【AI视野·今日CV 计算机视觉论文速览 第182期】Fri, 10 Apr 2020
AI视野·今日CS.CV 计算机视觉论文速览
Fri, 10-11 Apr 2020
Totally 55 papers
上期速览✈更多精彩请移步主页

Interesting:
*****神经渲染技术前沿,综述了目前前沿的神经渲染技术及其应用,包括图像操控,内容合成、新视角合成、自由视点、重光照模型、人脸、肢体重建等等。 (from MPI Informatics,Stanford University,Technical University of Munich,Facebook Reality Labs ,Adobe Research ,Google)

****基于可编程LED照片整列的虚拟荧光显微镜, (from 杜克大学 谷歌)
标准和优化后的照明模式下得到的显微结果:
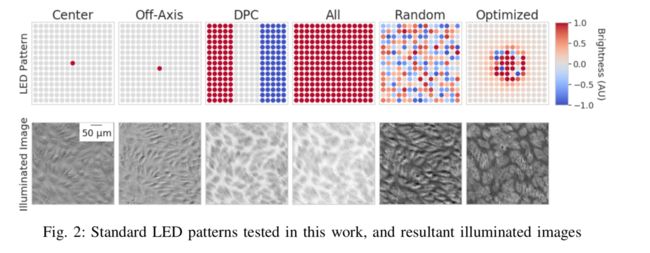
实验结果如下:

project:www.github.com/clvcooke/virtual-fluorescence
*****基于深度补全的3D立体照相成像技术, 提出了一种将单张RGBD图像转换为多视角合成的3D照片的方法,基于多层表达并利用层级深度图像和隐式的像素连续性表达来得到遮挡区域的色彩和深度信息。(from 弗吉尼亚理工)
深度和彩色图像补全流程:
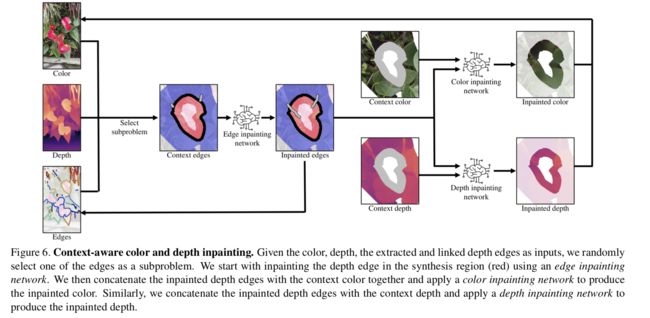
补全后的结果对比:
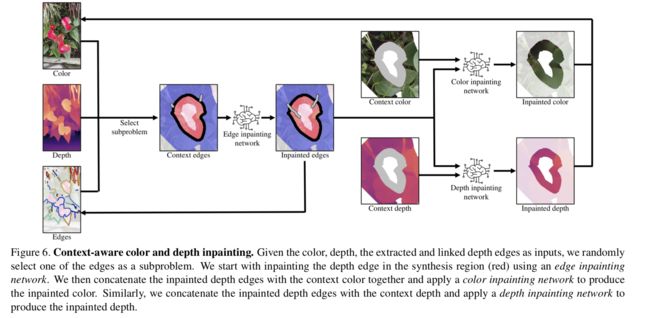
code:https://shihmengli.github.io/3D-Photo-Inpainting
****ARCH人体服装动作渲染模型, 基于二维图像输入实现三维人体着装模型重建和迁移(from facebook reality lab)
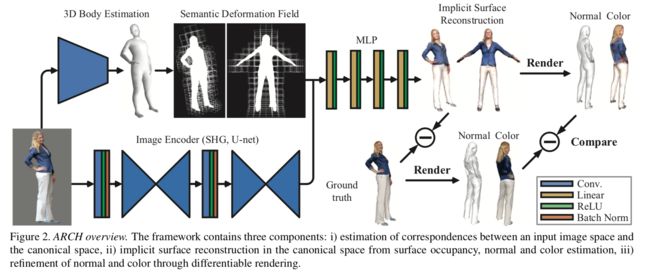
模型中使用的可差分渲染结果:
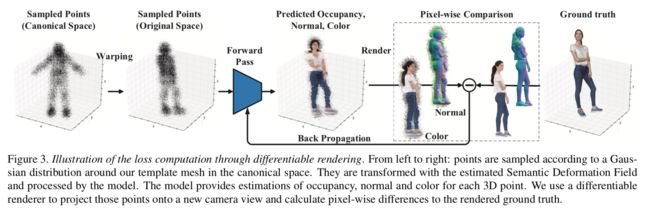
dataset:
RenderPeople dataset:http://renderpeople.com
AXYZ2 dataset: http://secure.axyz- design.com/
BUFF dataset:Detailed, accurate, human shape estimation from clothed 3D scan sequences.
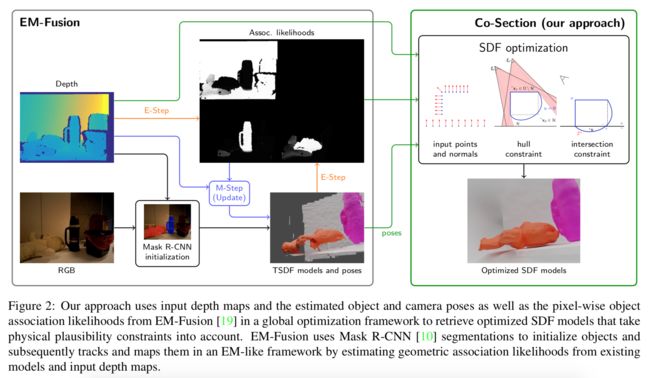
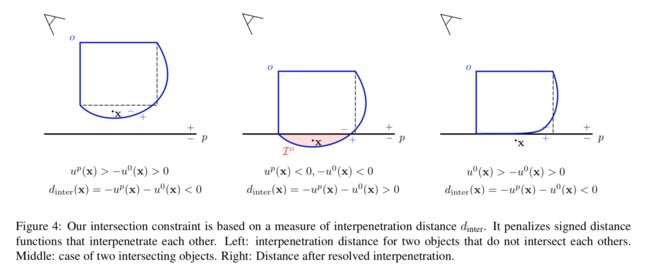
Co- Section三维动态场景重建方法,基于物体间的重合约束来推理出隐藏面的形状信息,其中物体级别的slam前段用于检测、分割、跟踪和映射场景目标,而后段则利用hull和物体间交叉重合约束来实现形状补全。 (from 马普研究所 Embodied Vision Group 图宾根)
交叉约束的示意图:
一些对动态目标的重建结果及其比较:
****用于多视角重建的神经描述子, 提出了一种高效的多类可学习目标描述子,结合了概率和可差分渲染引起,可以从单张或多张RGB-D图像中推理出目标形状(from 帝国理工 Dyson Robotics Lab)
使用的占据自编码器和优化框架,通过迭代循环来获取最终的描述子 :
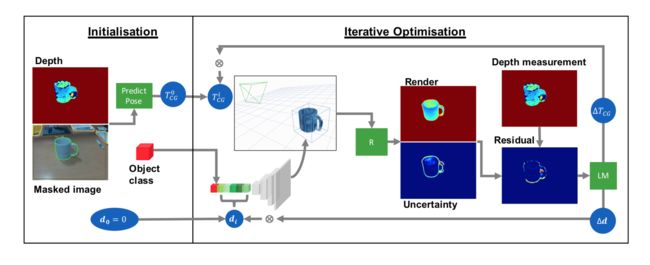
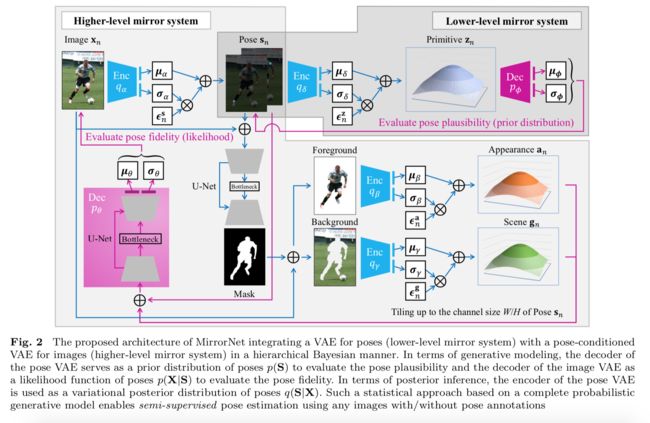
MirrorNet基于深度贝叶斯网络的人体位姿检测模型, (from 早稻田大学)
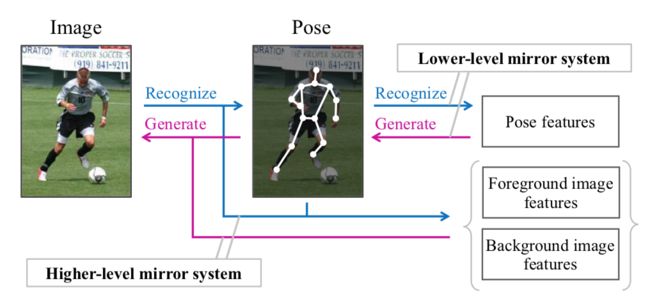
系统架构如下图所示:
弱监督点云分割方法, (from )
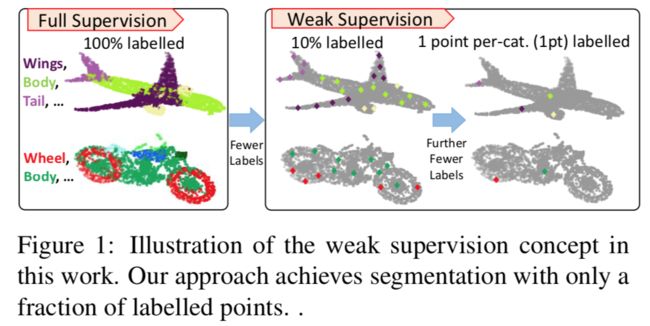
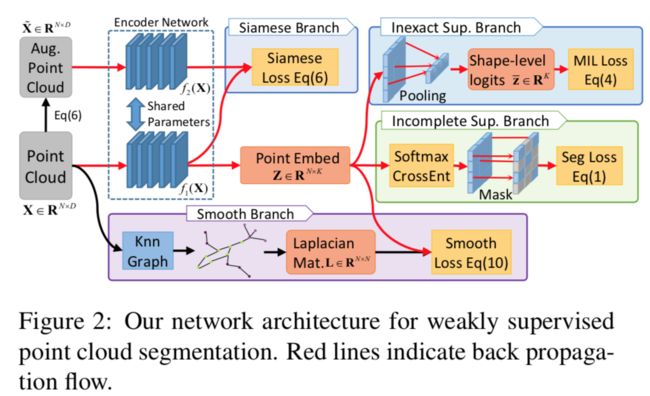
code:https://github.com/alex-xun-xu/WeakSupPointCloudSeg
TuiGAN多功能的条件生成模型用于未配对图像间的图像风格迁移, (from 中科大 微软亚洲研究院)
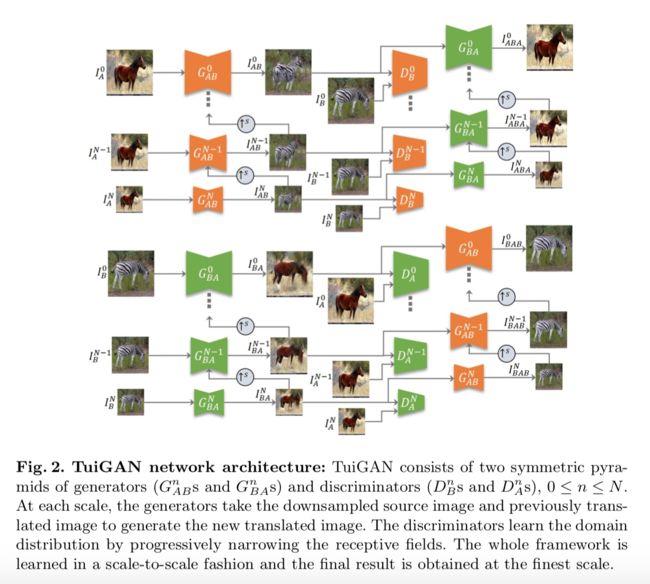
生成器的架构:
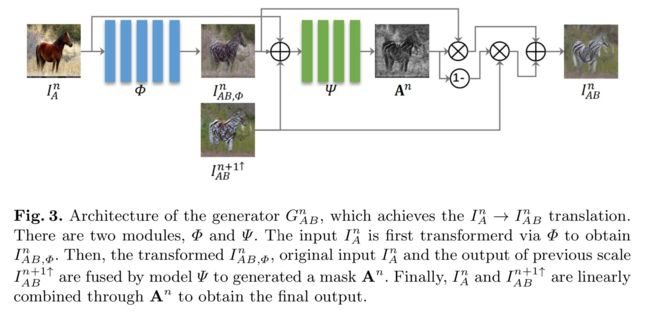
一些图像间的迁移结果:
code:https://github.com/linjx-ustc1106/TuiGAN-PyTorch
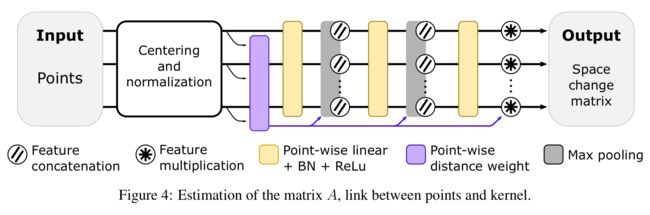
****LIGHTCONVPOINT用于点云分割的模型, (from valeo.ai)
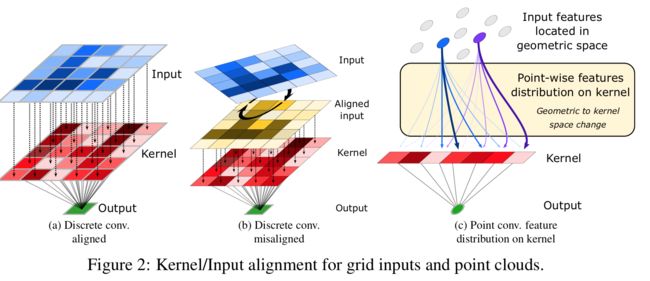
估计核与点之间的联系矩阵A:
MoreFusion多目标6D位姿推理, (from 帝国理工戴森实验室)
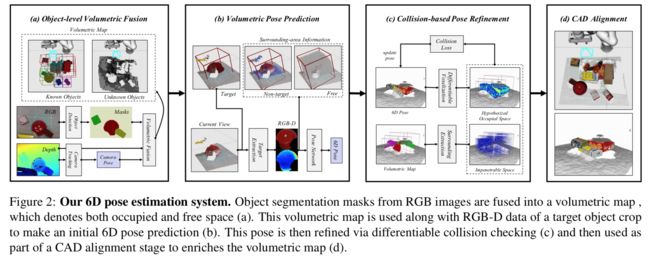
基于RGBD的位姿预测网络:

ref code:https://github.com/j96w/DenseFusion
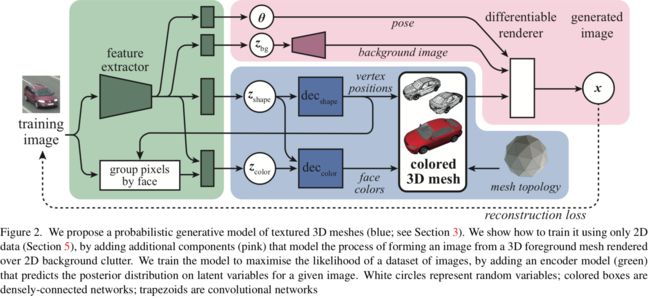
基于2D图像的三维纹理网格生成模型, (from IST Austria & ibm)
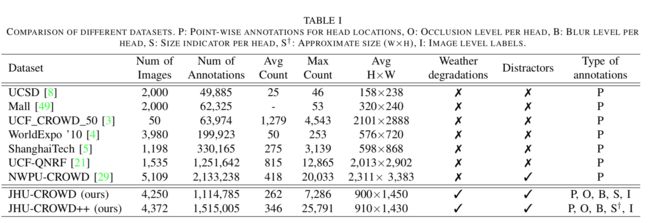
JHU-CROWD++人群密度检测数据集, (from 约翰霍普金斯)

web: http://www.crowd- counting.com
more:
基于注意力机制和特征融合的图像超分辨
物种地理空间分布The GeoLifeCLEF 2020 Dataset
基于航空图像和板在图像的野外道路的顺滑行驶
MNIST-MIX多语言手写数字识别系统
SA-UNet视网膜血管分割模型,数据集:Vascular Extraction (DRIVE) dataset,Child Heart and Health Study (CHASE_DB1) dataset
基于深度残差网络的视网膜血管分割,数据集:IOSTAR www.retinacheck.org RC-SLO www.retinacheck.org
基于多任务深度学习的COVID-19检测
基于深度特征融合与排序技术的COVID-19分类
TypeNet基于键盘按键过程的生物特征,dataset typeDNA:Observations on typing from 136 million keystrokes
Daily Computer Vision Papers
| X3D: Expanding Architectures for Efficient Video Recognition Authors Christoph Feichtenhofer 本文介绍了X3D,这是一个有效的视频网络系列,它沿空间,时间,宽度和深度的多个网络轴逐步扩展了微小的2D图像分类体系结构。受到机器学习中特征选择方法的启发,采用了一种简单的逐步网络扩展方法,该方法在每个步骤中都扩展了单个轴,从而实现了在复杂度折衷方面的良好准确性。为了将X3D扩展到特定的目标复杂度,我们执行渐进式正向扩展,然后进行反向收缩。 X3D达到了最先进的性能,同时所需的乘法加法和参数减少了4.8倍和5.5倍,以达到与以前的工作类似的精度。我们最令人惊讶的发现是,具有高时空分辨率的网络可以很好地运行,而在网络宽度和参数方面却非常轻。我们在视频分类和检测基准方面以前所未有的效率报告了具有竞争力的准确性。代码将在以下位置提供 |
| 3D Photography using Context-aware Layered Depth Inpainting Authors Meng Li Shih, Shih Yang Su, Johannes Kopf, Jia Bin Huang 我们提出了一种用于将单个RGB D输入图像转换为3D照片的方法,以用于新颖视图合成的多层表示形式,该方法在原始视图中包含的区域包含幻觉的颜色和深度结构。我们使用具有显式像素连通性的分层深度图像作为基础表示,并提出一种基于学习的修复模型,该模型以空间上下文感知的方式将新的局部颜色和深度内容合成到被遮挡的区域中。使用标准图形引擎,可以使用运动视差有效地渲染生成的3D照片。我们在各种具有挑战性的日常场景中验证了我们方法的有效性,并且与现有技术相比,所显示的伪像更少。 |
