0x21 树与图的遍历
树与图的深度优先遍历
深度优先遍历,就是在每个点\(x\)上面的的多条分支时,任意选择一条边走下去,执行递归,直到回溯到点x后再走其他的边
int head[N];
bool v[N];
struct edge
{
int v , next;
}e[N];
inline void dfs( int x )
{
v[x] = 1;
for( register int i = head[x] ; i ; i = e[i].next)
{
register int y = e[i].next;
if( v[y] ) continue;
dfs( y ) ;
}
return ;
}树的DFS序
一般来说,我们在对树的进行深度优先时,对于每个节点,在刚进入递归时和回溯前各记录一次该点的编号,最后会产生一个长度为\(2N\)的序列,就成为该树的\(DFS\)序
\(DFS\)序的特点时:每个节点的\(x\)的编号在序列中恰好出现两次。设这两次出现的位置时\(L[x]\),\(R[x]\),那么闭区间\([L[x],R[x]]\)就是以\(x\)为根的子树的\(DFS\)序
inline void dfs( int x )
{
a[ ++ tot ] = x; // a储存的是DFS序
v[ x ] = 1;
for( register int i = head[x] ; i ; i = e[i].next )
{
register int y = e[i].v;
if( v[y] ) continue;
dfs( y );
}
a[ ++ tot ] = x;
return ;
}树的深度
树中各个节点的深度是一种自顶向下的统计信息
起初,我们已知根节点深度是\(0\).若节点\(x\)的深度为\(d[x]\),则它的节点\(y\)的深度就是\(d[y] = d[x] + 1\)
inline void dfs( int x )
{
v[ x ] = 1;
for( register int i = head[ x ] ; i ; i = e[i].next )
{
register int y = e[i].v;
if( v[ y ] ) continue;
d[ y ] = d[ x ] + 1; // d[]就是深度
dfs( y );
}
return ;
}树的重心
对于一个节点\(x\),如果我们把它从树中删除,呢么原来的一颗树可能会被分割成若干个树。设\(max\_part(x)\)表示在删除节点\(x\)后产生子树中最大的一颗的大小。使\(max\_part(p)\)最下的\(p\)就是树的重心
inline void dfs( int x )
{
v[ x ] = 1 , size[ x ] = 1;//size 表示x的子树大小
register int max_part = 0; // 记录删掉x后最大一颗子树的大小
for( register int i = head[ x ] ; i ; i = e[i].next )
{
register int y = e[i].v;
if( v[y] ) continue;
dfs( y );
size[x] += size[y];
}
max_part = max ( max_part , n - size[x] );
if( max_part < ans ) //全局变量ans记录重心对应的max_part
{
ans = max_part;
pos = x;//pos 重心
}
return ;
}图的联通块划分
若在一个无向图中的一个子图中任意两个点之间都存在一条路径(可以相互到达),并且这个子图是“极大的”(不能在扩展),则称该子图是原图的一个联通块
如下代码所示,cnt是联通块的个数,v记录的是每一个点属于哪一个联通块
inline void dfs( int x )
{
v[ x ] = cnt;
for( register int i = head[x] ; i ; i = e[i].next )
{
register int y = e[i].v;
if( v[y] ) continue;
dfs(y);
}
return ;
}
for( register int i = 1 ; i < = n ; i ++ )
{
if( v[i] ) continue;
cnt ++ ;
dfs( i );
}图的广度优先搜索遍历
树与图的广度优先遍历是利用一个队列来实现的
queue< int > q;
inline void bfs()
{
q.push( 1 ) , d[1] = 1;
while( !q.empty() )
{
register int x = q.front(); q.pop();
for( register int i = head[ x ] ; i ; i = e[i].next )
{
register int y = e[i].v;
if( d[y] ) continue;
d[y] = d[x] + 1;
q.push(y);
}
}
return ;
}上面的代码中,我们在广度优先搜索中顺便求了个树的深度\(d\)
拓扑排序
给定一张有向无环图,若一个序列A满足图中的任意一条边(x,y)x都在y的前面呢么序列A就是图的拓扑排序
求拓扑序的过程非常简单我们只需要不断将入度为0的点加入序列中即可
- 建立空拓扑序列A
- 预处理出所有入度为deg[i],起初把入度为0的点入队
- 取出对头节点x,并把x放入序列A中
- 对于从x出发的每条边(x,y),把deg[y]减1,若deg[y] = 0 ,把y加入队列中
- 重复3,4直到队列为空,此时A即为所求
inline void addedge( int x , int y )
{
e[ ++ tot ].v = y , e[ tot ].next = head[x] , head[x] = tot;
deg[x] ++;
}
inline void topsort()
{
queue< int > q;
for( register int i = 1 ; i <= n ; i ++ )
{
if( !deg[i] ) q.push( i );
}
while( !q.empty() )
{
register int x = q.front(); q.pop();
a[ ++ cnt ] = x;
for( register int i = head[x] ; i ; i = e[i].next )
{
