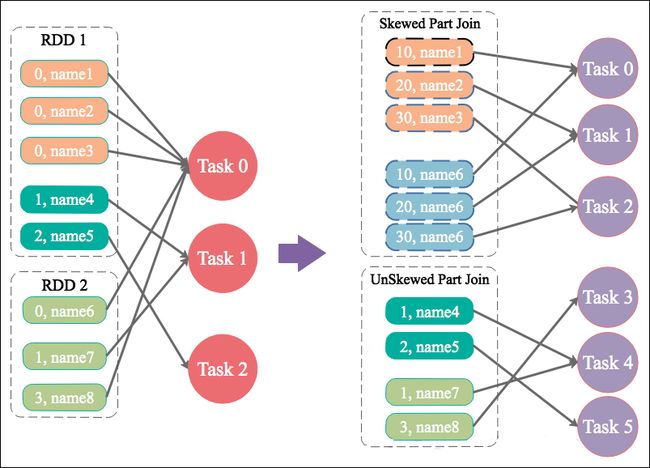
方案实现原理:增加 shuffle read task 的数量,可以让原本分配给一个 task 的多个 key 分配给多个 task,从而让每个 task 处理比原来更少的数据。举例来说,如果原本有 5 个 key,每个 key 对应 10 条数据,这 5 个 key 都是分配给一个 task 的,那么这个 task 就要处理 50 条数据。而增加了 shuffle read task 以后,每个 task 就分配到一个 key,即每个 task 就处理 10 条数据,那么自然每个 task 的执行时间都会变短了。具体原理如下图所示。
方案优点:实现起来比较简单,可以有效缓解和减轻数据倾斜的影响。
方案缺点:只是缓解了数据倾斜而已,没有彻底根除问题,根据实践经验来看,其效果有限。
方案实践经验:该方案通常无法彻底解决数据倾斜,因为如果出现一些极端情况,比如某个 key 对应的数据量有 100 万,那么无论你的 task 数量增加到多少,这个对应着 100 万数据的 key 肯定还是会分配到一个 task 中去处理,因此注定还是会发生数据倾斜的。所以这种方案只能说是在发现数据倾斜时尝试使用的第一种手段,尝试去用最简单的方法缓解数据倾斜而已,或者是和其他方案结合起来使用。
方案实现原理:Spark 在做 Shuffle 时,默认使用 HashPartitioner(非 Hash Shuffle)对数据进行分区。如果并行度设置的不合适,可能造成大量不相同的 Key 对应的数据被分配到了同一个 Task 上,造成该 Task 所处理的数据远大于其它 Task,从而造成数据倾斜。
如果调整 Shuffle 时的并行度,使得原本被分配到同一 Task 的不同 Key 发配到不同 Task 上处理,则可降低原 Task 所需处理的数据量,从而缓解数据倾斜问题造成的短板效应。
案例:
现有一张测试数据集,内有 100 万条数据,每条数据有一个唯一的 id 值。现通过一些处理,使得 id 为 90 万之下的所有数据对 12 取模后余数为 8(即在 Shuffle 并行度为 12 时该数据集全部被 HashPartition 分配到第 8 个 Task),其它数据集 id 不变,从而使得 id 大于 90 万的数据在 Shuffle 时可被均匀分配到所有 Task 中,而 id 小于 90 万的数据全部分配到同一个 Task 中。处理过程如下:
Step1:准备原始数据
原始数据格式:
20111230000005 57375476989eea12893c0c3811607bcf 奇艺高清 1 1 http://www.qiyi.com/
20111230000005 66c5bb7774e31d0a22278249b26bc83a 凡人修仙传 3 1 http://www.booksky.org/BookDetail.aspx?BookID=1050804&Level=1
20111230000007 b97920521c78de70ac38e3713f524b50 本本联盟 1 1 http://www.bblianmeng.com/
20111230000008 6961d0c97fe93701fc9c0d861d096cd9 华南师范大学图书馆 1 1 http://lib.scnu.edu.cn/
......
......
数据说明:
==========数据格式==========
访问时间 用户id 查询词 该URL在返回结果中的排名 用户点击的顺序号 用户点击的URL
20111230000005 57375476989eea12893c0c3811607bcf 奇艺高清 1 1 http://www.qiyi.com/
==========数据注意==========
1、其中用户 ID 是根据用户使用浏览器访问搜索引擎时的 Cookie 信息自动赋值,即同一次使用浏览器输入的不同查询对应同一个用户 ID。
2、数据字段之间用“\t”进行分割
Step2:给原始数据增加 ID 属性
处理原理:将 RDD 通过 zipWithIndex 实现 ID 添加,将 RDD 以制表符分割并转换为 ArrayBuffer,然后通过 mkString 将数据以 Text 输出。
(1)将原始数据上传到到 HDFS 上
[atguigu@hadoop102 software]$ pwd
/opt/software
[atguigu@hadoop102 software]$ /opt/module/hadoop-2.7.2/bin/hdfs dfs -put ./source.txt /
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hbase/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
[atguigu@hadoop102 software]$ /opt/module/hadoop-2.7.2/bin/hdfs dfs -ls /
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hbase/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Found 11 items
drwxr-xr-x - atguigu supergroup 0 2019-04-28 18:26 /data
drwxr-xr-x - atguigu supergroup 0 2019-05-03 01:17 /directory
drwxr-xr-x - atguigu supergroup 0 2019-04-17 19:56 /event_logs
-rw-r--r-- 1 atguigu supergroup 1247306 2019-04-30 19:03 /graphx-wiki-edges.txt
-rw-r--r-- 1 atguigu supergroup 946608 2019-04-30 19:04 /graphx-wiki-vertices.txt
drwxr-xr-x - atguigu supergroup 0 2019-04-30 09:34 /hbase
-rw-r--r-- 1 atguigu supergroup 114845849 2019-05-03 10:12 /source.txt
drwxr-xr-x - atguigu supergroup 0 2019-04-29 11:26 /spark
drwxr-xr-x - atguigu supergroup 0 2019-04-28 00:24 /spark_warehouse
drwxrwx--- - atguigu supergroup 0 2019-04-18 10:23 /tmp
drwxr-xr-x - atguigu supergroup 0 2019-04-22 11:23 /user
[atguigu@hadoop102 software]$
(2)通过 spark-shell 加载原始数据并转换输出
scala> val sourceRdd = sc.textFile("hdfs://hadoop102:9000/source.txt")
sourceRdd: org.apache.spark.rdd.RDD[String] = hdfs://hadoop102:9000/source.txt MapPartitionsRDD[3] at textFile at <console>:24
scala> val sourceWithIndexRdd = sourceRdd.zipWithIndex.map(tuple => {val array = scala.collection.mutable.ArrayBuffer[String](); array++=(tuple._1.split("\t")); tuple._2.toString +=: array; array.toArray})
sourceWithIndexRdd: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[5] at map at <console>:26
scala> sourceWithIndexRdd.map(_.mkString("\t")).saveAsTextFile("hdfs://hadoop102:9000/source_index")
HDFS 上查看转换后的结果
[atguigu@hadoop102 ~]$ /opt/module/hadoop-2.7.2/bin/hdfs dfs -ls /source_index
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hbase/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Found 3 items
-rw-r--r-- 1 atguigu supergroup 0 2019-05-03 10:18 /source_index/_SUCCESS
-rw-r--r-- 1 atguigu supergroup 60813047 2019-05-03 10:18 /source_index/part-00000
-rw-r--r-- 1 atguigu supergroup 60921692 2019-05-03 10:18 /source_index/part-00001
Step3:通过 spark-shell 加载新的数据并进行对应处理
#加载添加了id的原始数据
scala> val sourceRdd = sc.textFile("hdfs://hadoop102:9000/source_index")
sourceRdd: org.apache.spark.rdd.RDD[String] = hdfs://hadoop102:9000/source_index MapPartitionsRDD[1] at textFile at <console>:24
#新建一个 case 类代表数据集
scala> case class brower(id: Int, time: Long, uid: String, keyword: String, url_rank: Int, click_num: Int, click_url: String) extends Serializable
defined class brower
#通过 case 类创建 Dataset
scala> val ds = sourceRdd.map(_.split("\t")).map(attr => brower(attr(0).toInt, attr(1).toLong, attr(2), attr(3), attr(4).toInt, attr(5).toInt, attr(6))).toDS
ds: org.apache.spark.sql.Dataset[brower] = [id: int, time: bigint ... 5 more fields]
#注册一个临时表
scala> ds.createOrReplaceTempView("sourceTable")
#执行新的查询
scala> val newSource = spark.sql("SELECT CASE WHEN id < 900000 THEN (8 + (CAST (RAND() * 50000 AS bigint)) * 12 ) ELSE id END, time, uid, keyword, url_rank, click_num, click_url FROM sourceTable")
newSource: org.apache.spark.sql.DataFrame = [CASE WHEN (id < 900000) THEN (CAST(8 AS BIGINT) + (CAST((rand(-5486683549522524104) * CAST(50000 AS DOUBLE)) AS BIGINT) * CAST(12 AS BIGINT))) ELSE CAST(id AS BIGINT) END: bigint, time: bigint ... 5 more fields]
#将 900000 之前的 ID 设定为 12 取余为 8 的 ID 集,当并行度为 12 时,会通过 hash 分区器分区到第 8 个任务
#输出新的测试数据
scala> newSource.rdd.map(_.mkString("\t")).saveAsTextFile("hdfs://hadoop102:9000/test_data")
Step4:通过上述处理,一份可能造成后续数据倾斜的测试数据已经准备好
接下来,使用 Spark 读取该测试数据,并通过 groupByKey(12) 对 id 分组处理,且 Shuffle 并行度为 12。代码如下:
scala> val sourceRdd = sc.textFile("hdfs://hadoop102:9000/test_data/p*")
sourceRdd: org.apache.spark.rdd.RDD[String] = hdfs://hadoop102:9000/test_data/p* MapPartitionsRDD[1] at textFile at <console>:24
scala> val kvRdd = sourceRdd.map(x => { val parm = x.split("\t"); (parm(0).trim().toInt, parm(1).trim()) })
kvRdd: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[2] at map at <console>:26
scala> kvRdd.groupByKey(12).count
res0: Long = 150000
scala> :quit
本次实验所使用集群节点数为 3,每个节点可被 Yarn 使用的 CPU 核数为 3,内存为 2GB。在 Spark-shell 中进行提交。
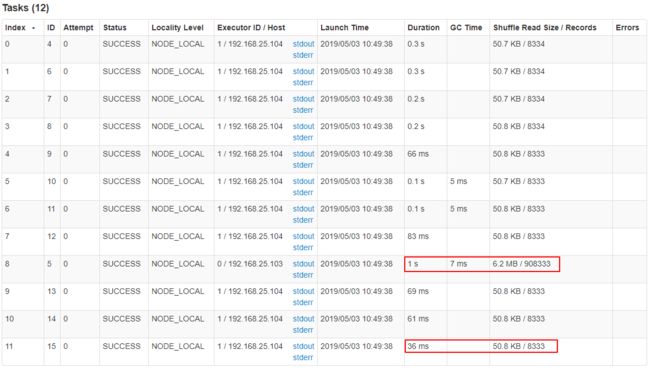
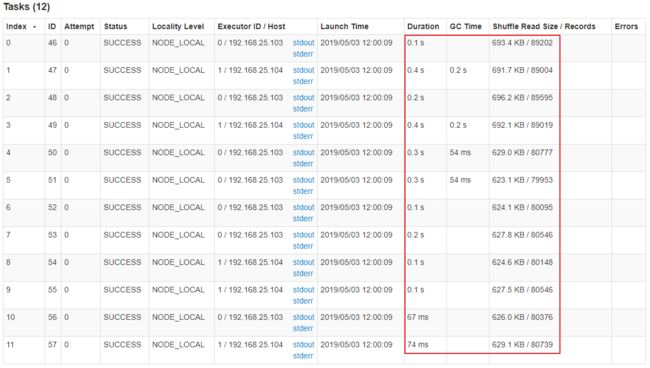
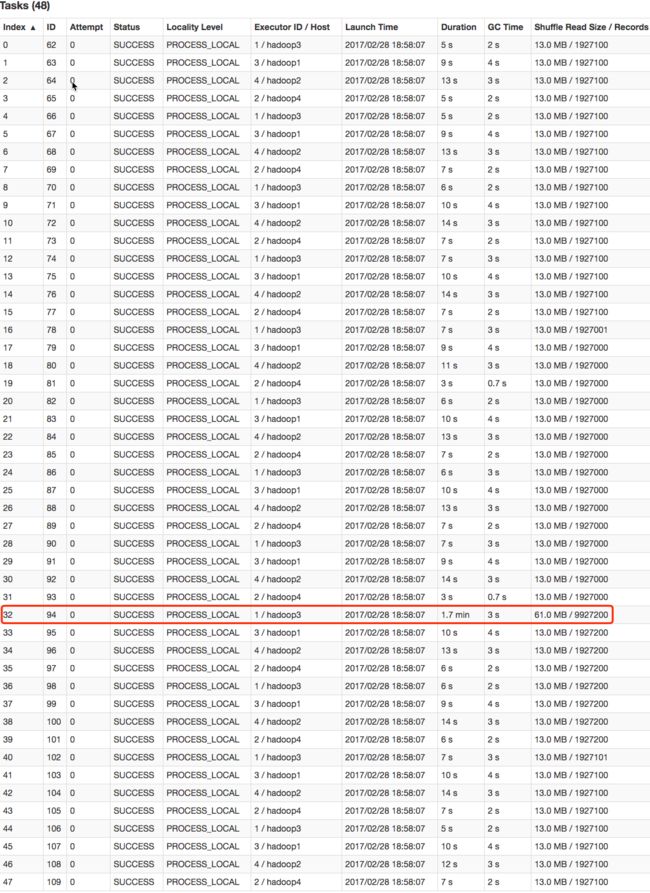
GroupBy Stage 的 Task 状态如下图所示,Task 8 处理的记录数为 90 万,远大于(9 倍于)其它 11 个 Task 处理的 10 万记录。而 Task 8 所耗费的时间为1 秒,远高于其它 11 个 Task 的平均时间。整个 Stage 的时间也为 1 秒,该时间主要由最慢的 Task 8 决定。数据之间处理的比例最大为 105 倍。
在这种情况下,可以通过调整 Shuffle 并行度,使得原来被分配到同一个 Task(即该例中的 Task 8)的不同 Key 分配到不同 Task,从而降低 Task 8 所需处理的数据量,缓解数据倾斜。
通过 groupByKey(17) 将 Shuffle 并行度调整为 17,重新提交到 Spark。新的 Job 的 GroupBy Stage 所有 Task 状态如下图所示。
scala> val sourceRdd = sc.textFile("hdfs://hadoop102:9000/test_data/p*")
sourceRdd: org.apache.spark.rdd.RDD[String] = hdfs://hadoop102:9000/test_data/p* MapPartitionsRDD[1] at textFile at <console>:24
scala> val kvRdd = sourceRdd.map(x =>{ val parm=x.split("\t");(parm(0).trim().toInt, parm(1).trim()) })
kvRdd: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[2] at map at <console>:26
scala> kvRdd.groupByKey(17).count
res0: Long = 150000
scala> :quit

从上图可知,相比以上次一计算,目前每一个计算的数据都比较平均,数据之间的最大比例基本为 1:1,总体时间降到了 0.8 秒。
在这种场景下,调整并行度,并不意味着一定要增加并行度,也可能是减小并行度。如果通过 groupByKey(7) 将 Shuffle 并行度调整为 7,重新提交到 Spark。新 Job 的 GroupBy Stage 的所有 Task 状态如下图所示。
从上图可见,处理记录数都比较平均。
总结:
适用场景:大量不同的 Key 被分配到了相同的 Task 造成该 Task 数据量过大。
解决方案:调整并行度。一般是增大并行度,但有时如本例减小并行度也可达到效果。
方案优点:实现简单,可在需要 Shuffle 的操作算子上直接设置并行度或者使用spark.default.parallelism设置。如果是 Spark SQL,还可通过SET spark.sql.shuffle.partitions=[num_tasks]设置并行度。可用最小的代价解决问题。一般如果出现数据倾斜,都可以通过这种方法先试验几次,如果问题未解决,再尝试其它方法。
方案缺点:适用场景少,只能将分配到同一 Task 的不同 Key 分散开,但对于同一 Key 倾斜严重的情况该方法并不适用。并且该方法一般只能缓解数据倾斜,没有彻底消除问题。从实践经验来看,其效果一般。
3、自定义 Partitioner
方案原理:使用自定义的 Partitioner(默认为 HashPartitioner),将原本被分配到同一个 Task 的不同 Key 分配到不同 Task。
案例:
以上述数据集为例,继续将并发度设置为 12,但是在 groupByKey 算子上,使用自定义的 Partitioner,实现如下:
class CustomerPartitioner(numParts: Int) extends org.apache.spark.Partitioner {
// 覆盖分区数
override def numPartitions: Int = numParts
// 覆盖分区号获取函数
override def getPartition(key: Any): Int = {
val id: Int = key.toString.toInt
if (id <= 900000)
return new java.util.Random().nextInt(100) % 12
else
return id % 12
}
}
执行如下代码:
scala> :paste
// Entering paste mode (ctrl-D to finish)
class CustomerPartitioner(numParts: Int) extends org.apache.spark.Partitioner {
// 覆盖分区数
override def numPartitions: Int = numParts
// 覆盖分区号获取函数
override def getPartition(key: Any): Int = {
val id: Int = key.toString.toInt
if (id <= 900000)
return new java.util.Random().nextInt(100) % 12
else
return id % 12
}
}
// Exiting paste mode, now interpreting.
defined class CustomerPartitioner
scala> val sourceRdd = sc.textFile("hdfs://hadoop102:9000/test_data/p*")
sourceRdd: org.apache.spark.rdd.RDD[String] = hdfs://hadoop102:9000/test_data/p* MapPartitionsRDD[10] at textFile at <console>:24
scala> val kvRdd = sourceRdd.map(x =>{ val parm=x.split("\t");(parm(0).trim().toInt, parm(1).trim()) })
kvRdd: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[11] at map at <console>:26
scala> kvRdd.groupByKey(new CustomerPartitioner(12)).count
res5: Long = 565650
scala> :quit
由下图可见,使用自定义 Partition 后,各 Task 所处理的数据集大小相当。
总结:
方案适用场景:大量不同的 Key 被分配到了相同的 Task 造成该 Task 数据量过大。
解决方案:使用自定义的 Partitioner 实现类代替默认的 HashPartitioner,尽量将所有不同的 Key 均匀分配到不同的 Task 中。
方案优点:不影响原有的并行度设计。如果改变并行度,后续 Stage 的并行度也会默认改变,可能会影响后续 Stage。
方案缺点:适用场景有限,只能将不同 Key 分散开,对于同一 Key 对应数据集非常大的场景不适用。效果与调整并行度类似,只能缓解数据倾斜而不能完全消除数据倾斜。而且需要根据数据特点自定义专用的 Partitioner,不够灵活。
4、将 Reduce side Join 转变为 Map side Join
方案适用场景:在对 RDD 使用 join 类操作,或者是在 Spark SQL 中使用 join 语句时,而且 join 操作中的一个 RDD 或表的数据量比较小(比如几百M 或者一两 G),比较适用此方案。
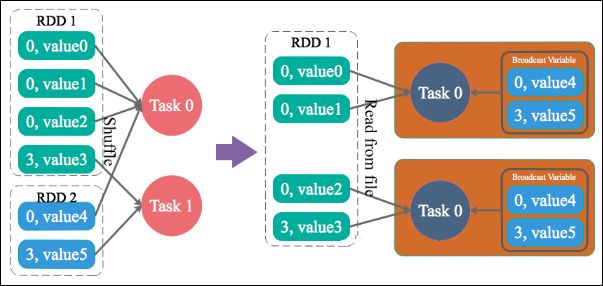
方案实现思路:不使用 join 算子进行连接操作,而使用 Broadcast 变量与 map 类算子实现 join 操作,进而完全规避掉 shuffle 类的操作,彻底避免数据倾斜的发生和出现。将较小 RDD 中的数据直接通过 collect 算子拉取到 Driver 端的内存中来,然后对其创建一个 Broadcast 变量;接着对另外一个 RDD 执行 map 类算子,在算子函数内,从 Broadcast 变量中获取较小 RDD 的全量数据,与当前 RDD 的每一条数据按照连接 key 进行比对,如果连接 key 相同的话,那么就将两个 RDD 的数据用你需要的方式连接起来。
方案实现原理:普通的 join 是会走 shuffle 过程的,而一旦 shuffle,就相当于会将相同 key 的数据拉取到一个 shuffle read task 中再进行 join,此时就是 reduce join。但是如果一个 RDD 是比较小的,则可以采用广播小 RDD 全量数据 +map 算子来实现与 join 同样的效果,也就是 map join,此时就不会发生 shuffle 操作,也就不会发生数据倾斜。具体原理如下图所示。
方案优点:对 join 操作导致的数据倾斜,效果非常好,因为根本就不会发生 shuffle,也就根本不会发生数据倾斜。
方案缺点:适用场景较少,因为这个方案只适用于一个大表和一个小表的情况。毕竟我们需要将小表进行广播,此时会比较消耗内存资源,Driver 和每个 Executor 内存中都会驻留一份小 RDD 的全量数据。如果我们广播出去的 RDD 数据比较大,比如 10G 以上,那么就可能发生内存溢出了。因此并不适合两个都是大表的情况。
通过 Spark 的 Broadcast 机制,将 Reduce 侧 Join 转化为 Map 侧 Join,避免 Shuffle 从而完全消除 Shuffle 带来的数据倾斜。
案例1:
Step1:准备数据
scala> val sourceRdd = sc.textFile("hdfs://hadoop102:9000/source_index/p*")
scala> val kvRdd = sourceRdd.map(x => { val parm = x.split("\t"); (parm(0).trim().toInt, x) } )
scala> kvRdd.first
res6: (Int, String) = (0,0 20111230000005 57375476989eea12893c0c3811607bcf 奇艺高清 1 1 http://www.qiyi.com/)
scala> val kvRdd2 = kvRdd.map(x => { if(x._1 < 900001) (900001, x._2) else x } )
scala> kvRdd2.first
res7: (Int, String) = (900001,0 20111230000005 57375476989eea12893c0c3811607bcf 奇艺高清 1 1 http://www.qiyi.com/)
scala> kvRdd2.map(x => x._1 + "," + x._2).saveAsTextFile("hdfs://hadoop102:9000/big_data/")
scala> val joinRdd2 = kvRdd.filter(_._1 > 900000)
scala> joinRdd2.first
res9: (Int, String) = (900001,900001 20111230093140 5d880d73e96fc08b294999ef87b778ab 凰图腾 4 1 http://www.youku.com/show_page/id_z85090998867b11e0a046.html)
scala> joinRdd2.map(x => x._1 + "," + x._2).saveAsTextFile("hdfs://hadoop102:9000/small_data/")
Step2:测试与修正
scala> val sourceRdd = sc.textFile("hdfs://hadoop102:9000/big_data/p*")
scala> val sourceRdd2 = sc.textFile("hdfs://hadoop102:9000/small_data/p*")
scala> val joinRdd = sourceRdd.map(x => { val parm = x.split(","); (parm(0).trim().toInt, parm(1).trim) })
scala> val joinRdd2 = sourceRdd2.map(x => { val parm = x.split(","); (parm(0).trim().toInt, parm(1).trim) })
scala> joinRdd.join(joinRdd2).count
通过如下 DAG 图可见,直接通过将 joinRdd(大数据集)和 joinRdd2(小数据集)进行 join 计算,如下:
从下图可见,出现数据倾斜

通过广播变量修正后:
scala> val sourceRdd = sc.textFile("hdfs://hadoop102:9000/big_data/p*")
scala> val sourceRdd2 = sc.textFile("hdfs://hadoop102:9000/small_data/p*")
scala> val joinRdd = sourceRdd.map(x => { val parm = x.split(","); (parm(0).trim().toInt, parm(1).trim) })
scala> val joinRdd2 = sourceRdd2.map(x => { val parm = x.split(","); (parm(0).trim().toInt, parm(1).trim) })
scala> val broadcastVar = sc.broadcast(joinRdd2.collectAsMap) #把分散的 RDD 转换为 Scala 的集合类型
scala> joinRdd.map(x => (x._1, (x._2, broadcastVar.value.getOrElse(x._1, "")))).count
通过如下 DAG 图可见,通过广播变量 + Map 完成了相同的工作(没有发生 shuffle):
从下图可见,没有出现数据倾斜

案例2:
Step1:通过如下 SQL 创建一张具有倾斜 Key 且总记录数为 1.5 亿的大表 test。
INSERT OVERWRITE TABLE test
SELECT CAST(CASE WHEN id < 980000000 THEN (95000000 + (CAST (RAND() * 4 AS INT) + 1) * 48 )
ELSE CAST(id/10 AS INT) END AS STRING),
name
FROM student_external
WHERE id BETWEEN 900000000 AND 1050000000;
使用如下 SQL 创建一张数据分布均匀且总记录数为 50 万的小表 test_new。
INSERT OVERWRITE TABLE test_new
SELECT CAST(CAST(id/10 AS INT) AS STRING),
name
FROM student_delta_external
WHERE id BETWEEN 950000000 AND 950500000;
Step2:直接通过 Spark Thrift Server 提交如下 SQL 将表 test 与表 test_new 进行 Join 并将 Join 结果存于表 test_join 中。
INSERT OVERWRITE TABLE test_join
SELECT test_new.id, test_new.name
FROM test
JOIN test_new
ON test.id = test_new.id;
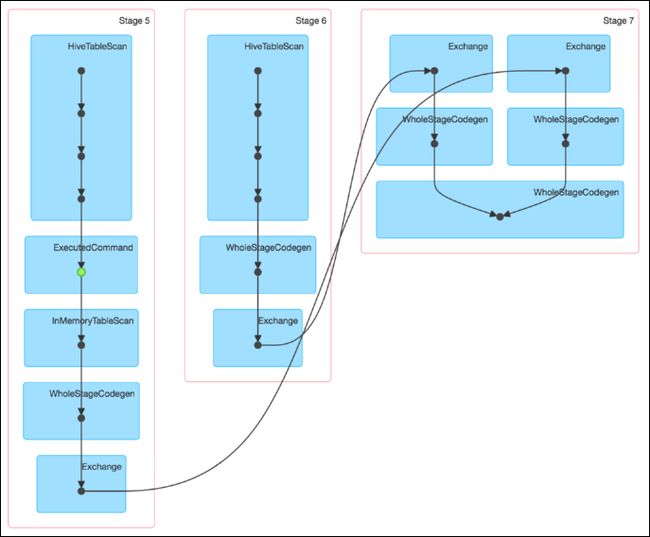
该 SQL 对应的 DAG 如下图所示。从该图可见,该执行过程总共分为三个 Stage,前两个用于从 Hive 中读取数据,同时二者进行 Shuffle,通过最后一个 Stage 进行 Join 并将结果写入表 test_join 中。
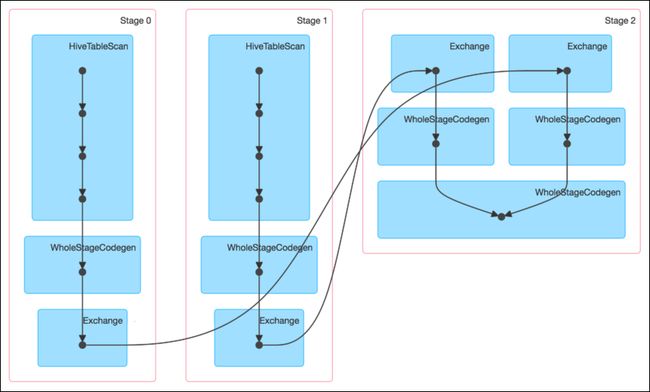
从下图可见,最近 Join Stage 各 Task 处理的数据倾斜严重,处理数据量最大的 Task 耗时 7.1 分钟,远高于其它无数据倾斜的 Task 约 2s 秒的耗时。
[外链图片转存失败(img-H3Dq4XnX-1562758075580)(https://s2.ax1x.com/2019/05/04/EamaKs.png)]
Step3:接下来,尝试通过 Broadcast 实现 Map 侧 Join,实现 Map 侧 Join 的方法,并非直接通过 CACHE TABLE test_new 将小表 test_new 进行 cache。现通过如下 SQL 进行 Join。
CACHE TABLE test_new;
INSERT OVERWRITE TABLE test_join
SELECT test_new.id, test_new.name
FROM test
JOIN test_new
ON test.id = test_new.id;
通过如下 DAG 图可见,该操作仍分为三个 Stage,且仍然有 Shuffle 存在,唯一不同的是,小表的读取不再直接扫描 Hive 表,而是扫描内存中缓存的表。
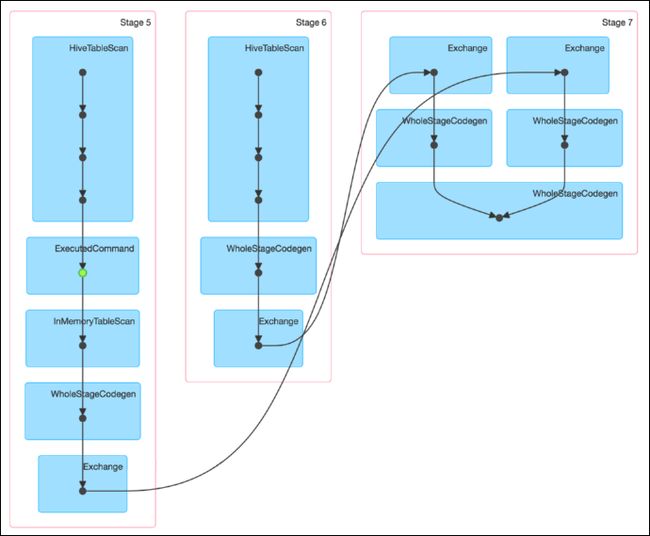
并且数据倾斜仍然存在。如下图所示,最慢的 Task 耗时为7.1分钟,远高于其它 Task 的约 2 秒。