| Instance-aware, Context-focused, and Memory-efficient Weakly Supervised Object Detection Authors Zhongzheng Ren, Zhiding Yu, Xiaodong Yang, Ming Yu Liu, Yong Jae Lee, Alexander G. Schwing, Jan Kautz 通过减少训练过程中对强大监督的需求,弱监督学习已成为一种用于目标检测的引人注目的工具。然而,主要挑战仍然是1。对象实例的区分可能是模棱两可的。2)检测器倾向于集中于区分部分而不是整个对象。3没有地面真理,对象建议对于高召回率必须是多余的,从而导致大量内存消耗。解决这些挑战非常困难,因为通常需要消除不确定性和简单的解决方案。为了解决这些问题,我们开发了一个实例感知和上下文相关的统一框架。它采用实例感知的自我训练算法和可学习的具体DropBlock,同时设计了内存有效的顺序批处理反向传播。我们提出的方法在COCO 12.1 AP,24.8 AP 50,VOC 2007 54.9 AP和VOC 2012 52.1 AP上达到了最先进的结果,大大提高了基线。此外,该方法是第一个对基于ResNet的模型和弱监督视频对象检测进行基准测试的方法。请参阅我们的项目页面以获取代码,模型和更多详细信息 |
| Scalable Active Learning for Object Detection Authors Elmar Haussmann, Michele Fenzi, Kashyap Chitta, Jan Ivanecky, Hanson Xu, Donna Roy, Akshita Mittel, Nicolas Koumchatzky, Clement Farabet, Jose M. Alvarez 以完全监督的方式训练的深度神经网络是基于感知的自动驾驶系统中的主导技术。尽管收集大量未标记的数据已经是一项重要的工作,但是由于需要高质量的注释,因此人类只能对其中的一部分进行标记。因此,寻找正确的数据进行标记已成为一项关键挑战。主动学习是一种有力的技术,可以提高监督学习方法的数据效率,因为它的目的是选择尽可能小的训练集以达到要求的性能。我们建立了可扩展的生产系统,用于自动驾驶领域的主动学习。在本文中,我们描述了由此产生的高级设计,概述了一些挑战及其解决方案,大规模地介绍了我们目前的结果,并简要描述了未解决的问题和未来的方向。 |
| TuiGAN: Learning Versatile Image-to-Image Translation with Two Unpaired Images Authors Jianxin Lin, Yingxue Pang, Yingce Xia, Zhibo Chen, Jiebo Luo 无监督的图像到图像的转换UI2I任务处理学习没有配对图像的两个域之间的映射。现有的UI2I方法通常需要来自不同域的大量不成对的图像进行训练,但是在许多情况下,训练数据非常有限。在本文中,我们认为即使每个域都包含单个图像,仍可以实现UI2I。为此,我们提出了TuiGAN,这是一种生成模型,仅在两幅不成对的图像上进行训练,相当于一次射击的无监督学习。使用TuiGAN,可以将图像以粗糙到精细的方式进行转换,然后将生成的图像从全局结构逐步细化为局部细节。我们进行了广泛的实验,以验证我们的通用方法可以胜任各种UI2I任务的强基准。此外,TuiGAN能够与训练有足够数据的最新UI2I模型取得可比的性能。 |
| Where Does It End? -- Reasoning About Hidden Surfaces by Object Intersection Constraints Authors Michael Strecke, Joerg Stueckler 动态场景理解是机器人技术和VR AR的基本功能。在本文中,我们提出了Co Section,这是一种基于优化的3D动态场景重构方法,可以从相交约束中推断出隐藏的形状信息。对象级动态SLAM前端可以检测,分割,跟踪和映射场景中的动态对象。我们的优化后端使用对象之间的外壳和相交约束来完善形状。在实验中,我们演示了在真实和合成动态场景数据集上的方法。我们还定量评估了我们方法的形状完成性能。据我们所知,我们的方法是在能量最小化框架中将此类物理合理性约束并入对象相交处以完成动态对象的形状的第一种方法。 |
| AdaStereo: A Simple and Efficient Approach for Adaptive Stereo Matching Authors Xiao Song, Guorun Yang, Xinge Zhu, Hui Zhou, Zhe Wang, Jianping Shi 在本文中,我们尝试解决深度立体声匹配网络的域自适应问题。与其求助于黑匣子结构或层来寻找跨域的隐式连接,我们不如研究立体声匹配的适应缺口。通过目视检查和广泛的实验,我们得出结论,低水平对齐对于自适应立体声匹配至关重要,因为跨域的主要差距在于输入颜色和成本量分布的不一致。相应地,我们设计了一种自底向上的域自适应方法,其中提出了两种特定的方法,即颜色转移和成本正则化,可以很容易地将其集成到现有的立体声匹配模型中。通过颜色传输,可以在训练过程中将大量合成数据传输到具有目标域的相同颜色空间。成本正则化可以进一步将较低层的功能和成本量限制在域不变分布中。尽管我们提出的策略很简单并且没有可供学习的参数,但是它们确实可以极大地提高现有视差网络的泛化能力。我们跨多个数据集进行实验,包括场景流,KITTI,Middlebury,ETH3D和DrivingStereo。与以前的领域不变方法相比,我们的合成数据预训练模型在没有哨声的情况下达到了最新的跨领域性能,甚至在多个立体声匹配基准上用目标领域的基本情况进行了微调的先进的视差网络也是如此。 |
| Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation Authors Yude Wang, Jie Zhang, Meina Kan, Shiguang Shan, Xilin Chen 图像级别的弱监督语义分割是一个具有挑战性的问题,近年来已对此进行了深入研究。大多数高级解决方案都利用类激活图CAM。但是,由于全面监督与弱监督之间的差距,CAMs几乎不能用作目标遮罩。在本文中,我们提出了一种自我监督的等方注意机制SEAM,以发现更多的监督并缩小差距。我们的方法基于这样的观察,即等方差是完全监督语义分割中的隐式约束,在数据增强期间,其像素级别标签与输入图像具有相同的空间变换。但是,在图像级监督训练的CAM上失去了这种约束。因此,我们建议对来自各种变换图像的预测CAM进行一致性正则化,以为网络学习提供自我监督。此外,我们提出了一种像素相关模块PCM,该模块利用上下文外观信息并通过其相似的邻居改进当前像素的预测,从而进一步提高CAM的一致性。在PASCAL VOC 2012数据集上进行的大量实验表明,在相同的监督水平下,我们的方法优于最新方法。该代码在线发布。 |
| Sequential Neural Rendering with Transformer Authors Phong Nguyen Ha, Lam Huynh, Esa Rahtu, Janne Heikkila 本文解决了通过神经渲染合成新视图的问题,其中我们有兴趣根据其他观点基于给定的一组输入图像来预测任意相机姿势下的新视图。使用已知的查询姿势和输入姿势,我们创建了一组有序的观测值,这些观测值可以通往目标视图。因此,将单个新颖视图合成的问题重新表述为顺序视图预测任务。在本文中,提出的基于变压器的生成查询网络T GQN通过添加两个新概念扩展了神经渲染方法。首先,我们在上下文图像之间使用多视图注意力学习来获取多个隐式场景表示。其次,我们引入顺序渲染解码器,根据学习的表示来预测图像序列,包括目标视图。我们在各种具有挑战性的综合数据集上评估了我们的模型,并证明了我们的模型可以给出一致的预测,并且比以前的体系结构更快地实现训练收敛。 |
