MyDLNote-Enhancement:[2020 CVPR] Domain Adaptation for Image Dehazing
2020 CVPR : Domain Adaptation for Image Dehazing
[paper] : http://export.arxiv.org/pdf/2005.04668
这篇文章之所以能够在 CVPR 发表,真的是因为该文章确实切中了目前基于深度学习去雾算法的要害,即依据大气光物理模型生成的人工合成雾图像与真实拍到的雾图像是不一样的。也就是说,大家一直广泛应用的大气光物理模型只是雾图像产生的一个近似图像,而非真实图像。在人工合成数据集上训练的去雾模型,自然是不能适应于真实雾图像的高质量去雾。
本人是第一次接触 Domain Adaptation 相关的研究内容,DA 其实是解决上述问题的一个非常合适的方法。
种豆南山下 的知乎上对 DA 做了比较全面的介绍,墙裂推荐学习,相关连接:https://zhuanlan.zhihu.com/p/53359505。
Abstract
Image dehazing using learning-based methods has achieved state-of-the-art performance in recent years. However, most existing methods train a dehazing model on synthetic hazy images, which are less able to generalize well to real hazy images due to domain shift.
对现有深度学习算法的肯定和否定:域迁移问题。
总:To address this issue, we propose a domain adaptation paradigm, which consists of an image translation module and two image dehazing modules.
分:Specifically, we first apply a bidirectional translation network to bridge the gap between the synthetic and real domains by translating images from one domain to another. And then, we use images before and after translation to train the proposed two image dehazing networks with a consistency constraint (后面说的 consistency loss). In this phase, we incorporate the real hazy image into the dehazing training via exploiting the properties of the clear image (e.g., dark channel prior and image gradient smoothing) to further improve the domain adaptivity. By training image translation and dehazing network in an end-to-end manner, we can obtain better effects of both image translation and dehazing.
介绍本文的方法,总-分的描写形式。
整个结构有两个部分:一个双向的迁移网络;两个去雾网络(分别在人工合成雾图像和迁移到的真实雾图像两个域中的去雾)。
Experimental results on both synthetic and real-world images demonstrate that our model performs favorably against the state-of-the-art dehazing algorithms.
实验结果。
Introduction
Single image dehazing aims to recover the clean image from a hazy input, which is essential for subsequent high-level tasks, such as object recognition and scene understanding. Thus, it has received significant attention in the vision community over the past few years. According to the physical scattering models [21, 23, 18], the hazing process is usually formulated as
where and denote the hazy image and the clean image, is the global atmospheric light, and is the transmission map. The transmission map can be represented as , where and denote the scene depth and the atmosphere scattering parameter, respectively. Given a hazy image , most dehazing algorithms try to estimate and .
背景:这段介绍去雾是干嘛的。公式(1)就是传统去雾算法(不论是基于先验的还是基于深度学习的)的问题根源。
However, estimating the transmission map from a hazy image is an ill-posed problem generally. Early prior-based methods try to estimate the transmission map by exploiting the statistical properties of clear images, such as dark channel prior [9] and color-line prior [8]. Unfortunately, these image priors are easily inconsistent with the practice, which may lead to inaccurate transmission approximations. Thus, the quality of the restored image is undesirable.
问题:传统基于先验的去雾算法存在的问题:这些图像先验很容易与实践不一致,这可能导致不准确的透射率图估计。因此,恢复图像的质量是不理想的。
To deal with this problem, convolutional neural networks (CNNs) have been employed to estimate transmissions [4, 26, 35] or predict clear images directly [12, 27, 16, 25]. These methods are valid and superior to the prior-based algorithms with significant performance improvements. However, deep learning-based approaches need to rely on a large amount of real hazy images and their hazefree counterparts for training. In general, it is impractical to acquire large quantities of ground-truth images in the real world. Therefore, most dehazing models resort to training on synthetic hazy dataset. However, due to the domain shift problem, the models learned from synthetic data often fail to generalize well to real data.
问题:传统基于深度学习的去雾算法存在的问题:然而,基于深度学习的方法需要依赖大量真实的模糊图像和对应的模糊图像进行训练。一般来说,在现实世界中获取大量的真实雾图像是不现实的。因此,大多数去雾模型都是在合成模糊数据集上进行训练。然而,由于 domain shift 问题(人工合成雾图像域和真实雾图像域之间的迁移),从综合数据中学习的模型往往不能很好地推广到实际数据。
To address this issue, we propose a domain adaptation framework for single image dehazing. The proposed framework includes two parts, namely an image translation module and two domain-related dehazing modules (one for synthetic domain and another for real domain).
To reduce the discrepancy between domains, our method first employs the bidirectional image translation network to translate images from one domain to another. Since image haze is a kind of noise and nonuniform highly depending on the scene depth, we incorporate the depth information into the translation network to guide the translation of synthetic to real hazy images.
