Solr简介

1.Solr是什么?
Solr它是一种开放源码的、基于 Lucene Java 的搜索服务器,易于加入到 Web 应用程序中。Solr 提供了层面搜索(就是统计)、命中醒目显示并且支持多种输出格式(包括XML/XSLT 和JSON等格式)。Solr是一个高性能,采用Java开发,
基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
Solr易于安装和配置,而且附带了一个基于HTTP 的管理界面。可以使用 Solr 的表现优异的基本搜索功能,也可以对它进行扩展从而满足企业的需要。
Solr架构图
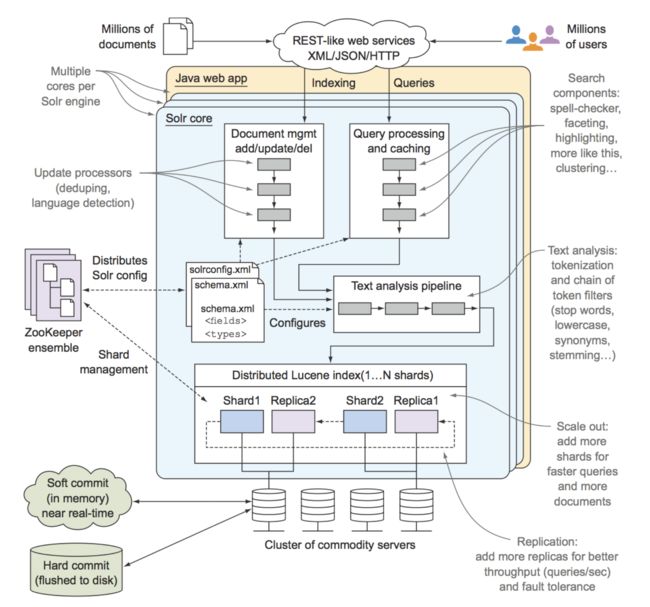
Solr的特性

高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等.
· 高级的全文搜索功能
· 专为高通量的网络流量进行的优化
· 基于开放接口(XML和HTTP)的标准
· 综合的HTML管理界面
· 可伸缩性-能够有效地复制到另外一个Solr搜索服务器
· 使用XML配置达到灵活性和适配性
· 可扩展的插件体系
2. Lucene 是什么?
Lucene是一个基于Java的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。Lucene 目前是 Apache Jakarta(雅加达) 家族中的一个开源项目。也是目前最为流行的基于Java开源全文检索工具包。目前已经有很多应用程序的搜索功能是基于 Lucene ,比如Eclipse 帮助系统的搜索功能。Lucene能够为文本类型的数据建立索引,所以你只要把你要索引的数据格式转化的文本格式,Lucene 就能对你的文档进行索引和搜索。
3. Solr vs Lucene
Solr与Lucene 并不是竞争对立关系,恰恰相反Solr 依存于Lucene,因为Solr底层的核心技术是使用Lucene 来实现的,Solr和Lucene的本质区别有以下三点:搜索服务器,企业级和管理。Lucene本质上是搜索库,不是独立的应用程序,而Solr是。Lucene专注于搜索底层的建设,而Solr专注于企业应用。Lucene不负责支撑搜索服务所必须的管理,而Solr负责。所以说,一句话概括 Solr: Solr是Lucene面向企业搜索应用的扩展。
Solr与Lucene架构图:
Solr使用Lucene并且扩展了它!
· 一个真正的拥有动态字段(Dynamic Field)和唯一键(Unique Key)的数据模式(Data Schema)
· 对Lucene查询语言的强大扩展!