Step4:正确的使用 Broadcast 实现 Map 侧 Join 的方式是,通过 SET spark.sql.autoBroadcastJoinThreshold=104857600;将 Broadcast 的阈值设置得足够大。
再次通过如下 SQL 进行 Join。
SET spark.sql.autoBroadcastJoinThreshold=104857600;
INSERT OVERWRITE TABLE test_join
SELECT test_new.id, test_new.name
FROM test
JOIN test_new
ON test.id = test_new.id;
通过如下 DAG 图可见,该方案只包含一个 Stage。
并且从下图可见,各 Task 耗时相当,无明显数据倾斜现象。并且总耗时为 1.5 分钟,远低于 Reduce 侧 Join 的 7.3 分钟。
总结:
方案适用场景:参与 Join 的一边数据集足够小,可被加载进 Driver 并通过 Broadcast 方法广播到各个 Executor 中。
方案优点:避免了 Shuffle,彻底消除了数据倾斜产生的条件,可极大提升性能。
方案缺点:要求参与 Join 的一侧数据集足够小,并且主要适用于 Join 的场景,不适合聚合的场景,适用条件有限。
5、两阶段聚合(局部聚合+全局聚合)
方案适用场景:对 RDD 执行 reduceByKey 等聚合类 shuffle 算子或者在 Spark SQL 中使用 group by 语句进行分组聚合时,比较适用这种方案。
方案实现思路:这个方案的核心实现思路就是进行两阶段聚合。第一次是局部聚合,先给每个 key 都打上一个随机数,比如 10 以内的随机数,此时原先一样的 key 就变成不一样的了,比如 (hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成 (1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着对打上随机数后的数据,执行 reduceByKey 等聚合操作,进行局部聚合,那么局部聚合结果,就会变成了 (1_hello, 2) (2_hello, 2)。然后将各个 key 的前缀给去掉,就会变成 (hello,2)(hello,2),再次进行全局聚合操作,就可以得到最终结果了,比如 (hello, 4)。
方案实现原理:将原本相同的 key 通过附加随机前缀的方式,变成多个不同的 key,就可以让原本被一个 task 处理的数据分散到多个 task 上去做局部聚合,进而解决单个 task 处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。具体原理见下图。
方案优点:对于聚合类的 shuffle 操作导致的数据倾斜,效果是非常不错的。通常都可以解决掉数据倾斜,或者至少是大幅度缓解数据倾斜,将 Spark 作业的性能提升数倍以上。
方案缺点:仅仅适用于聚合类的 shuffle 操作,适用范围相对较窄。如果是 join 类的 shuffle 操作,还得用其他的解决方案。
[外链图片转存失败(img-A3dk8m17-1562758075582)(https://s2.ax1x.com/2019/05/04/EamBV0.png)]
// 第一步,给 RDD 中的每个 key 都打上一个随机前缀。
JavaPairRDD<String, Long> randomPrefixRdd = rdd.mapToPair(
new PairFunction<Tuple2<Long,Long>, String, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Long> call(Tuple2<Long, Long> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(10);
return new Tuple2<String, Long>(prefix + "_" + tuple._1, tuple._2);
}
});
// 第二步,对打上随机前缀的 key 进行局部聚合。
JavaPairRDD<String, Long> localAggrRdd = randomPrefixRdd.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
// 第三步,去除 RDD 中每个 key 的随机前缀。
JavaPairRDD<Long, Long> removedRandomPrefixRdd = localAggrRdd.mapToPair(
new PairFunction<Tuple2<String,Long>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<String, Long> tuple)
throws Exception {
long originalKey = Long.valueOf(tuple._1.split("_")[1]);
return new Tuple2<Long, Long>(originalKey, tuple._2);
}
});
// 第四步,对去除了随机前缀的 RDD 进行全局聚合。
JavaPairRDD<Long, Long> globalAggrRdd = removedRandomPrefixRdd.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
案例:
scala> val sourceRdd = sc.textFile("hdfs://hadoop102:9000/source_index/p*", 13)
scala> val kvRdd = sourceRdd.map(x => { val parm = x.split("\t"); (parm(0).trim().toInt, parm(4).trim().toInt) })
scala> val kvRdd2 = kvRdd.map(x=> { if (x._1 > 20000) (20001, x._2) else x })
scala> kvRdd2.groupByKey().count
直接 groupByKey 数据倾斜,查看 DAG 图 如下:
查看各个任务的运行时间:
通过广播变量修正后:
scala> val kvRdd3 = kvRdd2.map(x => {if (x._1 == 20001) (x._1 + scala.util.Random.nextInt(100), x._2) else x })
scala> kvRdd3.groupByKey().count
查看 DAG 图 如下:
查看各个任务的运行时间:
发现时间都比较均匀,没有出现数据倾斜
6、为倾斜的 key 增加随机前/后缀
方案原理:为数据量特别大的 Key 增加随机前/后缀,使得原来 Key 相同的数据变为 Key 不相同的数据,从而使倾斜的数据集分散到不同的 Task 中,彻底解决数据倾斜问题。Join 另一侧的数据中,与倾斜 Key 对应的部分数据,与随机前缀集作笛卡尔乘积,从而保证无论数据倾斜侧倾斜 Key 如何加前缀,都能与之正常 Join。
案例:
通过如下 SQL,将 id 为 9 亿到 9.08 亿共 800 万条数据的 id 转为 9500048 或者 9500096,其它数据的 id 除以 100 取整。从而该数据集中,id 为 9500048 和 9500096 的数据各 400 万,其它 id 对应的数据记录数均为 100 条。这些数据存于名为 test 的表中。
对于另外一张小表 test_new,取出 50 万条数据,并将 id(递增且唯一)除以 100 取整,使得所有 id 都对应 100 条数据。
NSERT OVERWRITE TABLE test
SELECT CAST(CASE WHEN id < 908000000 THEN (9500000 + (CAST (RAND() * 2 AS INT) + 1) * 48 )
ELSE CAST(id/100 AS INT) END AS STRING),
name
FROM student_external
WHERE id BETWEEN 900000000 AND 1050000000;
INSERT OVERWRITE TABLE test_new
SELECT CAST(CAST(id/100 AS INT) AS STRING),
name
FROM student_delta_external
WHERE id BETWEEN 950000000 AND 950500000;
通过如下代码,读取 test 表对应的文件夹内的数据并转换为 JavaPairRDD 存于 leftRDD 中,同样读取 test 表对应的数据存于 rightRDD 中。通过 RDD 的 join 算子对 leftRDD 与 rightRDD 进行 Join,并指定并行度为 48。
public class SparkDataSkew{
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("DemoSparkDataFrameWithSkewedBigTableDirect");
sparkConf.set("spark.default.parallelism", parallelism + "");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaPairRDD<String, String> leftRDD = javaSparkContext.textFile("hdfs://hadoop102:9000/apps/hive/warehouse/default/test/")
.mapToPair((String row) -> {
String[] str = row.split(",");
return new Tuple2<String, String>(str[0], str[1]);
});
JavaPairRDD<String, String> rightRDD = javaSparkContext.textFile("hdfs://hadoop102:9000/apps/hive/warehouse/default/test_new/")
.mapToPair((String row) -> {
String[] str = row.split(",");
return new Tuple2<String, String>(str[0], str[1]);
});
leftRDD.join(rightRDD, parallelism)
.mapToPair((Tuple2<String, Tuple2<String, String>> tuple) -> new Tuple2<String, String>(tuple._1(), tuple._2()._2()))
.foreachPartition((Iterator<Tuple2<String, String>> iterator) -> {
AtomicInteger atomicInteger = new AtomicInteger();
iterator.forEachRemaining((Tuple2<String, String> tuple) -> atomicInteger.incrementAndGet());
});
javaSparkContext.stop();
javaSparkContext.close();
}
}
从下图可看出,整个 Join 耗时 1 分 54 秒,其中 Join Stage 耗时 1.7 分钟。

通过分析 Join Stage 的所有 Task 可知,在其它 Task 所处理记录数为 192.71 万的同时 Task 32 的处理的记录数为 992.72 万,故它耗时为 1.7 分钟,远高于其它 Task 的约 10 秒。这与上文准备数据集时,将 id 为 9500048 为 9500096 对应的数据量设置非常大,其它 id 对应的数据集非常均匀相符合。
现通过如下操作,实现倾斜 Key 的分散处理:
将 leftRDD 中倾斜的 key(即 9500048 与 9500096)对应的数据单独过滤出来,且加上 1 到 24 的随机前缀,并将前缀与原数据用逗号分隔(以方便之后去掉前缀)形成单独的 leftSkewRDD。
将 rightRDD 中倾斜 key 对应的数据抽取出来,并通过 flatMap 操作将该数据集中每条数据均转换为 24 条数据(每条分别加上 1 到 24 的随机前缀),形成单独的 rightSkewRDD。
将 leftSkewRDD 与 rightSkewRDD 进行 Join,并将并行度设置为 48,且在 Join 过程中将随机前缀去掉,得到倾斜数据集的 Join 结果 skewedJoinRDD。
将 leftRDD 中不包含倾斜 Key 的数据抽取出来作为单独的 leftUnSkewRDD。
对 leftUnSkewRDD 与原始的 rightRDD进行Join,并行度也设置为 48,得到 Join 结果 unskewedJoinRDD。
通过 union 算子将 skewedJoinRDD 与 unskewedJoinRDD 进行合并,从而得到完整的 Join 结果集。
具体实现代码如下:
public class SparkDataSkew{
public static void main(String[] args) {
int parallelism = 48;
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("SolveDataSkewWithRandomPrefix");
sparkConf.set("spark.default.parallelism", parallelism + "");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaPairRDD<String, String> leftRDD = javaSparkContext.textFile("hdfs://hadoop102:9000/apps/hive/warehouse/default/test/")
.mapToPair((String row) -> {
String[] str = row.split(",");
return new Tuple2<String, String>(str[0], str[1]);
});
JavaPairRDD<String, String> rightRDD = javaSparkContext.textFile("hdfs://hadoop102:9000/apps/hive/warehouse/default/test_new/")
.mapToPair((String row) -> {
String[] str = row.split(",");
return new Tuple2<String, String>(str[0], str[1]);
});
String[] skewedKeyArray = new String[]{"9500048", "9500096"};
Set<String> skewedKeySet = new HashSet<String>();
List<String> addList = new ArrayList<String>();
for(int i = 1; i <=24; i++) {
addList.add(i + "");
}
for(String key : skewedKeyArray) {
skewedKeySet.add(key);
}
Broadcast<Set<String>> skewedKeys = javaSparkContext.broadcast(skewedKeySet);
Broadcast<List<String>> addListKeys = javaSparkContext.broadcast(addList);
JavaPairRDD<String, String> leftSkewRDD = leftRDD
.filter((Tuple2<String, String> tuple) -> skewedKeys.value().contains(tuple._1()))
.mapToPair((Tuple2<String, String> tuple) -> new Tuple2<String, String>((new Random().nextInt(24) + 1) + "," + tuple._1(), tuple._2()));
JavaPairRDD<String, String> rightSkewRDD = rightRDD.filter((Tuple2<String, String> tuple) -> skewedKeys.value().contains(tuple._1()))
.flatMapToPair((Tuple2<String, String> tuple) -> addListKeys.value().stream()
.map((String i) -> new Tuple2<String, String>( i + "," + tuple._1(), tuple._2()))
.collect(Collectors.toList())
.iterator()
);
JavaPairRDD<String, String> skewedJoinRDD = leftSkewRDD
.join(rightSkewRDD, parallelism)
.mapToPair((Tuple2<String, Tuple2<String, String>> tuple) -> new Tuple2<String, String>(tuple._1().split(",")[1], tuple._2()._2()));
JavaPairRDD<String, String> leftUnSkewRDD = leftRDD.filter((Tuple2<String, String> tuple) -> !skewedKeys.value().contains(tuple._1()));
JavaPairRDD<String, String> unskewedJoinRDD = leftUnSkewRDD.join(rightRDD, parallelism).mapToPair((Tuple2<String, Tuple2<String, String>> tuple) -> new Tuple2<String, String>(tuple._1(), tuple._2()._2()));
skewedJoinRDD.union(unskewedJoinRDD).foreachPartition((Iterator<Tuple2<String, String>> iterator) -> {
AtomicInteger atomicInteger = new AtomicInteger();
iterator.forEachRemaining((Tuple2<String, String> tuple) -> atomicInteger.incrementAndGet());
});
javaSparkContext.stop();
javaSparkContext.close();
}
}
从下图可看出,整个 Join 耗时 58 秒,其中 Join Stage 耗时 33 秒。