Then, the domain-related dehazing network takes images of this domain, including the original and translated images, as inputs to perform image dehazing. Moreover, we use a consistency loss to ensure that the two dehazing networks generate consistent results. In this training phase, to further improve the generalization of the network in the real domain, we incorporate the real hazy images into the training. We hope that the dehazing results of the real hazy image can have some properties of the clear images, such as dark channel prior and image gradient smoothing. We train the image translation network and dehazing networks in an end-to-end manner so that they can improve each other. As shown in Figure 1, our model produces a cleaner image when compared with recent dehazing work of EPDN [25].
方法: 主要解决 domain shift 问题。该框架包括图像转换模块和域相关去雾模块两部分。
1. bidirectional image translation network:减少域之间的差异;
2. to perform image dehazing: 领域相关去雾网络获取该领域的图像,包括原始图像(人工合成域)和迁移图像(迁移到真实域);还包括了几个小技术:1)使用一致性损失(consistency loss)来确保两个去雾网络产生一致的结果;2)将真实的雾图像纳入到训练中,为了进一步提高网络在真实领域的泛化。
Figure 1
We summarize the contributions of our work as follows:
• We propose an end-to-end domain adaptation framework for image dehazing, which effectively bridges the gap between the synthetic and real-world hazy images.
• We show that incorporating real hazy images into the training process can improve the dehazing performance.
• We conduct extensive experiments on both synthetic datasets and real-world hazy images, which demonstrate that the proposed method performs favorably against the state-of-the-art dehazing approaches.
贡献:
提出了一种用于图像去雾的端到端域适应框架,有效地弥合了合成图像和真实图像之间的差距。
实验结果表明,在训练过程中加入真实的雾图像可以提高去雾性能。
在合成数据集和真实的雾图像上进行了广泛的实验,实验结果表明,该方法优于目前最先进的去雾方法。
Related Work
Domain Adaptation
Domain adaptation aims to reduce the discrepancy between different domains [1, 6, 20]. Existing work either to perform feature-level or pixel-level adaptation. Feature-level adaptation methods aim at aligning the feature distributions between the source and target domains through minimizing the maximum mean discrepancy [19], or applying adversarial learning strategies [32, 31] on the feature space. Another line of research focuses on pixel-level adaptation [3, 28, 7]. These approaches deal with the domain shift problem by applying image-to-image translation [3, 28] learning, or style transfer [7] methods to increase the data in the target domain.
介绍了 DA。
DA:旨在减少不同域之间的差异。有两种,特征级或像素级调整。
特征级:目的在于对齐源域和目标域之间的特性分布,通过最小化最大平均差异,或在特征空间上采用对抗性学习策略。
像素级:目的在于增加目标域中的数据,通过图像到图像的转换学习,或风格迁移方法。
Most recently, many methods perform feature-level and pixel-level adaptation jointly in many visual tasks, e.g., image classification [10], semantic segmentation [5], and depth prediction [37]. These methods [5, 37] translate images from one domain to another with pixel-level adaptation via image-to-image translation networks, e.g., the CycleGAN [38]. The translated images are then inputted to the task network with feature-level alignment. In this work, we take advantage of CycleGAN to adapt the real hazy images to our dehazing model trained on synthetic data. Moreover, since the depth information is closely related to the formulation of image haze, we incorporate the depth information into the translating network to better guide the real hazy image translation.
特征级-像素级联合:第一步,目的在于将图像从一个域转换到另一个域,通过像素级自适应的图像到图像的转换网络 (如CycleGAN) 。迁移后的图像通过特征级对齐方式输入到任务网络中。
本文利用 CycleGAN 将真实的雾图像与人工合成数据上训练的去雾模型相适应。
另外,由于深度信息与图像雾霾形成密切相关,将深度信息融入到迁移网络中,更好的指导真实的雾图像的迁移。
Proposed Method
Method Overview
Given a synthetic dataset and a real hazy image set , where and denote the number of the synthetic and real hazy images, respectively. We aim to learn a single image dehazing model which can accurately predict the clear image from real hazy image. Due to the domain shift, the dehazing model trained only on the synthetic data can not generalize well to the real hazy image.
数据集定义、目标设定和问题描述。
目标:学习一种能够从真实的雾图像中准确地预测出清晰图像的单一图像去雾模型。
问题:由于 domain shift,单纯在合成数据上训练的去雾模型不能很好地应用于真实的雾图像。
To deal with this problem, we present a domain adaptation framework, which consists of two main parts: the image translation network and , and two dehazing networks and . The image translation network translates images from one domain to another to bridge the gap between them. Then the dehazing networks perform image dehazing using both translated images and source images (e.g., synthetic or real).