| Spatial Information Guided Convolution for Real-Time RGBD Semantic Segmentation Authors Lin Zhuo Chen, Zheng Lin, Ziqin Wang, Yong Liang Yang, Ming Ming Cheng 已知3D空间信息对于语义分割任务是有益的。大多数现有方法将3D空间数据作为附加输入,从而导致两个流分割网络分别处理RGB和3D空间信息。该解决方案大大增加了推理时间,并严重限制了其在实时应用中的范围。为了解决这个问题,我们提出了空间信息引导的卷积S Conv,它允许有效的RGB特征和3D空间信息集成。 S Conv能够根据3D空间信息推断卷积核的采样偏移量,从而帮助卷积层调整接收场并适应几何变换。 S Conv还通过生成空间自适应卷积权重将几何信息纳入特征学习过程。感知几何的能力大大增强,而没有太大影响参数的数量和计算成本。我们进一步将S Conv嵌入到称为空间信息导向卷积网络SGNet的语义分割网络中,从而实时推断出NYUDv2和SUNRGBD数据集的性能。 |
| A Proposed IoT Smart Trap using Computer Vision for Sustainable Pest Control in Coffee Culture Authors Vitor Alexandre Campos Figueiredo, Samuel Mafra, Joel Rodrigues 物联网物联网正在作为一种多用途技术而出现,它在改善多个领域的生活质量方面具有巨大的潜力。尤其是,物联网已在农业中应用,以使其在生态上更具可持续性。例如,电子陷阱有可能在不使用任何农药的情况下进行害虫控制。在本文中,提出了一种具有IoT功能的智能陷阱,该陷阱使用计算机视觉来识别目标昆虫。该解决方案包括1个带有摄像头,GPS传感器和电机执行器的嵌入式系统2个作为数据库服务提供商的IoT中间件,以及3个通过可配置的热图显示数据的Web应用程序。公开了所提出的解决方案的论据,并且主要结论是对人工林中有害生物浓度的认识以及作为基于农药的传统防治方法的替代性有害生物防治方法的可行性。 |
| Multi-Granularity Canonical Appearance Pooling for Remote Sensing Scene Classification Authors S. Wang, Y. Guan, L. Shao 由于较大的视觉语义差异,识别遥感场景图像仍然具有挑战性。这些主要是由于缺少可用于将像素级别表示与高级语义标签对齐的详细注释而引起的。由于标记过程是劳动密集型的并且是主观的,因此我们提出一种新颖的多粒度规范化外观合并MG CAP,以自动捕获遥感数据集的潜在本体结构。我们设计了一个精细的框架,该框架允许逐步裁剪输入图像以学习多颗粒特征。对于每个特定的粒度,我们从一组预定义的转换中发现规范的外观,并通过基于maxout的Siamese样式体系结构学习相应的CNN功能。然后,我们用高斯协方差矩阵替换标准的CNN特征,并采用适当的矩阵归一化来提高特征的判别能力。此外,我们为在GPU中训练特征值分解函数EIG提供了稳定的解决方案,并使用矩阵演算演示了相应的反向传播。大量实验表明,我们的框架可以在公共遥感场景数据集中取得可喜的成果。 |
| Neural Object Descriptors for Multi-View Shape Reconstruction Authors Edgar Sucar, Kentaro Wada, Andrew Davison 场景表示的选择对于它要求的形状推断算法和它启用的智能应用程序都是至关重要的。我们提出了一种高效且可优化的多类学习对象描述符,以及一种新颖的概率和差分渲染引擎,用于从一个或多个RGB D图像进行原理上的完整对象形状推断。我们的框架可实现准确而强大的3D对象重建,从而实现多种应用,包括机器人抓取和放置,增强现实以及能够与相机轨迹一起优化对象姿态和形状的第一个对象级SLAM系统。 |
| LightConvPoint: convolution for points Authors Alexandre Boulch, Gilles Puy, Renaud Marlet 用于点云语义分割的最新技术水平是基于为点云定义的卷积。在本文中,我们提出了一种直接从图像处理中的离散卷积设计的点云卷积公式。所得公式强调了离散的内核空间与点所在的几何空间之间的分隔。这两个空间之间的链接是通过更改空间矩阵mathbf A完成的,该矩阵将输入特征分布在卷积内核上。几种现有的方法都属于这种提法。我们表明,可以使用神经网络轻松估计矩阵mathbfA。最后,我们在几个语义分割基准上显示出了有竞争力的结果,同时在计算时间和内存上都非常有效。 |
| Decoupled Gradient Harmonized Detector for Partial Annotation: Application to Signet Ring Cell Detection Authors Tiancheng Lin, Yuanfan Guo, Canqian Yang, Jiancheng Yang, Yi Xu 对印戒细胞癌的早期诊断大大提高了患者的生存率。由于缺乏公共数据集和专家级别的注释,对印章环格SRC的自动检测尚未进行深入研究。在MICCAI DigestPath2019挑战中,除了前景SRC区域背景正常组织区域类别不平衡之外,由于昂贵的医学图像注释会部分注释SRC,这会引入额外的标签噪声。为了同时解决这些问题,我们提出了解耦梯度协调机制DGHM并将其嵌入分类损失中,称为DGHM C损失。具体而言,除了阳性SRC和阴性正常组织样本,我们还将噪声样本与干净样本进一步分离,并分别协调分类中的相应梯度分布。在没有哨音的情况下,我们在挑战赛中获得了第二名。消融研究和受控的标签缺失率实验表明,DGHM C损失可以对部分注释的对象检测带来实质性的改善。 |
| CenterMask: single shot instance segmentation with point representation Authors Yuqing Wang, Zhaoliang Xu, Hao Shen, Baoshan Cheng, Lirong Yang 本文提出了一种简单,快速,准确的单镜头实例分割方法。一阶段实例分割对象实例的区分和逐像素特征对齐有两个主要挑战。因此,我们将实例分割分解为两个并行的子任务,即使在重叠条件下也可以将实例分离出来的局部形状预测,以及将全局图像以像素到像素的方式分割的全局显着性。两个分支的输出被组装以形成最终实例掩码。为了实现这一点,从对象中心点的表示中采用局部形状信息。拟议的CenterMask从零开始进行了全面培训,没有任何风吹草动,使用具有挑战性的COCO数据集的单一模型和单一规模的培训测试,可以以12.3 fps的速度实现34.5蒙版AP。除TensorMask慢了5倍之外,其准确性比所有其他一级实例分割方法都高,这表明CenterMask的有效性。此外,我们的方法可以轻松地嵌入到其他一级物体检测器(例如FCOS)中,并且性能良好,显示了CenterMask的生成。 |
| DeepSEE: Deep Disentangled Semantic Explorative Extreme Super-Resolution Authors Marcel Christoph B hler, Andr s Romero, Radu Timofte 根据定义,超分辨率SR是不适当的。对于给定的低分辨率自然图像,可能存在无限多个可能的高分辨率变体。这就是为什么基于示例的SR方法研究针对面部幻觉的放大系数高达4倍或8倍的原因。当前的大多数文献都针对高重建保真度或照片逼真的感知质量的单一确定性解决方案。在这项工作中,我们提出了一个新颖的框架DeepSEE,用于深度解开的语义探索极度超分辨率。据我们所知,DeepSEE是第一种利用语义图进行探索性超分辨率的方法。特别是,它提供了对语义区域,它们的不整齐外观的控制,并允许进行广泛的图像处理。我们验证DeepSEE的放大率高达32倍,并探索超分辨率的空间。 |