· 支持对结果进行动态的分组和过滤
· 高级的,可配置的文本分析
· 高度可配置和可扩展的缓存机制
· 性能优化
· 支持通过XML进行外部配置
· 拥有一个管理界面
· 可监控的日志
· 支持高速增量式更新(Fast incremental Updates)和快照发布(Snapshot Distribution)
下载安装
下载
https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/8.5.1/solr-8.5.1.tgz
解压即可.目录结构:

启动命令
-
cd ~/solr/bin回车 -
solr start -p 8983回车,等待启动成功 -
solr stop -p 8983这个是停止solr命令
solr-8.5.1/bin$ ./solr start -p 8983
*** [WARN] *** Your open file limit is currently 256.
It should be set to 65000 to avoid operational disruption.
If you no longer wish to see this warning, set SOLR_ULIMIT_CHECKS to false in your profile or solr.in.sh
*** [WARN] *** Your Max Processes Limit is currently 1418.
It should be set to 65000 to avoid operational disruption.
If you no longer wish to see this warning, set SOLR_ULIMIT_CHECKS to false in your profile or solr.in.sh
Waiting up to 180 seconds to see Solr running on port 8983 [-]
Started Solr server on port 8983 (pid=44785). Happy searching!
启动成功后,访问 http://127.0.0.1:8983/solr/#/
可以看到Solr的管理界面:

JVM
Runtime
Oracle Corporation Java HotSpot(TM) 64-Bit Server VM 1.8.0_40 25.40-b25
Processors
12
Args
-DSTOP.KEY=solrrocks-DSTOP.PORT=7983-Djetty.home=/Users/jack/soft/solr-8.5.1/server-Djetty.port=8983-Dsolr.data.home=-Dsolr.default.confdir=/Users/jack/soft/solr-8.5.1/server/solr/configsets/_default/conf-Dsolr.install.dir=/Users/jack/soft/solr-8.5.1-Dsolr.jetty.https.port=8983-Dsolr.jetty.inetaccess.excludes=-Dsolr.jetty.inetaccess.includes=-Dsolr.log.dir=/Users/jack/soft/solr-8.5.1/server/logs-Dsolr.log.muteconsole-Dsolr.solr.home=/Users/jack/soft/solr-8.5.1/server/solr-Duser.timezone=UTC-XX:+AlwaysPreTouch-XX:+ParallelRefProcEnabled-XX:+PerfDisableSharedMem-XX:+PrintGCApplicationStoppedTime-XX:+PrintGCDateStamps-XX:+PrintGCDetails-XX:+PrintGCTimeStamps-XX:+PrintHeapAtGC-XX:+PrintTenuringDistribution-XX:+UseG1GC-XX:+UseGCLogFileRotation-XX:+UseLargePages-XX:GCLogFileSize=20M-XX:MaxGCPauseMillis=250-XX:NumberOfGCLogFiles=9-XX:OnOutOfMemoryError=/Users/jack/soft/solr-8.5.1/bin/oom_solr.sh 8983 /Users/jack/soft/solr-8.5.1/server/logs-Xloggc:/Users/jack/soft/solr-8.5.1/server/logs/solr_gc.log-Xms512m-Xmx512m-Xss256k-verbose:gc
启动并重新启动 Solr
您可以使用 start 命令来启动 Solr,使用 restart 命令允许您在 Solr 已经运行或者已经停止的情况下重新启动 Solr。
该 start 和 restart 命令有多种选择,让您在 SolrCloud 模式下运行,使用一个示例配置集,从一个不是默认的主机名或端口开始并指向本地的 ZooKeeper 集合。
bin/solr start [options]
bin/solr start -help
bin/solr restart [options]
bin/solr restart -help
使用 restart 命令时,必须传递您在启动 Solr 时最初传递的所有参数。在幕后,启动了一个停止请求,所以 Solr 将在被再次启动之前停止。如果没有节点已经运行,则重新启动将跳过此步骤停止并继续启动 Solr。
启动参数
bin/solr 脚本提供了许多选项,允许您以常见的方式自定义服务器,例如更改侦听端口。但是,大多数默认设置对于大多数 Solr 安装都是足够的,特别是刚开始时。
-a ""
使用额外的 JVM 参数(例如以 -X 开头的参数)启动 Solr。如果您正在传递以 “-D” 开头的 JVM 参数,则可以省略 -a 选项。例如:
bin/solr start -a "-Xdebug -Xrunjdwp:transport=dt_socket, server=y,suspend=n,address=1044"
-cloud
以 SolrCloud 模式启动 Solr,该模式也将启动 Solr 附带的嵌入式 ZooKeeper 实例。
这个选项可以简单地缩短为-c。
如果您已经在运行您想要使用的 ZooKeeper 集合,而不是嵌入式(单节点)ZooKeeper,则还应该传递 -z 参数。
有关更多详细信息,请参阅下面的 SolrCloud 模式部分。例如:
bin/solr start -c