整体思路:迁移网络 和 ,用于人工合成图像与真实自然图像之间的转换;
和 分别用于对人工合成图像去雾和真实图像去雾。
As illustrated in Figure 2, the proposed model takes a real hazy image and a synthetic image along with its corresponding depth images ds as input. We first obtain the corresponding translated images and using two image translators. And then, we pass and to , and to to perform image dehazing.
Figure 2. Architecture of the proposed domain adaptation framework for image dehazing. The framework consists of two parts, an image translation module and two image dehazing modules. The image translation module translates images from one domain to another to reduce the domain discrepancy. The image dehazing modules perform image dehazing on both synthetic and real domain.
![MyDLNote-Enhancement:[2020 CVPR] Domain Adaptation for Image Dehazing_第2张图片](http://img.e-com-net.com/image/info8/33b9960e1b6c42f4aebee06e85c2f11d.jpg)
整个网络结构如图所示。
Image Translation Module
The image translation module includes two translators: synthetic to real network and real to synthetic network . The network takes as inputs, and generates translated images with similar style to the real hazy images. Another translator performs image translation inversely. Since the depth information is highly correlated to the hazing formulation, we incorporate it into the generator to produce images with similar haze distribution in real cases.
two translators: 人工合成雾图 to 真实雾图; 真实雾图 to 人工合成雾图。
:输入人工合成雾图和深度图;输出迁移的真实雾图和迁移的深度图。
:输入真实雾图;输出迁移的人工合成雾图。
We adopt the spatial feature transform (SFT) layer [33, 15] to incorporate the depth information into the translation network, which can fuse features from depth map and synthetic image effectively. As shown in Fig. 3, the SFT layer first applies three convolution layers to extract conditional maps φ from the depth map. The conditional maps are then fed to the other two convolution layers to predict the modulation parameters, γ and β, respectively. Finally, we can obtain the output shifted features by:
where is the element-wise multiplication. In the translator , we treat the depth map as the guidance and use the SFT layer to transform the features of the penultimate convolution layer. As shown in Fig. 4, the synthetic images are relative closer to the real-world hazy image after the translation.
We show the detailed configurations of the translator in Table 1. We also employ the architectures, provided by CycleGAN [38], for the generator and discriminators ( and ).
本段介绍了如何将深度信息迁移在生成的真实图像中。
SFT 空间特征变换模块,结构不多说了,如图 3 所示。
关于 SFT 的论文:
[2018 CVPR] Recovering realistic texture in image super-resolution by deep spatial feature transform
[2020 TIP] Dynamic scene deblurring by depth guided model
详细的 结构如表 1 所示。
Figure 3. Structure of the SFT layer. In the translator , we consider the depth map as the guidance to assist the image translation.
(a) Synthetic hazy image (b) Translated image (c) Real hazy image
Figure 4. Translated results on two synthetic hazy images.
Table 1. Configurations of image translation module. “Conv” denotes the convolution layer, “Res” denotes the residual block, “Upconv” denotes the up-sample layer by transposed convolution operator and “Tanh” denotes the non-linear Tanh layer
![MyDLNote-Enhancement:[2020 CVPR] Domain Adaptation for Image Dehazing_第3张图片](http://img.e-com-net.com/image/info8/dc75e96e5aed4df1a64e465822a68e80.jpg)
![MyDLNote-Enhancement:[2020 CVPR] Domain Adaptation for Image Dehazing_第4张图片](http://img.e-com-net.com/image/info8/eaf2e7dd6362487c8263447aac1c50ef.jpg)
![MyDLNote-Enhancement:[2020 CVPR] Domain Adaptation for Image Dehazing_第5张图片](http://img.e-com-net.com/image/info8/f7bcf10568844fe29605616de8564286.jpg)
Dehazing Module
Our method includes two dehazing modules and , which perform image dehazing on synthetic and real domains, respectively. takes the synthetic image and the translated image as inputs to perform image dehazing. And is trained on and . For these two image dehazing networks, we both utilize a standard encoder-decoder architecture with skip connections and side outputs as [37]. The dehazing network in each domain shares the same network architecture but with different learned parameters.
去雾网络,就是简单的 U-Net。
说实话,U-Net 真好用。
Training Losses
In the domain adaptation framework, we adopt the following losses to train the network.
迁移网络和去雾网络采用不同的 Loss 函数。
本文的 Loss 函数,有点多。
- Image translation Losses.
The aim of our translate module is to learn the translators and to reduce the discrepancy between the synthetic domain and the real domain . For translators , we expect the to be indistinguishable from the real hazy image . Thus, we employ an image-level discriminators and a feature-level discriminators , to perform a minmax game via an adversarial learning manner. The aims at aligning the distributions between the real image and the translated image . The discriminator helps align the distributions between the feature map of and .