| Self-Supervised 3D Human Pose Estimation via Part Guided Novel Image Synthesis Authors Jogendra Nath Kundu, Siddharth Seth, Varun Jampani, Mugalodi Rakesh, R. Venkatesh Babu, Anirban Chakraborty 相机捕捉到的人体姿势是多种变化来源的结果。有监督的3D姿势估计方法的性能是以消除诸如形状和外观之类的变化为代价的,这对于解决其他相关任务可能是有用的。结果,学习模型不仅灌输任务偏差,而且灌输数据集偏差,因为它强烈依赖于带注释的样本,对于弱监督模型也是如此。认识到这一点,我们提出了一种自我监督的学习框架,以消除未标记视频帧的这种变化。我们利用有关人体骨骼和姿势的先验知识,其形式为基于单个零件的2D人偶模型,人体姿势清晰度约束和一组未配对的3D姿势。我们的差异化形式弥合了3D姿势和空间零件图之间的表示差异,不仅有助于发现可解释的姿势解缠结,而且还使我们能够处理具有多种相机运动的视频。对野生数据集中看不见的定性结果建立了我们对多个任务的卓越概括,超出了3D姿态估计和零件分割的主要任务。此外,我们展示了在Human3.6M和MPI INF 3DHP数据集上进行弱监督3D姿态估计的最新技术。 |
| Online Meta-Learning for Multi-Source and Semi-Supervised Domain Adaptation Authors Da Li, Timothy Hospedales 域适应DA是从标记的源数据集中适应模型的主题问题,以便它们在仅未标记或部分标记的数据可用的目标数据集上表现良好。已经提出了许多方法来通过不同的方式来解决该问题,以最小化源数据集和目标数据集之间的域偏移。在本文中,我们采用正交的观点,并提出了一种通过元学习现有DA算法的初始条件来进一步提高性能的框架。由于涉及的计算图的长度,与更广泛考虑的少数镜头元学习设置相比,这具有挑战性。因此,我们提出了一种在线最短路径元学习框架,该框架在计算上既易于处理又在提高DA性能方面切实有效。我们提出了多源非监督域自适应MSDA和半监督域自适应SSDA的变体。重要的是,我们的方法与基本的自适应算法无关,可用于改进许多技术。通过实验,我们展示了对经典DANN以及针对MSDA和SSDA的最新MCD和MME技术的改进,并最终在包括最大规模的DomainNet在内的多个DA基准测试中取得了最先进的结果。 |
| Hierarchical Group Sparse Regularization for Deep Convolutional Neural Networks Authors Kakeru Mitsuno, Junichi Miyao, Takio Kurita 在深度神经网络DNN中,参数数量通常非常庞大,以获取较高的学习性能。因此,它会占用大量内存和大量计算资源,并且还会导致过拟合。众所周知,某些参数是冗余的,可以在不降低性能的情况下将其从网络中删除。已经提出了许多稀疏的正则化准则来解决该问题。在卷积神经网络CNN中,经常使用组稀疏正则化来删除不必要的权重子集,例如过滤器或通道。当我们对连接到神经元的权重应用组稀疏正则化时,每个卷积滤波器在正则化中均不会被视为目标组。在本文中,我们引入了层次分组的概念来解决此问题,并提出了一些针对CNN的层次分组稀疏正则化准则。我们提出的分层组稀疏正则化可以将输入神经元或输出神经元的权重视为一个组,而将卷积滤波器视为同一组中的一个组,以修剪不必要的权重子集。结果,我们可以根据网络的结构和保持高性能的通道数来更适当地调整权重。在实验中,我们通过对具有几种网络体系结构的公共数据集进行深入的对比实验,研究了提出的稀疏正则化方法的有效性。代码在GitHub上可用 |
| Universal Source-Free Domain Adaptation Authors Jogendra Nath Kundu, Naveen Venkat, Rahul M V, R. Venkatesh Babu 有强烈的动机去开发通用的学习技术,该技术可以在存在域迁移的情况下将类可分离性的知识从标记的源域转移到未标记的目标域。由于现有领域适应性DA方法依赖于源目标标签集关系的知识,因此无法用于实际的DA场景。封闭集,开放集或部分DA。此外,几乎所有先前的无监督DA工作甚至在部署期间都要求源样本和目标样本共存,这使其不适用于实时适应。缺乏这种不切实际的假设,我们提出了一种新颖的两阶段学习过程。 1在采购阶段,假设没有对即将出现的类别差距和领域转移的事先了解,我们旨在为将来的无源部署提供该模型。为了实现这一目标,我们在新颖的生成分类器框架中,通过利用可用的源数据来增强模型拒绝源分布样本的能力。 2在“部署”阶段,目标是设计一种统一的适应算法,该算法能够在广泛的类别差距范围内运行,而无需访问以前看到的源样本。为此,与使用复杂的对抗训练机制相反,我们通过利用一种新颖的实例级别加权机制(称为“源相似度度量” SSM)定义了一个简单而有效的无源自适应目标。全面的评估表明,即使在依赖于现有技术的最先进方法中,具有卓越DA性能的拟议学习框架的实用可用性也是如此。 |
| Towards Inheritable Models for Open-Set Domain Adaptation Authors Jogendra Nath Kundu, Naveen Venkat, Ambareesh Revanur, Rahul M V, R. Venkatesh Babu 域自适应DA在视觉识别任务方面取得了巨大进步。特别地,开放集DA已引起相当大的关注,其中目标域包含其他看不见的类别。现有的开放集DA方法要求访问带有标记的源数据集以及未标记的目标实例。但是,在数据共享由于其专有性质或隐私问题而受到限制的情况下,这种对共存源数据和目标数据的依赖非常不切实际。针对这一问题,我们介绍了一种实用的DA范式,其中在将来没有源数据集的情况下,使用经过源训练的模型来促进自适应。为此,我们将知识可继承性形式化为一个新颖的概念,并提出了一个简单而有效的解决方案,以实现适用于上述实际范式的可继承模型。此外,我们提出了一种量化继承性的客观方法,即使在没有源数据的情况下,也可以为给定的目标域选择最合适的源模型。我们提供理论上的见解,然后进行全面的经验评估,以证明最先进的开放集领域自适应性能。 |
| Masked GANs for Unsupervised Depth and Pose Prediction with Scale Consistency Authors Chaoqiang Zhao, Gary G. Yen, Qiyu Sun, Chongzhen Zhang, Yang Tang 先前的工作表明,对抗学习可用于无监督的单眼深度和视觉里程法VO估计。但是,姿势和深度网络的性能受到遮挡和视野变化的限制。由于运动引起的帧之间的视觉信息不完全对应,因此无法通过视图重建和双线性插值从源图像中完全合成目标图像。基于合成目标图像与实际目标图像之间差异的重建损失将受到不完整重建的影响。此外,将学习未重构区域的数据分布,并帮助鉴别器区分真实图像和伪图像,从而导致生成器可能无法与鉴别器竞争的情况。因此,本文设计了一种MaskNet来预测这些区域并减少其对重建损失和对抗损失的影响。未重构区域对鉴别器的影响通过提出布尔掩码方案来解决,如图1所示。此外,我们通过利用新的尺度一致性损失来考虑我们的姿势网络的尺度一致性,因此我们的姿势网络能够提供长单眼序列上的完整相机轨迹。在KITTI数据集上进行的大量实验表明,本文提出的每个组件都对性能有所贡献,并且我们的深度和轨迹预测均达到了竞争性能。 |
| Reciprocal Learning Networks for Human Trajectory Prediction Authors Hao Sun, Zhiqun Zhao, Zhihai He 我们观察到,人类的轨迹不仅向前可预测,而且向后可预测。向前和向后的轨迹都遵循相同的社会规范,并遵循相同的物理约束,只是时间方向不同。基于这种独特的属性,我们开发了一种用于人体轨迹预测的新方法,称为对等学习。向前和向后预测网络这两个网络紧密耦合,满足了互惠约束,可以共同学习。基于此约束,我们借鉴了深度神经网络的对抗攻击的概念,该概念反复修改网络的输入以匹配给定或强制的网络输出,并开发了一种新的网络预测方法,称为对等攻击的倒数攻击。这进一步提高了预测准确性。我们在基准数据集上的实验结果表明,我们的新方法优于人类轨迹预测的最新方法。 |