-d
定义一个服务器目录,默认为server(如,$SOLR_HOME/server)。重写此选项的情况并不常见。在同一台主机上运行多个 Solr 实例时,更常见的是为每个实例使用相同的服务器目录,并使用 -s 选项使用唯一的Solr主目录更为常见。例如:
bin/solr start -d newServerDir
应用示例
Building and Running SolrJ Applications: put the following dependency in the project’s pom.xml:
org.apache.solr
solr-solrj
x.y.z
Single node Solr client
String urlString = "http://localhost:8983/solr/techproducts";
SolrClient solr = new HttpSolrClient.Builder(urlString).build();
SolrCloud client
// Using a ZK Host String
String zkHostString = "zkServerA:2181,zkServerB:2181,zkServerC:2181/solr";
SolrClient solr = new CloudSolrClient.Builder().withZkHost(zkHostString).build();
// Using already running Solr nodes
SolrClient solr = new CloudSolrClient.Builder().withSolrUrl("http://localhost:8983/solr").build();
Once you have a SolrClient, you can use it by calling methods like query(), add(), and commit().
客户端API简介
Solr的核心是一个Web应用程序,但是由于它是建立在开放的协议之上的,任何类型的客户端应用程序都可以使用Solr。
HTTP是客户端应用程序和Solr之间使用的基本协议。客户端提出请求,Solr做一些工作并提供响应。客户使用请求来请求Solr执行查询或索引文件等操作。
客户端应用程序可以通过创建HTTP请求和解析HTTP响应到达Solr。客户端API封装了发送请求和解析响应的大部分工作,这使得编写客户端应用程序变得更加容易。
客户使用Solr的五个基本操作来与Solr一起工作。这五个操作分别是:查询、索引、删除、提交和优化。
查询通过创建一个包含所有查询参数的URL来执行。Solr检查请求URL,执行查询并返回结果。其他操作是相似的,虽然在某些情况下,HTTP请求是一个POST操作,并包含除请求URL中包含的任何信息之外的信息。例如,索引操作可能包含请求正文中的文档。
Solr 还具有一个 EmbeddedSolrServer,它提供了一个 Java API 而不需要 HTTP 连接。
Setting XMLResponseParser
SolrJ uses a binary format, rather than XML, as its default response format. If you are trying to mix Solr and SolrJ versions where one is version 1.x and the other is 3.x or later, then you MUST use the XML response parser. The binary format changed in 3.x, and the two javabin versions are entirely incompatible. The following code will make this change:
solr.setParser(new XMLResponseParser());
Performing Queries
Use query() to have Solr search for results. You have to pass a SolrQuery object that describes the query, and you will get back a QueryResponse (from the org.apache.solr.client.solrj.response package).
SolrQuery has methods that make it easy to add parameters to choose a request handler and send parameters to it. Here is a very simple example that uses the default request handler and sets the query string:
SolrQuery query = new SolrQuery();
query.setQuery(mQueryString);
To choose a different request handler, there is a specific method available in SolrJ version 4.0 and later:
query.setRequestHandler("/spellCheckCompRH");
You can also set arbitrary parameters on the query object. The first two code lines below are equivalent to each other, and the third shows how to use an arbitrary parameter q to set the query string:
query.set("fl", "category,title,price");
query.setFields("category", "title", "price");
query.set("q", "category:books");
Once you have your SolrQuery set up, submit it with query():
QueryResponse response = solr.query(query);
The client makes a network connection and sends the query. Solr processes the query, and the response is sent and parsed into a QueryResponse.