register int y = e[i].v;
if( -- deg[y] == 0 ) q.push( y );
}
}
return ;
}AcWing 164. 可达性统计
这道题的题意很简单,但是如果直接裸的计算会超时,所以要用拓扑序
首先求拓扑序,因为拓扑序中的每一个点都时由前面的点到的所以我们反过来从最后一个点开始
假设我们已经求得了\(x\)后面每一个点的所能到达的点,呢么我们对所有以x为起点的边所到达的点所能到达的点取并集就是\(x\)所等到达的所有的点
然后如果们要储存每个点所到达的点,如果我们用二维数组来存,会爆空间,所以为了节约空间可以用
#include
using namespace std;
const int N = 30010;
int n , m , head[N] , d[N] , a[N] , tot , cnt ;
bitset< N > f[N];
struct edge
{
int v , next;
}e[N];
inline int read()
{
register int x = 0;
register char ch = getchar();
while( ch < '0' || ch > '9' ) ch = getchar();
while( ch >= '0' && ch <= '9' )
{
x = ( x << 1 ) + ( x << 3 ) + ch - '0';
ch = getchar();
}
return x;
}
inline void addedge( int u , int v )
{
e[ ++ tot ].v = v , e[ tot ].next = head[u] , head[u] = tot;
d[ v ] ++;
}
inline void topsort()
{
queue< int > q;
for( register int i = 1 ; i <= n ; i ++ )
{
if( !d[i] ) q.push( i );
}
while( !q.empty() )
{
register int x = q.front(); q.pop();
a[ ++ cnt ] = x;
for( register int i = head[x] ; i ; i = e[i].next )
{
register int y = e[i].v;
if( -- d[y] == 0 ) q.push( y );
}
}
return ;
}
int main()
{
n = read() , m = read();
for( register int i = 1 ; i <= m ; i ++ )
{
register int a = read() , b = read();
addedge( a , b );
}
topsort();
for( register int i = cnt , j = a[i] ; i ; i -- , j = a[i] )
{
f[j][j] = 1;
for( register int k = head[j] ; k ; k = e[k].next ) f[j] |= f[ e[k].v ];
}
for( register int i = 1 ; i <= n ; i ++ ) printf( "%d\n" , f[i].count() );
return 0;
} 0x22 深度优先搜索
深度优先搜索算法\((Depth-First-Search)\)是一种用于遍历或搜索树或图的算法
沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点\(v\)的所在边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。
AcWing 165. 小猫爬山
这道题时dfs最基础的题目了
我们只需设计搜索的状态这道题就可以轻易的写出来
我们设(x,y)是搜索的状态即前x个小猫用了y个缆车
我们要转移的情况只有两种
- 小猫上前y辆缆车
- 小猫上y+1辆缆车(新开一辆)
所以我们只要枚举就好
然后就是如何优化算法
首先假如我们已经得到一个解pay,若此时的大于pay则不可能会更优,所以可以自己而回溯
然后我们把小猫从大到小排序可以排除很多不可能是结果的情况
#include
using namespace std;
const int N = 20;
int n , w , c[N] , f[N], pay = N;
inline int read()
{
register int x = 0;
register char ch = getchar();
while( ch < '0' || ch > '9' ) ch = getchar();
while( ch >= '0' && ch <= '9' )
{
x = ( x << 3 ) + ( x << 1 ) + ch - '0';
ch = getchar();
}
return x;
}
inline void dfs( int x , int y )
{
if( x > n )
{
pay = min( pay , y );
return ;
}
if( y > pay ) return ;
for( register int i = 1 ; i <= y ; i ++ )
{
if( f[i] + c[x] > w ) continue;
f[i] += c[x];
dfs( x + 1 , y );
f[i] -= c[x];
}
y ++;
f[y] += c[x];
dfs( x + 1 , y );
f[y] = 0;
return ;
}
inline bool cmp( int x , int y ) { return x > y; }
int main()
{
n = read() , w = read();
for( register int i = 1 ; i <= n ; i ++ ) c[i] = read();
sort( c + 1 , c + 1 + n , cmp );
dfs( 1 , 0 );
cout << pay << endl;
return 0;
} AcWing 166. 数独
这是一道经典的搜索题,不过是数据加强过的版本,所有直接搜索会T
必须要进行一些优化
首先我们想自己玩数独的时候是怎么玩的
肯定是首先填可能的结果最少的格子,在也是这道题优化的核心
如何快速的确定每个格子的情况?