| MoreFusion: Multi-object Reasoning for 6D Pose Estimation from Volumetric Fusion Authors Kentaro Wada, Edgar Sucar, Stephen James, Daniel Lenton, Andrew J. Davison 机器人和其他智能设备需要从其车载视觉系统中获得高效的基于对象的场景表示,以推断出接触,物理和遮挡的原因。可识别的精确对象模型将与不可识别结构的非参数重建一起发挥重要作用。我们提出了一种系统,该系统可以从实时,体现的多视图视觉估计接触和遮挡的多个已知对象的准确姿势。我们的方法从单个RGB D视图中提出3D对象姿势建议,在摄像机移动时从多个视图中累积姿势估计和非参数占用信息,并执行联合优化以估计接触的多个对象的一致,不相交的姿势。 |
| Quasi-Newton Solver for Robust Non-Rigid Registration Authors Yuxin Yao, Bailin Deng, Weiwei Xu, Juyong Zhang 不完善的数据噪声,异常值和部分重叠以及高度的自由度使非刚性配准成为计算机视觉中的经典难题。现有方法通常采用ell p型鲁棒估计量来使拟合和平滑度正规化,并且使用近端算子来解决由此产生的非平滑问题。然而,这些算法的缓慢收敛限制了其广泛的应用。在本文中,我们提出了一种基于全局平滑鲁棒估计量的鲁棒非刚性配准公式,用于数据拟合和正则化,可以处理离群值和部分重叠。我们对该问题应用了最小化最小化算法,该算法将每次迭代减少为使用L BFGS解决简单的最小二乘问题。大量实验证明了我们的方法在具有异常值和部分重叠的两种形状之间进行非刚性对齐的有效性,定量评估表明,该方法在配准精度和计算速度方面均优于最新方法。源代码位于 |
| Identification of splicing edges in tampered image based on Dichromatic Reflection Model Authors Zhe Shen, Peng Sun, Yubo Lang, Lei Liu, Silong Peng 成像是一个复杂的过程,结合了大量的光电转换,这会导致最终图像中超出视觉感知的某些光谱特征。对原始图像的任何操纵都将破坏这些签名,并不可避免地在最终的伪造品中留下一些痕迹。因此,我们提出了一种新颖的光学物理方法,以将拼接边缘与篡改图像中的自然边缘区分开。首先,我们将取证图像从RGB转换为S和o1o2的色彩空间。然后在二色反射模型的假设下,通过合成梯度发现图像中的边缘,并根据其不同的光度特性将其分类为不同的类型。最后,通过简单的逻辑算法将拼接边缘保留为自然边缘。实验结果表明了该方法的有效性。 |
| Learning to Scale Multilingual Representations for Vision-Language Tasks Authors Andrea Burns, Donghyun Kim, Derry Wijaya, Kate Saenko, Bryan A. Plummer 当前的多语言视觉语言模型或者每种支持的语言都需要大量附加参数,或者随着添加语言而导致性能下降。在本文中,我们提出了一种可伸缩的多语言对齐语言表示法SMALR,该语言可以在不牺牲下游任务性能的情况下以很少的模型参数来表示多种语言。 SMALR在多语言词汇表中为大多数单词学习固定大小的语言不可知表示,而很少有语言特定的功能。我们使用一种新颖的掩盖式跨语言建模损失来使特征与其他语言的上下文对齐。此外,我们提出了一种跨语言一致性模块,以确保对查询及其机器翻译的预测具有可比性。十种不同的语言证明了SMALR的有效性,是迄今为止视觉语言任务支持数量的两倍以上。与其他词嵌入方法相比,我们对多语言图像句子检索进行了评估,并以3 4的优势胜过了先前的工作,而训练参数不到1 5。 |
| Estimating Grape Yield on the Vine from Multiple Images Authors Daniel L. Silver, Jabun Nasa 收获前估算葡萄产量对于商业化葡萄园生产很重要,因为它可以为许多葡萄园和酿酒厂的决策提供依据。当前,产量估算过程很耗时,其精度从75 90视葡萄栽培师的经验而有所不同。本文提出了一种多任务学习MTL卷积神经网络CNN方法,该方法使用廉价的智能手机以简单的三脚架布置方式捕获的图像。 CNN模型使用来自自动编码器的MTL传输,以在收获前6天捕获的图像数据实现85精度。 |
| Deep Manifold Prior Authors Matheus Gadelha, Rui Wang, Subhransu Maji 我们为流形结构化数据(例如3D形状的表面)提出了先验知识,其中采用了深度神经网络来从随机初始化开始使用梯度下降来重建目标形状。我们证明以这种方式生成的曲面是光滑的,具有以高斯过程为特征的有限行为,并且我们从数学上推导了完全连接以及卷积网络的此类属性。我们在各种流形重建应用程序中演示了我们的方法,例如点云去噪和插值,在不需要训练数据的情况下,相对于竞争基准取得了更好的结果。我们还表明,当训练数据可用时,我们的方法允许在AtlasNet框架下开发曲面的替代参数化,从而形成紧凑的网络体系结构,并在标准图像上更好地重建结果以塑造重建基准。 |
| Transferable, Controllable, and Inconspicuous Adversarial Attacks on Person Re-identification With Deep Mis-Ranking Authors Hongjun Wang, Guangrun Wang, Ya Li, Dongyu Zhang, Liang Lin DNN的成功将人员识别ReID的广泛应用带入了一个新时代。但是,ReID是否继承DNN的漏洞仍待探讨。检查ReID系统的健壮性非常重要,因为ReID系统的不安全性可能会造成严重损失,例如,犯罪分子可能会利用对抗性干扰来欺骗CCTV系统。在这项工作中,我们通过建议学习错误地对公式进行排名以扰乱系统输出的排名,从而研究了当前性能最佳的ReID模型的不安全性。由于跨数据集的可传递性在ReID域中至关重要,因此我们还通过开发新颖的多级网络体系结构执行后箱攻击,该体系将不同级别的特征金字塔化,以提取对抗性扰动的常规和可传递特征。我们的方法可以通过使用可区分的多镜头采样来控制恶意像素的数量。为了保证攻击的不显眼性,我们还提出了一种新的感知损失,以实现更好的视觉质量。在四个最大的ReID基准测试(即Market1501 45,CUHK03 18,DukeMTMC 33和MSMT17 40)上进行的广泛实验不仅显示了我们方法的有效性,而且还为ReID系统的鲁棒性提供了未来改进的方向。例如,性能最好的ReID系统之一的精度在受到我们方法的攻击后从91.8急剧下降到1.4。一些攻击结果如图1所示。 |
| The GeoLifeCLEF 2020 Dataset Authors Elijah Cole, Benjamin Deneu, Titouan Lorieul, Maximilien Servajean, Christophe Botella, Dan Morris, Nebojsa Jojic, Pierre Bonnet, Alexis Joly 了解物种的地理分布是保护的关键问题。通过将物种发生与环境特征配对,研究人员可以对环境与可能在该物种中发现的物种之间的关系进行建模。为了促进这一领域的研究,我们提供了GeoLifeCLEF 2020数据集,该数据集包括190万种物种观测值,以及高分辨率的遥感影像,土地覆盖数据和海拔,以及传统的低分辨率的气候和土壤变量。我们还讨论了GeoLifeCLEF 2020竞赛,该竞赛旨在使用该数据集来推进基于位置的物种推荐中的最新技术。 |
| Leveraging 2D Data to Learn Textured 3D Mesh Generation Authors Paul Henderson, Vagia Tsiminaki, Christoph H. Lampert 已经提出了许多用于3D对象的概率生成建模的方法。但是,这些都不能产生纹理对象,这使得它们在实际任务中的使用受到限制。在这项工作中,我们提出了纹理3D网格的第一个生成模型。传统上,训练这样的模型将需要大量的纹理网格数据集,但是不幸的是,现有的网格数据集缺少详细的纹理。相反,我们提出了一种新的训练方法,该方法可以从没有任何3D信息的2D图像集合中学习。为此,我们训练模型以将每个图像建模为放置在2D背景前面的3D前景对象,从而解释图像的分布。因此,它学会了生成网格,该网格在渲染时会生成与其训练集中的图像相似的图像。 |