The QueryResponse is a collection of documents that satisfy the query parameters. You can retrieve the documents directly with getResults() and you can call other methods to find out information about highlighting or facets.
SolrDocumentList list = response.getResults();
Indexing Documents
Other operations are just as simple. To index (add) a document, all you need to do is create a SolrInputDocument and pass it along to the SolrClient’s `add() method. This example assumes that the SolrClient object called 'solr' is already created based on the examples shown earlier.
SolrInputDocument document = new SolrInputDocument();
document.addField("id", "552199");
document.addField("name", "Gouda cheese wheel");
document.addField("price", "49.99");
UpdateResponse response = solr.add(document);
// Remember to commit your changes!
solr.commit();
Uploading Content in XML or Binary Formats
SolrJ lets you upload content in binary format instead of the default XML format. Use the following code to upload using binary format, which is the same format SolrJ uses to fetch results. If you are trying to mix Solr and SolrJ versions where one is version 1.x and the other is 3.x or later, then you MUST stick with the XML request writer. The binary format changed in 3.x, and the two javabin versions are entirely incompatible.
solr.setRequestWriter(new BinaryRequestWriter());
Lucence工作原理
lucence 是一个高性能的java全文检索工具包,他使用倒排序文件索引结构,改结构和相应的生成算法如下:
一、设有两篇文章1和2
文章1的内容为:Tom lives in guangzhou,i live in guangzhou too
文章2的内容为:He once lived in shanghai
由于lucence是基于关键词索引和查询的,因此我们首先要取得这两篇文章的关键词。通常我们要做一下处理:
a.我们现在有的是文章内容,即一个字符串,我们先要找出字符串中的所有单词,即分词。英文单词由于用空格分隔,比较好处理。中文单词间是连在一起的需要特殊的分词处理。
b.文章中的”in”, “once” “too”等词没有什么实际意义,中文中的“的”“是”等字通常也无具体含义,这些不代表概念的词可以过滤掉
c.用户通常希望查“He”时能把含“he”,“HE”的文章也找出来,所以所有单词需要统一大小写。
d.用户通常希望查“live”时能把含“lives”,“lived”的文章也找出来,所以需要把“lives”,“lived”还原成“live”
e.文章中的标点符号通常不表示某种概念,也可以过滤掉
在lucene中以上措施由Analyzer类完成
经过上面处理后,
文章1的所有关键词为:[tom] [live] [guangzhou] [live] [guangzhou]
文章2的所有关键词为:[he] [live] [shanghai]**
- 有了关键词后,我们就可以建立倒排索引了。上面的对应关系是:“文章号”对“文章中所有关键词”。倒排索引把这个关系倒过来,变成:“关键词”对“拥有该关键词的所有文章号”。文章1,2经过倒排后变成
| 关键词 | 文章号 |
|---|---|
| guangzhou | 1 |
| he | 2 |
| i | 1 |
| live | 1,2 |
| shanghai | 2 |
| tom | 1 |