const int n = 9;
int row[n] , col[n] , cell[3][3];
// row[] 表示行 col表示列 cell[][] 表示格子
我们用一个九位二进制数来表示某一行、某一列、或某一个中可以填入的数,其中1表示可以填,0表示不能填
对于\((x,y)\)这个点我们只需\(row[x] \bigcap col[y] \bigcap cell[\frac{x}{3}][\frac{y}{3}]\)就可以知道这个点可以填入数字的集合然后用lowbit()把每一位取出来即可
而在二进制中的交集就是$& $操作,所以取交集的函数就是
inline int get( int x , int y )
{
return row[ x ] & col[ y ] & cell[ x / 3 ][ y / 3];
}
还有什么优化呢,lowbit()的时间复杂度是\(O(log(n))\)我们可以通过预处理把一些操作变成\(O(1)\)的
首先每次lowbit()得到的并不是最后一个一定位置而是一个二进制数,可以用这个maps[],\(O(1)\)查询最后一为的具体位置
for( register int i = 0 ; i < n ; i ++ ) maps[ 1 << i ] = i;
其次对于每个二进制数中有多少个\(1\)的查询也是很慢的,可以用这个ones[],\(O(1)\)查询一个二进制数中有多少个\(1\)
for( register int i = 0 , s = 0 ; i < 1 << n ; i ++ , s = 0)
{
for( register int j = i ; j ; j -= lowbit( j ) ) s ++;
ones[ i ] = s;
}
剩下就是常规的\(DSF\)
#include
#define lowbit( x ) ( x & -x )
using namespace std;
const int N = 100 , n = 9;
int maps[ 1 << n ] , ones[ 1 << n ] , row[n] , col[n] , cell[3][3];
char str[N];
inline void init() //初始化
{
for( register int i = 0 ; i < n ; i ++ ) row[i] = col[i] = ( 1 << n ) - 1 ;
for( register int i = 0 ; i < 3 ; i ++ )
{
for( register int j = 0 ; j < 3 ; j ++ ) cell[ i ][ j ] = ( 1 << n ) - 1;
}
}
inline int get( int x , int y ) //取交集
{
return row[ x ] & col[ y ] & cell[ x / 3 ][ y / 3];
}
inline bool dfs( int cnt )
{
if( !cnt ) return 1; // 已经填满
register int minv = 10 , x , y;
for( register int i = 0 ; i < n ; i ++ )
{
for( register int j = 0 ; j < n ; j ++ )
{
if( str[ i * 9 + j ] != '.' ) continue;
register int t = ones[ get( i , j ) ];
if( t < minv ) // 找到可能情况最少的格子
{
minv = t;
x = i , y = j ;
}
}
}
for( register int i = get( x , y ) ; i ; i -= lowbit( i ) ) // 枚举这个格子填那些数
{
register int t = maps[ lowbit(i) ];
row[x] -= 1 << t , col[y] -= 1 << t; // 打标记
cell[ x / 3 ][ y / 3 ] -= 1 << t;
str[ x * 9 + y ] = t + '1';
if( dfs(cnt - 1 ) ) return 1;
row[x] += 1 << t , col[y] += 1 << t; // 删除标记
cell[ x / 3 ][ y / 3 ] += 1 << t;
str[ x * 9 + y ] = '.';
}
return 0;
}
int main()
{
for( register int i = 0 ; i < n ; i ++ ) maps[ 1 << i ] = i;
for( register int i = 0 , s = 0 ; i < 1 << n ; i ++ , s = 0)
{
for( register int j = i ; j ; j -= lowbit( j ) ) s ++;
ones[ i ] = s; // i 这个数二进制中有多少个 1
}
while( cin >> str , str[0] != 'e' )
{
init();
register int cnt = 0;
for( register int i = 0 , k = 0 ; i < n ; i ++ )
{
for( register int j = 0 ; j < n ; j ++ , k ++ )
{
if(str[k] == '.' ) { cnt ++ ; continue; } //记录有多少个数字没有填
register int t = str[k] - '1'; // 把已经填入的数字删除
row[ i ] -= 1 << t;
col[ j ] -= 1 << t;
cell[ i / 3 ][ j / 3 ] -= 1 << t;
}
}
dfs( cnt );
cout << str << endl;
}
return 0;
}
0x23 剪枝
剪枝,就是减小搜索树的规模、尽早的排除搜索树中不必要的成分
- 优化搜索顺序
在一些问题中,搜索树的各个层次、各个分支的顺序是不固定的。不同的搜索顺序会产生不同的搜索树形态,其规模相差也很大。我们可以通过优先搜索更有可能出现结果的分支来提前找到答案 - 排除等效冗余
在搜索的过程中,如果能够判定搜索树上当前节点的几个分支是等效的,这我们搜索其中一个分支即可 - 可行性剪枝
在搜索的过程中对当前的状态进行检查,如果无论如何都不可能走到边界我们就放弃搜索当前子树,直接回溯 - 最优性剪枝
在搜索过程中假设我们已经找到了某一个解,如果我们目前的状态比已知解更劣就放弃继续搜索下去因为无法比当前解更优呢么后面情况累加起来后一定比当前解更劣,所以直接回溯 - 记忆化
可以记录每个状态的结果,在每次遍历过程中检查当前状态是否已经被访问过,若果被访问过直接返回之前搜索的结果
AcWing 167.木棒
这是一道经典的剪枝题
优化搜索顺序
- 把木棍从大到小排序,优先尝试比较长的木棍,越短的木棍适应能力越强
排除等效冗余
- 限制加入木棍的顺序必须是递减的,因为假如有两根木棍\(x,y(x
- 如果上一根木棍失败且和当前木棍长度相同,这当前木棍一定失败
- 如过当前木棍已经拼成一个完整的木棍,当后面拼接过程中失败则当前木棍无论怎么拼都一定会失败,因为在重新尝试的过程中会使用更多更小的木棍来拼成当前木棍,但更小的木棍的适用性更强,却失败了,所以用更长的木棍尝试也一定会失败
#include
#pragma GCC optimize(3,"Ofast","inline")
#pragma GCC optimize(2)
using namespace std;
const int N = 100;
int n , m , a[N] , sum , cnt , len ;
bool v[N];
inline int read()
{
register int x = 0;
register char ch = getchar();
while( ch < '0' || ch > '9' ) ch = getchar();
while( ch >= '0' && ch <= '9' )
{
x = ( x << 3 ) + ( x << 1 ) + ch - '0';
ch = getchar();
}
return x;
}
inline bool cmp( int x , int y ) { return x > y; }
inline bool dfs( int stick , int cur , int last)
{
if ( stick == cnt ) return 1;
if ( cur == len ) return dfs( stick + 1 , 0 , 1 );
register int fail = 0;
for (register int i = last; i <= n; i++) // 剪枝 2
{
if( v[i] || cur + a[i] > len || fail == a[i] ) continue;
// fail == a[i] 剪枝 3
v[i] = 1;
if ( dfs( stick , cur + a[i] , i + 1 ) ) return 1;
v[i] = 0 , fail = a[i];
if ( cur == 0 || cur + a[i] == len ) break;
// cur + a[i] = len 剪枝 4
}
return 0;
}
inline void work()
{
sum = n = 0;
for( register int i = 1 ; i <= m ; i ++ )
{
register int x = read();
if( x > 50 ) continue;
a[ ++ n ] = x , sum += x;
}
sort( a + 1 , a + 1 + n , cmp );
//剪枝 1
for( len = a[1] ; len <= sum ; len ++ )
{
if( sum % len ) continue;
cnt = sum / len;
memset( v , 0 , sizeof( v ) );
if( dfs( 1 , 0 , 1 ) ) break;
}
printf( "%d\n" , len );
return ;
}
int main()
{
while(1)
{
m = read();
if( m == 0 ) break;
work();
}
return 0;
}
0x24 迭代加深
深度优先搜索(\(ID-DSF\))就是每次选择一个分支,然后不断的一直搜索下去,直到搜索边界在回溯,这种算法有一定的缺陷
比如下面这张图,我要红色点走到另一个红色点
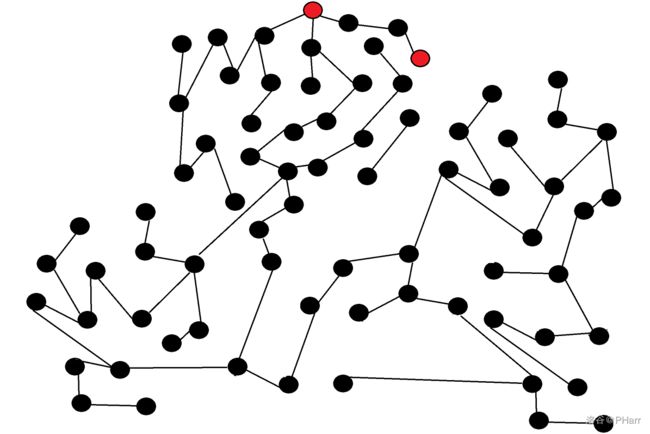
如果用普通的\(DFS\)前面的很多状态都是无用的,因为子树太深了
并且每到一个节点我都要储存很多的东西\(BFS\)很不好存
这是就要用到迭代加深了
AcWing 170. 加成序列
这道题就是一个迭代加深搜索的模板题
为什么是迭代加深搜索呢?