通过分析 Join Stage 的所有 Task 可知:
由于 Join 分倾斜数据集 Join 和非倾斜数据集 Join,而各 Join 的并行度均为 48,故总的并行度为 96。
由于提交任务时,设置的 Executor 个数为 4,每个 Executor 的 core 数为 12,故可用 Core 数为 48,所以前 48 个 Task 同时启动(其 Launch 时间相同),后 48 个 Task 的启动时间各不相同(等待前面的 Task 结束才开始)。
由于倾斜 Key 被加上随机前缀,原本相同的 Key 变为不同的 Key,被分散到不同的 Task 处理,故在所有 Task 中,未发现所处理数据集明显高于其它 Task 的情况。
实际上,由于倾斜 Key 与非倾斜 Key 的操作完全独立,可并行进行。而本实验受限于可用总核数为 48,可同时运行的总 Task 数为 48,故而该方案只是将总耗时减少一半(效率提升一倍)。如果资源充足,可并发执行 Task 数增多,该方案的优点将更为明显。在实际项目中,该方案往往可提升数倍至 10 倍的效率。
总结:
方案适用场景:两张表都比较大,无法使用 Map 侧 Join。其中一个 RDD 有少数几个 Key 的数据量过大,另外一个 RDD 的 Key 分布较为均匀。
方案解决方案:将有数据倾斜的 RDD 中倾斜 Key 对应的数据集单独抽取出来加上随机前缀,另外一个 RDD 每条数据分别与随机前缀结合形成新的 RDD(相当于将其数据增到到原来的 N 倍,N 即为随机前缀的总个数),然后将二者 Join 并去掉前缀。然后将不包含倾斜 Key 的剩余数据进行 Join。最后将两次 Join 的结果集通过 union 合并,即可得到全部 Join 结果。
方案优点:相对于 Map 侧 Join,更能适应大数据集的 Join。如果资源充足,倾斜部分数据集与非倾斜部分数据集可并行进行,效率提升明显。且只针对倾斜部分的数据做数据扩展,增加的资源消耗有限。
方案缺点:如果倾斜 Key 非常多,则另一侧数据膨胀非常大,此方案不适用。而且此时对倾斜 Key 与非倾斜 Key 分开处理,需要扫描数据集两遍,增加了开销。
7、使用随机前缀和扩容 RDD 进行 join
方案适用场景:如果在进行 join 操作时,RDD 中有大量的 key 导致数据倾斜,那么进行分拆 key 也没什么意义,此时就只能使用最后一种方案来解决问题了。
方案实现思路:该方案的实现思路基本和 “解决方案6” 类似,首先查看 RDD/Hive 表中的数据分布情况,找到那个造成数据倾斜的 RDD/Hive 表,比如有多个 key 都对应了超过 1 万条数据。
然后将该 RDD 的每条数据都打上一个 n 以内的随机前缀。
同时对另外一个正常的 RDD 进行扩容,将每条数据都扩容成 n 条数据,扩容出来的每条数据都依次打上一个 0~n 的前缀。
最后将两个处理后的 RDD 进行 join 即可。
方案实现原理:将原先一样的 key 通过附加随机前缀变成不一样的 key,然后就可以将这些处理后的 “不同key” 分散到多个 task 中去处理,而不是让一个 task 处理大量的相同 key。该方案与 “解决方案6” 的不同之处就在于,上一种方案是尽量只对少数倾斜 key 对应的数据进行特殊处理,由于处理过程需要扩容 RDD,因此上一种方案扩容 RDD 后对内存的占用并不大;而这一种方案是针对有大量倾斜 key 的情况,没法将部分 key 拆分出来进行单独处理,因此只能对整个 RDD 进行数据扩容,对内存资源要求很高。
方案优点:对 join 类型的数据倾斜基本都可以处理,而且效果也相对比较显著,性能提升效果非常不错。
方案缺点:该方案更多的是缓解数据倾斜,而不是彻底避免数据倾斜。而且需要对整个 RDD 进行扩容,对内存资源要求很高。
方案实践经验:曾经开发一个数据需求的时候,发现一个 join 导致了数据倾斜。优化之前,作业的执行时间大约是 60 分钟左右;使用该方案优化之后,执行时间缩短到 10 分钟左右,性能提升了 6 倍。
// 首先将其中一个 key 分布相对较为均匀的 RDD 膨胀 100 倍。
JavaPairRDD<String, Row> expandedRDD = rdd1.flatMapToPair(
new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<Tuple2<String, Row>> call(Tuple2<Long, Row> tuple)
throws Exception {
List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>();
for(int i = 0; i < 100; i++) {
list.add(new Tuple2<String, Row>(0 + "_" + tuple._1, tuple._2));
}
return list;
}
});
// 其次,将另一个有数据倾斜 key 的 RDD,每条数据都打上 100 以内的随机前缀。
JavaPairRDD<String, String> mappedRDD = rdd2.mapToPair(
new PairFunction<Tuple2<Long,String>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(Tuple2<Long, String> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(100);
return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2);
}
});
// 将两个处理后的 RDD 进行 join 即可。
JavaPairRDD<String, Tuple2<String, Row>> joinedRDD = mappedRDD.join(expandedRDD);
8、大表随机添加 N 种随机前缀,小表扩大 N 倍
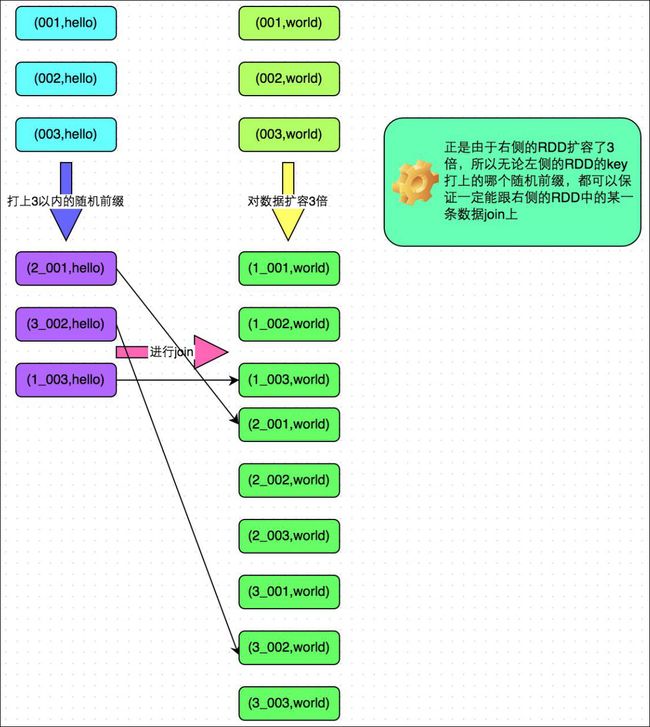
方案原理:如果出现数据倾斜的 Key 比较多,上一种方法将这些大量的倾斜 Key 分拆出来,意义不大。此时更适合直接对存在数据倾斜的数据集全部加上随机前缀,然后对另外一个不存在严重数据倾斜的数据集整体与随机前缀集作笛卡尔乘积(即将数据量扩大 N 倍)。
案例:
这里给出示例代码,读者可参考上文中分拆出少数倾斜 Key 添加随机前缀的方法,自行测试。
public class SparkDataSkew {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("ResolveDataSkewWithNAndRandom");
sparkConf.set("spark.default.parallelism", parallelism + "");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaPairRDD<String, String> leftRDD = javaSparkContext.textFile("hdfs://hadoop102:9000/apps/hive/warehouse/default/test/")
.mapToPair((String row) -> {
String[] str = row.split(",");
return new Tuple2<String, String>(str[0], str[1]);
});
JavaPairRDD<String, String> rightRDD = javaSparkContext.textFile("hdfs://hadoop102:9000/apps/hive/warehouse/default/test_new/")
.mapToPair((String row) -> {
String[] str = row.split(",");
return new Tuple2<String, String>(str[0], str[1]);
});
List<String> addList = new ArrayList<String>();
for(int i = 1; i <=48; i++) {
addList.add(i + "");
}
Broadcast<List<String>> addListKeys = javaSparkContext.broadcast(addList);
JavaPairRDD<String, String> leftRandomRDD = leftRDD.mapToPair((Tuple2<String, String> tuple) -> new Tuple2<String, String>(new Random().nextInt(48) + "," + tuple._1(), tuple._2()));
JavaPairRDD<String, String> rightNewRDD = rightRDD
.flatMapToPair((Tuple2<String, String> tuple) -> addListKeys.value().stream()
.map((String i) -> new Tuple2<String, String>( i + "," + tuple._1(), tuple._2()))
.collect(Collectors.toList())
.iterator()
);
JavaPairRDD<String, String> joinRDD = leftRandomRDD
.join(rightNewRDD, parallelism)
.mapToPair((Tuple2<String, Tuple2<String, String>> tuple) -> new Tuple2<String, String>(tuple._1().split(",")[1], tuple._2()._2()));
joinRDD.foreachPartition((Iterator<Tuple2<String, String>> iterator) -> {
AtomicInteger atomicInteger = new AtomicInteger();
iterator.forEachRemaining((Tuple2<String, String> tuple) -> atomicInteger.incrementAndGet());
});
javaSparkContext.stop();
javaSparkContext.close();
}
}
总结:
方案适用场景:一个数据集存在的倾斜 Key 比较多,另外一个数据集数据分布比较均匀。
方案优点:对大部分场景都适用,效果不错。
方案缺点:需要将一个数据集整体扩大 N 倍,会增加资源消耗。
方案总结:对于数据倾斜,并无一个统一的一劳永逸的方法。更多的时候,是结合数据特点(数据集大小,倾斜 Key 的多少等)综合使用上文所述的多种方法。
9、采样倾斜 key 并分拆 join 操作
方案适用场景:两个 RDD/Hive 表进行 join 的时候,如果数据量都比较大,无法采用 “解决方案5”,那么此时可以看一下两个 RDD/Hive 表中的 key 分布情况。如果出现数据倾斜,是因为其中某一个 RDD/Hive 表中的少数几个 key 的数据量过大,而另一个 RDD/Hive 表中的所有 key 都分布比较均匀,那么采用这个解决方案是比较合适的。
方案实现思路:对包含少数几个数据量过大的 key 的那个 RDD,通过 sample 算子采样出一份样本来,然后统计一下每个 key 的数量,计算出来数据量最大的是哪几个 key。
然后将这几个 key 对应的数据从原来的 RDD 中拆分出来,形成一个单独的 RDD,并给每个 key 都打上 n 以内的随机数作为前缀,而不会导致倾斜的大部分 key 形成另外一个 RDD。
接着将需要 join 的另一个 RDD,也过滤出来那几个倾斜 key 对应的数据并形成一个单独的 RDD,将每条数据膨胀成 n 条数据,这 n 条数据都按顺序附加一个 0~n 的前缀,不会导致倾斜的大部分 key 也形成另外一个 RDD。
再将附加了随机前缀的独立 RDD 与另一个膨胀 n 倍的独立 RDD 进行 join,此时就可以将原先相同的 key 打散成 n 份,分散到多个 task 中去进行 join 了。
而另外两个普通的 RDD 就照常 join 即可。
最后将两次 join 的结果使用 union 算子合并起来即可,就是最终的 join 结果。
方案实现原理:对于 join 导致的数据倾斜,如果只是某几个 key 导致了倾斜,可以将少数几个 key 分拆成独立 RDD,并附加随机前缀打散成 n 份去进行 join,此时这几个 key 对应的数据就不会集中在少数几个 task 上,而是分散到多个 task 进行 join 了。具体原理见下图。
方案优点:对于 join 导致的数据倾斜,如果只是某几个 key 导致了倾斜,采用该方式可以用最有效的方式打散 key 进行 join。而且只需要针对少数倾斜 key 对应的数据进行扩容 n 倍,不需要对全量数据进行扩容。避免了占用过多内存。
方案缺点:如果导致倾斜的 key 特别多的话,比如成千上万个 key 都导致数据倾斜,那么这种方式也不适合。
// 首先从包含了少数几个导致数据倾斜 key 的 rdd1 中,采样 10% 的样本数据。
JavaPairRDD<Long, String> sampledRDD = rdd1.sample(false, 0.1);
// 对样本数据 RDD 统计出每个 key 的出现次数,并按出现次数降序排序。
// 对降序排序后的数据,取出 top 1 或者 top 100 的数据,也就是 key 最多的前 n 个数据。
// 具体取出多少个数据量最多的 key,由大家自己决定,我们这里就取 1 个作为示范。
JavaPairRDD<Long, Long> mappedSampledRDD = sampledRDD.mapToPair(
new PairFunction<Tuple2<Long,String>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<Long, String> tuple)
throws Exception {
return new Tuple2<Long, Long>(tuple._1, 1L);
}
});
JavaPairRDD<Long, Long> countedSampledRDD = mappedSampledRDD.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
JavaPairRDD<Long, Long> reversedSampledRDD = countedSampledRDD.mapToPair(
new PairFunction<Tuple2<Long,Long>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<Long, Long> tuple)
throws Exception {
return new Tuple2<Long, Long>(tuple._2, tuple._1);
}
});
final Long skewedUserid = reversedSampledRDD.sortByKey(false).take(1).get(0)._2;
// 从 rdd1 中分拆出导致数据倾斜的 key,形成独立的 RDD。
JavaPairRDD<Long, String> skewedRDD = rdd1.filter(
new Function<Tuple2<Long,String>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, String> tuple) throws Exception {
return tuple._1.equals(skewedUserid);
}
});
// 从 rdd1 中分拆出不导致数据倾斜的普通 key,形成独立的 RDD。
JavaPairRDD<Long, String> commonRDD = rdd1.filter(
new Function<Tuple2<Long,String>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, String> tuple) throws Exception {
return !tuple._1.equals(skewedUserid);
}
});
// rdd2,就是那个所有 key 的分布相对较为均匀的 rdd。
// 这里将 rdd2 中,前面获取到的 key 对应的数据,过滤出来,分拆成单独的 rdd,并对 rdd 中的数据使用 flatMap 算子都扩容 100 倍。
// 对扩容的每条数据,都打上 0~100 的前缀。
JavaPairRDD<String, Row> skewedRdd2 = rdd2.filter(
new Function<Tuple2<Long,Row>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, Row> tuple) throws Exception {
return tuple._1.equals(skewedUserid);
}
}).flatMapToPair(new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<Tuple2<String, Row>> call(
Tuple2<Long, Row> tuple) throws Exception {
Random random = new Random();
List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>();
for(int i = 0; i < 100; i++) {
list.add(new Tuple2<String, Row>(i + "_" + tuple._1, tuple._2));
}
return list;
}
});
// 将 rdd1 中分拆出来的导致倾斜的 key 的独立 rdd,每条数据都打上 100 以内的随机前缀。
// 然后将这个 rdd1 中分拆出来的独立 rdd,与上面 rdd2 中分拆出来的独立 rdd,进行 join。
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD1 = skewedRDD.mapToPair(
new PairFunction<Tuple2<Long,String>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(Tuple2<Long, String> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(100);
return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2);
}
})
.join(skewedUserid2infoRDD)
.mapToPair(new PairFunction<Tuple2<String,Tuple2<String,Row>>, Long, Tuple2<String, Row>>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Tuple2<String, Row>> call(
Tuple2<String, Tuple2<String, Row>> tuple)
throws Exception {
long key = Long.valueOf(tuple._1.split("_")[1]);
return new Tuple2<Long, Tuple2<String, Row>>(key, tuple._2);
}
});
// 将 rdd1 中分拆出来的包含普通 key 的独立 rdd,直接与 rdd2 进行 join。
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD2 = commonRDD.join(rdd2);
// 将倾斜 key join 后的结果与普通 key join 后的结果,uinon 起来。
// 就是最终的 join 结果。
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD = joinedRDD1.union(joinedRDD2);
10、过滤少数导致倾斜的 key
方案适用场景:如果发现导致倾斜的 key 就少数几个,而且对计算本身的影响并不大的话,那么很适合使用这种方案。比如 99% 的 key 就对应 10 条数据,但是只有一个 key 对应了 100 万数据,从而导致了数据倾斜。
方案实现思路:如果我们判断那少数几个数据量特别多的 key,对作业的执行和计算结果不是特别重要的话,那么干脆就直接过滤掉那少数几个 key。比如,在 Spark SQL 中可以使用 where 子句过滤掉这些 key 或者在 Spark Core 中对 RDD 执行 filter 算子过滤掉这些 key。如果需要每次作业执行时,动态判定哪些 key 的数据量最多然后再进行过滤,那么可以使用 sample 算子对 RDD 进行采样,然后计算出每个 key 的数量,取数据量最多的 key 过滤掉即可。
方案实现原理:将导致数据倾斜的 key 给过滤掉之后,这些 key 就不会参与计算了,自然不可能产生数据倾斜。
方案优点:实现简单,而且效果也很好,可以完全规避掉数据倾斜。
方案缺点:适用场景不多,大多数情况下,导致倾斜的 key 还是很多的,并不是只有少数几个。
方案实践经验:在项目中我们也采用过这种方案解决数据倾斜。有一次发现某一天 Spark 作业在运行的时候突然 OOM 了,追查之后发现,是 Hive 表中的某一个 key 在那天数据异常,导致数据量暴增。因此就采取每次执行前先进行采样,计算出样本中数据量最大的几个 key 之后,直接在程序中将那些 key 给过滤掉。
1.3 运行资源调优
1.3.1 运行资源调优概述
在开发完 Spark 作业之后,就该为作业配置合适的资源了。Spark 的资源参数,基本都可以在 spark-submit 命令中作为参数设置。很多 Spark 初学者,通常不知道该设置哪些必要的参数,以及如何设置这些参数,最后就只能胡乱设置,甚至压根儿不设置。资源参数设置的不合理,可能会导致没有充分利用集群资源,作业运行会极其缓慢;或者设置的资源过大,队列没有足够的资源来提供,进而导致各种异常。
总之,无论是哪种情况,都会导致 Spark 作业的运行效率低下,甚至根本无法运行。因此我们必须对 Spark 作业的资源使用原理有一个清晰的认识,并知道在 Spark 作业运行过程中,有哪些资源参数是可以设置的,以及如何设置合适的参数值。
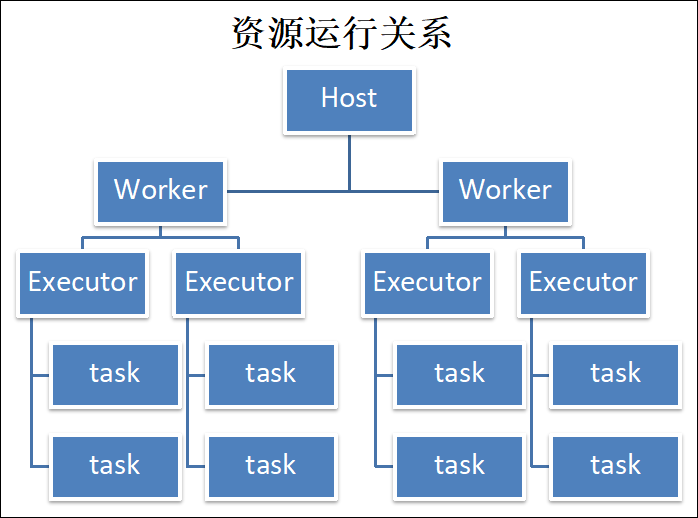
1.3.2 Spark 作业基本运行原理
详细原理见上图。我们使用 spark-submit 提交一个 Spark 作业之后,这个作业就会启动一个对应的 Driver 进程。根据你使用的部署模式(deploy-mode)不同,Driver 进程可能在本地启动,也可能在集群中某个工作节点上启动。Driver 进程本身会根据我们设置的参数,占有一定数量的内存和 CPU core。而 Driver 进程要做的第一件事情,就是向集群管理器(可以是 Spark Standalone 集群,也可以是其他的资源管理集群,美团-大众点评使用的是 YARN 作为资源管理集群)申请运行 Spark 作业需要使用的资源,这里的资源指的就是 Executor 进程。YARN 集群管理器会根据我们为 Spark 作业设置的资源参数,在各个工作节点上,启动一定数量的 Executor 进程,每个 Executor 进程都占有一定数量的内存和 CPU core。
在申请到了作业执行所需的资源之后,Driver 进程就会开始调度和执行我们编写的作业代码了。Driver 进程会将我们编写的 Spark 作业代码分拆为多个 stage,每个 stage 执行一部分代码片段,并为每个 stage 创建一批 task,然后将这些 task 分配到各个 Executor 进程中执行。task 是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个 task 处理的数据不同而已。一个 stage 的所有 task 都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后 Driver 就会调度运行下一个 stage。下一个 stage 的 task 的输入数据就是上一个 stage 输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果为止。
Spark 是根据 shuffle 类算子来进行 stage 的划分。如果我们的代码中执行了某个 shuffle 类算子(比如 reduceByKey、join 等),那么就会在该算子处,划分出一个 stage 界限来。可以大致理解为,shuffle 算子执行之前的代码会被划分为一个 stage,shuffle 算子执行以及之后的代码会被划分为下一个 stage。因此一个 stage 刚开始执行的时候,它的每个 task 可能都会从上一个 stage 的 task 所在的节点,去通过网络传输拉取需要自己处理的所有 key,然后对拉取到的所有相同的 key 使用我们自己编写的算子函数执行聚合操作(比如 reduceByKey() 算子接收的函数)。这个过程就是 shuffle。
当我们在代码中执行了 cache/persist 等持久化操作时,根据我们选择的持久化级别的不同,每个 task 计算出来的数据也会保存到 Executor 进程的内存或者所在节点的磁盘文件中。
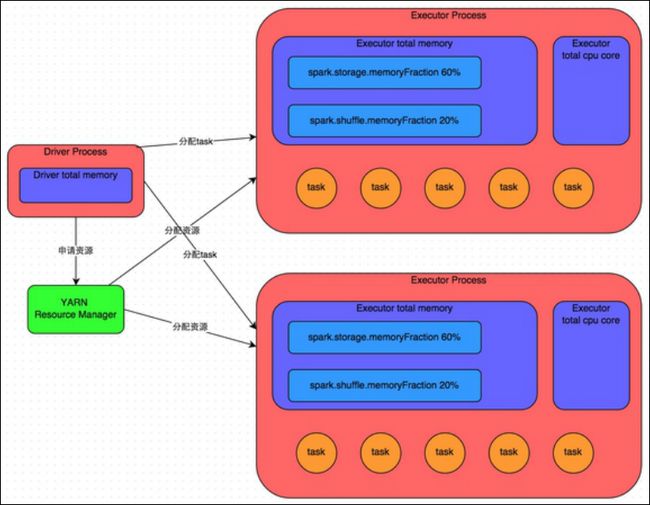
因此 Executor 的内存主要分为三块:第一块是让 task 执行我们自己编写的代码时使用,默认是占 Executor 总内存的 20%;第二块是让 task 通过 shuffle 过程拉取了上一个 stage 的 task 的输出后,进行聚合等操作时使用,默认也是占 Executor 总内存的 20%;第三块是让 RDD 持久化时使用,默认占 Executor 总内存的 60%。
task 的执行速度是跟每个 Executor 进程的 CPU core 数量有直接关系的。一个 CPU core 同一时间只能执行一个线程。而每个 Executor 进程上分配到的多个 task,都是以每个 task 一条线程的方式,多线程并发运行的。如果 CPU core 数量比较充足,而且分配到的 task 数量比较合理,那么通常来说,可以比较快速和高效地执行完这些 task 线程。
以上就是 Spark 作业的基本运行原理的说明,大家可以结合上图来理解。理解作业基本原理,是我们进行资源参数调优的基本前提。
1.3.3 运行资源中的几种情况
(1)实践中跑的 Spark job,有的特别慢,并且查看 CPU,发现 CPU 利用率很低,可以尝试减少每个 executor 占用 CPU core 的数量,增加并行的 executor 数量,同时配合增加分片,整体上增加了 CPU 的利用率,加快数据处理速度。
(2)发现某 job 很容易发生内存溢出,我们就增大分片数量,从而减少了每片数据的规模,同时可以减少并行的 executor 数量,这样相同的内存资源分配给数量更少的 executor,相当于增加了每个 task 的内存分配,这样运行速度可能慢了些,但是总比 OOM 强。
(3)数据量特别少,有大量的小文件生成,就减少文件分片,没必要创建那么多 task,这种情况,如果只是最原始的 input 比较小,一般都能被注意到;但是,如果是在运算过程中,比如应用某个 reduceBy 或者某个 filter 以后,数据大量减少,这种低效情况就很少被留意到。
1.3.4 运行资源参数调优
了解完了 Spark 作业运行的基本原理之后,对资源相关的参数就容易理解了。所谓的 Spark 资源参数调优,其实主要就是对 Spark 运行过程中各个使用资源的地方,通过调节各种参数,来优化资源使用的效率,从而提升 Spark 作业的执行性能。以下参数就是 Spark 中主要的资源参数,每个参数都对应着作业运行原理中的某个部分,我们同时也给出了一个调优的参考值。
num-executors – YARN-only
参数说明:该参数用于设置 Spark 作业总共要用多少个 Executor 进程来执行。Driver 在向 YARN 集群管理器申请资源时,YARN 集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的 Executor 进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的 Executor 进程,此时你的 Spark 作业的运行速度是非常慢的。
参数调优建议:每个 Spark 作业的运行一般设置50~100个左右的 Executor 进程比较合适,设置太少或太多的 Executor 进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
executor-memory
参数说明:该参数用于设置每个 Executor 进程的内存。Executor 内存的大小,很多时候直接决定了 Spark 作业的性能,而且跟常见的 JVM OOM 异常,也有直接的关联。
参数调优建议:每个 Executor 进程的内存设置4G~8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors * executor-memory,是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的内存量最好不要超过资源队列最大总内存的 1/3~1/2,避免你自己的 Spark 作业占用了队列所有的资源,导致别的同学的作业无法运行。
executor-cores – Spark standalone and YARN only
参数说明:该参数用于设置每个 Executor 进程的 CPU core 数量。这个参数决定了每个 Executor 进程并行执行 task 线程的能力。因为每个 CPU core 同一时间只能执行一个 task 线程,因此每个 Executor 进程的 CPU core 数量越多,越能够快速地执行完分配给自己的所有 task 线程。
参数调优建议:Executor 的 CPU core 数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大 CPU core 限制是多少,再依据设置的 Executor 数量,来决定每个 Executor 进程可以分配到几个 CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总 CPU core 的 1/3~1/2 左右比较合适,也是避免影响其他同学的作业运行。
driver-memory
参数说明:该参数用于设置Driver进程的内存。
参数调优建议:Driver 的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要使用 collect 算子将 RDD 的数据全部拉取到 Driver 上进行处理,那么必须确保 Driver 的内存足够大,否则会出现 OOM 内存溢出的问题。
spark.default.parallelism
参数说明:该参数用于设置每个 stage 的默认 task 数量。这个参数极为重要,如果不设置可能会直接影响你的 Spark 作业性能。
参数调优建议:Spark 作业的默认 task 数量为500~1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致 Spark 自己根据底层 HDFS 的 block 数量来设置 task 的数量,默认是一个 HDFS block 对应一个 task。通常来说,Spark 默认设置的数量是偏少的(比如就几十个 task),如果 task 数量偏少的话,就会导致你前面设置好的 Executor 的参数都前功尽弃。试想一下,无论你的 Executor 进程有多少个,内存和 CPU 有多大,但是 task 只有 1 个或者 10 个,那么 90% 的 Executor 进程可能根本就没有 task 执行,也就是白白浪费了资源!因此 Spark 官网建议的设置原则是,设置该参数为num-executors * executor-cores 的 2~3 倍较为合适,比如 Executor 的总 CPU core 数量为 300 个,那么设置 1000 个 task 是可以的,此时可以充分地利用 Spark 集群的资源。
spark.storage.memoryFraction
参数说明:该参数用于设置 RDD 持久化数据在 Executor 内存中能占的比例,默认是 0.6。也就是说,默认 Executor 60% 的内存,可以用来保存持久化的 RDD 数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
参数调优建议:如果 Spark 作业中,有较多的 RDD 持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果 Spark 作业中的 shuffle 类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的 gc 导致运行缓慢(通过 spark web ui 可以观察到作业的 gc 消耗),意味着 task 执行用户代码的内存不够用,那么同样建议调低这个参数的值。
spark.shuffle.memoryFraction
参数说明:该参数用于设置 shuffle 过程中一个 task 拉取到上个 stage 的 task 的输出后,进行聚合操作时能够使用的 Executor 内存的比例,默认是 0.2。也就是说,Executor 默认只有 20% 的内存用来进行该操作。shuffle 操作在进行聚合时,如果发现使用的内存超出了这个 20% 的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
参数调优建议:如果 Spark 作业中的 RDD 持久化操作较少,shuffle 操作较多时,建议降低持久化操作的内存占比,提高 shuffle 操作的内存占比比例,避免 shuffle 过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的 g c导致运行缓慢,意味着 task 执行用户代码的内存不够用,那么同样建议调低这个参数的值。
小结:
资源参数的调优,没有一个固定的值,需要同学们根据自己的实际情况(包括 Spark 作业中的 shuffle 操作数量、RDD 持久化操作数量以及 spark web ui 中显示的作业 gc 情况),同时参考本篇文章中给出的原理以及调优建议,合理地设置上述参数。
一个 CPU core 同一时间只能执行一个线程。而每个 Executor 进程上分配到的多个 task,都是以每个 task 一条线程的方式,多线程并发运行的。
一个应用提交的时候设置多大的内存?设置多少 Core?设置几个 Executor?
资源参数参考示例:
以下是一份 spark-submit 命令的示例,大家可以参考一下,并根据自己的实际情况进行调节:
./bin/spark-submit \
--master yarn-cluster \
--num-executors 100 \
--executor-memory 6G \
--executor-cores 4 \
--driver-memory 1G \
--conf spark.default.parallelism=1000 \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.3 \
bin/spark-submit -help 帮助参数如下:
[atguigu@hadoop102 spark-2.1.1-bin-hadoop2.7]$ bin/spark-submit -help
Error: Unrecognized option: -help
Usage: spark-submit [options] [app arguments]
Usage: spark-submit --kill [submission ID] --master [spark://...]
Usage: spark-submit --status [submission ID] --master [spark://...]
Usage: spark-submit run-example [options] example-class [example args]
Options:
--master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
--class CLASS_NAME Your application's main class (for Java / Scala apps).
--name NAME A name of your application.
--jars JARS Comma-separated list of local jars to include on the driver
and executor classpaths.
--packages Comma-separated list of maven coordinates of jars to include
on the driver and executor classpaths. Will search the local
maven repo, then maven central and any additional remote
repositories given by --repositories. The format for the
coordinates should be groupId:artifactId:version.
--exclude-packages Comma-separated list of groupId:artifactId, to exclude while
resolving the dependencies provided in --packages to avoid
dependency conflicts.
--repositories Comma-separated list of additional remote repositories to
search for the maven coordinates given with --packages.
--py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place
on the PYTHONPATH for Python apps.
--files FILES Comma-separated list of files to be placed in the working
directory of each executor.
--conf PROP=VALUE Arbitrary Spark configuration property.
--properties-file FILE Path to a file from which to load extra properties. If not
specified, this will look for conf/spark-defaults.conf.
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options Extra Java options to pass to the driver.
--driver-library-path Extra library path entries to pass to the driver.
--driver-class-path Extra class path entries to pass to the driver. Note that
jars added with --jars are automatically included in the
classpath.
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
--proxy-user NAME User to impersonate when submitting the application.
This argument does not work with --principal / --keytab.
--help, -h Show this help message and exit.
--verbose, -v Print additional debug output.
--version, Print the version of current Spark.
Spark standalone with cluster deploy mode only:
--driver-cores NUM Cores for driver (Default: 1).
Spark standalone or Mesos with cluster deploy mode only:
--supervise If given, restarts the driver on failure.
--kill SUBMISSION_ID If given, kills the driver specified.
--status SUBMISSION_ID If given, requests the status of the driver specified.
Spark standalone and Mesos only:
--total-executor-cores NUM Total cores for all executors.
Spark standalone and YARN only:
--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode, #注意:设置这个参数的时候会出现 bug,分配的 executor 核心数不起作用!!!
or all available cores on the worker in standalone mode)
YARN-only:
--driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
--queue QUEUE_NAME The YARN queue to submit to (Default: "default").
--num-executors NUM Number of executors to launch (Default: 2).
If dynamic allocation is enabled, the initial number of
executors will be at least NUM.
--archives ARCHIVES Comma separated list of archives to be extracted into the
working directory of each executor.
--principal PRINCIPAL Principal to be used to login to KDC, while running on
secure HDFS.
--keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above. This keytab will be copied to
the node running the Application Master via the Secure
Distributed Cache, for renewing the login tickets and the
delegation tokens periodically.
[atguigu@hadoop102 spark-2.1.1-bin-hadoop2.7]$
1.4 程序开发调优
Spark 性能优化的第一步,就是要在开发 Spark 作业的过程中注意和应用一些性能优化的基本原则。开发调优,就是要让大家了解以下一些 Spark 基本开发原则,包括:RDD 血统(lineage)设计、算子的合理使用、特殊操作的优化等。在开发过程中,时时刻刻都应该注意以上原则,并将这些原则根据具体的业务以及实际的应用场景,灵活地运用到自己的 Spark 作业中。
1.4.1 原则一:避免创建重复的 RDD
通常来说,我们在开发一个 Spark 作业时,首先是基于某个数据源(比如 Hive 表或 HDFS 文件)创建一个初始的 RDD;接着对这个 RDD 执行某个算子操作,然后得到下一个 RDD;以此类推,循环往复,直到计算出最终我们需要的结果。在这个过程中,多个 RDD 会通过不同的算子操作(比如 map、reduce 等)串起来,这个 “RDD串”,就是 RDD 血统(lineage),也就是 “RDD 的血缘关系链”。
我们在开发过程中要注意:对于同一份数据,只应该创建一个 RDD,不能创建多个 RDD来 代表同一份数据。
一些 Spark 初学者在刚开始开发 Spark 作业时,或者是有经验的工程师在开发 RDD 血统(lineage) 极其冗长的 Spark 作业时,可能会忘了自己之前对于某一份数据已经创建过一个 RDD 了,从而导致对于同一份数据,创建了多个 RDD。这就意味着,我们的 Spark 作业会进行多次重复计算来创建多个代表相同数据的 RDD,进而增加了作业的性能开销。
举一个简单的例子
// 需要对名为 “hello.txt” 的 HDFS 文件进行一次 map 操作,再进行一次 reduce 操作。
// 也就是说,需要对一份数据执行两次算子操作。
// 错误的做法:对于同一份数据执行多次算子操作时,创建多个 RDD。
// 这里执行了两次 textFile 方法,针对同一个 HDFS 文件,创建了两个 RDD 出来,
// 然后分别对每个 RDD 都执行了一个算子操作。
// 这种情况下,Spark 需要从 HDFS 上两次加载 hello.txt 文件的内容,并创建两个单独的 RDD;
// 第二次加载 HDFS 文件以及创建 RDD 的性能开销,很明显是白白浪费掉的。
val rdd1 = sc.textFile("hdfs://192.168.25.102:9000/hello.txt")
rdd1.map(...)
val rdd2 = sc.textFile("hdfs://192.168.25.102:9000/hello.txt")
rdd2.reduce(...)
// 正确的做法:对于一份数据执行多次算子操作时,只使用一个 RDD。
// 这种写法很明显比上一种写法要好多了,因为我们对于同一份数据只创建了一个 RDD,然后对这一个 RDD 执行了多次算子操作。
// 但是要注意到这里为止优化还没有结束,由于 rdd1 被执行了两次算子操作,第二次执行 reduce 操作的时候,
// 还会再次从源头处重新计算一次 rdd1 的数据,因此还是会有重复计算的性能开销。
// 要彻底解决这个问题,必须结合 “原则三:对多次使用的 RDD 进行持久化”,才能保证一个 RDD 被多次使用时只被计算一次。
val rdd1 = sc.textFile("hdfs://192.168.25.102:9000/hello.txt")
rdd1.map(...)
rdd1.reduce(...)
1.4.2 原则二:尽可能复用同一个 RDD
除了要避免在开发过程中对一份完全相同的数据创建多个 RDD 之外,在对不同的数据执行算子操作时还要尽可能地复用一个 RDD。比如说,有一个 RDD 的数据格式是 key-value 类型的,另一个是单 value 类型的,这两个 RDD 的 value 数据是完全一样的。那么此时我们可以只使用 key-value 类型的那个 RDD,因为其中已经包含了另一个的数据。对于类似这种多个 RDD 的数据有重叠或者包含的情况,我们应该尽量复用一个 RDD,这样可以尽可能地减少 RDD 的数量,从而尽可能减少算子执行的次数。
举一个简单的例子:
// 错误的做法:
// 有一个 格式的 RDD,即 rdd1。
// 接着由于业务需要,对 rdd1 执行了一个 map 操作,创建了一个 rdd2,
// 而 rdd2 中的数据仅仅是 rdd1 中的 value 值而已,也就是说,rdd2 是 rdd1 的子集。
JavaPairRDD<long, String> rdd1 = ...
JavaRDD<String> rdd2 = rdd1.map(...)
// 分别对 rdd1 和 rdd2 执行了不同的算子操作。
rdd1.reduceByKey(...)
rdd2.map(...)
// 正确的做法:
// 上面这个 case 中,其实 rdd1 和 rdd2 的区别无非就是数据格式不同而已,
// rdd2 的数据完全就是 rdd1 的子集而已,却创建了两个 rdd,并对两个 rdd 都执行了一次算子操作。
// 此时会因为对 rdd1 执行 map 算子来创建 rdd2,而多执行一次算子操作,进而增加性能开销。
// 其实在这种情况下完全可以复用同一个 RDD。
// 我们可以使用 rdd1,既做 reduceByKey 操作,也做 map 操作。
// 在进行第二个 map 操作时,只使用每个数据的 tuple._2,也就是 rdd1 中的 value 值即可。
JavaPairRDD<long, String> rdd1 = ...
rdd1.reduceByKey(...)
rdd1.map(tuple._2...)
// 第二种方式相较于第一种方式而言,很明显减少了一次 rdd2 的计算开销。
// 但是到这里为止,优化还没有结束,对 rdd1 我们还是执行了两次算子操作,rdd1 实际上还是会被计算两次。
// 因此还需要配合 “原则三:对多次使用的 RDD 进行持久化” 进行使用,
// 才能保证一个 RDD 被多次使用时只被计算一次。
1.4.3 原则三:对多次使用的 RDD 进行持久化
当你在 Spark 代码中多次对一个 RDD 做了算子操作后,你已经实现 Spark 作业第一步的优化了,也就是尽可能复用 RDD 时就该在这个基础之上,进行第二步优化了,也就是要保证对一个 RDD 执行多次算子操作时,这个 RDD 本身仅仅被计算一次。
Spark 中对于一个 RDD 执行多次算子的默认原理是这样的:每次你对一个 RDD 执行一个算子操作时,都会重新从源头处计算一遍,计算出那个 RDD 来,然后再对这个 RDD 执行你的算子操作。这种方式的性能是很差的。
因此对于这种情况,我们的建议是:对多次使用的 RDD 进行持久化(即缓存)。此时 Spark 就会根据你的持久化策略,将 RDD 中的数据保存到内存或者磁盘中。以后每次对这个 RDD 进行算子操作时,都会直接从内存或磁盘中提取持久化的 RDD 数据,然后执行算子,而不从源头处重新计算一遍这个 RDD,再执行算子操作。
对多次使用的 RDD 进行持久化的代码示例:
// 如果要对一个 RDD 进行持久化,只要对这个 RDD 调用 cache() 和 persist() 即可。
// 正确的做法:
// cache() 方法表示:使用非序列化的方式将 RDD 中的数据全部尝试持久化到内存中。
// 此时再对 rdd1 执行两次算子操作时,只有在第一次执行 map 算子时,才会将这个 rdd1 从源头处计算一次。
// 第二次执行 reduce 算子时,就会直接从内存中提取数据进行计算,不会重复计算一个 rdd。
val rdd1 = sc.textFile("hdfs://192.168.25.102:9000/hello.txt").cache()
rdd1.map(...)
rdd1.reduce(...)
// persist() 方法表示:手动选择持久化级别,并使用指定的方式进行持久化。
// 比如说,StorageLevel.MEMORY_AND_DISK_SER 表示,内存充足时优先持久化到内存中,内存不充足时持久化到磁盘文件中。
// 而且其中的 _SER 后缀表示,使用序列化的方式来保存 RDD 数据,此时 RDD 中的每个 partition 都会序列化成一个大的字节数组,然后再持久化到内存或磁盘中。
// 序列化的方式可以减少持久化的数据对内存/磁盘的占用量,进而避免内存被持久化数据占用过多,从而发生频繁 GC。
val rdd1 = sc.textFile("hdfs://192.168.25.102:9000/hello.txt")
.persist(StorageLevel.MEMORY_AND_DISK_SER)
rdd1.map(...)
rdd1.reduce(...)
对于 persist() 方法而言,我们可以根据不同的业务场景选择不同的持久化级别。
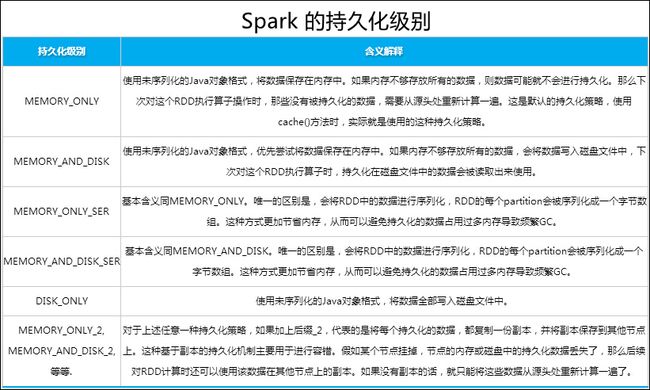
Spark 的持久化级别详解
MEMORY_ONLY 使用未序列化的 Java 对象格式,将数据保存在内存中。如果内存不够存放所有的数据,则数据可能就不会进行持久化。那么下次对这个 RDD 执行算子操作时,那些没有被持久化的数据,需要从源头处重新计算一遍。这是默认的持久化策略,使用 cache() 方法时,实际就是使用的这种持久化策略。
MEMORY_AND_DISK 使用未序列化的 Java 对象格式,优先尝试将数据保存在内存中。如果内存不够存放所有的数据,会将数据写入磁盘文件中,下次对这个 RDD 执行算子时,持久化在磁盘文件中的数据会被读取出来使用。
MEMORY_ONLY_SER 基本含义同 MEMORY_ONLY。唯一的区别是,会将 RDD 中的数据进行序列化,RDD 的每个 partition 会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁 GC。
MEMORY_AND_DISK_SER 基本含义同 MEMORY_AND_DISK。唯一的区别是,会将 RDD 中的数据进行序列化,RDD 的每个 partition 会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁 GC。
DISK_ONLY 使用未序列化的 Java 对象格式,将数据全部写入磁盘文件中。
MEMORY_ONLY_2, MEMORY_AND_DISK_2, 等等 对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化机制主要用于进行容错。假如某个节点挂掉,节点的内存或磁盘中的持久化数据丢失了,那么后续对 RDD 计算时还可以使用该数据在其他节点上的副本。如果没有副本的话,就只能将这些数据从源头处重新计算一遍了。
如何选择一种最合适的持久化策略
1、默认情况下,性能最高的当然是MEMORY_ONLY,但前提是你的内存必须足够足够大,可以绰绰有余地存放下整个 RDD 的所有数据。因为不进行序列化与反序列化操作,就避免了这部分的性能开销;对这个 RDD 的后续算子操作,都是基于纯内存中的数据的操作,不需要从磁盘文件中读取数据,性能也很高;而且不需要复制一份数据副本,并远程传送到其他节点上。但是这里必须要注意的是,在实际的生产环境中,恐怕能够直接用这种策略的场景还是有限的,如果 RDD 中数据比较多时(比如几十亿),直接用这种持久化级别,会导致 JVM 的 OOM 内存溢出异常。
2、如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议尝试使用MEMORY_ONLY_SER级别。该级别会将 RDD 数据序列化后再保存在内存中,此时每个 partition 仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用。这种级别比MEMORY_ONLY多出来的性能开销,主要就是序列化与反序列化的开销。但是后续算子可以基于纯内存进行操作,因此性能总体还是比较高的。此外,可能发生的问题同上,如果 RDD 中的数据量过多的话,还是可能会导致 OOM 内存溢出的异常。
3、如果纯内存的级别都无法使用,那么建议使用MEMORY_AND_DISK_SER策略,而不是MEMORY_AND_DISK策略。因为既然到了这一步,就说明 RDD 的数据量很大,内存无法完全放下。序列化后的数据比较少,可以节省内存和磁盘的空间开销。同时该策略会优先尽量尝试将数据缓存在内存中,内存缓存不下才会写入磁盘。
4、通常不建议使用DISK_ONLY和后缀为_2的级别。因为完全基于磁盘文件进行数据的读写,会导致性能急剧降低,有时还不如重新计算一次所有 RDD。后缀为_2 的级别,必须将所有数据都复制一份副本,并发送到其他节点上,数据复制以及网络传输会导致较大的性能开销,除非是要求作业的高可用性,否则不建议使用。
1.4.4 原则四:尽量避免使用 shuffle 类算子
如果有可能的话,要尽量避免使用 shuffle 类算子。因为 Spark 作业运行过程中,最消耗性能的地方就是 shuffle 过程。shuffle 过程,简单来说,就是将分布在集群中多个节点上的同一个 key,拉取到同一个节点上,进行聚合或 join 等操作。比如 reduceByKey、join 等算子,都会触发 shuffle 操作。
shuffle 过程中,各个节点上的相同 key 都会先写入本地磁盘文件中,然后其他节点需要通过网络传输拉取各个节点上的磁盘文件中的相同 key。而且相同 key 都拉取到同一个节点进行聚合操作时,还有可能会因为一个节点上处理的 key 过多,导致内存不够存放,进而溢写到磁盘文件中。因此在 shuffle 过程中,可能会发生大量的磁盘文件读写的 IO 操作,以及数据的网络传输操作。磁盘 IO 和网络数据传输也是 shuffle 性能较差的主要原因。
因此在我们的开发过程中,能避免则尽可能避免使用 reduceByKey、join、distinct、repartition 等会进行 shuffle 的算子,尽量使用 map 类的非 shuffle 算子。这样的话,没有 shuffle操 作或者仅有较少 shuffle 操作的 Spark 作业,可以大大减少性能开销。
Broadcast 与 map 进行 join 代码示例:
// 传统的 join 操作会导致 shuffle 操作。
// 因为两个 RDD 中,相同的 key 都需要通过网络拉取到一个节点上,由一个 task 进行 join 操作。
val rdd3 = rdd1.join(rdd2)
// Broadcast + map 的 join 操作,不会导致 shuffle 操作。
// 使用 Broadcast 将一个数据量较小的 RDD 作为广播变量。
val rdd2Data = rdd2.collect()
val rdd2DataBroadcast = sc.broadcast(rdd2Data)
// 在 rdd1.map 算子中,可以从 rdd2DataBroadcast 中,获取 rdd2 的所有数据。
// 然后进行遍历,如果发现 rdd2 中某条数据的 key 与 rdd1 的当前数据的 key 是相同的,那么就判定可以进行 join。
// 此时就可以根据自己需要的方式,将 rdd1 当前数据与 rdd2 中可以连接的数据,拼接在一起(String 或 Tuple)。
val rdd3 = rdd1.map(rdd2DataBroadcast...)
// 注意,以上操作,建议仅仅在 rdd2 的数据量比较少(比如几百 M,或者一两 G)的情况下使用。
// 因为每个 Executor 的内存中,都会驻留一份 rdd2 的全量数据。
1.4.5 原则五:使用 map-side 预聚合 shuffle 操作
如果因为业务需要,一定要使用 shuffle 操作,无法用 map 类的算子来替代,那么尽量使用可以 map-side 预聚合的算子。
所谓的 map-side 预聚合,说的是在每个节点本地对相同的 key 进行一次聚合操作,类似于 MapReduce 中的本地 combiner。map-side 预聚合之后,每个节点本地就只会有一条相同的 key,因为多条相同的 key 都被聚合起来了。其他节点在拉取所有节点上的相同 key 时,就会大大减少需要拉取的数据数量,从而也就减少了磁盘 IO 以及网络传输开销。通常来说,在可能的情况下,建议使用 reduceByKey 或者 aggregateByKey 算子来替代掉 groupByKey 算子。因为 reduceByKey 和 aggregateByKey 算子都会使用用户自定义的函数对每个节点本地的相同 key 进行预聚合。而 groupByKey 算子是不会进行预聚合的,全量的数据会在集群的各个节点之间分发和传输,性能相对来说比较差。
比如下图,就是典型的例子,分别基于 reduceByKey 和 groupByKey 进行单词计数。其中第一张图是 groupByKey 的原理图,可以看到,没有进行任何本地聚合时,所有数据都会在集群节点之间传输;第二张图是 reduceByKey 的原理图,可以看到,每个节点本地的相同 key 数据,都进行了预聚合,然后才传输到其他节点上进行全局聚合。