| Learning to Drive Off Road on Smooth Terrain in Unstructured Environments Using an On-Board Camera and Sparse Aerial Images Authors Travis Manderson, Stefan Wapnick, David Meger, Gregory Dudek 我们提出了一种方法,用于学习在平坦的地形上驾驶,同时仅通过视觉输入即可避免在越野和非结构化室外环境中遇到挑战时发生碰撞。我们的方法采用了基于混合模型和无模型的强化学习方法,该方法在使用板载传感器标记地形粗糙度和碰撞时完全可以自我监督。值得注意的是,我们为模型提供了第一人称和空中影像输入。我们发现这些补充输入的融合改善了计划的远见,并使模型对视觉障碍具有鲁棒性。我们的结果表明,可以将其推广到植被丰富,各种岩石和沙质小径的环境中。在评估过程中,与仅使用第一人称图像的模型相比,我们的策略可实现90次平滑的地形遍历,并将行驶的崎terrain地形的比例降低了6.1倍。 |
| Rethinking the Trigger of Backdoor Attack Authors Yiming Li, Tongqing Zhai, Baoyuan Wu, Yong Jiang, Zhifeng Li, Shutao Xia 在这项工作中,我们研究后门攻击的问题,后门攻击在特定训练图像上添加了特定的触发器(即本地补丁),以强制要求错误地预测具有相同触发器的测试图像,而受训练的人会正确预测自然的测试示例模型。许多现有的作品都采用了这样的设置:训练和测试图像上的触发器具有相同的外观,并且位于相同的区域。但是,我们观察到,如果触发器的外观或位置略有变化,则攻击性能可能会急剧下降。根据此观察,我们建议对空间进行变换,例如,翻转和缩放测试图像,以便更改触发器的外观和位置(如果存在)。该简单策略经过实验验证,可以有效地防御许多最新的后门攻击方法。此外,为了增强后门攻击的鲁棒性,我们建议在输入训练过程之前,使用触发器对训练图像进行随机空间变换。大量实验证明,提出的后门攻击对空间变换具有鲁棒性。 |
| Orthogonal Over-Parameterized Training Authors Weiyang Liu, Rongmei Lin, Zhen Liu, James M. Rehg, Li Xiong, Le Song 神经网络的感应偏差在很大程度上取决于架构和训练算法。为了获得良好的概括,如何有效地训练神经网络比设计体系结构更为重要。我们提出了一种新颖的正交过参数化训练OPT框架,该框架可以可证明地最小化表征超球面上神经元多样性的超球面能量。通过在训练过程中不断保持最小的超球面能量,OPT可以大大提高网络的通用性。具体来说,OPT固定神经元的随机初始化权重,并学习适用于这些神经元的正交变换。我们提出了多种学习此类正交变换的方法,包括展开正交算法,应用正交参数化以及设计正交性保留梯度更新。有趣的是,OPT揭示了学习适当的神经元坐标系对于泛化至关重要,并且可能比学习神经元的特定相对位置更重要。我们进一步提供了有关OPT为什么产生更好的泛化的理论见解。大量的实验证明了OPT的优越性。 |
| Fisher Discriminant Triplet and Contrastive Losses for Training Siamese Networks Authors Benyamin Ghojogh, Milad Sikaroudi, Sobhan Shafiei, H.R. Tizhoosh, Fakhri Karray, Mark Crowley 暹罗神经网络是用于特征提取和度量学习的非常强大的体系结构。它通常由几个共享权重的网络组成。暹罗概念与拓扑无关,可以使用任何神经网络作为其骨干。用于训练这些网络的两个最受欢迎的损失函数是三元组和对比损失函数。在本文中,我们提出了两个新颖的损失函数,分别为Fisher判别三重态FDT和Fisher判别对比FDC。前者使用锚邻近的三元组,而后者使用锚邻近和锚远的样本对。 FDT和FDC损失函数是根据Fisher判别分析FDA的统计公式设计的,该统计公式是线性子空间学习方法。我们在MNIST和两个具有挑战性且可公开获得的组织病理学数据集上进行的实验表明了所提出的损失函数的有效性。 |
| Test-Time Adaptable Neural Networks for Robust Medical Image Segmentation Authors Neerav Karani, Krishna Chaitanya, Ender Konukoglu 当训练数据集代表预期在测试时会遇到的变化时,卷积神经网络CNN可以很好地解决监督学习问题。在医学图像分割中,如果训练图像和测试图像之间在采集细节(例如扫描仪型号或协议)方面不匹配,则会违反此前提。在这种情况下,CNN的性能显着下降已在文献中充分记录。为了解决此问题,我们将分段CNN设计为两个子网络的串联,即相对较浅的图像规范化CNN,然后是对规范化图像进行分段的较深的CNN。我们使用训练数据集来训练这两个子网,这些数据集由来自特定扫描仪和协议设置的带注释的图像组成。现在,在测试时,我们在预测的分割标签上以隐式先验为指导,为每个测试图像调整图像标准化子网。我们采用了独立训练的降噪自动编码器DAE,以便在合理的解剖分割标签上对这种隐式先验建模。我们在大脑,心脏和前列腺的三个解剖结构的多中心磁共振成像数据集上验证了提出的想法。拟议的测试时间适应性始终如一地提供性能改进,证明了该方法的前景和普遍性。与深层CNN的第二子网的架构不可知,该提议的设计可与任何分段网络一起使用,以提高对成像扫描仪和协议变化的鲁棒性。 |
| CNN2Gate: Toward Designing a General Framework for Implementation of Convolutional Neural Networks on FPGA Authors Alireza Ghaffari, Yvon Savaria 卷积神经网络CNN由于提供的服务众多,因此对我们的社会产生了重大影响。另一方面,它们需要相当大的计算能力。为了满足这些要求,可以使用图形处理单元GPU。但是,高功耗和有限的外部IO限制了它们在工业和关键任务场景中的可用性和适用性。最近,利用FPGA实现CNN的研究数量正在迅速增加。这是由于这些平台提供了较低的功耗和易于重新配置的能力。由于在诸如架构,综合和优化等主题上进行了研究,因此将此类硬件解决方案集成到高级机器学习软件库中出现了一些新的挑战。本文介绍了一个集成框架CNN2Gate,该框架支持针对FPGA目标的CNN模型的编译。 CNN2Gate利用商业供应商提供的针对FPGA的OpenCL textsuperscript TM综合工作流程。 CNN2Gate能够从多个流行的高级机器学习库(例如Keras,Pytorch,Caffe2等)中解析CNN模型。CNN2Gate不仅提取权重和偏差,还提取层的计算流程,并应用给定的定点量化。此外,它以OpenCL综合工具的正确格式写入此信息,然后这些工具用于在FPGA上构建和运行项目。 CNN2Gate使用增强学习代理执行设计空间探索,并自动将设计与逻辑资源有限的其他FPGA配合。本文报告了在各种英特尔FPGA平台上AlexNet和VGG 16的自动综合和设计空间探索的结果。 CNN2Gate在VGG 16上的延迟为205毫秒,在AlexNet上的延迟为18毫秒。 |
| Cortical surface registration using unsupervised learning Authors Jieyu Cheng, Adrian Dalca, Bruce Fischl, Lilla Zollei for the Alzheimer s Disease Neuroimaging Initiative 由于人类皮质的几何复杂性和受试者之间高度的可变性,非刚性皮质配准是一项重要且具有挑战性的任务。传统的解决方案是使用表面特性的球形表示并通过在该空间中对齐皮质折叠图案来执行配准。这种策略可产生精确的空间对齐,但通常需要很高的计算成本。最近,卷积神经网络的CNN已显示出显着加快体积配准的潜力。但是,由于将球体投影到2D平面而引入的变形,将基于学习的新方法直接应用于曲面会产生较差的结果。在这项研究中,我们提出了SphereMorph,这是一个使用深层网络解决这些问题的皮质表面微分配准框架。 SphereMorph使用与球核相关联的UNet样式网络来学习位移场,并使用修改的空间变换器层使球体变形。我们提出了一种重采样权重来计算数据拟合损失,以解决极地投影引入的失真问题,并演示我们提出的方法在两项任务上的性能,包括皮质分割和逐组功能区域对齐。实验表明,提出的SphereMorph能够在CNN框架中对几何配准问题进行建模,并显示出优异的配准精度和计算效率。 |
| DeepCOVIDExplainer: Explainable COVID-19 Predictions Based on Chest X-ray Images Authors Md. Rezaul Karim, Till D hmen, Dietrich Rebholz Schuhmann, Stefan Decker, Michael Cochez, Oya Beyan 在冠状病毒疾病COVID 19大流行中,人类感染的人数在世界范围内迅速增加。在抗击病毒方面,医院面临的挑战是对入院病人的有效筛查。一种方法是评估胸部X射线摄影CXR图像,这通常需要放射线专家知识。在本文中,我们提出了一种基于DNN的可解释的基于深度神经网络的方法,用于从CXR图像中自动检测COVID 19症状,我们将其称为DeepCOVIDExplainer。我们在13,808例患者中使用了16,995例CXR图像,涵盖了正常,肺炎和COVID 19例。首先对CXR图像进行全面的预处理,然后再使用神经集成方法对其进行扩展和分类,然后使用梯度引导的类激活图Grad CAM和逐层相关性传播LRP突出显示类区分区域。此外,我们提供了有关预测的人类可解释的解释。基于保留数据的评估结果表明,我们的方法可以可靠地识别出COVID 19,其正预测值PPV为89.61,召回率为83,与最近的可比较方法相比有所改善。我们希望我们的发现将为对抗COVID 19做出更有益的贡献,更广泛地说,将为在临床实践中越来越多地接受和采用AI辅助应用程序。 |
| ARCH: Animatable Reconstruction of Clothed Humans Authors Zeng Huang, Yuanlu Xu, Christoph Lassner, Hao Li, Tony Tung 在本文中,我们提出了“穿衣人类的ARCH动画可重构”,这是一种新颖的端到端框架,用于从单眼图像中准确重建动画就绪的3D穿衣服的人类。现有的数字化3D人类方法难以应对姿势变化和恢复细节。此外,它们不会生成动画就绪的模型。相比之下,ARCH是一种学习型姿势感知模型,可从单个不受约束的RGB图像生成详细的3D装配的全身人体化身。使用参数3D人体估计器创建语义空间和语义变形场。它们允许将穿着2D 3D衣服的人转换为规范的空间,从而减少了因姿势变化和训练数据遮挡而导致的几何模糊性。使用具有空间局部特征的隐式函数表示可以了解详细的表面几何形状和外观。此外,我们建议使用不透明感知的可区分渲染对3D重建进行额外的每像素监督。我们的实验表明,ARCH提高了重建人类的保真度。与公共数据集上的最新方法相比,我们为标准指标获得了50多个更低的重构误差。我们还显示了迄今为止在文献中未见过的动画,高质量重建化身的许多定性例子。 |
| Recognizing Spatial Configurations of Objects with Graph Neural Networks Authors Laetitia Teodorescu, Katja Hofmann, Pierre Yves Oudeyer 深度学习算法可以看作是作用在编码为张量结构化数据的学习表示上的功能组合。然而,在大多数应用中,那些表示是整体的,例如,一个矢量对整个图像或句子进行编码。在本文中,我们以图神经网络GNN的最新成功为基础,探索图结构化表示在学习空间配置中的使用。受人类区分形状排列的能力的激励,我们引入了两种新颖的几何推理任务,为此我们提供了数据集。我们介绍了新颖的GNN层和体系结构来解决任务,并表明图结构化表示对于获得良好性能是必要的。 |
| Learnable Subspace Clustering Authors Jun Li, Hongfu Liu, Zhiqiang Tao, Handong Zhao, Yun Fu 本文研究了具有百万个数据点的大规模子空间聚类LSSC问题。尽管许多流行的子空间聚类方法已被视为小规模数据点的最新技术,但它们无法直接处理LSSC问题。一个基本的原因是,这些方法经常选择所有数据点作为大词典来构建庞大的编码模型,从而导致较高的时间和空间复杂性。在本文中,我们开发了一种可学习的子空间聚类范例,以有效解决LSSC问题。关键思想是学习一个参数函数,以将高维子空间划分为它们的基础低维子空间,而不是经典编码模型的昂贵成本。此外,我们提出了一个统一的鲁棒预测编码器RPCM来学习参数函数,这可以通过交替最小化算法来解决。此外,我们提供了参数函数的有界收缩分析。据我们所知,本文是在子空间聚类方法中有效地对数百万个数据点进行聚类的第一项工作。在数百万个数据集上进行的实验证明,我们的范例在效率和有效性方面都优于相关的最新方法。 |
| Adversarial Latent Autoencoders Authors Stanislav Pidhorskyi, Donald Adjeroh, Gianfranco Doretto 自动编码器网络是无监督的方法,旨在通过同时学习编码器生成器图来组合生成属性和表示属性。尽管已进行了广泛的研究,但是它们是否具有GAN的相同生成能力或学习解开表示法的问题尚未得到充分解决。我们介绍了一种自动编码器,可共同解决这些问题,我们称之为对抗性潜在自动编码器ALAE。它是一种通用架构,可以利用GAN培训程序的最新改进。我们设计了两种自动编码器,一种基于MLP编码器,另一种基于StyleGAN生成器,我们称为StyleALAE。我们验证两种体系结构的解缠结特性。我们显示,StyleALAE不仅可以生成质量与StyleGAN相当的1024x1024人脸图像,而且在相同的分辨率下还可以基于真实图像生成人脸重建和操作。这使ALAE成为第一个能够与之匹敌的自动编码器,并且超越了仅发生器类型的体系结构的能力。 |
| TensorProjection Layer: A Tensor-Based Dimensionality Reduction Method in CNN Authors Toshinari Morimoto, Su Yun Huang 在本文中,我们提出了一种应用于张量结构化数据的降维方法,将其作为卷积神经网络中的隐层TensorProjection Layer。我们提出的方法通过投影将输入张量转换为尺寸较小的张量。投影的方向被视为与我们提出的图层相关的训练参数,并通过监督学习准则(例如最小化交叉熵损失函数)进行训练。我们讨论了损失函数相对于与我们提出的层相关的参数的梯度。我们还实施了简单的数值实验来评估TensorProjection层的性能。 |
| Automatic detection of acute ischemic stroke using non-contrast computed tomography and two-stage deep learning model Authors Mizuho Nishio, Sho Koyasu, Shunjiro Noguchi, Takao Kiguchi, Kanako Nakatsu, Thai Akasaka, Hiroki Yamada, Kyo Itoh 背景与目的我们旨在开发和评估涉及两阶段深度学习模型的自动急性缺血性卒中相关AIS检测系统。 |
| Score-Guided Generative Adversarial Networks Authors Minhyeok Lee, Junhee Seok 我们提出了一个生成对抗网络GAN,该网络使用预先训练的网络来引入评估模块。提议的模型称为得分指导GAN ScoreGAN,使用GAN的评估指标(即初始得分)进行训练,作为发电机训练的粗略指南。通过使用另一个预先训练的网络而不是Inception网络,ScoreGAN避免了Inception网络的过度拟合,以使生成的样本不对应于Inception网络的对抗示例。另外,为了防止过度拟合,仅将评估指标用作辅助角色,而主要使用GAN的常规目标。使用CIFAR 10数据集进行评估,ScoreGAN的Inception得分为10.36 pm 0.15,与最新技术水平相对应。此外,为了概括ScoreGAN的有效性,进一步使用另一个数据集(即CIFAR 100)对该模型进行了评估,ScoreGAN优于其他现有方法,其中在CIFAR 100数据集上训练的ScoreGAN的Fr chet Inception Distance FID为13.98。 |
| Feedback Recurrent Autoencoder for Video Compression Authors Adam Golinski, Reza Pourreza, Yang Yang, Guillaume Sautiere, Taco S Cohen 深度生成建模的最新进展使得能够对高维数据分布进行高效建模,并为解决数据压缩问题开辟了新的视野。具体而言,基于自动编码器的学习型图像或视频压缩解决方案正在成为传统方法的强大竞争者。在这项工作中,我们提出了一种基于常见和深入研究的组件的新网络架构,用于在低延迟模式下运行的学习型视频压缩。我们的方法可在高分辨率UVG数据集上获得最先进的MS SSIM速率性能,这是流媒体应用感兴趣的速率范围内的学习视频压缩方法以及经典视频压缩方法H.265和H.264两者。此外,我们通过其潜在的概率图形模型的角度对现有方法进行了分析。最后,我们指出了在经验评估中观察到的时间一致性和色偏问题,并提出了缓解这些问题的方向。 |
| TOG: Targeted Adversarial Objectness Gradient Attacks on Real-time Object Detection Systems Authors Ka Ho Chow, Ling Liu, Mehmet Emre Gursoy, Stacey Truex, Wenqi Wei, Yanzhao Wu 实时海量数据捕获的快速增长将深度学习和数据分析计算推向了边缘系统。边缘上的实时对象识别是由DNN提供动力的代表性深层神经系统之一,用于现实世界中的关键任务应用,例如自动驾驶和增强现实。尽管DNN驱动的物体检测边缘系统庆祝了许多丰富的生活机会,但它们也为滥用和滥用打开了大门。本文提出了三种针对性的对抗性目标梯度攻击,简称TOG,它们可能导致最先进的深度目标检测网络遭受目标消失,目标制造和目标标签错误的攻击。我们还提出了一种通用的目标梯度攻击,将对抗性可传递性用于黑匣子攻击,这种攻击对任何输入都有效,且攻击时间成本可忽略,人类的感知能力较低,特别不利于对象检测边缘系统。我们报告了使用两个基准数据集PASCAL VOC和MS COCO的两个最先进的检测算法YOLO和SSD的实验测量结果。结果表明,存在严重的对抗漏洞,并且迫切需要开发强大的对象检测系统。 |
| Physics-enhanced machine learning for virtual fluorescence microscopy Authors Colin L. Cooke, Fanjie Kong, Amey Chaware, Kevin C. Zhou, Kanghyun Kim, Rong Xu, D. Michael Ando, Samuel J. Yang, Pavan Chandra Konda, Roarke Horstmeyer 本文介绍了一种受监督的深度学习网络,该网络可以共同优化光学显微镜的物理设置以推断荧光图像信息。具体而言,我们设计了一个明场显微镜的照明模块,以最大化从明场图像推断荧光细胞特征的性能。我们利用照亮样品的广泛灵活性来优化来自定制LED阵列的可编程光模式,与标准照明技术相比,该模式可产生更好的任务特定性能。我们通过在深度卷积网络的初始层中包含图像形成的物理模型来实现照明模式的优化。与标准成像方法相比,我们优化的照明模式最多可提高45种性能,此外,我们还将探索优化模式如何根据推理任务而变化。这项工作证明了通过可编程光学元件优化图像捕获过程以改善自动化分析的重要性,并为近期荧光图像推断工作的预期性能提升提供了新的物理见解。 |
| GeneCAI: Genetic Evolution for Acquiring Compact AI Authors Mojan Javaheripi, Mohammad Samragh, Tara Javidi, Farinaz Koushanfar 在当今的大数据领域,深度神经网络DNN正在向更复杂的架构发展,以实现更高的推理精度。可以利用模型压缩技术在资源受限的移动设备上有效地部署此类计算密集型体系结构。这样的方法包括各种超参数,这些超参数要求每层定制以确保高精度。由于相关搜索空间随模型层呈指数增长,因此选择此类超级参数非常麻烦。本文介绍了GeneCAI,这是一种新颖的优化方法,可自动学习如何调整每层压缩超参数。我们设计了一种双射翻译方案,将压缩的DNN编码到基因型空间。使用多目标评分基于浮点运算的准确性和数量来测量每种基因型的最佳性。我们开发了定制的遗传运算,以将非支配解迭代地演化为最优的Pareto前沿,从而捕获了模型准确性和复杂性之间的最优权衡。 GeneCAI优化方法具有高度可扩展性,可以在分布式多GPU平台上实现近乎线性的性能提升。我们的广泛评估表明,通过发现位于精度更高,复杂度更高的帕累托曲线上的模型,GeneCAI在DNN压缩中优于现有的基于规则和强化学习的方法。 |
| Variable Rate Video Compression using a Hybrid Recurrent Convolutional Learning Framework Authors Aishwarya Jadhav 近年来,基于神经网络的图像压缩技术已经能够胜过传统编解码器,并为基于学习的视频编解码器的发展打开了大门。然而,为了利用视频中的高时间相关性,需要采用更复杂的架构。本文介绍了PredEncoder,这是一种基于预测自动编码概念的混合视频压缩框架,该框架使用预测网络对连续视频帧之间的时间相关性进行建模,然后将其与渐进式编码器网络结合以利用空间冗余。在本文中提出了可变速率块编码方案,该方案导致了很高的质量比特率比。通过联合培训和对该混合体系结构进行微调,PredEncoder能够在MPEG 4编解码器上取得显着改进,并在低至中等比特率范围内为高清视频提供了比H.264编解码器节省的比特率,并且具有可比的结果非高清视频的大多数比特率。本文旨在说明如何利用神经架构与视频压缩领域中高度优化的传统方法相媲美。 |
| A single image deep learning approach to restoration of corrupted remote sensing products Authors Anna Petrovskaia, Raghavendra B. Jana, Ivan V. Oseledets 遥感图像用于各种分析,从农业监测到救灾,再到资源规划,等等。图像可能由于多种原因而损坏,包括仪器错误和自然障碍(例如云)。我们在这里提出一种新颖的方法,在这种情况下,仅使用损坏的图像作为输入,即可重建丢失的信息。深度映像先验方法消除了对预先训练的网络或映像数据库的需求。结果表明,该方法很容易击败传统的单图像方法。 |
| Inpainting via Generative Adversarial Networks for CMB data analysis Authors Alireza Vafaei Sadr, Farida Farsian 在这项工作中,我们提出了一种新的方法,可以在点源提取过程之后,在掩蔽的区域中修补CMB信号。我们采用改进的Generative Adversarial Network GAN,比较内部超参数和训练策略的不同组合。我们使用合适的数学C r变量研究性能,以估计有关CMB功率谱恢复的性能。我们考虑一个测试集,其中一个点源在每个天空斑块中以1.83乘以1.83平方度的扩展被掩盖,在我们的网格中,它对应于64乘以64像素。 GAN经过优化,可在Planck 2018总强度模拟中估算性能。训练使GAN有效地重构了对应于约1500个像素的掩膜,其中1个误差降低到对应于约5弧分的角标度。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
Interesting:
, (from )
, (from )
, (from )
, (from )
, (from )
pic from pexels.com