通常仅知道关键词在哪些文章中出现还不够,我们还需要知道关键词在文章中出现次数和出现的位置,通常有两种位置:a)字符位置,即记录该词是文章中第几个字符(优点是关键词亮显时定位快);b)关键词位置,即记录该词是文章中第几个关键词(优点是节约索引空间、词组(phase)查询快),lucene 中记录的就是这种位置。
加上“出现频率”和“出现位置”信息后,我们的索引结构变为:
| 关键词 | 文章号[出现频率] | 出现位置 |
|---|---|---|
| guangzhou | 1[2] | 3,6 |
| he | 2[1] | 1 |
| i | 1[1] | 4 |
| live | 1[2],2[1] | 2,5,2 |
| shanghai | 2[1] | 3 |
| tom | 1[1] | 1 |
以live 这行为例我们说明一下该结构:live在文章1中出现了2次,文章2中出现了一次,它的出现位置为“2,5,2”这表示什么呢?我们需要结合文章号和出现频率来分析,文章1中出现了2次,那么“2,5”就表示live在文章1中出现的两个位置,文章2中出现了一次,剩下的“2”就表示live是文章2中第 2个关键字。
以上就是lucene索引结构中最核心的部分。我们注意到关键字是按字符顺序排列的(lucene没有使用B树结构),因此lucene可以用二元搜索算法快速定位关键词。
实现时 lucene将上面三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)、位置文件 (positions)保存。其中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息。
Lucene中使用了field的概念,用于表达信息所在位置(如标题中,文章中,url中),在建索引中,该field信息也记录在词典文件中,每个关键词都有一个field信息(因为每个关键字一定属于一个或多个field)。
为了减小索引文件的大小,Lucene对索引还使用了压缩技术。首先,对词典文件中的关键词进行了压缩,关键词压缩为<堉?缀长度,后缀>,例如:当前词为“阿拉伯语”,上一个词为“阿拉伯”,那么“阿拉伯语”压缩为<3,语>。其次大量用到的是对数字的压缩,数字只保存与上一个值的差值(这样可以减小数字的长度,进而减少保存该数字需要的字节数)。例如当前文章号是16389(不压缩要用3个字节保存),上一文章号是16382,压缩后保存7(只用一个字节)。
下面我们可以通过对该索引的查询来解释一下为什么要建立索引。
假设要查询单词 “live”,lucene先对词典二元查找、找到该词,通过指向频率文件的指针读出所有文章号,然后返回结果。词典通常非常小,因而,整个过程的时间是毫秒级的。
而用普通的顺序匹配算法,不建索引,而是对所有文章的内容进行字符串匹配,这个过程将会相当缓慢,当文章数目很大时,时间往往是无法忍受的。
参考资料
https://lucene.apache.org/solr/guide/8_5/solr-tutorial.html
https://lucene.apache.org/solr/
https://www.jianshu.com/p/be9e4accb486
https://www.w3cschool.cn/solr_doc/solr_doc-emn62fs5.html
https://lucene.apache.org/solr/guide/6_6/using-solrj.html#UsingSolrJ-SettingXMLResponseParser
https://www.cnblogs.com/senlinyang/p/8064202.html
Kotlin开发者社区

专注分享 Java、 Kotlin、Spring/Spring Boot、MySQL、redis、neo4j、NoSQL、Android、JavaScript、React、Node、函数式编程、编程思想、"高可用,高性能,高实时"大型分布式系统架构设计主题。
High availability, high performance, high real-time large-scale distributed system architecture design。
分布式框架:Zookeeper、分布式中间件框架等
分布式存储:GridFS、FastDFS、TFS、MemCache、redis等
分布式数据库:Cobar、tddl、Amoeba、Mycat
云计算、大数据、AI算法
虚拟化、云原生技术
分布式计算框架:MapReduce、Hadoop、Storm、Flink等
分布式通信机制:Dubbo、RPC调用、共享远程数据、消息队列等
消息队列MQ:Kafka、MetaQ,RocketMQ
怎样打造高可用系统:基于硬件、软件中间件、系统架构等一些典型方案的实现:HAProxy、基于Corosync+Pacemaker的高可用集群套件中间件系统
Mycat架构分布式演进
大数据Join背后的难题:数据、网络、内存和计算能力的矛盾和调和
Java分布式系统中的高性能难题:AIO,NIO,Netty还是自己开发框架?
高性能事件派发机制:线程池模型、Disruptor模型等等。。。
合抱之木,生于毫末;九层之台,起于垒土;千里之行,始于足下。不积跬步,无以至千里;不积小流,无以成江河。