1.4.6 原则六:使用高性能的算子
除了 shuffle 相关的算子有优化原则之外,其他的算子也都有着相应的优化原则。
使用 reduceByKey/aggregateByKey 替代 groupByKey – map-side 预聚合的 shuffle 操作
详情见 “原则五:使用 map-side 预聚合的 shuffle 操作”。
使用 mapPartitions 替代普通 map – 函数执行频率
mapPartitions 类的算子,一次函数调用会处理一个 partition 所有的数据,而不是一次函数调用处理一条,性能相对来说会高一些。但是有的时候,使用 mapPartitions 会出现 OOM(内存溢出)的问题。因为单次函数调用就要处理掉一个 partition 所有的数据,如果内存不够,垃圾回收时是无法回收掉太多对象的,很可能出现 OOM 异常。所以使用这类操作时要慎重!
使用 foreachPartitions 替代 foreach – 函数执行频率
原理类似于 “使用 mapPartitions 替代 map”,也是一次函数调用处理一个 partition 的所有数据,而不是一次函数调用处理一条数据。在实践中发现,foreachPartitions 类的算子,对性能的提升还是很有帮助的。比如在 foreach 函数中,将 RDD 中所有数据写 MySQL,那么如果是普通的 foreach 算子,就会一条数据一条数据地写,每次函数调用可能就会创建一个数据库连接,此时就势必会频繁地创建和销毁数据库连接,性能是非常低下;但是如果用 foreachPartitions 算子一次性处理一个 partition 的数据,那么对于每个 partition,只要创建一个数据库连接即可,然后执行批量插入操作,此时性能是比较高的。实践中发现,对于 1 万条左右的数据量写 MySQL,性能可以提升 30% 以上。
使用 filter 之后进行 coalesce 操作 – filter后对分区进行压缩
通常对一个 RDD 执行 filter 算子过滤掉 RDD 中较多数据后(比如 30% 以上的数据),建议使用 coalesce 算子,手动减少 RDD 的 partition 数量,将 RDD 中的数据压缩到更少的 partition 中去。因为 filter 之后,RDD 的每个 partition 中都会有很多数据被过滤掉,此时如果照常进行后续的计算,其实每个 task 处理的 partition 中的数据量并不是很多,有一点资源浪费,而且此时处理的 task 越多,可能速度反而越慢。因此用 coalesce 减少 partition 数量,将 RDD 中的数据压缩到更少的 partition 之后,只要使用更少的 task 即可处理完所有的 partition。在某些场景下,对于性能的提升会有一定的帮助。
使用 repartitionAndSortWithinPartitions 替代 repartition 与 sort类 操作 – 如果需要在 repartition 重分区之后,还要进行排序,建议直接使用 repartitionAndSortWithinPartitions 算子
repartitionAndSortWithinPartitions 是 Spark 官网推荐的一个算子,官方建议,如果需要在 repartition 重分区之后,还要进行排序,建议直接使用 repartitionAndSortWithinPartitions 算子。因为该算子可以一边进行重分区的 shuffle 操作,一边进行排序。shuffle 与 sort 两个操作同时进行,比先 shuffle 再 sort 来说,性能可能是要高的。
1.4.7 原则七:广播大变量
有时在开发过程中,会遇到需要在算子函数中使用外部变量的场景(尤其是大变量,比如 100M 以上的大集合),那么此时就应该使用 Spark 的广播(Broadcast)功能来提升性能。
在算子函数中使用到外部变量时,默认情况下,Spark 会将该变量复制多个副本,通过网络传输到 task 中,此时每个 task 都有一个变量副本。如果变量本身比较大的话(比如 100M,甚至 1G),那么大量的变量副本在网络中传输的性能开销,以及在各个节点的 Executor 中占用过多内存导致的频繁 GC,都会极大地影响性能。
因此对于上述情况,如果使用的外部变量比较大,建议使用 Spark 的广播功能,对该变量进行广播。广播后的变量,会保证每个 Executor 的内存中,只驻留一份变量副本,而 Executor 中的 task 执行时共享该 Executor 中的那份变量副本。这样的话,可以大大减少变量副本的数量,从而减少网络传输的性能开销,并减少对 Executor 内存的占用开销,降低 GC 的频率。
广播大变量的代码示例:
// 以下代码在算子函数中,使用了外部的变量。
// 此时没有做任何特殊操作,每个 task 都会有一份 list1 的副本。
val list1 = ...
rdd1.map(list1...)
// 以下代码将 list1 封装成了 Broadcast 类型的广播变量。
// 在算子函数中,使用广播变量时,首先会判断当前 task 所在 Executor 内存中,是否有变量副本。
// 如果有则直接使用;如果没有则从 Driver 或者其他 Executor 节点上远程拉取一份放到本地 Executor 内存中。
// 每个 Executor 内存中,就只会驻留一份广播变量副本。
val list1 = ...
val list1Broadcast = sc.broadcast(list1)
rdd1.map(list1Broadcast...)
1.4.8 原则八:使用 Kryo 优化序列化性能
在 Spark 中,主要有三个地方涉及到了序列化:
1、在算子函数中使用到外部变量时,该变量会被序列化后进行网络传输(见 “原则七:广播大变量” 中的讲解)。
2、将自定义的类型作为 RDD 的泛型类型时(比如 JavaRDD,Student 是自定义类型),所有自定义类型对象,都会进行序列化。因此这种情况下,也要求自定义的类必须实现 Serializable 接口。
3、使用可序列化的持久化策略时(比如 MEMORY_ONLY_SER),Spark 会将 RDD 中的每个 partition 都序列化成一个大的字节数组。
对于这三种出现序列化的地方,我们都可以通过使用 Kryo 序列化类库,来优化序列化和反序列化的性能。Spark 默认使用的是 Java 的序列化机制,也就是 ObjectOutputStream/ObjectInputStream API 来进行序列化和反序列化。但是 Spark 同时支持使用 Kryo 序列化库,Kryo 序列化类库的性能比 Java 序列化类库的性能要高很多。官方介绍,Kryo 序列化机制比 Java序列化机制,性能高 10 倍左右。Spark 之所以默认没有使用 Kryo 作为序列化类库,是因为 Kryo 要求最好要注册所有需要进行序列化的自定义类型,因此对于开发者来说,这种方式比较麻烦。
以下是使用 Kryo 的代码示例,我们只要设置序列化类,再注册要序列化的自定义类型即可(比如算子函数中使用到的外部变量类型、作为 RDD 泛型类型的自定义类型等):
使用 Kryo 的代码示例:
// 创建 SparkConf 对象。
val conf = new SparkConf().setMaster(...).setAppName(...)
// 设置序列化器为 KryoSerializer。
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 注册要序列化的自定义类型。
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
1.4.9 原则九:预分区 Shuffle 优化
当遇到 userData 和 events 进行 join 时,userData 比较大,而且 join 操作比较频繁,这个时候,可以先将 userData 调用 partitionBy() 分区,可以极大提高效率。即如果一个 RDD 频繁和其他 RDD 进行 Shuffle 操作,比如:cogroup()、 groupWith()、join()、leftOuterJoin()、rightOuterJoin()、groupByKey()、reduceByKey()、 combineByKey() 以及 lookup() 等,那么最好先将该 RDD 通过 partitionBy() 操作进行预分区,这些操作在 Shuffle 过程中会减少 Shuffle 的数据量,可以极大提高效率。
[外链图片转存失败(img-mwgAm1vr-1562758075586)(https://s2.ax1x.com/2019/05/04/EamOsA.png)]
1.4.10 原则十:优化数据结构
Java 中,有三种类型比较耗费内存:
1、对象,每个 Java 对象都有对象头、引用等额外的信息,因此比较占用内存空间。
2、字符串,每个字符串内部都有一个字符数组以及长度等额外信息。
3、集合类型,比如 HashMap、LinkedList 等,因为集合类型内部通常会使用一些内部类来封装集合元素,比如 Map.Entry。
因此 Spark 官方建议,在 Spark 编码实现中,特别是对于算子函数中的代码,尽量不要使用上述三种数据结构,尽量使用字符串替代对象,使用原始类型(比如 Int、Long)替代字符串,使用数组替代集合类型,这样尽可能地减少内存占用,从而降低 GC 频率,提升性能。
1.5 Shuffle 调优
1.5.1 Shuffle 调优概述
大多数 Spark 作业的性能主要就是消耗在了 shuffle 环节,因为该环节包含了
大量的磁盘IO、序列化、网络数据传输等操作。因此,如果要让作业的性能更上一层楼,就有必要对 shuffle 过程进行调优。但是也必须提醒大家的是,影响一个 Spark 作业性能的因素,主要还是代码开发、资源参数以及数据倾斜,shuffle 调优只能在整个 Spark 的性能调优中占到一小部分而已。因此大家务必把握住调优的基本原则,千万不要舍本逐末。下面我们就给大家详细讲解 shuffle 的原理,以及相关参数的说明,同时给出各个参数的调优建议。
1.5.2 ShuffleManager 发展概述
在 Spark 的源码中,负责 shuffle 过程的执行、计算和处理的组件主要就是 ShuffleManager,也即 shuffle 管理器。而随着 Spark 的版本的发展,ShuffleManager 也在不断迭代,变得越来越先进。
在 Spark 1.2 以前,默认的 shuffle 计算引擎是 HashShuffleManager。该 HashShuffleManager 有着一个非常严重的弊端,就是会产生大量的中间磁盘文件,进而由大量的磁盘 IO 操作影响了性能。
因此在 Spark 1.2 以后的版本中,默认的 ShuffleManager 改成了 SortShuffleManager。SortShuffleManager 相较于 HashShuffleManager来说,有了一定的改进。主要就在于,每个 Task 在进行 shuffle 操作时,虽然也会产生较多的临时磁盘文件,但是最后会将所有的临时文件合并(merge)成一个磁盘文件,因此每个 Task 就只有一个磁盘文件。在下一个 stage 的 shuffle read task 拉取自己的数据时,只要根据索引读取每个磁盘文件中的部分数据即可。
下面我们详细分析一下 HashShuffleManager 和 SortShuffleManager 的原理。
1.5.3 HashShuffleManager 运行原理
未经优化的 HashShuffleManager
下图说明了未经优化的 HashShuffleManager 的原理。这里我们先明确一个假设前提:每个 Executor 只有 1 个 CPU core,也就是说,无论这个 Executor 上分配多少个 task 线程,同一时间都只能执行一个 task 线程。
我们先从 shuffle write 开始说起。shuffle write 阶段,主要就是在一个 stage 结束计算之后,为了下一个 stage 可以执行 shuffle 类的算子(比如 reduceByKey),而将每个 task 处理的数据按 key 进行 “分类”。所谓 “分类”,就是对相同的 key 执行 hash 算法,从而将相同 key 都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游 stage 的一个 task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。
那么每个执行 shuffle write 的 task,要为下一个 stage 创建多少个磁盘文件呢?很简单,下一个 stage 的 task 有多少个,当前 stage 的每个 task 就要创建多少份磁盘文件。比如下一个 stage 总共有 100 个 task,那么当前 stage 的每个 task 都要创建 100 份磁盘文件。如果当前 stage 有 50 个 task,总共有 10 个 Executor,每个 Executor 执行5 个 Task,那么每个 Executor 上总共就要创建 500 个磁盘文件,所有 Executor 上会创建 5000 个磁盘文件。由此可见,未经优化的 shuffle write 操作所产生的磁盘文件的数量是极其惊人的。
接着我们来说说 shuffle read。shuffle read,通常就是一个 stage 刚开始时要做的事情。此时该 stage 的每一个 task 就需要将上一个 stage 的计算结果中的所有相同 key,从各个节点上通过网络都拉取到自己所在的节点上,然后进行 key的 聚合或连接等操作。由于 shuffle write 的过程中,task 给下游 stage 的每个 task 都创建了一个磁盘文件,因此 shuffle read 的过程中,每个 task 只要从上游 stage 的所有 task 所在节点上,拉取属于自己的那一个磁盘文件即可。
shuffle read 的拉取过程是一边拉取一边进行聚合的。每个 shuffle read task 都会有一个自己的 buffer 缓冲,每次都只能拉取与 buffer 缓冲相同大小的数据,然后通过内存中的一个 Map 进行聚合等操作。聚合完一批数据后,再拉取下一批数据,并放到 buffer 缓冲中进行聚合操作。以此类推,直到最后将所有数据到拉取完,并得到最终的结果。
优化后的 HashShuffleManager
下图说明了优化后的 HashShuffleManager 的原理。这里说的优化,是指我们可以设置一个参数,spark.shuffle.consolidateFiles。该参数默认值为 false,将其设置为 true 即可开启优化机制。通常来说,如果我们使用 HashShuffleManager,那么都建议开启这个选项。
开启 consolidate 机制之后,在 shuffle write 过程中,task 就不是为下游 stage 的每个 task 创建一个磁盘文件了。此时会出现 shuffleFileGroup 的概念,每个 shuffleFileGroup 会对应一批磁盘文件,磁盘文件的数量与下游 stage 的 task 数量是相同的。一个 Executor 上有多少个 CPU core,就可以并行执行多少个 task。而第一批并行执行的每个 task 都会创建一个 shuffleFileGroup,并将数据写入对应的磁盘文件内。
当 Executor 的 CPU core 执行完一批 task,接着执行下一批 task 时,下一批 task 就会复用之前已有的 shuffleFileGroup,包括其中的磁盘文件。也就是说,此时 task 会将数据写入已有的磁盘文件中,而不会写入新的磁盘文件中。因此,consolidate 机制允许不同的 task 复用同一批磁盘文件,这样就可以有效将多个 task 的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升 shuffle write 的性能。
假设第二个 stage 有 100 个 task,第一个 stage 有 50 个 task,总共还是有 10 个 Executor,每个 Executor 执行 5 个 task。那么原本使用未经优化的 HashShuffleManager 时,每个 Executor 会产生 500 个磁盘文件,所有 Executor 会产生 5000 个磁盘文件的。但是此时经过优化之后,每个 Executor 创建的磁盘文件的数量的计算公式为:CPU core 的数量 * 下一个 stage 的 task 数量。也就是说,每个 Executor 此时只会创建 100 个磁盘文件,所有 Executor 只会创建 1000 个磁盘文件。
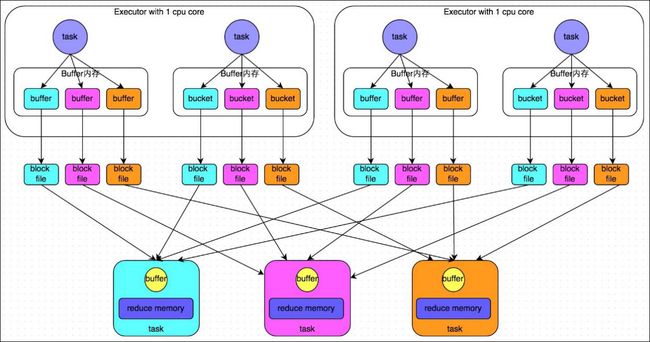
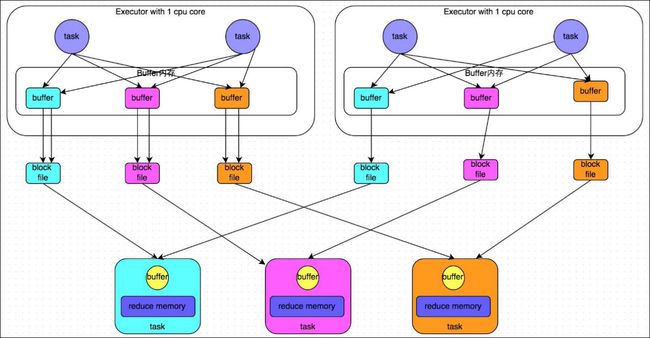
1.5.4 SortShuffleManager 运行原理
SortShuffleManager 的运行机制主要分成两种,一种是
普通运行机制,另一种是bypass运行机制。当 shuffle read task 的数量小于等于 spark.shuffle.sort.bypassMergeThreshold 参数的值时(默认为 200),就会启用 bypass 机制。
普通运行机制
下图说明了普通的 SortShuffleManager 的原理。在该模式下,数据会先写入一个内存数据结构中,此时根据不同的 shuffle 算子,可能选用不同的数据结构。如果是 reduceByKey 这种聚合类的 shuffle 算子,那么会选用 Map 数据结构,一边通过 Map 进行聚合,一边写入内存;如果是 join 这种普通的 shuffle 算子,那么会选用 Array 数据结构,直接写入内存。接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
在溢写到磁盘文件之前,会先根据 key 对内存数据结构中已有的数据进行排序。排序过后,会分批将数据写入磁盘文件。默认的 batch 数量是 10000 条,也就是说,排序好的数据,会以每批 1 万条数据的形式分批写入磁盘文件。写入磁盘文件是通过 Java 的 BufferedOutputStream 实现的。BufferedOutputStream 是 Java 的缓冲输出流,首先会将数据缓冲在内存中,当内存缓冲满溢之后再一次写入磁盘文件中,这样可以减少磁盘 IO 次数,提升性能。
一个 task 将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之前所有的临时磁盘文件都进行合并,这就是 merge 过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最终的磁盘文件之中。此外,由于一个 task 就只对应一个磁盘文件,也就意味着该 task 为下游 stage 的 task 准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个 task 的数据在文件中的 start offset 与 end offset。
SortShuffleManager 由于有一个磁盘文件 merge 的过程,因此大大减少了文件数量。比如第一个 stage 有 50 个 task,总共有 10 个 Executor,每个 Executor 执行 5 个 task,而第二个 stage 有 100 个 task。由于每个 task 最终只有一个磁盘文件,因此此时每个 Executor 上只有 5 个磁盘文件,所有 Executor 只有 50 个磁盘文件。
bypass 运行机制
下图说明了 bypass SortShuffleManager 的原理。bypass 运行机制的触发条件如下:
shuffle map task 数量小于 spark.shuffle.sort.bypassMergeThreshold 参数的值。
不是聚合类的 shuffle 算子(比如 reduceByKey)。
此时 task 会为每个下游 task 都创建一个临时磁盘文件,并将数据按 key 进行 hash 然后根据 key 的 hash 值,将 key 写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的 HashShuffleManager 是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的 HashShuffleManager 来说,shuffle read 的性能会更好。
而该机制与普通 SortShuffleManager 运行机制的不同在于:第一,磁盘写机制不同;第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write 过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。

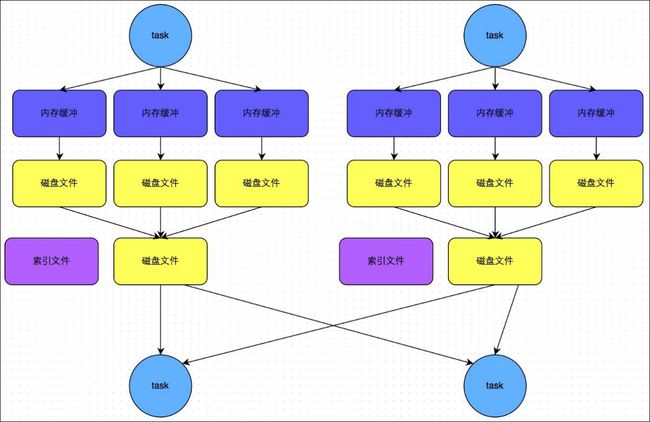
1.5.5 shuffle 相关参数调优
以下是 Shffule 过程中的一些主要参数,这里详细讲解了各个参数的功能、默认值以及基于实践经验给出的调优建议。
spark.shuffle.file.buffer
默认值:32k
参数说明:该参数用于设置 shuffle write task 的 BufferedOutputStream 的 buffer 缓冲大小。将数据写到磁盘文件之前,会先写入 buffer 缓冲中,待缓冲写满之后,才会溢写到磁盘。
调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如 64k),从而减少 shuffle write 过程中溢写磁盘文件的次数,也就可以减少磁盘 IO 次数,进而提升性能。在实践中发现,合理调节该参数,性能会有 1%~5% 的提升。
spark.reducer.maxSizeInFlight
默认值:48m
参数说明:该参数用于设置 shuffle read task 的 buffer 缓冲大小,而这个 buffer 缓冲决定了每次能够拉取多少数据。
调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如 96m),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。在实践中发现,合理调节该参数,性能会有 1%~5% 的提升。
spark.shuffle.io.maxRetries
默认值:3
参数说明:shuffle read task 从 shuffle write task 所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败。
调优建议:对于那些包含了特别耗时的 shuffle 操作的作业,建议增加重试最大次数(比如 60 次),以避免由于 JVM 的 full gc 或者网络不稳定等因素导致的数据拉取失败。在实践中发现,对于针对超大数据量(数十亿~上百亿)的 shuffle 过程,调节该参数可以大幅度提升稳定性。
spark.shuffle.io.retryWait
默认值:5s
参数说明:具体解释同上,该参数代表了每次重试拉取数据的等待间隔,默认是 5s。
调优建议:建议加大间隔时长(比如 60s),以增加 shuffle 操作的稳定性。
spark.shuffle.memoryFraction
默认值:0.2
参数说明:该参数代表了 Executor 内存中,分配给 shuffle read task 进行聚合操作的内存比例,默认是 20%。
调优建议:在资源参数调优中讲解过这个参数。如果内存充足,而且很少使用持久化操作,建议调高这个比例,给 shuffle read 的聚合操作更多内存,以避免由于内存不足导致聚合过程中频繁读写磁盘。在实践中发现,合理调节该参数可以将性能提升 10% 左右。
spark.shuffle.manager
默认值:sort
参数说明:该参数用于设置 ShuffleManager 的类型。Spark 1.5 以后,有三个可选项:hash、sort 和 tungsten-sort。HashShuffleManager 是 Spark 1.2 以前的默认选项,但是 Spark 1.2 以及之后的版本默认都是 SortShuffleManager 了。tungsten-sort 与 sort 类似,但是使用了 tungsten 计划中的堆外内存管理机制,内存使用效率更高。
调优建议:由于 SortShuffleManager 默认会对数据进行排序,因此如果你的业务逻辑中需要该排序机制的话,则使用默认的 SortShuffleManager 就可以;而如果你的业务逻辑不需要对数据进行排序,那么建议参考后面的几个参数调优,通过 bypass 机制或优化的 HashShuffleManager 来避免排序操作,同时提供较好的磁盘读写性能。这里要注意的是,tungsten-sort 要慎用,因为之前发现了一些相应的 bug。
spark.shuffle.sort.bypassMergeThreshold
默认值:200
参数说明:当 ShuffleManager 为 SortShuffleManager 时,如果 shuffle read task 的数量小于这个阈值(默认是 200),则 shuffle write 过程中不会进行排序操作,而是直接按照未经优化的 HashShuffleManager 的方式去写数据,但是最后会将每个 task 产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。
调优建议:当你使用 SortShuffleManager 时,如果的确不需要排序操作,那么建议将这个参数调大一些,大于 shuffle read task 的数量。那么此时就会自动启用 bypass 机制,map-side 就不会进行排序了,减少了排序的性能开销。但是这种方式下,依然会产生大量的磁盘文件,因此 shuffle write 性能有待提高。
spark.shuffle.consolidateFiles
默认值:false
参数说明:如果使用 HashShuffleManager,该参数有效。如果设置为 true,那么就会开启 consolidate 机制,会大幅度合并 shuffle write 的输出文件,对于 shuffle read task 数量特别多的情况下,这种方法可以极大地减少磁盘 IO 开销,提升性能。
调优建议:如果的确不需要 SortShuffleManager 的排序机制,那么除了使用 bypass 机制,还可以尝试将 spark.shffle.manager 参数手动指定为 hash,使用 HashShuffleManager,同时开启 consolidate 机制。在实践中尝试过,发现其性能比开启了 bypass 机制的 SortShuffleManager 要高出 10%~30%。
1.6 GC 调优
Spark 立足内存计算,常常需要在内存中存放大量数据,因此也更依赖 JVM 的垃圾回收机制。与此同时,它也兼容批处理和流式处理,对于程序吞吐量和延迟都有较高要求,因此 GC 参数的调优在 Spark 应用实践中显得尤为重要。
按照经验来说,当我们配置垃圾收集器时,主要有两种策略 – Parallel GC 和 CMS GC。前者注重更高的吞吐量,而后者则注重更低的延迟。两者似乎是鱼和熊掌,不能兼得。在实际应用中,我们只能根据应用对性能瓶颈的侧重性,来选取合适的垃圾收集器。例如,当我们运行需要有实时响应的场景的应用时,我们一般选用 CMS GC,而运行一些离线分析程序时,则选用 Parallel GC。那么对于 Spark 这种既支持流式计算,又支持传统的批处理运算的计算框架来说,是否存在一组通用的配置选项呢?
通常 CMS GC 是企业比较常用的 GC 配置方案,并在长期实践中取得了比较好的效果。例如对于进程中若存在大量寿命较长的对象,Parallel GC 经常带来较大的性能下降。因此,即使是批处理的程序也能从 CMS GC 中获益。不过,在从 1.6 开始的 HOTSPOT JVM 中,我们发现了一个新的 GC 设置项:Garbage-First GC(G1 GC),Oracle 将其定位为 CMS GC 的长期演进。
1.6.1 JVM 虚拟机
每个 Java 开发者都知道 Java 字节码是执行在 JRE(Java Runtime Environment:Java 运行时环境)上的。JRE 中最重要的部分是 Java 虚拟机(JVM),JVM 负责分析和执行 Java 字节码。Java 开发人员并不需要去关心 JVM 是如何运行的。在没有深入理解 JVM 的情况下,许多开发者已经开发出了非常多的优秀的应用以及 Java 类库。不过,如果你了解 JVM 的话,你会更加了解 Java 的,并且你会轻松解决那些看似简单但是无从下手的问题。
虚拟机(Virtual Machine)
JRE 是由 Java API 和 JVM 组成的。JVM 的主要作用是通过 Class Loader 来加载 Java 程序,并且按照 Java API 来执行加载的程序。
虚拟机是通过软件的方式来模拟实现的机器(比如说计算机),它可以像物理机一样运行程序。设计虚拟机的初衷是让 Java 能够通过它来实现 WORA(Write Once Run Anywher 一次编译,到处运行),尽管这个目标现在已经被大多数人忽略了。因此,JVM 可以在不修改 Java 代码的情况下,在所有的硬件环境上运行 Java 字节码。
Java 虚拟机的特点如下:
1)基于栈的虚拟机:Intel x86 和 ARM 这两种最常见的计算机体系的机构都是基于寄存器的。不同的是,JVM 是基于栈的。
2)符号引用:除了基本类型以外的数据(类和接口)都是通过符号来引用,而不是通过显式地使用内存地址来引用。
3)垃圾回收机制:类的实例都是通过用户代码进行创建,并且自动被垃圾回收机制进行回收。
4)通过对基本类型的清晰定义来保证平台独立性:传统的编程语言,例如 C/C++,int 类型的大小取决于不同的平台。JVM 通过对基本类型的清晰定义来保证它的兼容性以及平台独立性。
5)网络字节码顺序:Java class 文件用网络字节码顺序来进行存储:为了保证和小端的 Intel x86 架构以及大端的 RISC 系列的架构保持无关性,JVM 使用用于网络传输的网络字节顺序,也就是大端。
虽然是 Sun 公司开发了 Java,但是所有的开发商都可以开发并且提供遵循 Java 虚拟机规范的 JVM。正是由于这个原因,使得 Oracle HotSpot 和 IBM JVM 等不同的 JVM 能够并存。Google 的 Android 系统里的 Dalvik VM 也是一种 JVM,虽然它并不遵循 Java 虚拟机规范。和基于栈的 Java 虚拟机不同,Dalvik VM 是基于寄存器的架构,因此它的 Java 字节码也被转化成基于寄存器的指令集。
Java字节码(Java bytecode)
为了保证 WORA,JVM 使用 Java 字节码这种介于 Java 和机器语言之间的中间语言。字节码是部署 Java 代码的最小单位。
在解释 Java 字节码之前,我们先通过实例来简单了解它。这个案例是一个在开发环境出现的真实案例的总结。
现象:
一个一直运行正常的应用突然无法运行了。在类库被更新之后,返回下面的错误。
Exception in thread "main" java.lang.NoSuchMethodError: com.atguigu.user.UserAdmin.addUser(Ljava/lang/String;)V
at com.atguigu.service.UserService.add(UserService.java:14)
at com.atguigu.service.UserService.main(UserService.java:19)
应用的代码如下,而且它没有被改动过。
// UserService.java
...
public void add(String userName) {
admin.addUser(userName);
}
更新后的类库的源代码和原始的代码如下:
// UserAdmin.java - Updated library source code
...
public User addUser(String userName) {
User user = new User(userName);
User prevUser = userMap.put(userName, user);
return prevUser;
}
...
public void addUser(String userName) {
User user = new User(userName);
userMap.put(userName, user);
}
简而言之,之前没有返回值的 addUser() 被修改成返回一个 User 类的实例的方法。不过,应用的代码没有做任何修改,因为它没有使用 addUser() 的返回值。
咋一看,com.atguigu.user.UserAdmin.addUser() 方法似乎仍然存在,如果存在的话,那么怎么还会出现 NoSuchMethodError 的错误呢?
原因:
上面问题的原因是在于应用的代码没有用新的类库来进行编译。换句话来说,应用代码似乎是调用了正确的方法,只是没有使用它的返回值而已。不管怎样,编译后的 class 文件表明了这个方法是有返回值的。你可以从下面的错误信息里看到答案。
java.lang.NoSuchMethodError: com.aiguigu.user.UserAdmin.addUser(Ljava/lang/String;)V
NoSuchMethodError 出现的原因是
com.atguigu.user.UserAdmin.addUser(Ljava/lang/String;)V方法找不到。注意一下Ljava/lang/String;和最后面的V。在 Java 字节码的表达式里,L表示的是类的实例。这里表示 addUser() 方法有一个 java/lang/String 的对象作为参数。在这个类库里,参数没有被改变,所以它是正常的。最后面的 “V” 表示这个方法的返回值。在 Java 字节码的表达式里, “V” 表示没有返回(Void)。综上所述,上面的错误信息是表示有一个 java.lang.String 类型的参数,并且没有返回值的 com.atguigu.user.UserAdmin.addUser 方法没有找到。;
因为应用是用之前的类库编译的,所以返回值为空的方法被调用了。但是在修改后的类库里,返回值为空的方法不存在,并且添加了一个返回值为 “Lcom/atguigu/user/User” 的方法。因此,就出现了 NoSuchMethodError。
这个错误出现的原因是因为开发者没有用新的类库来重新编译应用。不过,出现这种问题的大部分责任在于类库的提供者。这个 public 的方法本来没有返回值的,但是后来却被修改成返回 User 类的实例。很明显,方法的签名被修改了,这也表明了这个类库的后向兼容性被破坏了。因此,这个类库的提供者应该告知使用者这个方法已经被改变了。
我们再回到 Java 字节码上来。Java 字节码是 JVM 很重要的部分。JVM 是模拟执行 Java 字节码的一个模拟器。Java 编译器不会直接把高级语言(例如 C/C++)编写的代码直接转换成机器语言(CPU 指令);它会把开发者可以理解的 Java 语言转换成 JVM 能够理解的 Java 字节码。因为 Java 字节码本身是平台无关的,所以它可以在任何安装了 JVM(确切地说,是相匹配的 JRE)的硬件上执行,即使是在 CPU 和 OS 都不相同的平台上(在 Windows PC 上开发和编译的字节码可以不做任何修改就直接运行在 Linux 机器上)。编译后的代码的大小和源代码大小基本一致,这样就可以很容易地通过网络来传输和执行编译后的代码。
Java class 文件是一种人很难去理解的二进制文件。为了便于理解它,JVM 提供者提供了 javap,反汇编器。使用 javap 产生的结果是 Java 汇编语言。在上面的例子中,下面的 Java 汇编代码是通过 javap-c 对 UserServiceadd() 方法进行反汇编得到的。
public void add(java.lang.String);
Code:
0: aload_0
1: getfield #15; // Field admin:Lcom/atguigu/user/UserAdmin;
4: aload_1
5: invokevirtual #23; // Method com/atguigu/user/UserAdmin.addUser:(Ljava/lang/String;)V
8: return
invokeinterface:调用一个接口方法在这段 Java 汇编代码中,addUser() 方法是在第四行的 “5:invokevitual#23” 进行调用的。这表示对应索引为 23 的方法会被调用。索引为 23 的方法的名称已经被 javap 给注解在旁边了。invokevirtual 是 Java 字节码里调用方法的最基本的操作码。在 Java 字节码里,有四种操作码可以用来调用一个方法,分别是:invokeinterface、invokespecial、invokestatic 以及 invokevirtual。操作码的作用分别如下:
1)invokespecial:调用一个初始化方法,私有方法或者父类的方法
2)invokestatic:调用静态方法
3)invokevirtual:调用实例方法
Java 字节码的指令集由操作码和操作数组成。类似 invokevirtual 这样的操作数需要 2 个字节的操作数。
用更新的类库来编译上面的应用代码,然后反编译它,将会得到下面的结果。
public void add(java.lang.String);
Code:
0: aload_0
1: getfield #15; // Field admin:Lcom/atguigu/user/UserAdmin;
4: aload_1
5: invokevirtual #23; // Method com/atguigu/user/UserAdmin.addUser:(Ljava/lang/String;)Lcom/atguigu/user/User;
8: pop
9: return
你会发现,对应索引为 23 的方法被替换成了一个返回值为 “Lcom/atguigu/user/User” 的方法。
在上面的反汇编代码里,代码前面的数字代码什么呢?
它表示的是字节数。大概这就是为什么运行在 JVM 上面的代码成为 Java “字节” 码的原因。简而言之,Java 字节码指令的操作码,例如aload_0、getfield 和 invokevirtual等,都是用一个字节的数字来表示的(aload_0=0x2a, getfield=0xb4, invokevirtual=0xb6)。由此可知 Java 字节码指令的操作码最多有 256 个。
aload_0和aload_1这样的指令不需要任何操作数。因此,aload_0 指令的下一个字节是下一个指令的操作码。不过,getfield 和 invokevirtual 指令需要 2 字节的操作数。因此,getfiled 的下一条指令是跳过两个字节,写在第四个字节的位置上的。十六进制编译器里查看字节码的结果如下所示。
2a b4 00 0f 2b b6 00 17 57 b1
表一:Java 字节码中的类型表达式在 Java 字节码里,类的实例用字母 “L;” 表示,void 用字母 “V” 表示。通过这种方式,其他的类型也有对应的表达式。下面的表格对此作了总结。
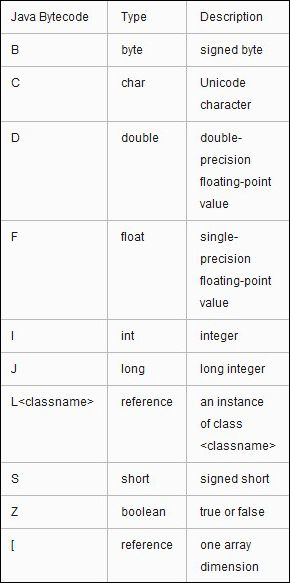
下面的表格给出了字节码表达式的几个实例。
表二:Java 字节码表达式范例

Class文件格式
在讲解 Java class 文件格式之前,我们先看看一个在 Java Web 应用中经常出现的问题。
现象:
当我们编写完 Jsp 代码,并且在 Tomcat 运行时,Jsp 代码没有正常运行,而是出现了下面的错误。
Servlet.service() for servlet jsp threw exception org.apache.jasper.JasperException: Unable to compile class for JSP Generated servlet error:
The code of method _jspService(HttpServletRequest, HttpServletResponse) is exceeding the 65535 bytes limit"
原因在不同的 Web 服务器上,上面的错误信息可能会有点不同,不过有有一点肯定是相同的,它出现的原因是 65535 字节的限制。这个 65535 字节的限制是 JVM 规范里的限制,它规定了一个方法的大小不能超过 65535 字节。
下面我会更加详细地讲解这个 65535 字节限制的意义以及它出现的原因。
Java 字节码里的分支和跳转指令分别是 “goto” 和 “jsr”。
goto [branchbyte1] [branchbyte2]
jsr [branchbyte1] [branchbyte2]
这两个指令都接收一个2字节的有符号的分支跳转偏移量做为操作数,因此偏移量最大只能达到 65535。不过,为了支持更多的跳转,Java 字节码提供了“goto_w”和 “jsr_w” 这两个可以接收4字节分支偏移的指令。
goto_w [branchbyte1] [branchbyte2] [branchbyte3] [branchbyte4]
jsr_w [branchbyte1] [branchbyte2] [branchbyte3] [branchbyte4]
有了这两个指令,索引超过 65535 的分支也是可用的。因此,Java 方法的 65535 字节的限制就可以解除了。不过,由于 Java class 文件的更多的其他的限制,使得 Java 方法还是不能超过 65535 字节。
为了展示其他的限制,我会简单讲解一下 class 文件的格式。
Java class 文件的大致结构如下:
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];}
之前反汇编的 UserService.class 文件反汇编的结果的前 16 个字节在十六进制编辑器中如下所示:
ca fe ba be 00 00 00 32 00 28 07 00 02 01 00 1b
通过这些数值,我们可以来看看 class 文件的格式。
1)magic:class 文件最开始的四个字节是魔数。它的值是用来标识 Java class 文件的。从上面的内容里可以看出,魔数的值是 0xCAFEBABE。简而言之,只有一个文件的起始 4 字节是 0xCAFEBABE 的时候,它才会被当作 Java class 文件来处理。
2)minor_version、major_version:接下来的四个字节表示的是 class 文件的版本。UserService.class 文件里的是 0x00000032,所以这个 class 文件的版本是 50.0。JDK 1.6 编译的 class 文件的版本是 50.0,JDK 1.5 编译出来的 class 文件的版本是 49.0。JVM 必须对低版本的 class 文件保持后向兼容性,也就是低版本的 class 文件可以运行在高版本的 JVM 上。不过,反过来就不行了,当一个高版本的 class 文件运行在低版本的 JVM 上时,会出现 java.lang.UnsupportedClassVersionError 的错误。
3)constant_pool_count、constant_pool[]:在版本号之后,存放的是类的常量池。这里保存的信息将会放入运行时常量池 (Runtime Constant Pool) 中去,这个后面会讲解的。在加载一个 class 文件的时候,JVM 会把常量池里的信息存放在方法区的运行时常量区里。UserService.class 文件里的 constant_pool_count 的值是 0x0028,这表示常量池里有 39(40-1) 个常量。
4)access_flags:这是表示一个类的描述符的标志;换句话说,它表示一个类是 public、final 还是 abstract 以及是不是接口的标志。
5)fields_count、fields[]:当前类的成员变量的数量以及成员变量的信息。成员变量的信息包含变量名、类型、修饰符以及变量在 constant_pool 里的索引。
6)methods_count、methods[]:当前类的方法数量以及方法的信息。方法的信息包含方法名、参数的数量和类型、返回值的类型、修饰符,以及方法在 constant_pool 里的索引,方法的可执行代码以及异常信息。
7)attributes_count、attributes[]:attribution_info结构包含不同种类的属性。field_info和method_info里都包含了attribute_info结构。
javap 简要地给出了 class 文件的一个可读形式。当你用 “java -verbose” 命令来分析 UserService.class 时,会输出如下的内容:
Compiled from "UserService.java"
public class com.atguigu.service.UserService extends java.lang.Object
SourceFile: "UserService.java"
minor version: 0
major version: 50
Constant pool:const #1 = class #2; // com/atguigu/service/UserService
const #2 = Asciz com/atguigu/service/UserService;
const #3 = class #4; // java/lang/Object
const #4 = Asciz java/lang/Object;
const #5 = Asciz admin;
const #6 = Asciz Lcom/atguigu/user/UserAdmin;; // ... omitted - constant pool continued ...
{
// ... omitted - method information ...
public void add(java.lang.String);
Code:
Stack=2, Locals=2, Args_size=2
0: aload_0
1: getfield #15; // Field admin:Lcom/atguigu/user/UserAdmin;
4: aload_1
javap 输出的内容太长,我这里只是提出了整个输出的一部分。整个的输出展示了
constant_pool里的不同信息,以及方法的内容。
关于方法的 65565 字节大小的限制是和method_info struct相关的。method_info结构包含 Code、LineNumberTable 以及 LocalViriable attribute 几个属性,这个在 “javap -verbose” 的输出里可以看到。Code 属性里的LineNumberTable、LocalVariableTable以及exception_table的长度都是用一个固定的 2 字节来表示的。因此,方法的大小是不能超过 LineNumberTable,LocalVariableTable 以及 exception_table 的长度的,它们都是 65535 字节。
许多人都在抱怨方法的大小限制,而且在 JVM 规范里还说名了 “这个长度以后有可能会是可扩展的”。不过,到现在为止,还没有为这个限制做出任何动作。从 JVM 规范里的把 class 文件里的内容直接拷贝到方法区这个特点来看,要想在保持后向兼容性的同时来扩展方法区的大小是非常困难的。
如果因为 Java 编译器的错误而导致 class 文件的错误,会怎么样呢?或者,因为网络传输的错误导致拷贝的 class 文件的损坏呢?
为了预防这种场景,Java 的类装载器通过一个严格而且慎密的过程来校验 class 文件。在 JVM 规范里详细地讲解了这方面的内容。
注意:
我们怎样能够判断 JVM 正确地执行了 class 文件校验的所有过程呢?我们怎么来判断不同提供商的不同 JVM 实现是符合 JVM 规范的呢?为了能够验证以上两点,Oracle 提供了一个测试工具 TCK(Technology Compatibility Kit)。这个 TCK 工具通过执行成千上万的测试用例来验证一个 JVM 是否符合规范,这些测试里面包含了各种非法的 class 文件。只有通过了 TCK 的测试的 JVM 才能称作 JVM。
和 TCK 相似,有一个组织 JCP(Java Community Process;http://jcp.org) 负责 Java 规范以及新的 Java 技术规范。对于 JCP 而言,如果要完成一项 Java 规范请求(Java Specification Request, JSR) 的话,需要具备规范文档,可参考的实现以及通过 TCK 测试。任何人如果想使用一项申请 JSR 的新技术的话,他要么使用 RI 提供许可的实现,要么自己实现一个并且保证通过 TCK 的测试。
JVM 结构
Java 编写的代码会按照下图的流程来执行:
[外链图片转存失败(img-z557UpDC-1562758075587)(https://s2.ax1x.com/2019/05/04/EanALn.png)]
类装载器装载负责装载编译后的字节码,并加载到运行时数据区(Runtime Data Area),然后执行引擎执行会执行这些字节码。
类加载器(Class Loader)
Java 提供了动态的装载特性;它会在运行时的第一次引用到一个 class 的时候对它进行装载和链接,而不是在编译期进行。JVM 的类装载器负责动态装载。Java 类装载器有如下几个特点:
层级结构:Java 里的类装载器被组织成了有父子关系的层级结构。Bootstrap 类装载器是所有装载器的父亲。
代理模式:基于层级结构,类的装载可以在装载器之间进行代理。当装载器装载一个类时,首先会检查它是否在父装载器中进行装载了。如果上层的装载器已经装载了这个类,这个类会被直接使用。反之,类装载器会请求装载这个类。
可见性限制:一个子装载器可以查找父装载器中的类,但是一个父装载器不能查找子装载器里的类。
不允许卸载:类装载器可以装载一个类但是不可以卸载它,不过可以删除当前的类装载器,然后创建一个新的类装载器。
每个类装载器都有一个自己的命名空间用来保存已装载的类。当一个类装载器装载一个类时,它会通过保存在命名空间里的类全局限定名 (Fully Qualified Class Name) 进行搜索来检测这个类是否已经被加载了。如果两个类的全局限定名是一样的,但是如果命名空间不一样的话,那么它们还是不同的类。不同的命名空间表示 class 被不同的类装载器装载。
下图展示了类装载器的代理模型。
当一个类装载器(class loader)被请求装载类时,它首先按照顺序在上层装载器、父装载器以及自身的装载器的缓存里检查这个类是否已经存在。简单来说,就是在缓存里查看这个类是否已经被自己装载过了,如果没有的话,继续查找父类的缓存,直到在 bootstrap 类装载器里也没有找到的话,它就会自己在文件系统里去查找并且加载这个类。
启动类加载器(Bootstrap class loader):这个类装载器是在 JVM 启动的时候创建的。它负责装载 Java API,包含 Object 对象。和其他的类装载器不同的地方在于这个装载器是通过 native code 来实现的,而不是用 Java 代码。
扩展类加载器(Extension class loader):它装载除了基本的 Java API 以外的扩展类。它也负责装载其他的安全扩展功能。
系统类加载器(System class loader):如果说 bootstrap class loader 和 extension class loader 负责加载的是 JVM 的组件,那么 system class loader 负责加载的是应用程序类。它负责加载用户在$CLASSPATH里指定的类。
用户自定义类加载器(User-defined class loader):这是应用程序开发者用直接用代码实现的类装载器。
类似于 web 应用服务 (WAS) 之类的框架会用这种结构来对 Web 应用和企业级应用进行分离。换句话来说,类装载器的代理模型可以用来保证不同应用之间的相互独立。WAS 类装载器使用这种层级结构,不同的 WAS 供应商的装载器结构有稍许区别。
如果类装载器查找到一个没有装载的类,它会按照下图的流程来装载和链接这个类:
每个阶段的描述如下:
Loading:类的信息从文件中获取并且载入到 JVM 的内存里。
Verifying:检查读入的结构是否符合 Java 语言规范以及 JVM 规范的描述。这是类装载中最复杂的过程,并且花费的时间也是最长的。并且 JVM TCK 工具的大部分场景的用例也用来测试在装载错误的类的时候是否会出现错误。
Preparing:分配一个结构用来存储类信息,这个结构中包含了类中定义的成员变量,方法和接口的信息。
Resolving:把这个类的常量池中的所有的符号引用改变成直接引用。
Initializing:把类中的变量初始化成合适的值。执行静态初始化程序,把静态变量初始化成指定的值。
JVM 规范定义了上面的几个任务,不过它允许具体执行的时候能够有些灵活的变动。
运行时数据区(Runtime Data Areas)
运行时数据区是在 JVM 运行的时候操作所分配的内存区。运行时内存区可以划分为 6 个区域。在这 6 个区域中,一个 PC Register、JVM stack 以及 Native Method Statck 都是按照线程创建的,Heap、Method Area 以及 Runtime Constant Pool 都是被所有线程公用的。
PC 寄存器(PC register):每个线程启动的时候,都会创建一个 PC(Program Counter,程序计数器) 寄存器。PC 寄存器里保存有当前正在执行的 JVM 指令的地址。
JVM 堆栈(JVM stack):每个线程启动的时候,都会创建一个 JVM 堆栈。它是用来保存栈帧的。JVM 只会在 JVM 堆栈上对栈帧进行 push 和 pop 的操作。如果出现了异常,堆栈跟踪信息的每一行都代表一个栈帧立的信息,这些信息它是通过类似于 printStackTrace() 这样的方法来展示的。
栈帧(stack frame):每当一个方法在 JVM 上执行的时候,都会创建一个栈帧,并且会添加到当前线程的 JVM 堆栈上。当这个方法执行结束的时候,这个栈帧就会被移除。每个栈帧里都包含有当前正在执行的方法所属类的本地变量数组、操作数栈、以及运行时常量池的引用。本地变量数组的和操作数栈的大小都是在编译时确定的。因此,一个方法的栈帧的大小也是固定不变的。
局部变量数组(Local variable array):这个数组的索引从 0 开始。索引为 0 的变量表示这个方法所属的类的实例。从 1 开始,首先存放的是传给该方法的参数,在参数后面保存的是方法的局部变量。
操作数栈(Operand stack):方法实际运行的工作空间。每个方法都在操作数栈和局部变量数组之间交换数据,并且压入或者弹出其他方法返回的结果。操作数栈所需的最大空间是在编译期确定的。因此,操作数栈的大小也可以在编译期间确定。
本地方法栈(Native method stack):供用非 Java 语言实现的本地方法的堆栈。换句话说,它是用来调用通过 JNI(Java Native Interface Java本地接口) 调用的 C/C++ 代码。根据具体的语言,一个 C 堆栈或者 C++ 堆栈会被创建。
方法区(Method area):方法区是所有线程共享的,它是在 JVM 启动的时候创建的。它保存所有被 JVM 加载的类和接口的运行时常量池,成员变量以及方法的信息,静态变量以及方法的字节码。JVM 的提供者可以通过不同的方式来实现方法区。在 Oracle 的 HotSpot JVM 里,方法区被称为永久区或者永久代(PermGen)。是否对方法区进行垃圾回收对 JVM 的实现是可选的。
运行时常量池(Runtime constant pool):这个区域和 class 文件里的 constant_pool 是相对应的。这个区域是包含在方法区里的,不过,对于 JVM 的操作而言,它是一个核心的角色。因此在 JVM 规范里特别提到了它的重要性。除了包含每个类和接口的常量,它也包含了所有方法和变量的引用。简而言之,当一个方法或者变量被引用时,JVM 通过运行时常量区来查找方法或者变量在内存里的实际地址。
堆(Heap):用来保存实例或者对象的空间,而且它是垃圾回收的主要目标。当讨论类似于 JVM 性能之类的问题时,它经常会被提及。JVM 提供者可以决定怎么来配置堆空间,以及不对它进行垃圾回收。
现在我们再会过头来看看之前反汇编的字节码:
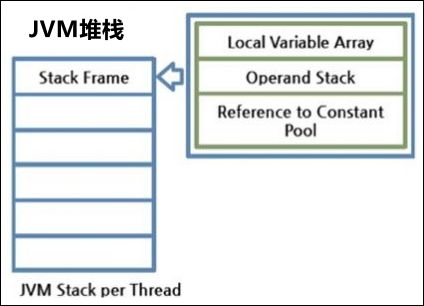
public void add(java.lang.String);
Code:
0: aload_0
1: getfield #15; //Field admin:Lcom/nhn/user/UserAdmin;
4: aload_1
5: invokevirtual #23; //Method com/nhn/user/UserAdmin.addUser:(Ljava/lang/String;)Lcom/nhn/user/User;
8: pop
9: return
把上面的反汇编代码和我们平时所见的 x86 架构的汇编代码相比较,我们会发现这两者的结构有点相似,都使用了操作码;不过,有一点不同的地方是 Java 字节码并不会在操作数里写入寄存器的名称、内存地址或者偏移量。之前已经说过,JVM 用的是栈,它不会使用寄存器。和使用寄存器的 x86 架构不同,它自己负责内存的管理。它用索引例如 15 和 23 来代替实际的内存地址。15 和 23 都是当前类(这里是 UserService 类)的常量池里的索引。简而言之,JVM 为每个类创建了一个常量池,并且这个常量池里保存了实际目标的引用。
每行反汇编代码的解释如下:
aload_0:把局部变量数组中索引为#0的变量添加到操作数栈上。索引#0所表示的变量是 this,即是当前实例的引用。
getfield #15:把当前类的常量池里的索引为#15的变量添加到操作数栈。这里添加的是 UserAdmin 的 admin 成员变量。因为 admin 变量是个类的实例,因此添加的是一个引用。
aload_1:把局部变量数组里的索引为#1的变量添加到操作数栈。来自局部变量数组里的索引为 1 的变量是方法的一个参数。因此,在调用 add() 方法的时候,会把 userName 指向的 String 的引用添加到操作数栈上。
invokevirtual #23:调用当前类的常量池里的索引为#23的方法。这个时候,通过 getfile 和 aload_1 添加到操作数栈上的引用都被作为方法的参数。当方法运行完成并且返回时,它的返回值会被添加到操作数栈上。
pop:把通过 invokevirtual 调用的方法的返回值从操作数栈里弹出来。你可以看到,在前面的例子里,用老的类库编译的那段代码是没有返回值的。简而言之,正因为之前的代码没有返回值,所以没必要吧把返回值从操作数栈上给弹出来。
return:结束当前方法调用。
下图可以帮助你更好地理解上面的内容。

顺便提一下,在这个方法里,局部变量数组没有被修改。所以上图只显示了操作数栈的变化。不过,大部分的情况下,局部变量数组也是会改变的。局部变量数组和操作数栈之间的数据传输是使用通过大量的 load 指令 (aload,iload) 和 store 指令(astore,istore) 来实现的。
在这个图里,我们简单验证了运行时常量池和 JVM 栈的描述。当 JVM 运行的时候,每个类的实例都会在堆上进行分配,User、UserAdmin、UserService 以及 String 等类的信息都会保存在方法区。
执行引擎(Execution Engine)通过类装载器装载的,被分配到 JVM 的运行时数据区的字节码会被执行引擎执行。执行引擎以指令为单位读取 Java 字节码。它就像一个 CPU 一样,一条一条地执行机器指令。每个字节码指令都由一个 1 字节的操作码和附加的操作数组成。执行引擎取得一个操作码,然后根据操作数来执行任务,完成后就继续执行下一条操作码。
不过 Java 字节码是用一种人类可以读懂的语言编写的,而不是用机器可以直接执行的语言。因此,执行引擎必须把字节码转换成可以直接被 JVM 执行的语言。字节码可以通过以下两种方式转换成合适的语言。
解释器:一条一条地读取,解释并且执行字节码指令。因为它一条一条地解释和执行指令,所以它可以很快地解释字节码,但是执行起来会比较慢。这是解释执行的语言的一个缺点。字节码这种“语言”基本来说是解释执行的。
即时(Just-In-Time)编译器:即时编译器被引入用来弥补解释器的缺点。执行引擎首先按照解释执行的方式来执行,然后在合适的时候,即时编译器把整段字节码编译成本地代码。然后,执行引擎就没有必要再去解释执行方法了,它可以直接通过本地代码去执行它。执行本地代码比一条一条进行解释执行的速度快很多。编译后的代码可以执行的很快,因为本地代码是保存在缓存里的。
不过,用 JIT 编译器来编译代码所花的时间要比用解释器去一条条解释执行花的时间要多。因此,如果代码只被执行一次的话,那么最好还是解释执行而不是编译后再执行。因此,内置了 JIT 编译器的 JVM 都会检查方法的执行频率,如果一个方法的执行频率超过一个特定的值的话,那么这个方法就会被编译成本地代码。
JVM 规范没有定义执行引擎该如何去执行。因此,JVM 的提供者通过使用不同的技术以及不同类型的 JIT 编译器来提高执行引擎的效率。
大部分的 JIT 编译器都是按照下图的方式来执行的:
JIT 编译器把字节码转换成一个中间层表达式,一种中间层的表示方式,来进行优化,然后再把这种表示转换成本地代码。
Oracle Hotspot VM 使用一种叫做热点编译器的 JIT 编译器。它之所以被称作 “热点” 是因为热点编译器通过分析找到最需要编译的 “热点” 代码,然后把热点代码编译成本地代码。如果已经被编译成本地代码的字节码不再被频繁调用了,换句话说,这个方法不再是热点了,那么 Hotspot VM 会把编译过的本地代码从 cache 里移除,并且重新按照解释的方式来执行它。Hotspot VM 分为 Server VM 和 Client VM 两种,这两种 VM 使用不同的 JIT 编译器。

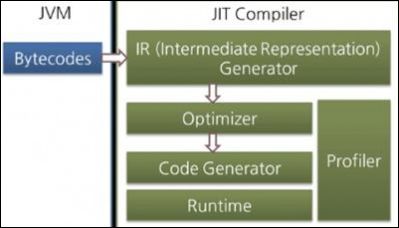

Client VM 和 Server VM 使用完全相同的运行时,不过如上图所示,它们所使用的 JIT 编译器是不同的。Server VM 用的是更高级的动态优化编译器,这个编译器使用了更加复杂并且更多种类的性能优化技术。
IBM 在 IBM JDK 6 里不仅引入了 JIT 编译器,它同时还引入了 AOT(Ahead-Of-Time) 编译器。它使得多个 JVM 可以通过共享缓存来共享编译过的本地代码。简而言之,通过 AOT 编译器编译过的代码可以直接被其他 JVM 使用。除此之外,IBM JVM 通过使用 AOT 编译器来提前把代码编译器成 JXE(Java EXecutable) 文件格式来提供一种更加快速的执行方式。
大部分 Java 程序的性能都是通过提升执行引擎的性能来达到的。正如 JIT 编译器一样,很多优化的技术都被引入进来使得 JVM 的性能一直能够得到提升。最原始的 JVM 和最新的 JVM 最大的差别之处就是在于执行引擎。
Hotspot 编译器在 1.3 版本的时候就被引入到 Oracle Hotspot VM 里了,JIT 编译技术在 Anroid 2.2 版本的时候被引入到 Dalvik VM 里。
引入一种中间语言,例如字节码,虚拟机执行字节码,并且通过 JIT 编译器来提升 JVM 的性能的这种技术以及广泛应用在使用中间语言的编程语言上。例如微软的.Net,CLR(Common Language Runtime 公共语言运行时),也是一种 VM,它执行一种被称作 CIL(Common Intermediate Language)的字节码。CLR 提供了 AOT 编译器和 JIT 编译器。因此,用 C# 或者 VB.NET 编写的源代码被编译后,编译器会生成 CIL 并且 CIL 会执行在有 JIT 编译器的 CLR 上。CLR 和 JVM 相似,它也有垃圾回收机制,并且也是基于堆栈运行。
Java 虚拟机规范,Java SE 第 7 版 2011 年 7 月 28 日,Oracle 发布了 Java SE 的第 7 个版本,并且把 JVM 规也更新到了相应的版本。在 1999 年发布 《The Java Virtual Machine Specification,Second Edition》 后,Oracle 花了 12 年来发布这个更新的版本。这个更新的版本包含了这 12 年来累积的众多变化以及修改,并且更加细致地对规范进行了描述。此外,它还反映了 《The Java Language Specificaion,Java SE 7 Edition》 里的内容。主要的变化总结如下:
• 来自 Java SE 5.0 里的泛型,支持可变参数的方法
• 从 Java SE 6 以来,字节码校验的处理技术所发生的改变
• 添加 invokedynamic 指令以及 class 文件对于该指令的支持
• 删除了关于 Java 语言概念的内容,并且指引读者去参考 Java 语言规范
• 删除关于 Java 线程和锁的描述,并且把它们移到 Java 语言规范里
最大的改变是添加了 invokedynamic 指令。也就是说 JVM 的内部指令集做了修改,使得 JVM 开始支持动态类型的语言,这种语言的类型不是固定的,例如脚本语言以及来自 Java SE 7 里的 Java 语言。之前没有被用到的操作码 186 被分配给新指令 invokedynamic,而且 class 文件格式里也添加了新的内容来支持 invokedynamic 指令。
Java SE 7 的编译器生成的 class 文件的版本号是 51.0。Java SE 6 的是 50.0。class 文件的格式变动比较大,因此,51.0 版本的 class 文件不能够在 Java SE 6 的虚拟机上执行。
尽管有了这么多的变动,但是 Java 方法的 65535 字节的限制还是没有被去掉。除非 class 文件的格式彻底改变,否者这个限制将来也是不可能去掉的。
值得说明的是,Oracle Java SE 7 VM 支持 G1 这种新的垃圾回收机制,不过,它被限制在 Oracle JVM 上,因此,JVM 本身对于垃圾回收的实现不做任何限制。也因此,在 JVM 规范里没有对它进行描述。
switch 语句里的 StringJava SE 7 里添加了很多新的语法和特性。不过,在 Java SE 7 的版本里,相对于语言本身而言,JVM 没有多少的改变。那么,这些新的语言特性是怎么来实现的呢?我们通过反汇编的方式来看看 switch 语句里的 String(把字符串作为 switch() 语句的比较对象)是怎么实现的?
例如,下面的代码:
// SwitchTest
public class SwitchTest {
public int doSwitch(String str) {
switch (str) {
case "abc": return 1;
case "123": return 2;
default: return 0;
}
}
}
因为这是 Java SE 7 的一个新特性,所以它不能在 Java SE 6 或者更低版本的编译器上来编译。用 Java SE 7 的 javac 来编译。下面是通过 javap -c 来反编译后的结果。
C:Test>javap -c SwitchTest.classCompiled from "SwitchTest.java"
public class SwitchTest {
public SwitchTest();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."":()V
4: return public int doSwitch(java.lang.String);
Code:
0: aload_1
1: astore_2
2: iconst_m1
3: istore_3
4: aload_2
5: invokevirtual #2 // Method java/lang/String.hashCode:()I
8: lookupswitch { // 2
48690: 50
96354: 36
default: 61
}
36: aload_2
37: ldc #3 // String abc
39: invokevirtual #4 // Method java/lang/String.equals:(Ljava/lang/Object;)Z
42: ifeq 61
45: iconst_0
46: istore_3
47: goto 61
50: aload_2
51: ldc #5 // String 123
53: invokevirtual #4 // Method java/lang/String.equals:(Ljava/lang/Object;)Z
56: ifeq 61
59: iconst_1
60: istore_3
61: iload_3
62: lookupswitch { // 2
0: 88
1: 90
default: 92
}
88: iconst_1
89: ireturn
90: iconst_2
91: ireturn
92: iconst_0
93: ireturn
在 #5 和 #8 字节处,首先是调用了 hashCode() 方法,然后它作为参数调用了 switch(int)。在 lookupswitch 的指令里,根据 hashCode 的结果进行不同的分支跳转。字符串 “abc” 的hashCode是96354,它会跳转到#36处。字符串 “123” 的 hashCode 是 48690,它会跳转到 #50 处。生成的字节码的长度比 Java 源码长多了。首先,你可以看到字节码里用 lookupswitch 指令来实现 switch() 语句。不过,这里使用了两个 lookupswitch 指令,而不是一个。如果反编译的是针对 Int 的 switch() 语句的话,字节码里只会使用一个 lookupswitch 指令。也就是说,针对 string 的 switch 语句被分成用两个语句来实现。留心标号为 #5、#39 和#53 的指令,来看看 switch() 语句是如何处理字符串的。
在第 #36、#37、#39 以及 #42 字节的地方,你可以看见 str 参数被 equals() 方法来和字符串 “abc” 进行比较。如果比较的结果是相等的话,‘0’ 会被放入到局部变量数组的索引为 #3 的位置,然后跳抓转到第 #61 字节。
在第 #50、#51、#53 以及 #56 字节的地方,你可以看见 str 参数被 equals() 方法来和字符串 “123” 进行比较。如果比较的结果是相等的话,‘10’ 会被放入到局部变量数组的索引为 #3 的位置,然后跳转到第 #61 字节。
在第 #61 和 #62 字节的地方,局部变量数组里索引为 #3 的值,这里是 ‘0’,‘1’ 或者其他的值,被 lookupswitch 用来进行搜索并进行相应的分支跳转。
换句话来说,在 Java 代码里的用来作为 switch() 的参数的字符串 str 变量是通过 hashCode() 和 equals() 方法来进行比较,然后根据比较的结果,来执行 swtich() 语句。
在这个结果里,编译后的字节码和之前版本的 JVM 规范没有不兼容的地方。Java SE 7 的这个用字符串作为 switch 参数的特性是通过 Java 编译器来处理的,而不是通过 JVM 来支持的。通过这种方式还可以把其他的 Java SE 7 的新特性也通过 Java 编译器来实现。
1.6.2 GC 算法原理
在传统 JVM 内存管理中,我们把 Heap 空间分为 Young/Old 两个分区,Young 分区又包括一个 Eden 和两个 Survivor 分区,如下图所示。新产生的对象首先会被存放在 Eden 区,而每次 minor GC 发生时,JVM 一方面将 Eden 分区内存活的对象拷贝到一个空的 Survivor 分区,另一方面将另一个正在被使用的 Survivor 分区中的存活对象也拷贝到空的 Survivor 分区内。在此过程中,JVM 始终保持一个 Survivor 分区处于全空的状态。一个对象在两个 Survivor 之间的拷贝到一定次数后,如果还是存活的,就将其拷入 Old 分区。当 Old 分区没有足够空间时,GC 会停下所有程序线程,进行 Full GC,即对 Old 区中的对象进行整理。这个所有线程都暂停的阶段被称为 Stop-The-World(STW),也是大多数 GC 算法中对性能影响最大的部分。
而 G1 GC 则完全改变了这一传统思路。它将整个 Heap 分为若干个预先设定的小区域块(如下图),每个区域块内部不再进行新旧分区,而是将整个区域块标记为 Eden/Survivor/Old。当创建新对象时,它首先被存放到某一个可用区块(Region)中。当该区块满了,JVM 就会创建新的区块存放对象。当发生 minor GC 时,JVM 将一个或几个区块中存活的对象拷贝到一个新的区块中,并在空余的空间中选择几个全新区块作为新的 Eden 分区。当所有区域中都有存活对象,找不到全空区块时,才发生 Full GC。而在标记存活对象时,G1 使用 RememberSet 的概念,将每个分区外指向分区内的引用记录在该分区的 RememberSet 中,避免了对整个 Heap 的扫描,使得各个分区的 GC 更加独立。在这样的背景下,我们可以看出 G1 GC 大大提高了触发 Full GC 时的 Heap 占用率,同时也使得 Minor GC 的暂停时间更加可控,对于内存较大的环境非常友好。这些颠覆性的改变,将给 GC 性能带来怎样的变化呢?最简单的方式,我们可以将老的 GC 设置直接迁移为 G1 GC,然后观察性能变化。
由于 G1 取消了对于 heap 空间不同新旧对象固定分区的概念,所以我们需要在 GC 配置选项上作相应的调整,使得应用能够合理地运行在 G1 GC 收集器上。一般来说,对于原运行在 Parallel GC 上的应用,需要去除的参数包括 -Xmn、-XX:-UseAdaptiveSizePolicy、-XX:SurvivorRatio=n 等;而对于原来使用 CMS GC 的应用,我们需要去掉 -Xmn -XX:InitialSurvivorRatio、-XX:SurvivorRatio、-XX:InitialTenuringThreshold 、-XX:MaxTenuringThreshold 等参数。另外在 CMS 中已经调优过的 -XX:ParallelGCThreads、 -XX:ConcGCThreads 参数最好也移除掉,因为对于 CMS 来说性能最好的不一定是对于 G1 性能最好的选择。我们先统一置为默认值,方便后期调优。此外,当应用开启的线程较多时,最好使用 -XX:-ResizePLAB 来关闭 PLAB() 的大小调整,以避免大量的线程通信所导致的性能下降。
关于 Hotspot JVM 所支持的完整的 GC 参数列表,可以使用参数 -XX:+PrintFlagsFinal 打印出来,也可以参见 Oracle 官方的文档中对部分参数的解释。

