pytorch用VGG11识别cifar10数据集(训练+预测单张输入图片代码)
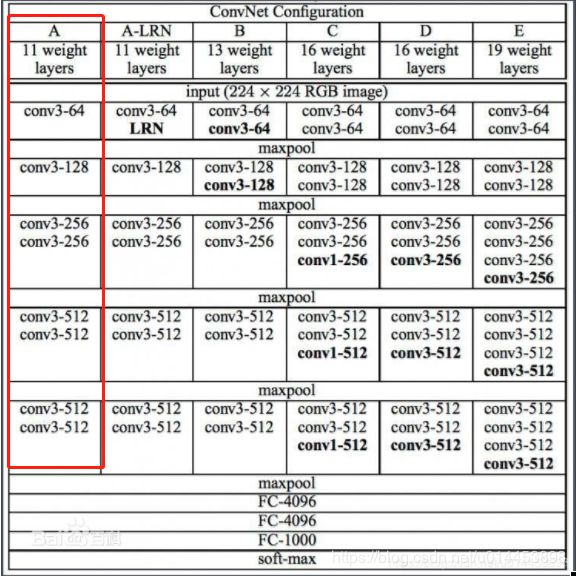
首先这是VGG的结构图,VGG11则是红色框里的结构,共分五个block,如红框中的VGG11第一个block就是一个conv3-64卷积层:
一,写VGG代码时,首先定义一个 vgg_block(n,in,out)方法,用来构建VGG中每个block中的卷积核和池化层:
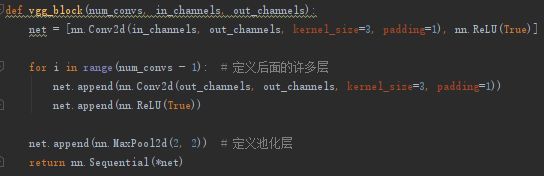
n是这个block中卷积层的数目,in是输入的通道数,out是输出的通道数
有了block以后,我们还需要一个方法把形成的block叠在一起,我们定义这个方法叫vgg_stack:
def vgg_stack(num_convs, channels): # vgg_net = vgg_stack((1, 1, 2, 2, 2), ((3, 64), (64, 128), (128, 256), (256, 512), (512, 512)))
net = []
for n, c in zip(num_convs, channels):
in_c = c[0]
out_c = c[1]
net.append(vgg_block(n, in_c, out_c))
return nn.Sequential(*net)右边的注释
vgg_net = vgg_stack((1, 1, 2, 2, 2), ((3, 64), (64, 128), (128, 256), (256, 512), (512, 512)))里,(1, 1, 2, 2, 2)表示五个block里,各自的卷积层数目,((3, 64), (64, 128), (128, 256), (256, 512), (512, 512))表示每个block中的卷积层的类型,如(3,64)表示这个卷积层输入通道数是3,输出通道数是64。vgg_stack方法返回的就是完整的vgg11模型了。
接着定义一个vgg类,包含vgg_stack方法:
#vgg类
class vgg(nn.Module):
def __init__(self):
super(vgg, self).__init__()
self.feature = vgg_net
self.fc = nn.Sequential(
nn.Linear(512, 100),
nn.ReLU(True),
nn.Linear(100, 10)
)
def forward(self, x):
x = self.feature(x)
x = x.view(x.shape[0], -1)
x = self.fc(x)
return x最后:
net = vgg() #就能获取到vgg网络那么构建vgg网络完整的pytorch代码是:
def vgg_block(num_convs, in_channels, out_channels):
net = [nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1), nn.ReLU(True)]
for i in range(num_convs - 1): # 定义后面的许多层
net.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
net.append(nn.ReLU(True))
net.append(nn.MaxPool2d(2, 2)) # 定义池化层
return nn.Sequential(*net)
# 下面我们定义一个函数对这个 vgg block 进行堆叠
def vgg_stack(num_convs, channels): # vgg_net = vgg_stack((1, 1, 2, 2, 2), ((3, 64), (64, 128), (128, 256), (256, 512), (512, 512)))
net = []
for n, c in zip(num_convs, channels):
in_c = c[0]
out_c = c[1]
net.append(vgg_block(n, in_c, out_c))
return nn.Sequential(*net)
#确定vgg的类型,是vgg11 还是vgg16还是vgg19
vgg_net = vgg_stack((1, 1, 2, 2, 2), ((3, 64), (64, 128), (128, 256), (256, 512), (512, 512)))
#vgg类
class vgg(nn.Module):
def __init__(self):
super(vgg, self).__init__()
self.feature = vgg_net
self.fc = nn.Sequential(
nn.Linear(512, 100),
nn.ReLU(True),
nn.Linear(100, 10)
)
def forward(self, x):
x = self.feature(x)
x = x.view(x.shape[0], -1)
x = self.fc(x)
return x
#获取vgg网络
net = vgg()
基于VGG11的cifar10训练代码:
import sys
import numpy as np
import torch
from torch import nn
from torch.autograd import Variable
from torchvision.datasets import CIFAR10
import torchvision.transforms as transforms
def vgg_block(num_convs, in_channels, out_channels):
net = [nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1), nn.ReLU(True)]
for i in range(num_convs - 1): # 定义后面的许多层
net.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
net.append(nn.ReLU(True))
net.append(nn.MaxPool2d(2, 2)) # 定义池化层
return nn.Sequential(*net)
# 下面我们定义一个函数对这个 vgg block 进行堆叠
def vgg_stack(num_convs, channels): # vgg_net = vgg_stack((1, 1, 2, 2, 2), ((3, 64), (64, 128), (128, 256), (256, 512), (512, 512)))
net = []
for n, c in zip(num_convs, channels):
in_c = c[0]
out_c = c[1]
net.append(vgg_block(n, in_c, out_c))
return nn.Sequential(*net)
#vgg类
class vgg(nn.Module):
def __init__(self):
super(vgg, self).__init__()
self.feature = vgg_net
self.fc = nn.Sequential(
nn.Linear(512, 100),
nn.ReLU(True),
nn.Linear(100, 10)
)
def forward(self, x):
x = self.feature(x)
x = x.view(x.shape[0], -1)
x = self.fc(x)
return x
# 然后我们可以训练我们的模型看看在 cifar10 上的效果
def data_tf(x):
x = np.array(x, dtype='float32') / 255
x = (x - 0.5) / 0.5