The adversarial losses are defined as:
Similar to GS→R, the translator GR→S has another image-level adversarial loss and feature-level adversarial loss, which are denoted as
,
, respectively
![MyDLNote-Enhancement:[2020 CVPR] Domain Adaptation for Image Dehazing_第6张图片](http://img.e-com-net.com/image/info8/794815ac08e74aadb23bc16506ae6729.jpg)
In addition, we utilize the cycle-consistency loss [38] to regularize the training of translation network. Specifically, when passing an image xs to GS→R and GR→S sequentially, we expect the output should be the same image, and vice versa for xr. Namely,
and
.
The cycle consistency loss can be expressed as:
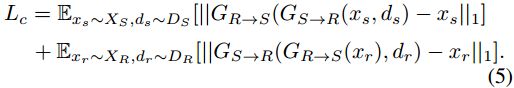
Finally, to encourage the generators to preserve content information between the input and output, we also utilize an identity mapping loss [38], which is denoted as:

The full loss function for the the translating module is as follow:
![MyDLNote-Enhancement:[2020 CVPR] Domain Adaptation for Image Dehazing_第7张图片](http://img.e-com-net.com/image/info8/8068d4f899304f63991422db1c60477b.jpg)
- Image translation Losses:
图像级对抗损失函数(image-level adversarial loss)和特征级对抗损失函数(feature-level adversarial loss):对于从人工合成雾图迁移到真实雾图的网络,adversarial loss 是指迁移的真实图像与真实图像之间的对比(图像级和特征级,两个);同理,对于从真实雾图迁移到人工合成雾图的网络,也是两个对抗损失函数;这样,一共有 4 个损失函数;
一致性损失函数(cycle-consistency loss):是指,从原始人工合成雾图迁移到真实的雾图,再经过真实雾图迁移到人工合成雾图网络,此时的图像与原始人工合成雾图应该比较近似,用 L1 损失函数刻画差别;同理,从原始真实雾图迁移到人工合成的雾图,再经过人工合成雾图迁移到真实雾图网络,得到的图像应该和原始真实雾图相似(说的有些绕,希望大家能够理解);
身份匹配损失函数(identity mapping loss):是指,将人工合成雾图输入到从真实雾图迁移到人工合成雾图网络中,生成的图应和原始人工合成图像相似,用 L1 损失函数刻画差别;相反,将真实雾图输入到从人工合成雾图迁移到真实雾图网络中,生成的图应和原始真实雾图相似。
- Image dehazing Losses.
We can now transfer the synthetic images XS and the corresponding depth images DS to the generator GS→R, and obtain a new dataset XS→R = GS→R(XS, DS), which has a similar style with real hazy images. And then, we train a image dehazing network GR on XS→R and XR in a semi-supervised manner. For supervised branch, we apply the mean squared loss to ensure the predicted images JS→R is close to clean images YS, which can be defined as:
In the unsupervised branch, we introduce the total variation and dark channel losses, which regularize the dehazing network to produce images with similar statistical characteristics of the clear images. The total variation loss is an L1-regularization gradient prior on the predicted images JR:
where ∂h denotes the horizontal gradient operators, and ∂v represents the vertical gradient operators.
Furthermore, the recent work [9] has proposed the concept of the dark channel, which can be expressed as:
where x and y are pixel coordinates of image I, I c represents c-th color channel of I, and N(x) denotes the local neighborhood centered at x. He et al. [9] have also shown that most intensity of the dark channel image are zero or close to zero . Therefore, we apply the following dark channel (DC) loss to ensure that the dark channel of the predicted images are in consistence with that of clean image:
In addition, we also train a complementary image dehazing network GS on XS and XR→S. Similarly, we apply the same supervised loss and unsupervised loss to train the dehazing network GS, which are as follows:
Finally, considering that the outputs of the two dehazing networks should be consistency for real hazy images, i.e., GR(XR) ≈ GS(GR→S(XR)), we introduce following consistency loss:
- Overall Loss Function.
The overall loss function are de- fined as follow:
where λm, λd, λt and λc are trade-off weights.
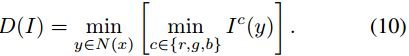
![MyDLNote-Enhancement:[2020 CVPR] Domain Adaptation for Image Dehazing_第8张图片](http://img.e-com-net.com/image/info8/56ae0e21f2cb41ac823ea989df6e2f38.jpg)
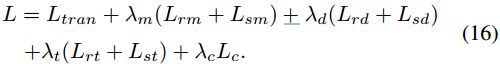
- Image dehazing Losses.
L2 损失函数(mean squared loss):先将人工合成雾图迁移到真实雾图,然后去雾,得到的图与 GT 的 L2 损失函数;
全变差损失函数和暗通道损失函数(total variation and dark channel losses);
一致性损失(consistency loss):真实雾图经过真实雾图去雾网络,与真实雾图迁移到人工合成的雾图经过真实雾图去雾网络得到的结果应该相似。