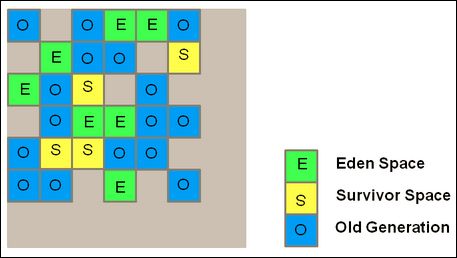
1.6.3 Spark 的内存管理
Spark 的核心概念是 RDD,实际运行中内存消耗都与 RDD 密切相关。Spark 允许用户将应用中重复使用的 RDD 数据持久化缓存起来,从而避免反复计算的开销,而 RDD 的持久化形态之一就是将全部或者部分数据缓存在 JVM 的 Heap 中。Spark Executor 会将 JVM 的 heap 空间大致分为两个部分,一部分用来存放 Spark 应用中持久化到内存中的 RDD 数据,剩下的部分则用来作为 JVM 运行时的堆空间,负责 RDD 转化等过程中的内存消耗。我们可以通过
spark.storage.memoryFraction参数调节这两块内存的比例,Spark 会控制缓存 RDD 总大小不超过 heap 空间体积乘以这个参数所设置的值,而这块缓存 RDD 的空间中没有使用的部分也可以为 JVM 运行时所用。因此,分析 Spark 应用 GC 问题时应当分别分析两部分内存的使用情况。
而当我们观察到 GC 延迟影响效率时,应当先检查 Spark 应用本身是否有效利用有限的内存空间。RDD 占用的内存空间比较少的话,程序运行的 heap 空间也会比较宽松,GC 效率也会相应提高;而 RDD 如果占用大量空间的话,则会带来巨大的性能损失。下面我们从一个用户案例展开:
该应用是利用 Spark 的组件 Bagel 来实现的,其本质就是一个简单的迭代计算。而每次迭代计算依赖于上一次的迭代结果,因此每次迭代结果都会被主动持续化到内存空间中。当运行用户程序时,我们观察到随着迭代次数的增加,进程占用的内存空间不断快速增长,GC 问题越来越突出。但是,仔细分析 Bagel 实现机制,我们很快发现 Bagel 将每次迭代产生的 RDD 都持久化下来了,而没有及时释放掉不再使用的 RDD,从而造成了内存空间不断增长,触发了更多 GC 执行。经过简单的修改,我们修复了这个问题(SPARK-2661)。应用的内存空间得到了有效的控制后,迭代次数三次以后 RDD 大小趋于稳定,缓存空间得到有效控制(如下表所示),GC 效率得以大大提高,程序总的运行时间缩短了 10%~20%。
小结:当观察到 GC 频繁或者延时长的情况,也可能是 Spark 进程或者应用中内存空间没有有效利用。所以可以尝试检查是否存在 RDD 持久化后未得到及时释放等情况。
1.6.4 选择垃圾收集器
在解决了应用本身的问题之后,我们就要开始针对 Spark 应用的 GC 调优了。基于修复了 SPARK-2661 的 Spark 版本,我们搭建了一个 4 个节点的集群,给每个 Executor 分配 88G 的 Heap,在 Spark 的 Standalone 模式下来进行我们的实验。在使用默认的 Parallel GC 运行我们的 Spar k应用时,我们发现,由于 Spark 应用对于内存的开销比较大,而且大部分对象并不能在一个较短的生命周期中被回收,Parallel GC 也常常受困于 Full GC,而每次 Full GC 都给性能带来了较大的下降。而 Parallel GC 可以进行参数调优的空间也非常有限,我们只能通过调节一些基本参数来提高性能,如各年代分区大小比例、进入老年代前的拷贝次数等。而且这些调优策略只能推迟 Full GC 的到来,如果是长期运行的应用,Parallel GC 调优的意义就非常有限了。因此,本文中不会再对 Parallel GC 进行调优。下表列出了 Parallel GC 的运行情况,其中 CPU 利用率较低的部分正是发生 Full GC 的时候。

Parallel GC 运行情况(未调优)
至于 CMS GC,也没有办法消除这个 Spark 应用中的 Full GC,而且 CMS 的 Full GC 的暂停时间远远超过了 Parallel GC,大大拖累了该应用的吞吐量。
接下来,我们就使用最基本的 G1 GC 配置来运行我们的应用。实验结果发现,G1 GC 竟然也出现了不可忍受的 Full GC(下表的 CPU 利用率图中,可以明显发现 Job 3 中出现了将近 100 秒的暂停),超长的暂停时间大大拖累了整个应用的运行。如下表所示,虽然总的运行时间比 Parallel GC 略长,不过 G1 GC 表现略好于 CMS GC。
三种垃圾收集器对应的程序运行时间比较(88GB heap 未调优)
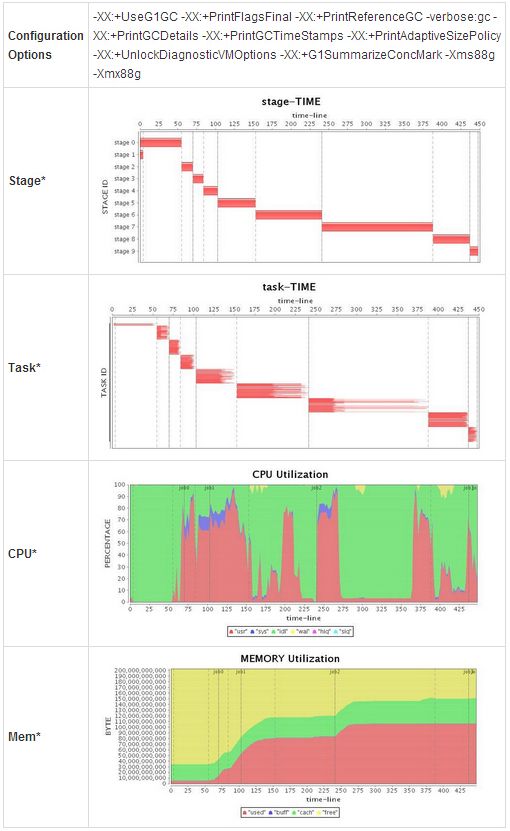

1.6.5 根据日志进一步调优
在让 G1 GC 跑起来之后,我们下一步就是需要根据 GC log,来进一步进行性能调优。首先,我们要让 JVM 记录比较详细的 GC 日志. 对于 Spark 而言,我们需要在
SPARK_JAVA_OPTS中设置参数使得 Spark 保留下我们需要用到的日志. 一般而言,我们需要设置这样一串参数:
-XX:+PrintFlagsFinal
-XX:+PrintReferenceGC -verbose:gc
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintAdaptiveSizePolicy
-XX:+UnlockDiagnosticVMOptions
-XX:+G1SummarizeConcMark
有了这些参数,我们就可以在 SPARK 的 EXECUTOR 日志中(默认输出到各 worker 节点的
$SPARK_HOME/work/$app_id/$executor_id/stdout中)读到详尽的 GC 日志以及生效的 GC 参数了。接下来,我们就可以根据 GC 日志来分析问题,使程序获得更优性能。我们先来了解一下 G1 中一次 GC 的日志结构。
251.354: [G1Ergonomics (Mixed GCs) continue mixed GCs,
reason: candidate old regions available,
candidate old regions: 363 regions,
reclaimable: 9830652576 bytes (10.40 %),
threshold: 10.00 %]
[Parallel Time: 145.1 ms, GC Workers: 23]
[GC Worker Start (ms): Min: 251176.0, Avg: 251176.4, Max: 251176.7, Diff: 0.7]
[Ext Root Scanning (ms): Min: 0.8, Avg: 1.2, Max: 1.7, Diff: 0.9, Sum: 28.1]
[Update RS (ms): Min: 0.0, Avg: 0.3, Max: 0.6, Diff: 0.6, Sum: 5.8]
[Processed Buffers: Min: 0, Avg: 1.6, Max: 9, Diff: 9, Sum: 37]
[Scan RS (ms): Min: 6.0, Avg: 6.2, Max: 6.3, Diff: 0.3, Sum: 143.0]
[Object Copy (ms): Min: 136.2, Avg: 136.3, Max: 136.4, Diff: 0.3, Sum: 3133.9]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.3]
[GC Worker Other (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 1.9]
[GC Worker Total (ms): Min: 143.7, Avg: 144.0, Max: 144.5, Diff: 0.8, Sum: 3313.0]
[GC Worker End (ms): Min: 251320.4, Avg: 251320.5, Max: 251320.6, Diff: 0.2]
[Code Root Fixup: 0.0 ms]
[Clear CT: 6.6 ms]
[Other: 26.8 ms]
[Choose CSet: 0.2 ms]
[Ref Proc: 16.6 ms]
[Ref Enq: 0.9 ms]
[Free CSet: 2.0 ms]
[Eden: 3904.0M(3904.0M)->0.0B(4448.0M) Survivors: 576.0M->32.0M Heap: 63.7G(88.0G)->58.3G(88.0G)]
[Times: user=3.43 sys=0.01, real=0.18 secs]
以 G1 GC 的一次 mixed GC 为例,从这段日志中,我们可以看到 G1 GC 日志的层次是非常清晰的。日志列出了这次暂停发生的时间、原因,并分析各种线程所消耗的时长以及 CPU 时间的均值和最值。最后,G1 GC 列出了本次暂停的清理结果,以及总共消耗的时间。
而在我们现在的 G1 GC 运行日志中,我们明显发现这样一段特殊的日志:
(to-space exhausted), 1.0552680 secs]
[Parallel Time: 958.8 ms, GC Workers: 23]
[GC Worker Start (ms): Min: 759925.0, Avg: 759925.1, Max: 759925.3, Diff: 0.3]
[Ext Root Scanning (ms): Min: 1.1, Avg: 1.4, Max: 1.8, Diff: 0.6, Sum: 33.0]
[SATB Filtering (ms): Min: 0.0, Avg: 0.0, Max: 0.3, Diff: 0.3, Sum: 0.3]
[Update RS (ms): Min: 0.0, Avg: 1.2, Max: 2.1, Diff: 2.1, Sum: 26.9]
[Processed Buffers: Min: 0, Avg: 2.8, Max: 11, Diff: 11, Sum: 65]
[Scan RS (ms): Min: 1.6, Avg: 2.5, Max: 3.0, Diff: 1.4, Sum: 58.0]
[Object Copy (ms): Min: 952.5, Avg: 953.0, Max: 954.3, Diff: 1.7, Sum: 21919.4]
[Termination (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 2.2]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.6]
[GC Worker Total (ms): Min: 958.1, Avg: 958.3, Max: 958.4, Diff: 0.3, Sum: 22040.4]
[GC Worker End (ms): Min: 760883.4, Avg: 760883.4, Max: 760883.4, Diff: 0.0]
[Code Root Fixup: 0.0 ms]
[Clear CT: 0.4 ms]
[Other: 96.0 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.4 ms]
[Ref Enq: 0.0 ms]
[Free CSet: 0.1 ms]
[Eden: 160.0M(3904.0M)->0.0B(4480.0M) Survivors: 576.0M->0.0B Heap: 87.7G(88.0G)->87.7G(88.0G)]
[Times: user=1.69 sys=0.24, real=1.05 secs]
760.981: [G1Ergonomics (Heap Sizing) attempt heap expansion, reason: allocation request failed, allocation request: 90128 bytes]
760.981: [G1Ergonomics (Heap Sizing) expand the heap, requested expansion amount: 33554432 bytes, attempted expansion amount: 33554432 bytes]
760.981: [G1Ergonomics (Heap Sizing) did not expand the heap, reason: heap expansion operation failed]
760.981: [Full GC 87G->36G(88G), 67.4381220 secs]
显然最大的性能下降是这样的 Full GC 导致的,我们可以在日志中看到类似 To-space Exhausted 或者 To-space Overflow 这样的输出(取决于不同版本的 JVM,输出略有不同)。这是 G1 GC 收集器在将某个需要垃圾回收的分区进行回收时,无法找到一个能将其中存活对象拷贝过去的空闲分区。这种情况被称为 Evacuation Failure,常常会引发 Full GC。而且很显然,G1 GC 的 Full GC 效率相对于 Parallel GC 实在是相差太远,我们想要获得比 Parallel GC 更好的表现,一定要尽力规避 Full GC 的出现。对于这种情况,我们常见的处理办法有两种:
• 将 InitiatingHeapOccupancyPercent 参数调低(默认值是 45),可以使 G1 GC 收集器更早开始 Mixed GC;但另一方面,会增加 GC 发生频率。
• 提高 ConcGCThreads 的值,在 Mixed GC 阶段投入更多的并发线程,争取提高每次暂停的效率。但是此参数会占用一定的有效工作线程资源。
调试这两个参数可以有效降低 Full GC 出现的概率。Full GC 被消除之后,最终的性能获得了大幅提升。但是我们发现,仍然有一些地方 GC 产生了大量的暂停时间。比如,我们在日志中读到很多类似这样的片断:
280.008: [G1Ergonomics (Concurrent Cycles)
request concurrent cycle initiation,
reason: occupancy higher than threshold,
occupancy: 62344134656 bytes,
allocation request: 46137368 bytes,
threshold: 42520176225 bytes (45.00 %),
source: concurrent humongous allocation]
这里就是 Humongous object,一些比 G1 的一个分区的一半更大的对象。对于这些对象,G1 会专门在 Heap 上开出一个个 Humongous Area 来存放,每个分区只放一个对象。但是申请这么大的空间是比较耗时的,而且这些区域也仅当 Full GC 时才进行处理,所以我们要尽量减少这样的对象产生。或者提高 G1HeapRegionSize 的值减少 HumongousArea 的创建。不过在内存比较大的时,JVM 默认把这个值设到了最大(32M),此时我们只能通过分析程序本身找到这些对象并且尽量减少这样的对象产生。当然,相信随着G1 GC 的发展,在后期的版本中相信这个最大值也会越来越大,毕竟 G1 号称是在 1024~2048 个 Region 时能够获得最佳性能。
接下来,我们可以分析一下单次 cycle start 到 Mixed GC 为止的时间间隔。如果这一时间过长,可以考虑进一步提升 ConcGCThreads,需要注意的是,这会进一步占用一定 CPU 资源。
对于追求更短暂停时间的在线应用,如果观测到较长的 Mixed GC pause,我们还要把 G1RSetUpdatingPauseTimePercent 调低,把 G1ConcRefinementThreads 调高。前文提到 G1 GC 通过为每个分区维护 RememberSet 来记录分区外对分区内的引用,G1RSetUpdatingPauseTimePercent 则正是在 STW 阶段为 G1 收集器指定更新 RememberSet 的时间占总 STW 时间的期望比例,默认为 10。而 G1ConcRefinementThreads 则是在程序运行时维护 RememberSet 的线程数目。通过对这两个值的对应调整,我们可以把 STW 阶段的 RememberSet 更新工作压力更多地移到 Concurrent 阶段。
另外,对于需要长时间运行的应用,我们不妨加上 AlwaysPreTouch 参数,这样 JVM 会在启动时就向 OS 申请所有需要使用的内存,避免动态申请,也可以提高运行时性能。但是该参数也会大大延长启动时间。
最终,经过几轮 GC 参数调试,其结果如下表所示。较之先前的结果,我们最终还是获得了较满意的运行效率。
小结:综合考虑 G1 GC 是较为推崇的默认 Spark GC 机制。进一步的 GC 日志分析,可以收获更多的 GC 优化。经过上面的调优过程,我们将该应用的运行时间缩短到了 4.3 分钟,相比调优之前,我们获得了 1.7 倍左右的性能提升,而相比 Parallel GC 也获得了 1.5 倍左右的性能提升。
对于大量依赖于内存计算的 Spark 应用,GC 调优显得尤为重要。在发现 GC 问题的时候,不要着急调试 GC。而是先考虑是否存在 Spark 进程内存管理的效率问题,例如 RDD 缓存的持久化和释放。至于 GC 参数的调试,首先我们比较推荐使用 G1 GC 来运行 Spark 应用。相较于传统的垃圾收集器,随着 G1 的不断成熟,需要配置的选项会更少,能同时满足高吞吐量和低延迟的需求。当然,GC 的调优不是绝对的,不同的应用会有不同应用的特性,掌握根据 GC 日志进行调优的方法,才能以不变应万变。最后,也不能忘了先对程序本身的逻辑和代码编写进行考量,例如减少中间变量的创建或者复制,控制大对象的创建,将长期存活对象放在 Off-heap 中等等。
第2章 Spark 企业应用案例
2.1 京东商城基于 Spark 的风控系统的实现
2.1.1 风控系统背景
互联网的迅速发展,为电子商务兴起提供了肥沃的土壤。2014 年,中国电子商务市场交易规模达到 13.4 万亿元,同比增长 31.4%。其中,B2B 电子商务市场交易额达到 10 万亿元,同比增长 21.9%。这一连串高速增长的数字背后,不法分子对互联网资产的觊觎,针对电商行业的恶意行为也愈演愈烈,这其中,最典型的就是
黄牛抢单囤货和商家恶意刷单。黄牛囤货让广大正常用户失去了商家给予的优惠让利;而商家的刷单刷好评,不仅干扰了用户的合理购物选择,更是搅乱了整个市场秩序。
京东作为国内电商的龙头企业,在今天遭受着严酷的风险威胁。机器注册账号、恶意下单、黄牛抢购、商家刷单等等问题如果不被有效阻止,会给京东和消费者带来难以估量的损失
互联网行业中,通常使用风控系统抵御这些恶意访问。在技术层面上来讲,风控领域已逐渐由传统的 “rule-base”(基于规则判断)发展到今天的大数据为基础的实时+离线双层识别。Hadoop、Spark 等大数据大集群分布式处理框架的不断发展为风控技术提供了有效的支撑。
2.1.2 什么是“天网”
在此背景下,京东风控部门打造 “天网” 系统,在经历了多年沉淀后,“天网” 目前已全面覆盖京东商城数十个业务节点并有效支撑了京东集团旗下的京东到家及海外购风控相关业务,有效保证了用户利益和京东的业务流程。
“天网“ 作为京东风控的核心利器,目前搭建了风控专用的基于 spark 的图计算平台,主要分析维度主要包括:用户画像、用户社交关系网络、交易风险行为特性模型。
其系统内部既包含了面向业务的交易订单风控系统、爆品抢购风控系统、商家反刷单系统,在其身后还有存储用户风险信用信息及规则识别引擎的风险信用中心(RCS)系统,专注于打造用户风险画像的用户风险评分等级系统。
下面,我们将从用户可以直接感知的前端业务风控系统和后台支撑系统两部分对天网进行剖析。

2.1.3 前端业务风控系统
1、交易订单风控系统
交易订单风控系统主要致力于控制下单环节的各种恶意行为。该系统根据用户注册手机,收货地址等基本信息结合当前下单行为、历史购买记录等多种维度,对机器刷单、人工批量下单以及异常大额订单等多种非正常订单进行实时判别并实施拦截。
目前该系统针对图书、日用百货、3C 产品、服饰家居等不同类型的商品制定了不同的识别规则,经过多轮的迭代优化,识别准确率已超过 99%。对于系统无法精准判别的嫌疑订单,系统会自动将他们推送到后台风控运营团队进行人工审核,运营团队将根据账户的历史订单信息并结合当前订单,判定是否为恶意订单。从系统自动识别到背后人工识别辅助,能够最大限度地保障订单交易的真实有效性。
2、爆品抢购风控系统
在京东电商平台,每天都会有定期推出的秒杀商品,这些商品多数来自一线品牌商家在京东平台上进行产品首发或是爆品抢购,因此秒杀商品的价格会相对市场价格有很大的优惠力度。
但这同时也给黄牛带来了巨大的利益诱惑,他们会采用批量机器注册账号,机器抢购软件等多种形式来抢购秒杀商品,数量有限的秒杀商品往往在一瞬间被一抢而空,一般消费者却很难享受到秒杀商品的实惠。针对这样的业务场景,秒杀风控系统这把利剑也就顺势而出。
在实际的秒杀场景中,其特点是瞬间流量巨大。即便如此,“爆品抢购风控系统” 这把利剑对这种高并发、高流量的机器抢购行为显示出无穷的威力。目前,京东的集群运算能力能够到达每分钟上亿次并发请求处理和毫秒级实时计算的识别引擎能力,在秒杀行为中,可以阻拦 98% 以上的黄牛生成订单,最大限度地为正常用户提供公平的抢购机会。
3、商家反刷单系统
随着电商行业的不断发展,很多不轨商家尝试采用刷单、刷评价的方式来提升自己的搜索排名进而提高自家的商品销量。随着第三方卖家平台在京东的引入,一些商家也试图钻这个空子,我们对此类行为提出了 “零容忍” 原则,为了达到这个目标,商家反刷单系统也就应运而生。
商家反刷单系统利用京东自建的大数据平台,从订单、商品、用户、物流等多个维度进行分析,分别计算每个维度下面的不同特征值。通过发现商品的历史价格和订单实际价格的差异、商品 SKU 销量异常、物流配送异常、评价异常、用户购买品类异常等上百个特性,结合贝叶斯学习、数据挖掘、神经网络等多种智能算法进行精准定位。
而被系统识别到的疑似刷单行为,系统会通过后台离线算法,结合订单和用户的信息调用存储在大数据集市中的数据进行离线的深度挖掘和计算,继续进行识别,让其无所遁形。而对于这些被识别到的刷单行为,商家反刷单系统将直接把关联商家信息告知运营方做出严厉惩罚,以保证消费者良好的用户体验。
前端业务系统发展到今天,已经基本覆盖了交易环节的全流程,从各个维度打击各种侵害消费者利益的恶意行为。
2.1.4 后台支撑系统
天网作为京东的风控系统,每天都在应对不同特性的风险场景。它可能是每分钟数千万的恶意秒杀请求,也可能是遍布全球的黄牛新的刷单手段。天网是如何通过底层系统建设来解决这一个又一个的难题的呢?让我们来看一看天网的两大核心系统:风险信用服务(RCS)和 风控数据支撑系统(RDSS)。
1、风险信用服务(RCS)
风险信用服务(RCS)是埋藏在各个业务系统下的风控核心引擎,它既支持动态规则引擎的高效在线识别,又是打通沉淀数据和业务系统的桥梁。它是风控数据层对外提供服务的唯一途径,重要程度和性能压力不言而喻。
1.1、RCS 的服务框架
RCS 作为天网对外提供风控服务的唯一出口,其调用方式依赖于京东自主研发的服务架构框架 JSF,它帮助 RCS 在分布式架构下提供了高效 RPC 调用、高可用的注册中心和完备的容灾特性,同时支持黑白名单、负载均衡、Provider 动态分组、动态切换调用分组等服务治理功能。
面对每分钟千万级别的调用量,RCS 结合 JSF 的负载均衡、动态分组等功能,依据业务特性部署多个分布式集群,按分组提供服务。每个分组都做了跨机房部署,最大程度保障系统的高可用性。
1.2、RCS 动态规则引擎的识别原理
RCS 内部实现了一套自主研发的规则动态配置和解析的引擎,用户可以实时提交或者修改在线识别模型。当实时请求过来时,系统会将实时请求的数据依据模型里的核心特性按时间分片在一个高性能中间件中进行高性能统计,一旦模型中特性统计超过阀值时,前端风控系统将立刻进行拦截。
而前面我们所说的高性能中间件系统就是 JIMDB,它同样是自主研发的,主要功能是基于 Redis 的分布式缓存与高速 Key/Value 存储服务,采用 “Pre-Sharding” 技术,将缓存数据分摊到多个分片(每个分片上具有相同的构成,比如:都是一主一从两个节点)上,从而可以创建出大容量的缓存。支持读写分离、双写等 I/O 策略,支持动态扩容,还支持异步复制。在 RCS 的在线识别过程中起到了至关重要的作用
1.3、RCS 的数据流转步骤
风险库是 RCS 的核心组件,其中保存有各种维度的基础数据,下图是整个服务体系中的基本数据流转示意图:
[外链图片转存失败(img-mKoj0pjy-1562758075592)(https://s2.ax1x.com/2019/05/04/EatVeO.png)]
1)各个前端业务风控系统针对各个业务场景进行风险识别,其结果数据将回流至风险库用户后续离线分析及风险值判定。
2)风险库针对业务风控识别进过数据进行清洗,人工验证,定义并抽取风控指标数据,经过此道工序风险库的元数据可以做到基本可用。
3)后台数据挖掘工具对各来源数据,依据算法对各类数据进行权重计算,计算结果将用于后续的风险值计算。
4)风险信用服务一旦接收到风险值查询调用,将通过在 JIMDB 缓存云中实时读取用户的风控指标数据,结合权重配置,使用欧式距离计算得出风险等级值,为各业务风控系统提供实时服务。
1.4 RCS 的技术革新与规划
进入 2015 年以后,RCS 系统面临了巨大的挑战。首先,随着数据量的不断增大,之前的处理框架已无法继续满足需求,与此同时不断更新的恶意行为手段对风控的要求也越来越高,这也就要求风控系统不断增加针对性规则,这同样带来不不小的业务压力。
面对这样的挑战,RCS 更加密切地加强了和京东大数据平台的合作。在实时识别数据的存储方面,面对每天十几亿的识别流水信息,引入了 Kafka+Presto 的组合。通过 Presto 对缓存在 Kafka 一周之内的识别数据进行实时查询。超过 1 周的数据通过 ETL 写入 Presto 的 HDFS,支持历史查询。在 RCS 识别维度提升方面,目前已经与京东用户风险评分等级系统打通流程,目前已拿到超过 1 亿的基于社交网络维度计算的风险等级,用于风险信用识别。在风险等级的实时计算方面,已经逐步切换到大数据部基于 Strom 打造的流式计算计算平台 JRC。
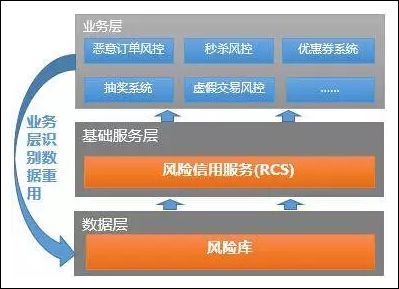
2.1.5 风控数据支撑系统
风控数据支撑系统是围绕着京东用户风险评分等级系统搭建起来的一整套风控数据挖掘体系。
1、RDSS 的核心架构
1)数据层
如图所示,数据层负责数据的抽取、清洗、预处理。目前 ETL 程序通过 JMQ、Kafka、数据集市、基础信息接口、日志接入了超过 500 个生产系统的业务数据,其中包括大量的非结构化数据。通过对数据的多样性、依赖性、不稳定性进行处理,最终输出完整的、一致性的风控指标数据,并通过数据接口提供给算法引擎层调用。这一层最关键的部分是在对风控指标数据的整理。指标数据质量的好坏直接关联到系统的最终输出结果。目前指标的整理主要从以下三个维度开展:
• a) 基于用户生命周期的指标数据整理
对于电商业务而言,一个普通用户基本上都会存在以下几种粘性状态,从尝试注册,到尝试购买;从被深度吸引,到逐渐理性消费。每一种状态总是伴随着一定的消费特征,而这些特征也将成为我们捕获用户异常行为的有利数据。
• b) 基于用户购买流程的风控指标数据整理
对于一般用户而说,其购买习惯具有相当的共性,例如,通常都会对自己需求的商品进行搜索,对搜索结果中自己感兴趣的品牌进行浏览比较,几经反复才最终做出购买决定。在真正购买之前还要找一下相关的优惠券,在支付过程中也会或多或少有些停顿。而对于黄牛来说,他们目标明确,登录之后直奔主题,爽快支付,这些在浏览行为上的差异也是我们寻找恶意用户的有利数据。
• c) 基于用户社交网络的风控指标数据整理
基于用户社交网络的指标数据是建立在当前风控领域的黑色产业链已经逐渐成体系的背景下的。往往那些不怀好意的用户总会在某些特征上有所聚集,这背后也就是一家家黄牛,刷单公司,通过这种方式可以实现一个抓出一串,个别找到同伙的效果。
2)算法引擎层
算法引擎层集合了各种数据挖掘算法,在系统内被分门别类的封装成各种常用的分类、聚类、关联、推荐等算法集,提供给分析引擎层进行调用。
3)分析引擎层
分析引擎层是风控数据分析师工作的主要平台,数据分析师可以在分析引擎层依据业务设立项目,并且在平台上开展数据挖掘全流程的工作,最终产出风控模型和识别规则。
4)决策引擎层
决策引擎层负责模型和规则的管理,所有系统产出的模型及规则都集合在这里进行统一管理更新。
5)应用层
应用层主要涵盖了决策引擎层产出模型和规则的应用场景,这里最重要的就是风险信用服务(RCS),其主要职能是对接底层数据,对外层业务风控系统提供风险识别服务。
而在模型和规则投入使用之前必须要经过我们另外一个重要的系统也就是风控数据分析平台(FBI),因为所有的模型和规则都先将在这个平台中进行评估,其输入就是所有规则和模型的产出数据,输出就是评估结果,评估结果也将反馈到决策引擎层来进行下一步的规则,模型优化。
2、RDSS 之用户风险评分等级系统
京东用户风险评分等级系统是天网数据挖掘体系孵化出的第一个数据项目。其主要目的在于将所有的京东用户进行分级,明确哪些是忠实用户,哪些又是需要重点关注的恶意用户。其实现原理是依赖前面所描述的社交关系网络去识别京东用户的风险程度。而这种方式在整个数据领域来说都是属于领先的。京东用户风险评分等级系统一期已经产出 1 亿数据,目前已经通过 RCS 系统对外提供服务。根据识别结果评估,识别忠实用户较 RCS 风险库增加 37%,识别的恶意用户较 RCS 风险库增加 10%。
目前,京东用户风险评分等级系统已经实现:
• 1)数据层基于社交网络的维度产出 50 余个风险指标。
• 2)通过 PageRank、三角形计数、连通图、社区发现等算法进行点、边定义,并识别出数十万个社区网络。
• 3)通过经典的加权网络上的能量传播思想,计算上亿用户的风险指数。
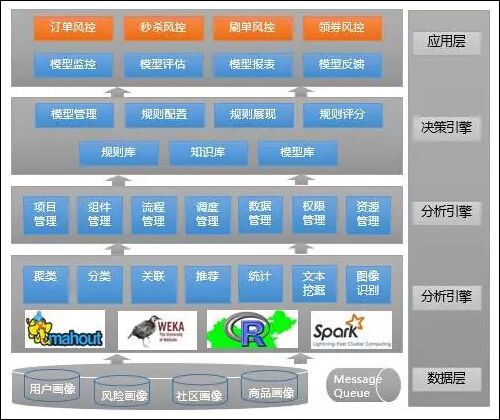
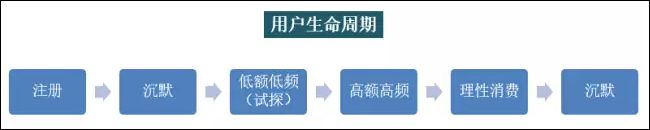
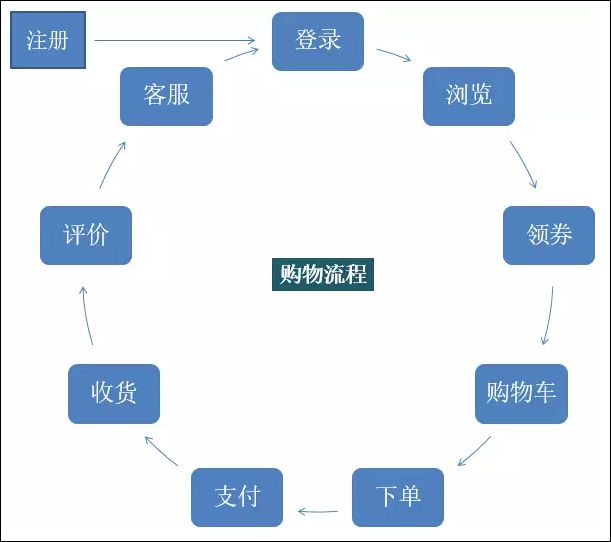