x = x.transpose((2, 0, 1)) ## 将 channel 放到第一维,只是 pytorch 要求的输入方式
x = torch.from_numpy(x)
return x
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
])
def get_acc(output, label):
total = output.shape[0]
_, pred_label = output.max(1)
num_correct = (pred_label == label).sum().item()
return num_correct / total
def train(net, train_data, valid_data, num_epochs, optimizer, criterion):
if torch.cuda.is_available():
net = net.cuda()
for epoch in range(num_epochs):
train_loss = 0
train_acc = 0
net = net.train()
for im, label in train_data:
if torch.cuda.is_available():
im = Variable(im.cuda())
label = Variable(label.cuda())
else:
im = Variable(im)
label = Variable(label)
# forward
output = net(im)
loss = criterion(output, label)
# forward
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += get_acc(output, label)
if valid_data is not None:
valid_loss = 0
valid_acc = 0
net = net.eval()
for im, label in valid_data:
if torch.cuda.is_available():
with torch.no_grad():
im = Variable(im.cuda())
label = Variable(label.cuda())
else:
with torch.no_grad():
im = Variable(im)
label = Variable(label)
output = net(im)
loss = criterion(output, label)
valid_loss += loss.item()
valid_acc += get_acc(output, label)
epoch_str = (
"Epoch %d. Train Loss: %f, Train Acc: %f, Valid Loss: %f, Valid Acc: %f, "
% (epoch, train_loss / len(train_data),
train_acc / len(train_data), valid_loss / len(valid_data),
valid_acc / len(valid_data)))
else:
epoch_str = ("Epoch %d. Train Loss: %f, Train Acc: %f, " %
(epoch, train_loss / len(train_data),
train_acc / len(train_data)))
# prev_time = cur_time
print(epoch_str)
if __name__ == '__main__':
# 作为实例,我们定义一个稍微简单一点的 vgg11 结构,其中有 8 个卷积层
vgg_net = vgg_stack((1, 1, 2, 2, 2), ((3, 64), (64, 128), (128, 256), (256, 512), (512, 512)))
print(vgg_net)
train_set = CIFAR10('./data', train=True, transform=transform, download=True)
train_data = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)
test_set = CIFAR10('./data', train=False, transform=transform, download=True)
test_data = torch.utils.data.DataLoader(test_set, batch_size=128, shuffle=False)
net = vgg()
optimizer = torch.optim.SGD(net.parameters(), lr=1e-1)
criterion = nn.CrossEntropyLoss() #损失函数为交叉熵
train(net, train_data, test_data, 50, optimizer, criterion)
torch.save(net, 'vgg_model.pth')
结束后,会出现一个模型文件vgg_model.pth
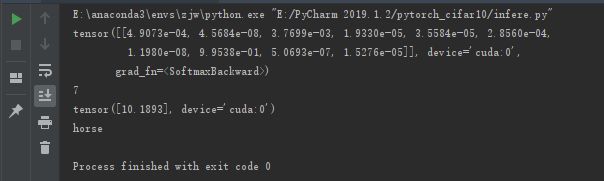
二,然后网上找张图片,把图片缩成32x32,放到预测代码中,即可有预测结果出现,预测代码如下:
import torch
import cv2
import torch.nn.functional as F
from vgg2 import vgg ##重要,虽然显示灰色(即在次代码中没用到),但若没有引入这个模型代码,加载模型时会找不到模型
from torch.autograd import Variable
from torchvision import datasets, transforms
import numpy as np
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = torch.load('vgg_model.pth') # 加载模型
model = model.to(device)
model.eval() # 把模型转为test模式
img = cv2.imread("horse.jpg") # 读取要预测的图片
trans = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
img = trans(img)
img = img.to(device)
img = img.unsqueeze(0) # 图片扩展多一维,因为输入到保存的模型中是4维的[batch_size,通道,长,宽],而普通图片只有三维,[通道,长,宽]
# 扩展后,为[1,1,28,28]
output = model(img)
prob = F.softmax(output,dim=1) #prob是10个分类的概率
print(prob)
value, predicted = torch.max(output.data, 1)
print(predicted.item())
print(value)
pred_class = classes[predicted.item()]
print(pred_class)
# prob = F.softmax(output, dim=1)
# prob = Variable(prob)
# prob = prob.cpu().numpy() # 用GPU的数据训练的模型保存的参数都是gpu形式的,要显示则先要转回cpu,再转回numpy模式
# print(prob) # prob是10个分类的概率
# pred = np.argmax(prob) # 选出概率最大的一个
# # print(pred)
# # print(pred.item())
# pred_class = classes[pred]
# print(pred_class)缩成32x32的图片:

运行结果: