论文阅读——TBN(2019ICCV)
目录
- 论文
- 工作介绍
- TBW多模态融合模块
- 1.前融合
- 2.后融合
- 3.TBW融合模块
- 网络框架TBN
- 网络的输入
- 实验
- 数据集
- 实现细节
论文
pdf:EPIC-Fusion: Audio-Visual Temporal Binding for Egocentric Action Recognition
code:https://github.com/ekazakos/temporal-binding-network
以下仅是个人在阅读论文时的个人理解,如有不同观点,欢迎讨论!!!
工作介绍
该论文所做的工作主要是第一视角下的行为识别。为此作者提出了端到端的RGB,Flow,Audio三种模态的融合模型框架TBN网络,并在当前最大的第一视角下的数据集EPIC-KITCHENS上验证了模型的性能。在多模态的融合阶段,作者提出了TBW模块来融合多模态的信息。
TBW多模态融合模块
以前的多模态融合方式大致可分为:前融合(synchronous fusion)和后融合(late fusion)。
1.前融合
就是在输入端将不同的模态输入融合在一起,例如RGB模态的图像外观和FLow的光流图在输入端进行融合,直接输入网络。前融合主要存在的问题是不同模态之间的帧速率的匹配问题,以及表示的尺寸变化时的问题。一般也只能做到近似融合而已,具体融合公式为: y = h ( G ( f s y n c ( m 1 j , m 2 k ) ) ) : k = [ j r 2 r 1 ] y\ =\ h( G( f_{sync}( m_{1j} ,m_{2k}))) :k=\Bigl[\frac{jr2}{r1}\Bigr] y = h(G(fsync(m1j,m2k))):k=[r1jr2]其中m1,m2表示不同的模态,j,k表示帧号,r1,r2表示两种模态的帧速率或者采样频率,f表示多模态的特征提取器,在每一个时间帧都有一个输出,G表示时间上的聚合效果,因为我们操作的是视频,因此需要把时间上的信息关联起来,h表示多模态的融合功能,y为最后的预测输出。
2.后融合
简单来说就是每个模态都做自己的事情,即对视频行为进行预测,将各个模态的模型训练好之后,再将各模态提取的特征进行拼接,用融合了多模态的特征进行最终的预测。这种融合方式的缺陷也是显而易见的,即每个模态都做自己的事情,缺少模态之间信息的交互。融合公式为 y = h ( G ( f 1 ( m 1 ) ) , G ( f 2 ( m 2 ) ) ) y\ =\ h( G( f_{1}( m_{1})) ,G( f_{2}( m_{2}))) y = h(G(f1(m1)),G(f2(m2)))其中 m i = ( m i 1 , m i 2 , . . . , m i T / r i ) m_{i} =( m_{i1} ,m_{i2} ,...,m_{iT/r_{i}}) mi=(mi1,mi2,...,miT/ri), T代表视频的长度。典型的网络有TSN【42】网络。
3.TBW融合模块
作者提出的TBW(temporal binding window)融合模块也是一种前融合的形式,不同的是作者是在一个时间窗里进行多模态的融合。这样的话,不同模态的时间偏置被限制在一个时间窗里。具体的公式为 y = h ( G ( f t b w ( m 1 j , m 2 k ) ) ) : k = [ [ j r 2 r 1 − b ] , [ j r 2 r 1 + b ] y=h( G( f_{tbw}( m_{1j} ,m_{2k}))) :k=\Bigl[\Bigl[\frac{jr_{2}}{r_{1}} -b\Bigr] ,\Bigl[\frac{jr_{2}}{r_{1}} +b\Bigr] y=h(G(ftbw(m1j,m2k))):k=[[r1jr2−b],[r1jr2+b]其中时间窗的宽度为[-b, b]。作者这里设置的b不是固定的,而是与当前视频长度有关的函数!同时b与视频分割的段数T/r也可以分别独立设置,也就是说时间窗在视频整个序列上是可以有重叠的!

网络框架TBN
网络的整体框架为

如上图所示,使用TBW对多模态进行采样,针对不同的输入(TBWs),同一模态共享权重(图中相同的颜色),多模态在中层进行融合,一起训练。最后将多个TBWs(可能重叠)的预测结果进行平均作为最终的预测结果。
单独一个TBN block的展示为:
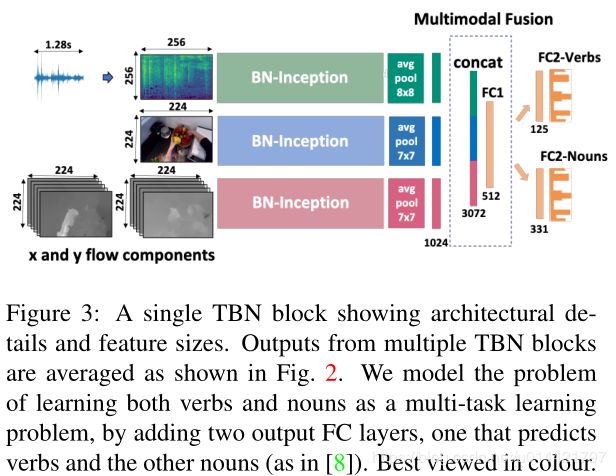
即在每一个TBW中,首先对每一个模态,使用Conv模块提取中层特征,然后将提取的特征拼接起来,再接一个全连接层,进行预测。同时作者将反向传播传递到输入层。
网络的输入
- 与大多数视频处理方式一样,先整个视频进行分段处理,分成等宽的 K K K个片段
- 在每个片段内,随机的为第一个模态(例如RGB)选择一个样本,即 ∀ k ∈ K : m 1 k \forall k\in K:m_{1k} ∀k∈K:m1k,这样做的好处是:(1)在视频段内稀疏采样,获取视频动作的时间进展,(2)在每一段内随机采样,实现了数据增强
- 将采样得到的 m 1 k m_{1k} m1k作为TBW时间窗口的中心,以宽度为[-b,b]构建时间窗口TBW,然后其他的模态在TBW窗口内随机选择样本
- 总之,模型的输入为 K × M \displaystyle K\times M K×M个样本, M M M为模态数(RGB,Flow,Audio)
通过这种方式,对于一个视频,共构建了 K K K个TBW窗口,在每个窗口内都实现了多模态的融合,可以更好的将多模态之间的信息进行互补。
实验
数据集
作者使用的是目前最大的第一视角视频数据集EPIC-KITCHENS,包含39596个行为视频片段,由32个参与者每天在厨房的活动组成。在该数据集中每一个行为被定义为动宾短语,即动词和名词的组合。目前动词包含125类,名词包含352类,而且各类别数量之间是严重失衡的!测试数据集可分为两个部分:S1:视频中的厨房环境与训练数据一致;S2:视频中的厨房环境在训练集中没有出现过。另外该数据集还发布了视频中的音频信息供使用。这在以前的数据集中是没有的。
实现细节
1.RGB和Flow是利用数据集中提供的。
2.Audio数据的处理:首先,提取1.28s的音频,转化为单通道,重新采样为24kHZ;然后,使用窗口长度为10ms的STFT将其转换为对数谱图表示形式,hop length 是5ms, 256个频段。计算完对数之后,结果存储在256x256的2D光谱图矩阵中。实际中视频动作的时长很多是小于1.28s的,即提取的音频时长比动作时长要长,超出行为动作发生的时长!
3.训练的细节:
(1)框架Pytorch
(2)使用的基本结构是BN-Inception,在平均池化之后融合多模态特征。选用这个结构,是因为BN-Inception在模型大小和性能之间取得了很好的平衡。因为TBN网络是所有模式一起训练,所以比较消耗内存,参数量为32.64M。
(3)参数设置:优化方法:SGD with momentum, batch size:128, dropout:0.5; momentum:0.9,lr:0.01; 训练80epoch,在60epoch时,lr衰减10倍。RGB和Audio模型使用ImageNet预训练参数,Flow采用x,y交叉堆叠的10帧作为输入,预训练模型采用Kinetics.设置网络频片段数K=3,模态M=3,时间窗b=T,即窗口大小和行为片段长度一致。每个模态使用等间隔采样的25帧进行测试,并与标准的TSN网络进行对比。
4.实验结果
(1)单一模态的效果

注:单一模态结果是使用TSN网络训练的。
从结果中可以看出融合的模态比单一的模态效果更好,top1的RGB和Audio在verb识别效果上相当;Flow在S2测试上表现比RGB好,而S1中RGB与Flow相当,甚至更好,这符合Flow对环境更具有不变形的预期。
为了查看各模态如何工作的,在S1上使用单一模态对verb,noun进行测试

从结果来看:verb与动作的时间进展密切相关,Flow识别verb效果较好;RGB可以识别大部分的noun类别;Audio在noun和verb上的表现相当,对伴随有声音的noun,verb识别效果更好。
使用TBN网络训练三种模态的测试结果如下

可以看出融合模态对于verb的识别效果更为明显,对某些类别的noun识别效果好,这说明视频中捕获的补充信息和冗余信息的混合很大程度上取决于行为动作本身,从而使融合在某些类别上的表现效果好。
从结果中还可以看出,融合可以提高对长尾类别的识别效果,而这些类别在单一模态上表现效果不好。
音频的作用:
从上表中可以看出,音频对第一视角行为识别的重要性。

从上图中可以看出,增加音频信息后,对角线的置信度增加,其他地方的置信度降低。
与行为无关的音频的影响:
使用头戴相机拍摄的视频会记录下与行为无关的背景音乐。为了验证无关的声音在测试集中对行为的影响,将测试集进行划分:S1中有14%包含无效声音,S2中有46%包含无效的声音,分别对他们进行测试,结果见下表

将All和RGB+Flow进行对比,发现:1、无论是否包含无效的声音,增加Audio的信息之后,识别效果均有所提高;2、相比于rest,包含无效声音的行为识别效果不高,All,RGB+Flow均有所下降,这说明无关的声音不是影响识别效果的主要因素,即使只是视觉特征RGB+Flow,对这些行为识别效果也不好。
(2)不同的mid-level fusion技术
(i)直接进行串联Concatenation
即每个模态的特征先进行拼接,然后使用一个全连接层将各模态的特征进行交叉。
f t b w c o n c a t = ϕ ( W [ m 1 j , m 2 k , m 3 l ] + b ) \displaystyle f^{concat}_{tbw} =\phi ( W[ m_{1j} ,m_{2k} ,m_{3l}] +b) ftbwconcat=ϕ(W[m1j,m2k,m3l]+b)
ϕ \phi ϕ是非线性激活单元,在一个时间窗内TBW, f t b w c o n c a t f^{concat}_{tbw} ftbwconcat权值共享。
(ii)上下文的门控Context gating
通过一个自动调节机制,重新校准不同单元的激活强度。
f t b w c o n c a t = ϕ ( W h + b z ) ∘ h f^{concat}_{tbw} =\phi ( Wh+b_{z}) \circ h ftbwconcat=ϕ(Wh+bz)∘h
∘ \circ ∘表示元素相乘,在带有全连接的多模态融合之后,使用门控,因此 h h h与上文相同。
(iii)门控融合Gating fusion
使用每个模态使用一个门控单元将多模态的特征作为输入,学习该模态的重要性。
h i = ϕ ( W i m i j + b i ) ∀ i h_{i} =\phi ( W_{i} m_{ij} +b_{i}) \ \ \forall i hi=ϕ(Wimij+bi) ∀i
z i = ϕ ( W z i [ m 1 j , m 2 k , m 3 l ] + b z i ) ∀ i z_{i} =\phi ( W_{zi}[ m_{1j} ,m_{2k} ,m_{3l}] +b_{zi}) \ \forall i zi=ϕ(Wzi[m1j,m2k,m3l]+bzi) ∀i
f t b w g a t i n g = z 1 ∘ h 1 + z 2 ∘ h 2 + z 3 ∘ h 3 f^{gating}_{tbw} =z_{1} \circ h_{1} +z_{2} \circ h_{2} +z_{3} \circ h_{3} ftbwgating=z1∘h1+z2∘h2+z3∘h3
三种模式的效果比较:
 从结果中看出,反而是最简单的融合模式效果最好!
从结果中看出,反而是最简单的融合模式效果最好!
(3)TBW宽度b的影响
训练:作者训练设置b的宽度分别为T/6, T/3, T;发现性能几乎没有什么影响。由于在训练中更改b的代价很大,而且还需要进行不同的优化策略,所以作者采用了,对一个模型,在测试时更改不同的b,查看测试的效果。
具体来说,作者在测试时,选择b为T/60, T/30, T/25, T/15, T/10, T/5, T/3,这相当于将TBW的宽度在60ms~1200ms之间进行变换。结果如下图所示:

从中可以看出,最优的结果是b在【T/30, T/20】,相当于平均的b在【120ms±190ms, 180ms±285ms】。当TBW的宽度变小时(即b=T/60),性能明显的下降。当TBW较大时,显示出更强的鲁棒性。
(4)最终的实验结果

Ensemble是使用多个不同的TBW窗口训练模型,然后进行融合,最高相比单TBW模型,提升3%