2.2 Spark 在美团的实践
2.2.1 应用需求
美团是数据驱动的互联网服务,用户每天在美团上的点击、浏览、下单支付行为都会产生海量的日志,这些日志数据将被汇总处理、分析、挖掘与学习,为美团的各种推荐、搜索系统甚至公司战略目标制定提供数据支持。大数据处理渗透到了美团各业务线的各种应用场景,选择合适、高效的数据处理引擎能够大大提高数据生产的效率,进而间接或直接提升相关团队的工作效率。
美团最初的数据处理以 Hive SQL 为主,底层计算引擎为 MapReduce,部分相对复杂的业务会由工程师编写 MapReduce 程序实现。随着业务的发展,单纯的 Hive SQL 查询或者 MapReduce 程序已经越来越难以满足数据处理和分析的需求。
一方面,MapReduce 计算模型对多轮迭代的 DAG 作业支持不给力,每轮迭代都需要将数据落盘,极大地影响了作业执行效率,另外只提供 Map 和 Reduce 这两种计算因子,使得用户在实现迭代式计算(比如:机器学习算法)时成本高且效率低。
另一方面,在数据仓库的按天生产中,由于某些原始日志是半结构化或者非结构化数据,因此,对其进行清洗和转换操作时,需要结合 SQL 查询以及复杂的过程式逻辑处理,这部分工作之前是由 Hive SQL 结合 Python 脚本来完成。这种方式存在效率问题,当数据量比较大的时候,流程的运行时间较长,这些 ETL 流程通常处于比较上游的位置,会直接影响到一系列下游的完成时间以及各种重要数据报表的生成。
基于以上原因,美团在 2014 年的时候引入了 Spark。为了充分利用现有 Hadoop 集群的资源,我们采用了 Spark on Yarn 模式,所有的 Spark app 以及 MapReduce 作业会通过 Yarn 统一调度执行。Spark 在美团数据平台架构中的位置如图所示:
经过近两年的推广和发展,从最开始只有少数团队尝试用 Spark 解决数据处理、机器学习等问题,到现在已经覆盖了美团各大业务线的各种应用场景。从上游的 ETL 生产,到下游的 SQL 查询分析以及机器学习等,Spark 正在逐步替代 MapReduce 作业,成为美团大数据处理的主流计算引擎。目前美团 Hadoop 集群用户每天提交的 Spark 作业数和 MapReduce 作业数比例为4:1,对于一些上游的 Hive ETL 流程,迁移到 Spark 之后,在相同的资源使用情况下,作业执行速度提升了十倍,极大地提升了业务方的生产效率。
下面我们将介绍 Spark 在美团的实践,包括我们基于 Spark 所做的平台化工作以及 Spark 在生产环境下的应用案例。其中包含 Zeppelin 结合的交互式开发平台,也有使用 Spark 任务完成的 ETL 数据转换工具,数据挖掘组基于 Spark 开发了特征平台和数据挖掘平台,另外还有基于 Spark 的交互式用户行为分析系统以及在 SEM 投放服务中的应用,以下是详细介绍。
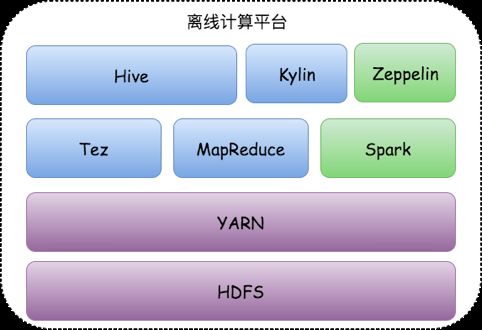
2.2.2 Spark 交互式开发平台
在推广如何使用 Spark 的过程中,我们总结了用户开发应用的主要需求:
数据调研:在正式开发程序之前,首先需要认识待处理的业务数据,包括:数据格式,类型(若以表结构存储则对应到字段类型)、存储方式、有无脏数据,甚至分析根据业务逻辑实现是否可能存在数据倾斜等等。这个需求十分基础且重要,只有对数据有充分的掌控,才能写出高效的 Spark 代码。
代码调试:业务的编码实现很难保证一蹴而就,可能需要不断地调试;如果每次少量的修改,测试代码都需要经过编译、打包、提交线上,会对用户的开发效率影响是非常大的。
联合开发:对于一整个业务的实现,一般会有多方的协作,这时候需要能有一个方便的代码和执行结果共享的途径,用于分享各自的想法和试验结论。
基于这些需求,我们调研了现有的开源系统,最终选择了 Apache 的孵化项目 Zeppelin,将其作为基于 Spark 的交互式开发平台。Zeppelin 整合了 Spark、Markdown、Shell、Angular 等引擎,集成了数据分析和可视化等功能。
我们在原生的 Zeppelin 上增加了用户登陆认证、用户行为日志审计、权限管理以及执行 Spark 作业资源隔离,打造了一个美团的 Spark 的交互式开发平台,不同的用户可以在该平台上调研数据、调试程序、共享代码和结论。
集成在 Zeppelin 的 Spark 提供了三种解释器:Spark、Pyspark、SQL,分别适用于编写 Scala、Python、SQL 代码。对于上述的数据调研需求,无论是程序设计之初,还是编码实现过程中,当需要检索数据信息时,通过 Zeppelin 提供的 SQL 接口可以很便利的获取到分析结果;另外,Zeppelin 中 Scala 和 Python 解释器自身的交互式特性满足了用户对 Spark 和 Pyspark 分步调试的需求,同时由于 Zeppelin 可以直接连接线上集群,因此可以满足用户对线上数据的读写处理请求;最后,Zeppelin 使用 Web Socket 通信,用户只需要简单地发送要分享内容所在的 http 链接,所有接受者就可以同步感知代码修改,运行结果等,实现多个开发者协同工作。
2.2.3 Spark 作业 ETL 模板
除了提供平台化的工具以外,我们也会从其他方面来提高用户的开发效率,比如将类似的需求进行封装,提供一个统一的 ETL 模板,让用户可以很方便的使用 Spark 实现业务需求。
美团目前的数据生产主体是通过 ETL 将原始的日志通过清洗、转换等步骤后加载到 Hive 表中。而很多线上业务需要将 Hive 表里面的数据以一定的规则组成键值对,导入到 Tair 中,用于上层应用快速访问。其中大部分的需求逻辑相同,即把 Hive 表中几个指定字段的值按一定的规则拼接成 key 值,另外几个字段的值以 json 字符串的形式作为 value 值,最后将得到的对写入 Tair。
由于 Hive 表中的数据量一般较大,使用单机程序读取数据和写入 Tair 效率比较低,因此部分业务方决定使用 Spark 来实现这套逻辑。最初由业务方的工程师各自用 Spark 程序实现从 Hive 读数据,写入到 Tair 中(以下简称 hive2Tair 流程),这种情况下存在如下问题:
每个业务方都要自己实现一套逻辑类似的流程,产生大量重复的开发工作。
由于 Spark 是分布式的计算引擎,因此代码实现和参数设置不当很容易对 Tair 集群造成巨大压力,影响 Tair 的正常服务。
基于以上原因,我们开发了 Spark 版的 hive2Tair 流程,并将其封装成一个标准的 ETL 模板,其格式和内容如下所示:
source 用于指定 Hive 表源数据,target 指定目标 Tair 的库和表,这两个参数可以用于调度系统解析该 ETL 的上下游依赖关系,从而很方便地加入到现有的 ETL 生产体系中。
有了这个模板,用户只需要填写一些基本的信息(包括 Hive 表来源,组成 key 的字段列表,组成 value 的字段列表,目标 Tair 集群)即可生成一个 hive2Tair 的 ETL 流程。整个流程生成过程不需要任何 Spark 基础,也不需要做任何的代码开发,极大地降低了用户的使用门槛,避免了重复开发,提高了开发效率。该流程执行时会自动生成一个 Spark 作业,以相对保守的参数运行:默认开启动态资源分配,每个 Executor 核数为 2,内存 2GB,最大 Executor 数设置为 100。如果对于性能有很高的要求,并且申请的 Tair 集群比较大,那么可以使用一些调优参数来提升写入的性能。目前我们仅对用户暴露了设置 Executor 数量以及每个 Executor 内存的接口,并且设置了一个相对安全的最大值规定,避免由于参数设置不合理给 Hadoop 集群以及 Tair 集群造成异常压力。

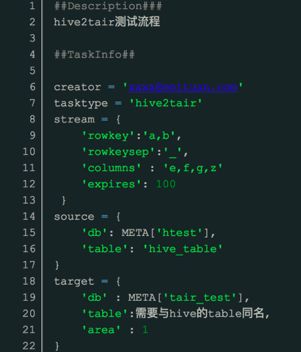
2.2.4 基于 Spark 的用户特征平台
在没有特征平台之前,各个数据挖掘人员按照各自项目的需求提取用户特征数据,主要是通过美团的 ETL 调度平台按月/天来完成数据的提取。
但从用户特征来看,其实会有很多的重复工作,不同的项目需要的用户特征其实有很多是一样的,为了减少冗余的提取工作,也为了节省计算资源,建立特征平台的需求随之诞生,特征平台只需要聚合各个开发人员已经提取的特征数据,并提供给其他人使用。特征平台主要使用 Spark 的批处理功能来完成数据的提取和聚合。
开发人员提取特征主要还是通过 ETL 来完成,有些数据使用 Spark 来处理,比如用户搜索关键词的统计。
开发人员提供的特征数据,需要按照平台提供的配置文件格式添加到特征库,比如在图团购的配置文件中,团购业务中有一个用户 24 小时时段支付的次数特征,输入就是一个生成好的特征表,开发人员通过测试验证无误之后,即完成了数据上线;另外对于有些特征,只需要从现有的表中提取部分特征数据,开发人员也只需要简单的配置即可完成。
在图中,我们可以看到特征聚合分两层,第一层是各个业务数据内部聚合,比如团购的数据配置文件中会有很多的团购特征、购买、浏览等分散在不同的表中,每个业务都会有独立的 Spark 任务来完成聚合,构成一个用户团购特征表;特征聚合是一个典型的 join 任务,对比 MapReduce 性能提升了 10 倍左右。第二层是把各个业务表数据再进行一次聚合,生成最终的用户特征数据表。
特征库中的特征是可视化的,我们在聚合特征时就会统计特征覆盖的人数,特征的最大最小数值等,然后同步到 RDB,这样管理人员和开发者都能通过可视化来直观地了解特征。 另外,我们还提供特征监测和告警,使用最近 7 天的特征统计数据,对比各个特征昨天和今天的覆盖人数,是增多了还是减少了,比如性别为女这个特征的覆盖人数,如果发现今天的覆盖人数比昨天低了 1%(比如昨天 6 亿用户,女性 2 亿,那么人数降低了 1%* 2亿 = 2百万)突然减少 2 万女性用户说明数据出现了极大的异常,何况网站的用户数每天都是增长的。这些异常都会通过邮件发送到平台和特征提取的相关人。
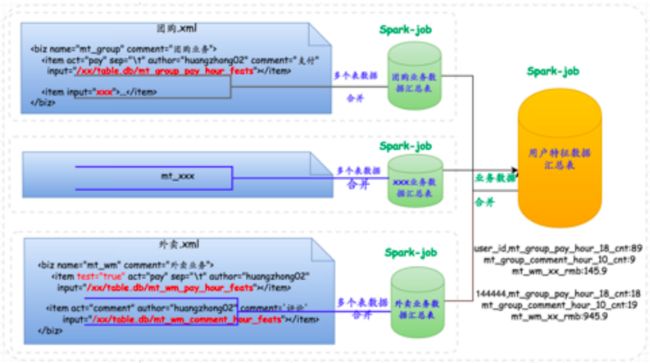
2.2.5 Spark 数据挖掘平台
数据挖掘平台是完全依赖于用户特征库的,通过特征库提供用户特征,数据挖掘平台对特征进行转换并统一格式输出,就此开发人员可以快速完成模型的开发和迭代,之前需要两周开发一个模型,现在短则需要几个小时,多则几天就能完成。特征的转换包括特征名称的编码,也包括特征值的平滑和归一化,平台也提供特征离散化和特征选择的功能,这些都是使用 Spark 离线完成。
开发人员拿到训练样本之后,可以使用 Spark mllib 或者 Python sklearn 等完成模型训练,得到最优化模型之后,将模型保存为平台定义好的模型存储格式,并提供相关配置参数,通过平台即可完成模型上线,模型可以按天或者按周进行调度。当然如果模型需要重新训练或者其它调整,那么开发者还可以把模型下线。不只如此,平台还提供了一个模型准确率告警的功能,每次模型在预测完成之后,会计算用户提供的样本中预测的准确率,并比较开发者提供的准确率告警阈值,如果低于阈值则发邮件通知开发者,是否需要对模型重新训练。
在开发挖掘平台的模型预测功时能我们走了点弯路,平台的模型预测功能开始是兼容 Spark 接口的,也就是使用 Spark 保存和加载模型文件并预测,使用过的人知道 Spark mllib 的很多 API 都是私有的开发人员无法直接使用,所以我们这些接口进行封装然后再提供给开发者使用,但也只解决了 Spark 开发人员的问题,平台还需要兼容其他平台的模型输出和加载以及预测的功能,这让我们面临必需维护一个模型多个接口的问题,开发和维护成本都较高,最后还是放弃了兼容 Spark 接口的实现方式,我们自己定义了模型的保存格式,以及模型加载和模型预测的功能。
以上内容介绍了美团基于 Spark 所做的平台化工作,这些平台和工具是面向全公司所有业务线服务的,旨在避免各团队做无意义的重复性工作,以及提高公司整体的数据生产效率。目前看来效果是比较好的,这些平台和工具在公司内部得到了广泛的认可和应用,当然也有不少的建议,推动我们持续地优化。
随着 Spark 的发展和推广,从上游的 ETL 到下游的日常数据统计分析、推荐和搜索系统,越来越多的业务线开始尝试使用 Spark 进行各种复杂的数据处理和分析工作。下面将以 Spark 在交互式用户行为分析系统以及 SEM 投放服务为例,介绍 Spark 在美团实际业务生产环境下的应用。

2.2.6 Spark 在交互式用户行为分析系统中的实践
美团的交互式用户行为分析系统,用于提供对海量的流量数据进行交互式分析的功能,系统的主要用户为公司内部的 PM 和运营人员。普通的 BI 类报表系统,只能够提供对聚合后的指标进行查询,比如 PV、UV 等相关指标。但是 PM 以及运营人员除了查看一些聚合指标以外,还需要根据自己的需求去分析某一类用户的流量数据,进而了解各种用户群体在 App 上的行为轨迹。根据这些数据,PM 可以优化产品设计,运营人员可以为自己的运营工作提供数据支持,用户核心的几个诉求包括:
自助查询:不同的 PM 或运营人员可能随时需要执行各种各样的分析功能,因此系统需要支持用户自助使用。
响应速度:大部分分析功能都必须在几分钟内完成。
可视化:可以通过可视化的方式查看分析结果。
要解决上面的几个问题,技术人员需要解决以下两个核心问题:
海量数据的处理:用户的流量数据全部存储在 Hive 中,数据量非常庞大,每天的数据量都在数十亿的规模。
快速计算结果:系统需要能够随时接收用户提交的分析任务,并在几分钟之内计算出他们想要的结果。
要解决上面两个问题,目前可供选择的技术主要有两种:MapReduce 和 Spark。在初期架构中选择了使用 MapReduce 这种较为成熟的技术,但是通过测试发现,基于 MapReduce 开发的复杂分析任务需要数小时才能完成,这会造成极差的用户体验,用户无法接受。
因此我们尝试使用 Spark 这种内存式的快速大数据计算引擎作为系统架构中的核心部分,主要使用了 Spark Core 以及 Spark SQL 两个组件,来实现各种复杂的业务逻辑。实践中发现,虽然 Spark 的性能非常优秀,但是在目前的发展阶段中,还是或多或少会有一些性能以及 OOM 方面的问题。因此在项目的开发过程中,对大量 Spark 作业进行了各种各样的性能调优,包括算子调优、参数调优、shuffle 调优以及数据倾斜调优等,最终实现了所有 Spark 作业的执行时间都在数分钟左右。并且在实践中解决了一些 shuffle 以及数据倾斜导致的 OOM 问题,保证了系统的稳定性。
结合上述分析,最终的系统架构与工作流程如下所示:
用户在系统界面中选择某个分析功能对应的菜单,并进入对应的任务创建界面,然后选择筛选条件和任务参数,并提交任务。
由于系统需要满足不同类别的用户行为分析功能(目前系统中已经提供了十个以上分析功能),因此需要为每一种分析功能都开发一个 Spark 作业。
采用 J2EE 技术开发了 Web 服务作为后台系统,在接收到用户提交的任务之后,根据任务类型选择其对应的 Spark 作业,启动一条子线程来执行 spark-submit 命令以提交 Spark 作业。
Spark 作业运行在 Yarn 集群上,并针对 Hive 中的海量数据进行计算,最终将计算结果写入数据库中。
用户通过系统界面查看任务分析结果,J2EE 系统负责将数据库中的计算结果返回给界面进行展现。
该系统上线后效果良好:90% 的 Spark 作业运行时间都在 5 分钟以内,剩下 10% 的 Spark 作业运行时间在 30 分钟左右,该速度足以快速响应用户的分析需求。通过反馈来看,用户体验非常良好。目前每个月该系统都要执行数百个用户行为分析任务,有效并且快速地支持了 PM 和运营人员的各种分析需求。

2.2.7 Spark 在 SEM 投放服务中的应用
流量技术组负责着美团站外广告的投放技术,目前在 SEM、SEO、DSP 等多种业务中大量使用了 Spark 平台,包括离线挖掘、模型训练、流数据处理等。美团 SEM(搜索引擎营销)投放着上亿的关键词,一个关键词从被挖掘策略发现开始,就踏上了精彩的 SEM 之旅。它经过预估模型的筛选,投放到各大搜索引擎,可能因为市场竞争频繁调价,也可能因为效果不佳被迫下线。而这样的旅行,在美团每分钟都在发生。如此大规模的随机 “迁徙” 能够顺利进行,Spark 功不可没。
Spark 不止用于美团 SEM 的关键词挖掘、预估模型训练、投放效果统计等大家能想到的场景,还罕见地用于关键词的投放服务,这也是本段介绍的重点。一个快速稳定的投放系统是精准营销的基础。
美团早期的 SEM 投放服务采用的是单机版架构,随着关键词数量的极速增长,旧有服务存在的问题逐渐暴露。受限于各大搜索引擎 API 的配额(请求频次)、账户结构等规则,投放服务只负责处理 API 请求是远远不够的,还需要处理大量业务逻辑。单机程序在小数据量的情况下还能通过多进程勉强应对,但对于如此大规模的投放需求,就很难做到 “兼顾全局” 了。
新版 SEM 投放服务在 15 年 Q2 上线,内部开发代号为 Medusa。在 Spark 平台上搭建的 Medusa,全面发挥了 Spark 大数据处理的优势,提供了高性能高可用的分布式 SEM 投放服务,具有以下几个特性:
低门槛:Medusa 整体架构的设计思路是提供数据库一样的服务。在接口层,让 RD 可以像操作本地数据库一样,通过 SQL 来 “增删改查” 线上关键词表,并且只需要关心自己的策略标签,不需要关注关键词的物理存储位置。Medusa 利用 Spark SQL 作为服务的接口,提高了服务的易用性,也规范了数据存储,可同时对其他服务提供数据支持。基于 Spark 开发分布式投放系统,还可以让 RD 从系统层细节中解放出来,全部代码只有 400 行。
高性能、可伸缩:为了达到投放的“时间”、“空间” 最优化,Medusa 利用 Spark 预计算出每一个关键词在远程账户中的最佳存储位置,每一次 API 请求的最佳时间内容。在配额和账号容量有限的情况下,轻松掌控着亿级的在线关键词投放。通过控制 Executor 数量实现了投放性能的可扩展,并在实战中做到了全渠道 4 小时全量回滚。
高可用:有的同学或许会有疑问:API 请求适合放到 Spark 中做吗?因为函数式编程要求函数是没有副作用的纯函数(输入是确定的,输出就是确定的)。这确实是一个问题,Medusa 的思路是把请求 API 封装成独立的模块,让模块尽量做到“纯函数”的无副作用特性,并参考面向轨道编程的思路,将全部请求 log 重新返回给 Spark 继续处理,最终落到 Hive,以此保证投放的成功率。为了更精准的控制配额消耗,Medusa 没有引入单次请求重试机制,并制定了服务降级方案,以极低的数据丢失率,完整地记录了每一个关键词的旅行。

2.3 数据处理平台架构中的 SMACK 组合:Spark、Mesos、Akka、Cassandra 以及 Kafka
2.3.1 综述

1、Spark – 一套高速通用型引擎,用于实现分布式大规模数据处理任务。
2、Mesos – 集群资源管理系统,能够立足于分布式应用程序提供行之有效的资源隔离与共享能力。
3、Akka – 一套用于在 JVM 之上构建高并发、分布式及弹性消息驱动型应用程序的工具包与运行时。
4、Cassandra – 一套分布式高可用性数据库,旨在跨越多座数据中心处理大规模数据。
5、Kafka – 一套高吞吐能力、低延迟、分布式消息收发系统/提交日志方案,旨在处理实时数据供给。
2.3.2 存储层:Cassandra
Cassandra 一直以其高可用性与高吞吐能力两大特性而备受瞩目,其同时能够处理极为可观的写入负载并具备节点故障容错能力。以 CAP 原则为基础,Cassandra 能够为业务运营提供可调整的一致性/可用性水平。
更有趣的是,Cassandra 在处理数据时拥有线性可扩展能力(即可通过向集群当中添加节点的方式实现负载增容)并能够提供跨数据中心复制(简称 XDCR)能力。事实上,跨数据中心复制功能除了数据复制,同时也能够实现以下各类扩展用例:
• 1)地理分布式数据中心处理面向特定区域或者客户周边位置数据。
• 2)在不同数据中心之间者数据迁移,从而实现故障后恢复或者将数据移动至新数据中心。
• 3)对运营工作负载与分析工作负载加以拆分。
但上述特性也都有着自己的实现成本,而对于 Cassandra 而言这种成本体现为数据模型——这意味着我们需要通过聚类对分区键及入口进行分组/分类,从而实现嵌套有序映射。以下为简单示例:
为了获取某一范围内的特定数据,我们必须指定全键,且不允许除列表内最后一列之外的其它任何范围划定得以执行。这种限制用于针对不同范围进行多重扫描限定,否则其可能带来随机磁盘访问并拖慢整体性能表现。这意味着该数据模型必须根据读取查询进行认真设计,从而限制读取/扫描量——但这同时也会导致对新查询的支持灵活性有所下降。
那么如果我们需要将某些表加入到其它表当中,又该如何处理?让我们考虑下一种场景:针对特定月份对全部活动进行总体访问量计算。
在特定模型之下,实现这一目标的惟一办法就是读取全部活动、读取全部事件、汇总各属性值(其与活动id相匹配)并将其分配给活动。实现这类应用程序操作显然极具挑战,因为保存在 Casandra 中的数据总量往往非常庞大,内存容量根本不足以加以容纳。因此我们必须以分布式方式对此类数据加以处理,而 Spark 在这类用例中将发挥重要作用。
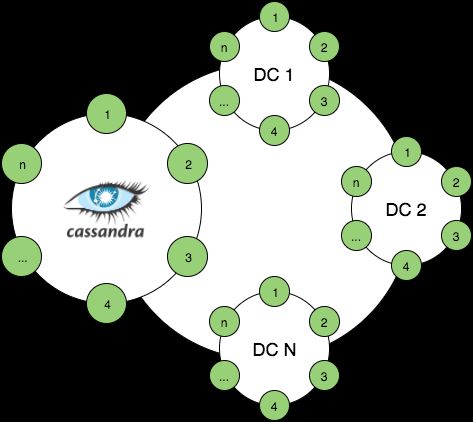
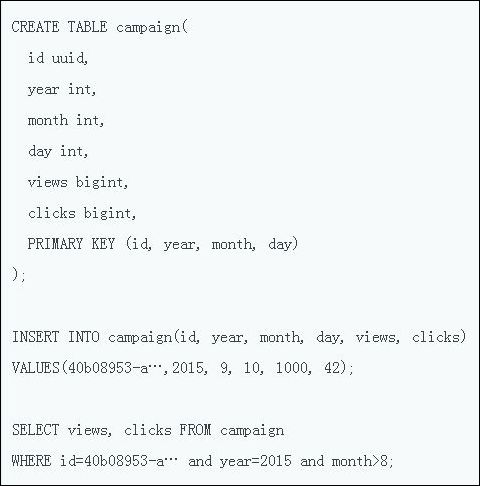

2.3.3 处理层:Spark
Spark 的抽象核心主要涉及 RDD(即弹性分布式数据集,一套分布式元素集合)以及由以下四个主要阶段构成的工作流:
• 1)RDD 操作(转换与操作)以 DAG(即有向无环图)形式进行
• 2)DAG 会根据各任务阶段进行拆分,并随后被提交至集群管理器
• 3)各阶段无需混洗/重新分配即可与任务相结合
• 4)任务运行在工作程序之上,而结果随后返回至客户端
以下为我们如何利用 Spark 与 Cassandra 解决上述问题:
指向 Cassandra 的交互通过 Spark-Cassandra-连接器负责执行,其能够让整个流程变得更为直观且简便。另有一个非常有趣的选项能够帮助大家实现对 NoSQL 存储内容的交互–SparkSQL,其能够将 SQL 语句翻译成一系列 RDD 操作。
通过几行代码,我们已经能够实现原生 Lambda 设计——其复杂度显然较高,但这一示例表明大家完全有能力以简单方式实现既定功能。


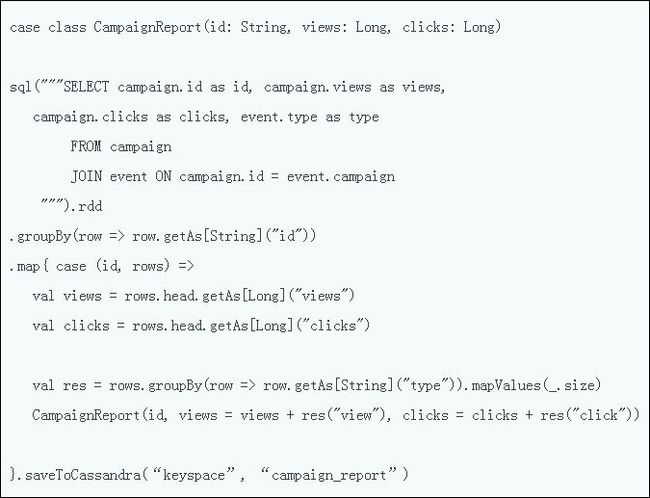
类 MapReduce 解决方案:拉近处理与数据间的距离
Spark-Cassandra 连接器拥有数据位置识别能力,并会从集群内距离最近的节点处读取数据,从而最大程度降低数据在网络中的传输需求。为了充分发挥 Spark-C*连接器的数据位置识别能力,大家应当让 Spark 工作程序与 Cassandra 节点并行协作。
除了 Spark 与 Cassandra 的协作之外,我们也有理由将运营(或者高写入强度)集群同分析集群区分开来,从而保证:
• 1)不同集群能够独立进行规模伸缩
• 2)数据由 Cassandra 负责复制,而无需其它机制介入
• 3)分析集群拥有不同的读取/写入负载模式
• 4)分析集群能够容纳额外数据(例如词典)与处理结果
• 5)Spark 对资源的影响只局限于单一集群当中
下面让我们再次回顾 Spark 的应用程序部署选项:
目前我们拥有三种主要集群资源管理器选项可供选择:
• 1)单独使用 Spark–Spark 作为主体,各工作程序以独立应用程序的形式安装并执行(这明显会增加额外资源负担,且只支持为每工作程序分配静态资源)。
• 2)如果大家已经拥有 Hadoop 生态系统,那么 YARN 绝对是个不错的选项。
• 3)Mesos 自诞生之初就在设计中考虑到对集群资源的动态分配,而且除了 Hadoop 应用程序之外,同时也适合处理各类异构工作负载。

2.3.4 Mesos 架构
Mesos 集群由各主节点构成,它们负责资源供应与调度,而各从节点则实际承担任务执行负载。在 HA 模式当中,我们利用多个主 ZooKeeper 节点负责进行主节点选择与服务发现。Mesos 之上执行的各应用程序被称为 “框架(Framework)”,并利用 API 处理资源供应及将任务提交至 Mesos。总体来讲,其任务执行流程由以下几个步骤构成:
• 1)从节点为主节点提供可用资源
• 2)主节点向框架发送资源供应
• 3)调度程序回应这些任务及每任务资源需求
• 4)主节点将任务发送至从节点

2.3.5 将 Spark、Mesos 以及 Cassandra 加以结合
正如之前所提到,Spark 工作程序应当与 Cassandra 节点协作,从而实现数据位置识别能力以降低网络流量与 Cassandra 集群负载。下图所示为利用 Mesos 实现这一目标的可行部署场景示例:
1)Mesos 主节点与 ZooKeeper 协作
2)Mesos 从节点与 Cassandra 节点协作,从而为 Spark 提供更理想的数据位置
3)Spark 二进制文件部署至全部工作节点当中,而 spark-env.sh 则配置以合适的主端点及执行器 jar 位置
4)Spark 执行器 JAR 被上传至 S3/HDFS 当中
根据以上设置流程 Spark 任务可利用简单的 spark-submit 调用从任意安装有 Spark 二进制文件并上传有包含实际任务逻辑jar的工作节点被提交至集群中。
由于现有选项已经能够运行Docker化Spark,因此我们不必将二进制文件分发至每个单一集群节点当中。

2.3.6 定期与长期运行任务之执行机制
每套数据处理系统迟早都要面对两种必不可少的任务运行类别:定期批量汇聚型定期/阶段性任务以及以数据流处理为代表的长期任务。这两类任务的一大主要要求在于容错能力——各任务必须始终保持运行,即使集群节点发生故障。Mesos 提供两套出色的框架以分别支持这两种任务类别。
Marathon 是一套专门用于实现长期运行任务高容错性的架构,且支持与 ZooKeeper 相配合之 HA 模式。其能够运行 Docker 并提供出色的 REST API。以下 shell 命令示例为通过运行 spark-submit 实现简单任务配置:
Chronos 拥有与 Marathon 相同的特性,但其设计目标在于运行定期任务,而且总体而言其分布式 HA cron 支持任务图谱。以下示例为利用简单的 bash 脚本实现 S3 压缩任务配置:
目前已经有多种框架方案可供选择,或者正处于积极开发当中以对接各类系统中所广泛采用的Mesos资源管理功能。下面列举其中一部分典型代表:
• 1)Hadoop
• 2)Cassandra
• 3)Kafka
• 4)Myriad : YARN on Mesos
• 5)Storm
• 6)Samza


