Keras实现注意力机制
Keras实现注意力机制
这里主要记录几种Keras的注意力机制的实现,仅作为个人记录。
- python 3
- keras 2.1.0 (tensorflow backend)
写法1
这种写法比较简单,参考自这里。相似度函数采用的是一层全连接层。全连接层的输出经过softmax激活函数计算权重。他对隐层向量的每一维在每个时间步上进行了softmax操作,这里函数的返回值是三维的,也就是说这里只是乘上了权重,但并没有求和。
def attention_3d_block(inputs, single_attention_vector=False):
# 如果上一层是LSTM,需要return_sequences=True
# inputs.shape = (batch_size, time_steps, input_dim)
time_steps = K.int_shape(inputs)[1]
input_dim = K.int_shape(inputs)[2]
a = Permute((2, 1))(inputs)
a = Dense(time_steps, activation='softmax')(a)
if single_attention_vector:
a = Lambda(lambda x: K.mean(x, axis=1))(a)
a = RepeatVector(input_dim)(a)
a_probs = Permute((2, 1))(a)
# 乘上了attention权重,但是并没有求和,好像影响不大
# 如果分类任务,进行Flatten展开就可以了
# element-wise
output_attention_mul = Multiply()([inputs, a_probs])
return output_attention_mul注意:这里直接对经过线性变换后的所有向量进行了softmax,并没有乘上context vector后再做,好像在分类例子里影响不大。这里time_steps有时候不太容易取,需要事先手动指定,而且有时候可能需要可变的time_steps,这就可能有问题。
写法2
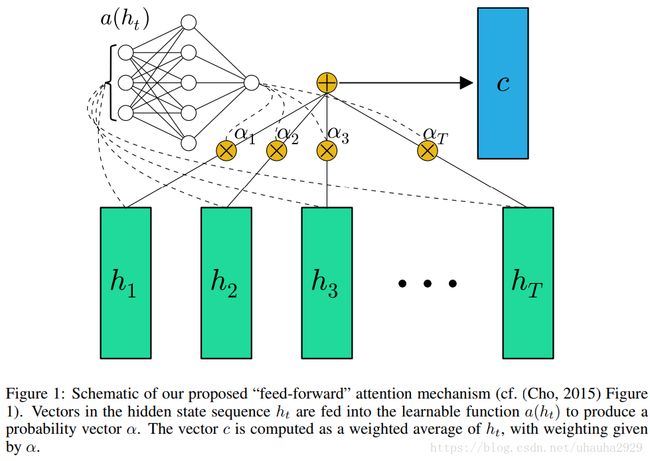
这里我仿照上面的写法,自定义了一个Keras层。不同的是,这里在softmax之前还加了tanh激活函数,而且将输出进行了求和,所以输出是二维的。借用这篇文章中的图,应该大致描述了这个意思。
class AttentionLayer(Layer):
def __init__(self, **kwargs):
super(AttentionLayer, self).__init__(** kwargs)
def build(self, input_shape):
assert len(input_shape)==3
# W.shape = (time_steps, time_steps)
self.W = self.add_weight(name='att_weight',
shape=(input_shape[1], input_shape[1]),
initializer='uniform',
trainable=True)
self.b = self.add_weight(name='att_bias',
shape=(input_shape[1],),
initializer='uniform',
trainable=True)
super(AttentionLayer, self).build(input_shape)
def call(self, inputs):
# inputs.shape = (batch_size, time_steps, seq_len)
x = K.permute_dimensions(inputs, (0, 2, 1))
# x.shape = (batch_size, seq_len, time_steps)
a = K.softmax(K.tanh(K.dot(x, self.W) + self.b))
outputs = K.permute_dimensions(a * x, (0, 2, 1))
outputs = K.sum(outputs, axis=1)
return outputs
def compute_output_shape(self, input_shape):
return input_shape[0], input_shape[2]Hierarchical Attention Networks
这篇论文提出了一种层级的注意力机制,在词汇级别和句子级别应用注意力机制对文档进行分类,得到了不错的效果。
这篇博客好像做了实现,使用的数据集来自这里。我也按照他的代码进行了实验,并且用到了上文提到的自定义的Attention层。代码在这里,简单试了一下,准确率为90.52%。
sentence_input = Input(shape=(MAX_SENT_LENGTH,), dtype='int32')
embedded_sequences = embedding_layer(sentence_input)
l_lstm = Bidirectional(GRU(100, return_sequences=True))(embedded_sequences)
l_dense = TimeDistributed(Dense(200))(l_lstm) # 对句子中的每个词
l_att = AttentionLayer()(l_dense)
sentEncoder = Model(sentence_input, l_att)
review_input = Input(shape=(MAX_SENTS,MAX_SENT_LENGTH), dtype='int32')
review_encoder = TimeDistributed(sentEncoder)(review_input) # 对文档中每个句子
l_lstm_sent = Bidirectional(GRU(100, return_sequences=True))(review_encoder)
l_dense_sent = TimeDistributed(Dense(200))(l_lstm_sent)
l_att_sent = AttentionLayer()(l_dense_sent)
preds = Dense(2, activation='softmax')(l_att_sent)
model = Model(review_input, preds)