2.3.7 数据提取
到目前为止可谓一切顺利:存储层已经设计完成,资源管理机制设置妥当,而各任务亦经过配置。接下来惟一要做的就是数据处理工作了。
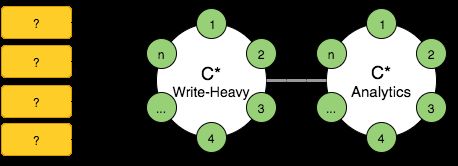
假定输入数据将以极高速率涌来,这时端点要顺利应对就需要满足以下要求:
1)提供高吞吐能力/低延迟。
2)具备弹性。
3)可轻松实现规模扩展。
4)支持背压。
背压能力并非必需,不过将其作为选项来应对负载峰值是个不错的选择。Akka 能够完美支持以上要求,而且基本上其设计目标恰好是提供这套功能集。
下面来看 Akka 的特性:
1)JVM面向JVM的角色模型实现能力。
2)基于消息且支持异步架构。
3)强制执行非共享可变状态。
4)可轻松由单一进程扩展至设备集群。
5)利用自上而下之监督机制实现角色层级。
6)不仅是并发框架:akka-http、akka-stream 以及 akka-persistence。
以下简要示例展示了三个负责处理 JSON HttpRequest 的角色,它们将该请求解析为域模型例类,并将其保存在 Cassandra 当中:
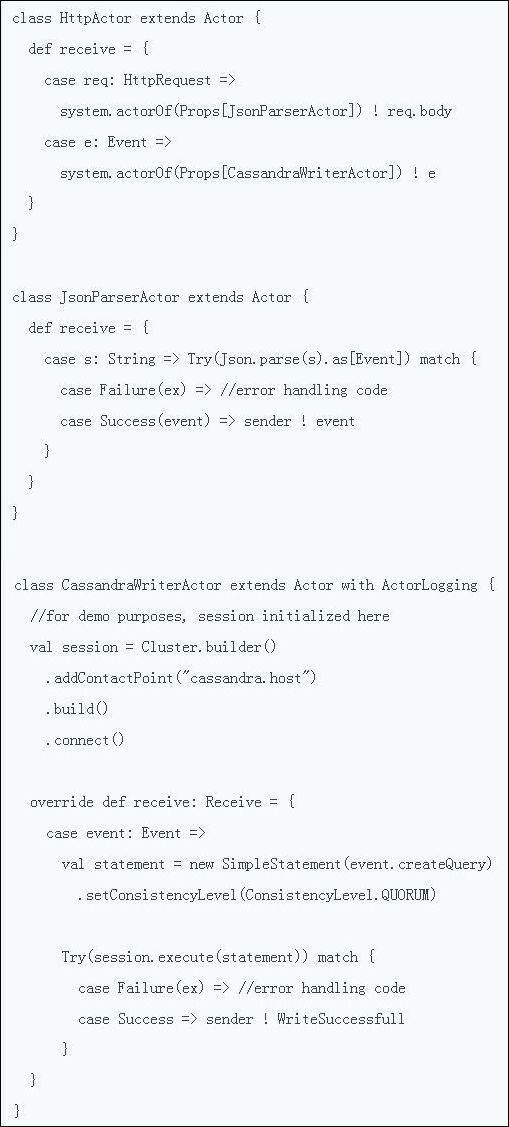
看起来只需几行代码即可实现上述目标,不过利用Akka向Cassandra当中写入原始数据(即事件)却有可能带来以下问题:
1)Cassandra 的设计思路仍然偏重高速交付而非批量处理,因此必须对输入数据进行预汇聚。
2)汇聚/汇总所带来的计算时间会随着数据总量的增长而逐步加长。
3)由于采用无状态设计模式,各角色并不适合用于执行汇聚任务。
4)微批量机制能够在一定程度上解决这个难题。
5)仍然需要为原始数据提供某种可靠的缓冲机制。
2.3.8 Kafka 充当输入数据之缓冲机制
为了保留输入数据并对其进行预汇聚/处理,我们也可以使用某种类型的分布式提交日志机制。在以下用例中,消费程序将批量读取数据,对其进行处理并将其以预汇聚形式保存在 Cassandra 当中。该示例说明了如何利用 akka-http 通过 HTTP 将 JSON 数据发布至 Kafka 当中:


2.3.9 数据消费:Spark Streaming
尽管 Akka 也能够用于消耗来自 Kafka 的流数据,但将 Spark 纳入生态系统以引入 Spark Streaming 能够切实解决以下难题:
1)其支持多种数据源。
2)提供 “至少一次” 语义。
3)可在配合 Kafka Direct 与幂等存储实现 “仅一次” 语义。
以下代码示例阐述了如何利用 Spark Streaming 消费来自 Kinesis 的事件流:


2.3.10 故障设计:备份与补丁安装
通常来讲,故障设计是任何系统当中最为枯燥的部分,但其重要性显然不容质疑–当数据中心不可用或者需要对崩溃状况加以分析时,尽可能保障数据免于丢失可谓至关重要。
那么为什么要将数据存储在 Kafka/Kinesis 当中?截至目前,Kinesis 仍然是惟一在无需备份的情况下能够确保全部处理结果丢失后保留数据的解决方案。虽然 Kafka 也能够支持数据长期保留,但硬件持有成本仍是个需要认真考虑的问题,因为 S3 存储服务的使用成本要远低于支持 Kafka 所需要的大量实例,另外,S3 也提供非常理想的服务水平协议。
除了备份能力,恢复/补丁安装策略还应当考虑到前期与测试需求,从而保证任何与数据相关的问题能够得到迅速解决。程序员们在汇聚任务或者重复数据删除操作中可能不慎破坏计算结果,因此修复这类错误的能力就变得非常关键。简化这类操作任务的一种简便方式在于在数据模型当中引入幂等机制,这样同一操作的多次重复将产生相同的结果(例如 SQL 更新属于幂等操作,而计数递增则不属于)。
以下示例为 Spark 任务读取 S3 备份并将其载入至 Cassandra:
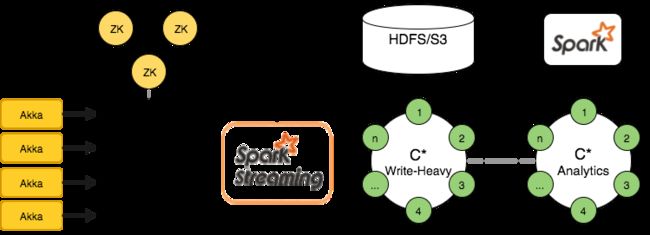

2.3.11 宏观构成
利用 SMACK 构建数据平台顶层设计:
纵观全文,SMACK 堆栈的卓越能力包括:
1)简明的工具储备以解决范围极广的各类数据处理场景
2)软件方案久经考验且拥有广泛普及度,背后亦具备强大的技术社区
3)易于实现规模伸缩与数据复制,且提供较低延迟水平
4)统一化集群管理以实现异构负载
5)可面向任意应用程序类型的单一平台
6)面向不同架构设计(批量、流数据、Lambda、Kappa)的实现平台
7)出色的产品发布速度(例如用于 MVP 验证)
2.4 大数据架构选择
2.4.1 简介
大数据是收集、整理、处理大容量数据集,并从中获得见解所需的非传统战略和技术的总称。虽然处理数据所需的计算能力或存储容量早已超过一台计算机的上限,但这种计算类型的普遍性、规模,以及价值在最近几年才经历了大规模扩展。
处理框架负责对系统中的数据进行计算,例如处理从非易失存储中读取的数据,或处理刚刚摄入到系统中的数据。数据的计算则是指从大量单一数据点中提取信息和见解的过程。
那么框架有很多,该如何选择呢?下文将介绍这些框架:
仅批处理框架:
Apache Hadoop
仅流处理框架:
Apache Storm
Apache Samza
混合框架:
Apache Spark
Apache Flink
2.4.2 大数据处理框架是什么?
处理框架和处理引擎负责对数据系统中的数据进行计算。虽然 “引擎” 和 “框架” 之间的区别没有什么权威的定义,但大部分时候可以将前者定义为实际负责处理数据操作的组件,后者则可定义为承担类似作用的一系列组件。
例如 Apache Hadoop 可以看作一种以 MapReduce 作为默认处理引擎的处理框架。引擎和框架通常可以相互替换或同时使用。例如另一个框架 Apache Spark 可以纳入 Hadoop 并取代 MapReduce。组件之间的这种互操作性是大数据系统灵活性如此之高的原因之一。
虽然负责处理生命周期内这一阶段数据的系统通常都很复杂,但从广义层面来看它们的目标是非常一致的:通过对数据执行操作提高理解能力,揭示出数据蕴含的模式,并针对复杂互动获得见解。
为了简化这些组件的讨论,我们会通过不同处理框架的设计意图,按照所处理的数据状态对其进行分类。一些系统可以用批处理方式处理数据,一些系统可以用流方式处理连续不断流入系统的数据。此外还有一些系统可以同时处理这两类数据。
在深入介绍不同实现的指标和结论之前,首先需要对不同处理类型的概念进行一个简单的介绍。
2.4.3 批处理系统
批处理在大数据世界有着悠久的历史。批处理主要操作大容量静态数据集,并在计算过程完成后返回结果。
批处理模式中使用的数据集通常符合下列特征…
1、有界:批处理数据集代表数据的有限集合
2、持久:数据通常始终存储在某种类型的持久存储位置中
3、大量:批处理操作通常是处理极为海量数据集的唯一方法
批处理非常适合需要访问全套记录才能完成的计算工作。例如在计算总数和平均数时,必须将数据集作为一个整体加以处理,而不能将其视作多条记录的集合。这些操作要求在计算进行过程中数据维持自己的状态。
需要处理大量数据的任务通常最适合用批处理操作进行处理。无论直接从持久存储设备处理数据集,或首先将数据集载入内存,批处理系统在设计过程中就充分考虑了数据的量,可提供充足的处理资源。由于批处理在应对大量持久数据方面的表现极为出色,因此经常被用于对历史数据进行分析。
大量数据的处理需要付出大量时间,因此批处理不适合对处理时间要求较高的场合。
Apache Hadoop
Apache Hadoop 是一种专用于批处理的处理框架。Hadoop 是首个在开源社区获得极大关注的大数据框架。基于谷歌有关海量数据处理所发表的多篇论文与经验的 Hadoop 重新实现了相关算法和组件堆栈,让大规模批处理技术变得更易用。
新版 Hadoop 包含多个组件,即多个层,通过配合使用可处理批数据:
HDFS:HDFS 是一种分布式文件系统层,可对集群节点间的存储和复制进行协调。HDFS 确保了无法避免的节点故障发生后数据依然可用,可将其用作数据来源,可用于存储中间态的处理结果,并可存储计算的最终结果。
YARN:YARN 是 Yet Another Resource Negotiator(另一个资源管理器)的缩写,可充当 Hadoop 堆栈的集群协调组件。该组件负责协调并管理底层资源和调度作业的运行。通过充当集群资源的接口,YARN 使得用户能在 Hadoop 集群中使用比以往的迭代方式运行更多类型的工作负载。
MapReduce:MapReduce 是 Hadoop 的原生批处理引擎。
批处理模式:Hadoop 的处理功能来自 MapReduce 引擎。MapReduce 的处理技术符合使用键值对的 map、shuffle、reduce 算法要求。基本处理过程包括:
从 HDFS 文件系统读取数据集
将数据集拆分成小块并分配给所有可用节点
针对每个节点上的数据子集进行计算(计算的中间态结果会重新写入 HDFS)
重新分配中间态结果并按照键进行分组
通过对每个节点计算的结果进行汇总和组合对每个键的值进行 “Reducing”
将计算而来的最终结果重新写入 HDFS
优势和局限
由于这种方法严重依赖持久存储,每个任务需要多次执行读取和写入操作,因此速度相对较慢。但另一方面由于磁盘空间通常是服务器上最丰富的资源,这意味着 MapReduce 可以处理非常海量的数据集。同时也意味着相比其他类似技术,Hadoop 的 MapReduce 通常可以在廉价硬件上运行,因为该技术并不需要将一切都存储在内存中。MapReduce 具备极高的缩放潜力,生产环境中曾经出现过包含数万个节点的应用。
MapReduce 的学习曲线较为陡峭,虽然 Hadoop 生态系统的其他周边技术可以大幅降低这一问题的影响,但通过 Hadoop 集群快速实现某些应用时依然需要注意这个问题。
围绕 Hadoop 已经形成了辽阔的生态系统,Hadoop 集群本身也经常被用作其他软件的组成部件。很多其他处理框架和引擎通过与 Hadoop 集成也可以使用 HDFS 和 YARN 资源管理器。
总结
Apache Hadoop 及其 MapReduce 处理引擎提供了一套久经考验的批处理模型,最适合处理对时间要求不高的非常大规模数据集。通过非常低成本的组件即可搭建完整功能的 Hadoop 集群,使得这一廉价且高效的处理技术可以灵活应用在很多案例中。与其他框架和引擎的兼容与集成能力使得 Hadoop 可以成为使用不同技术的多种工作负载处理平台的底层基础。
2.4.4 流处理系统
流处理系统会对随时进入系统的数据进行计算。相比批处理模式,这是一种截然不同的处理方式。流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作。
流处理中的数据集是 “无边界” 的,这就产生了几个重要的影响:
完整数据集只能代表截至目前已经进入到系统中的数据总量。
工作数据集也许更相关,在特定时间只能代表某个单一数据项。
处理工作是基于事件的,除非明确停止否则没有“尽头”。处理结果立刻可用,并会随着新数据的抵达继续更新。
流处理系统可以处理几乎无限量的数据,但同一时间只能处理一条(真正的流处理)或很少量(微批处理,Micro-batch Processing)数据,不同记录间只维持最少量的状态。虽然大部分系统提供了用于维持某些状态的方法,但流处理主要针对副作用更少,更加功能性的处理(Functional processing)进行优化。
功能性操作主要侧重于状态或副作用有限的离散步骤。针对同一个数据执行同一个操作会或略其他因素产生相同的结果,此类处理非常适合流处理,因为不同项的状态通常是某些困难、限制,以及某些情况下不需要的结果的结合体。因此虽然某些类型的状态管理通常是可行的,但这些框架通常在不具备状态管理机制时更简单也更高效。
此类处理非常适合某些类型的工作负载。有近实时处理需求的任务很适合使用流处理模式。分析、服务器或应用程序错误日志,以及其他基于时间的衡量指标是最适合的类型,因为对这些领域的数据变化做出响应对于业务职能来说是极为关键的。流处理很适合用来处理必须对变动或峰值做出响应,并且关注一段时间内变化趋势的数据。
Apache Storm
Apache Storm 是一种侧重于极低延迟的流处理框架,也许是要求近实时处理的工作负载的最佳选择。该技术可处理非常大量的数据,通过比其他解决方案更低的延迟提供结果。
流处理模式
Storm 的流处理可对框架中名为 Topology(拓扑)的 DAG(Directed Acyclic Graph,有向无环图)进行编排。这些拓扑描述了当数据片段进入系统后,需要对每个传入的片段执行的不同转换或步骤。
拓扑包含:
1、Stream:普通的数据流,这是一种会持续抵达系统的无边界数据。
2、Spout:位于拓扑边缘的数据流来源,例如可以是 API 或查询等,从这里可以产生待处理的数据。
3、Bolt:Bolt 代表需要消耗流数据,对其应用操作,并将结果以流的形式进行输出的处理步骤。Bolt 需要与每个 Spout 建立连接,随后相互连接以组成所有必要的处理。在拓扑的尾部,可以使用最终的 Bolt 输出作为相互连接的其他系统的输入。
Storm 背后的想法是使用上述组件定义大量小型的离散操作,随后将多个组件组成所需拓扑。默认情况下 Storm 提供了 “至少一次” 的处理保证,这意味着可以确保每条消息至少可以被处理一次,但某些情况下如果遇到失败可能会处理多次。Storm 无法确保可以按照特定顺序处理消息。
为了实现严格的一次处理,即有状态处理,可以使用一种名为 Trident 的抽象。严格来说不使用 Trident 的 Storm 通常可称之为 Core Storm。Trident 会对 Storm 的处理能力产生极大影响,会增加延迟,为处理提供状态,使用微批模式代替逐项处理的纯粹流处理模式。
为避免这些问题,通常建议 Storm 用户尽可能使用 Core Storm。然而也要注意,Trident 对内容严格的一次处理保证在某些情况下也比较有用,例如系统无法智能地处理重复消息时。如果需要在项之间维持状态,例如想要计算一个小时内有多少用户点击了某个链接,此时 Trident 将是你唯一的选择。尽管不能充分发挥框架与生俱来的优势,但 Trident 提高了 Storm 的灵活性。
Trident 拓扑包含:
1、流批(Stream batch):这是指流数据的微批,可通过分块提供批处理语义。
2、操作(Operation):是指可以对数据执行的批处理过程。
优势和局限
目前来说 Storm 可能是近实时处理领域的最佳解决方案。该技术可以用极低延迟处理数据,可用于希望获得最低延迟的工作负载。如果处理速度直接影响用户体验,例如需要将处理结果直接提供给访客打开的网站页面,此时 Storm 将会是一个很好的选择。
Storm 与 Trident 配合使得用户可以用微批代替纯粹的流处理。虽然借此用户可以获得更大灵活性打造更符合要求的工具,但同时这种做法会削弱该技术相比其他解决方案最大的优势。话虽如此,但多一种流处理方式总是好的。
Core Storm无法保证消息的处理顺序。Core Storm 为消息提供了 “至少一次” 的处理保证,这意味着可以保证每条消息都能被处理,但也可能发生重复。Trident 提供了严格的一次处理保证,可以在不同批之间提供顺序处理,但无法在一个批内部实现顺序处理。
在互操作性方面,Storm 可与 Hadoop 的 YARN 资源管理器进行集成,因此可以很方便地融入现有 Hadoop 部署。除了支持大部分处理框架,Storm 还可支持多种语言,为用户的拓扑定义提供了更多选择。
总结
对于延迟需求很高的纯粹的流处理工作负载,Storm 可能是最适合的技术。该技术可以保证每条消息都被处理,可配合多种编程语言使用。由于 Storm 无法进行批处理,如果需要这些能力可能还需要使用其他软件。如果对严格的一次处理保证有比较高的要求,此时可考虑使用 Trident。不过这种情况下其他流处理框架也许更适合。
Apache Samza
Apache Samza 是一种与 Apache Kafka 消息系统紧密绑定的流处理框架。虽然 Kafka 可用于很多流处理系统,但按照设计,Samza 可以更好地发挥 Kafka 独特的架构优势和保障。该技术可通过 Kafka 提供容错、缓冲,以及状态存储。
Samza 可使用 YARN 作为资源管理器。这意味着默认情况下需要具备 Hadoop 集群(至少具备 HDFS 和 YARN),但同时也意味着 Samza 可以直接使用 YARN 丰富的内建功能。
流处理模式
1、Samza 依赖 Kafka 的语义定义流的处理方式。Kafka 在处理数据时涉及下列概念:
2、Topic(话题):进入 Kafka 系统的每个数据流可称之为一个话题。话题基本上是一种可供消耗方订阅的,由相关信息组成的数据流。
3、Partition(分区):为了将一个话题分散至多个节点,Kafka 会将传入的消息划分为多个分区。分区的划分将基于键(Key)进行,这样可以保证包含同一个键的每条消息可以划分至同一个分区。分区的顺序可获得保证。
4、Broker(代理):组成 Kafka 集群的每个节点也叫做代理。
5、Producer(生成方):任何向 Kafka 话题写入数据的组件可以叫做生成方。生成方可提供将话题划分为分区所需的键。
6、Consumer(消耗方):任何从 Kafka 读取话题的组件可叫做消耗方。消耗方需要负责维持有关自己分支的信息,这样即可在失败后知道哪些记录已经被处理过了。
由于 Kafka 相当于永恒不变的日志,Samza 也需要处理永恒不变的数据流。这意味着任何转换创建的新数据流都可被其他组件所使用,而不会对最初的数据流产生影响。
优势和局限
乍看之下,Samza 对 Kafka 类查询系统的依赖似乎是一种限制,然而这也可以为系统提供一些独特的保证和功能,这些内容也是其他流处理系统不具备的。
例如 Kafka 已经提供了可以通过低延迟方式访问的数据存储副本,此外还可以为每个数据分区提供非常易用且低成本的多订阅者模型。所有输出内容,包括中间态的结果都可写入到 Kafka,并可被下游步骤独立使用。
这种对 Kafka 的紧密依赖在很多方面类似于 MapReduce 引擎对 HDFS 的依赖。虽然在批处理的每个计算之间对 HDFS 的依赖导致了一些严重的性能问题,但也避免了流处理遇到的很多其他问题。
Samza 与 Kafka 之间紧密的关系使得处理步骤本身可以非常松散地耦合在一起。无需事先协调,即可在输出的任何步骤中增加任意数量的订阅者,对于有多个团队需要访问类似数据的组织,这一特性非常有用。多个团队可以全部订阅进入系统的数据话题,或任意订阅其他团队对数据进行过某些处理后创建的话题。这一切并不会对数据库等负载密集型基础架构造成额外的压力。
直接写入 Kafka 还可避免回压(Backpressure)问题。回压是指当负载峰值导致数据流入速度超过组件实时处理能力的情况,这种情况可能导致处理工作停顿并可能丢失数据。按照设计,Kafka 可以将数据保存很长时间,这意味着组件可以在方便的时候继续进行处理,并可直接重启动而无需担心造成任何后果。
Samza可以使用以本地键值存储方式实现的容错检查点系统存储数据。这样 Samza 即可获得 “至少一次” 的交付保障,但面对由于数据可能多次交付造成的失败,该技术无法对汇总后状态(例如计数)提供精确恢复。
Samza 提供的高级抽象使其在很多方面比 Storm 等系统提供的基元(Primitive)更易于配合使用。目前 Samza 只支持 JVM 语言,这意味着它在语言支持方面不如 Storm 灵活。
总结
对于已经具备或易于实现 Hadoop 和 Kafka 的环境,Apache Samza 是流处理工作负载一个很好的选择。Samza 本身很适合有多个团队需要使用(但相互之间并不一定紧密协调)不同处理阶段的多个数据流的组织。Samza 可大幅简化很多流处理工作,可实现低延迟的性能。如果部署需求与当前系统不兼容,也许并不适合使用,但如果需要极低延迟的处理,或对严格的一次处理语义有较高需求,此时依然适合考虑。
2.4.5 混合处理系统:批处理和流处理
一些处理框架可同时处理批处理和流处理工作负载。这些框架可以用相同或相关的组件和 API 处理两种类型的数据,借此让不同的处理需求得以简化。
如你所见,这一特性主要是由 Spark 和 Flink 实现的,下文将介绍这两种框架。实现这样的功能重点在于两种不同处理模式如何进行统一,以及要对固定和不固定数据集之间的关系进行何种假设。
虽然侧重于某一种处理类型的项目会更好地满足具体用例的要求,但混合框架意在提供一种数据处理的通用解决方案。这种框架不仅可以提供处理数据所需的方法,而且提供了自己的集成项、库、工具,可胜任图形分析、机器学习、交互式查询等多种任务。
Apache Spark
Apache Spark 是一种包含流处理能力的下一代批处理框架。与 Hadoop 的 MapReduce 引擎基于各种相同原则开发而来的 Spark 主要侧重于通过完善的内存计算和处理优化机制加快批处理工作负载的运行速度。
Spark 可作为独立集群部署(需要相应存储层的配合),或可与 Hadoop 集成并取代 MapReduce 引擎。
批处理模式
与 MapReduce 不同,Spark 的数据处理工作全部在内存中进行,只在一开始将数据读入内存,以及将最终结果持久存储时需要与存储层交互。所有中间态的处理结果均存储在内存中。
虽然内存中处理方式可大幅改善性能,Spark 在处理与磁盘有关的任务时速度也有很大提升,因为通过提前对整个任务集进行分析可以实现更完善的整体式优化。为此 Spark 可创建代表所需执行的全部操作,需要操作的数据,以及操作和数据之间关系的 Directed Acyclic Graph(有向无环图),即 DAG,借此处理器可以对任务进行更智能的协调。
为了实现内存中批计算,Spark 会使用一种名为 Resilient Distributed Dataset(弹性分布式数据集),即 RDD 的模型来处理数据。这是一种代表数据集,只位于内存中,永恒不变的结构。针对 RDD 执行的操作可生成新的 RDD。每个 RDD 可通过世系(Lineage)回溯至父级 RDD,并最终回溯至磁盘上的数据。Spark 可通过 RDD 在无需将每个操作的结果写回磁盘的前提下实现容错。
流处理模式
流处理能力是由 Spark Streaming 实现的。Spark 本身在设计上主要面向批处理工作负载,为了弥补引擎设计和流处理工作负载特征方面的差异,Spark 实现了一种叫做微批(Micro-batch)的概念。在具体策略方面该技术可以将数据流视作一系列非常小的 “批”,借此即可通过批处理引擎的原生语义进行处理。
Spark Streaming 会以亚秒级增量对流进行缓冲,随后这些缓冲会作为小规模的固定数据集进行批处理。这种方式的实际效果非常好,但相比真正的流处理框架在性能方面依然存在不足。
优势和局限
使用 Spark 而非 Hadoop MapReduce 的主要原因是速度。在内存计算策略和先进的 DAG 调度等机制的帮助下,Spark 可以用更快速度处理相同的数据集。
Spark 的另一个重要优势在于多样性。该产品可作为独立集群部署,或与现有 Hadoop 集群集成。该产品可运行批处理和流处理,运行一个集群即可处理不同类型的任务。
除了引擎自身的能力外,围绕 Spark 还建立了包含各种库的生态系统,可为机器学习、交互式查询等任务提供更好的支持。相比 MapReduce,Spark 任务更是 “众所周知” 地易于编写,因此可大幅提高生产力。
为流处理系统采用批处理的方法,需要对进入系统的数据进行缓冲。缓冲机制使得该技术可以处理非常大量的传入数据,提高整体吞吐率,但等待缓冲区清空也会导致延迟增高。这意味着 Spark Streaming 可能不适合处理对延迟有较高要求的工作负载。
由于内存通常比磁盘空间更贵,因此相比基于磁盘的系统,Spark 成本更高。然而处理速度的提升意味着可以更快速完成任务,在需要按照小时数为资源付费的环境中,这一特性通常可以抵消增加的成本。
Spark 内存计算这一设计的另一个后果是,如果部署在共享的集群中可能会遇到资源不足的问题。相比 Hadoop MapReduce,Spark 的资源消耗更大,可能会对需要在同一时间使用集群的其他任务产生影响。从本质来看,Spark 更不适合与 Hadoop 堆栈的其他组件共存一处。
总结
Spark 是多样化工作负载处理任务的最佳选择。Spark 批处理能力以更高内存占用为代价提供了无与伦比的速度优势。对于重视吞吐率而非延迟的工作负载,则比较适合使用 Spark Streaming 作为流处理解决方案。
Apache Flink
Apache Flink 是一种可以处理批处理任务的流处理框架。该技术可将批处理数据视作具备有限边界的数据流,借此将批处理任务作为流处理的子集加以处理。为所有处理任务采取流处理为先的方法会产生一系列有趣的副作用。
这种流处理为先的方法也叫做 Kappa 架构,与之相对的是更加被广为人知的 Lambda 架构(该架构中使用批处理作为主要处理方法,使用流作为补充并提供早期未经提炼的结果)。Kappa 架构中会对一切进行流处理,借此对模型进行简化,而这一切是在最近流处理引擎逐渐成熟后才可行的。
流处理模型
Flink 的流处理模型在处理传入数据时会将每一项视作真正的数据流。Flink 提供的 DataStream API可用于处理无尽的数据流。Flink 可配合使用的基本组件包括:
1)Stream(流)是指在系统中流转的,永恒不变的无边界数据集
2)Operator(操作方)是指针对数据流执行操作以产生其他数据流的功能
3)Source(源)是指数据流进入系统的入口点
4)Sink(槽)是指数据流离开Flink系统后进入到的位置,槽可以是数据库或到其他系统的连接器
为了在计算过程中遇到问题后能够恢复,流处理任务会在预定时间点创建快照。为了实现状态存储,Flink 可配合多种状态后端系统使用,具体取决于所需实现的复杂度和持久性级别。
此外 Flink 的流处理能力还可以理解 “事件时间” 这一概念,这是指事件实际发生的时间,此外该功能还可以处理会话。这意味着可以通过某种有趣的方式确保执行顺序和分组。
批处理模型
Flink 的批处理模型在很大程度上仅仅是对流处理模型的扩展。此时模型不再从持续流中读取数据,而是从持久存储中以流的形式读取有边界的数据集。Flink 会对这些处理模型使用完全相同的运行时。
Flink 可以对批处理工作负载实现一定的优化。例如由于批处理操作可通过持久存储加以支持,Flink 可以不对批处理工作负载创建快照。数据依然可以恢复,但常规处理操作可以执行得更快。
另一个优化是对批处理任务进行分解,这样即可在需要的时候调用不同阶段和组件。借此 Flink 可以与集群的其他用户更好地共存。对任务提前进行分析使得 Flink 可以查看需要执行的所有操作、数据集的大小,以及下游需要执行的操作步骤,借此实现进一步的优化。
优势和局限
Flink 目前是处理框架领域一个独特的技术。虽然 Spark 也可以执行批处理和流处理,但 Spark 的流处理采取的微批架构使其无法适用于很多用例。Flink 流处理为先的方法可提供低延迟,高吞吐率,近乎逐项处理的能力。
Flink 的很多组件是自行管理的。虽然这种做法较为罕见,但出于性能方面的原因,该技术可自行管理内存,无需依赖原生的 Java 垃圾回收机制。与 Spark 不同,待处理数据的特征发生变化后 Flink 无需手工优化和调整,并且该技术也可以自行处理数据分区和自动缓存等操作。
Flink 会通过多种方式对工作进行分许进而优化任务。这种分析在部分程度上类似于 SQL 查询规划器对关系型数据库所做的优化,可针对特定任务确定最高效的实现方法。该技术还支持多阶段并行执行,同时可将受阻任务的数据集合在一起。对于迭代式任务,出于性能方面的考虑,Flink 会尝试在存储数据的节点上执行相应的计算任务。此外还可进行 “增量迭代”,或仅对数据中有改动的部分进行迭代。
在用户工具方面,Flink 提供了基于 Web 的调度视图,借此可轻松管理任务并查看系统状态。用户也可以查看已提交任务的优化方案,借此了解任务最终是如何在集群中实现的。对于分析类任务,Flink 提供了类似 SQL 的查询,图形化处理,以及机器学习库,此外还支持内存计算。
Flink 能很好地与其他组件配合使用。如果配合 Hadoop 堆栈使用,该技术可以很好地融入整个环境,在任何时候都只占用必要的资源。该技术可轻松地与 YARN、HDFS 和 Kafka 集成。在兼容包的帮助下,Flink 还可以运行其他处理框架,例如 Hadoop 和 Storm 编写的任务。
目前 Flink 最大的局限之一在于这依然是一个非常 “年幼” 的项目。现实环境中该项目的大规模部署尚不如其他处理框架那么常见,对于 Flink 在缩放能力方面的局限目前也没有较为深入的研究。随着快速开发周期的推进和兼容包等功能的完善,当越来越多的组织开始尝试时,可能会出现越来越多的 Flink 部署。
总结
Flink 提供了低延迟流处理,同时可支持传统的批处理任务。Flink 也许最适合有极高流处理需求,并有少量批处理任务的组织。该技术可兼容原生 Storm 和 Hadoop程序,可在 YARN 管理的集群上运行,因此可以很方便地进行评估。快速进展的开发工作使其值得被大家关注。
2.4.6 结论
大数据系统可使用多种处理技术。
对于仅需要批处理的工作负载,如果对时间不敏感,比其他解决方案实现成本更低的 Hadoop 将会是一个好选择。
对于仅需要流处理的工作负载,Storm 可支持更广泛的语言并实现极低延迟的处理,但默认配置可能产生重复结果并且无法保证顺序。Samza 与 YARN 和 Kafka 紧密集成可提供更大灵活性,更易用的多团队使用,以及更简单的复制和状态管理。
对于混合型工作负载,Spark 可提供高速批处理和微批处理模式的流处理。该技术的支持更完善,具备各种集成库和工具,可实现灵活的集成。Flink 提供了真正的流处理并具备批处理能力,通过深度优化可运行针对其他平台编写的任务,提供低延迟的处理,但实际应用方面还为时过早。
最适合的解决方案主要取决于待处理数据的状态,对处理所需时间的需求,以及希望得到的结果。具体是使用全功能解决方案或主要侧重于某种项目的解决方案,这个问题需要慎重权衡。随着逐渐成熟并被广泛接受,在评估任何新出现的创新型解决方案时都需要考虑类似的问题。
我的GitHub地址:https://github.com/heizemingjun
我的博客园地址:https://www.cnblogs.com/chenmingjun
我的CSDN地址:https://blog.csdn.net/u012990179
我的蚂蚁笔记博客地址:https://blog.leanote.com/chenmingjun
Copyright ©2018~2019 黑泽君
【转载文章务必保留出处和署名,谢谢!】