分析题目给的性质
如果使用\(DFS\),你需要搜索很多层,并且第一个找到的解不一定最有解
如果使用\(BFS\),你需要在队列中储存\(M\)个长度为\(n\)的数组(\(M\)是队列长度),不仅储存非常麻烦并且还有可能会爆栈
所以通过迭代加深性质就能很好的解决这个问题
限制序列的长度,不断从已知的数中找两个相加,到边界时判断一下,比较常规
优化搜索顺序
- 为了能够尽早的达到\(n\),从大到小枚举\(i\),\(j\)
排除等效冗余
- 因为\(i\),\(j\)和\(j\),\(i\)是等效的所以保证\(j \le i\)
- 不同的\(i\),\(j\)可能出现\(a[i]+a[j]\)相同的情况,对相加结果进行判重
#include
using namespace std;
const int N = 105;
int n , m , a[N];
bitset< N > vis;
inline int read()
{
register int x = 0;
register char ch = getchar();
while( ch < '0' || ch > '9' ) ch = getchar();
while( ch >= '0' && ch <= '9' )
{
x = ( x << 3 ) + ( x << 1 ) + ch - '0';
ch = getchar();
}
return x;
}
inline bool ID_dfs( int k )
{
if( k > m ) return a[m] == n;
vis.reset();
for( register int i = k - 1 ; i > 0 ; i -- )
{
for( register int j = k - 1 ; j > 0 ; j -- )
{
register int cur = a[i] + a[j];
if( cur > n || vis[ cur ] || cur < a[ k - 1 ]) continue;
a[k] = cur;
vis[ cur ] = 1;
if( ID_dfs( k + 1 ) ) return 1;
}
}
return 0;
}
inline void work()
{
for( m = 1 ; m <= n ; m ++ )
{
if( ID_dfs( 2 ) ) break;
}
for( register int i = 1 ; i <= m ; i ++ ) printf( "%d " , a[i] );
puts("");
return ;
}
int main()
{
a[1] = 1 , a[2] = 2;
for( n = read() ; n ; n = read() ) work();
return 0;
}
双向搜索
除了迭代加深外,双向搜索也可以大大减少在深沉子树上浪费时间
在一些问题中有明确的初始状态和末状态,呢么就可以采用双向搜索
从初状态和末状态出发各搜索一半,产生两颗深度减半的搜索树,在中间交汇组合成最终答案
AcWing 171.送礼物
这到题显然是一个\(DP\),但是由于它数字的范围非常大做\(DP\)肯定会\(T\)
所以这道题的正解就是\(DFS\)暴力枚举所有可能在判断
但是\(n\le 46\)所以搜索的复杂度是\(O(2^{46})\)依然会\(T\)
所以还是要想办法优化,这里用了到了双向搜索的思想
我们将\(a[1\cdots n]\),分成\(a[1\cdots mid]\)和\(a[mid+1\cdots n]\)两个序列
首先现在第一个序列中跑一次\(DFS\)求出所以可以产生的合法情况,去重,排序
然后在第二个序列中再跑一次\(DFS\),求出的每一个解\(x\)就在第一序列产生的结构中二分一个\(y\)满足\(max(x),x\in\{ x | x + y \le W \}\),更新答案
优化
- 优化搜索顺序,从大到小搜索,很常规
- 我们发现第二次\(DFS\)中会多次二分,所以我们可以适当的减少第二个序列长度,来平衡复杂度。换句话来说就是适当的减少二分的次数,根据实测\(mid=\frac{n}{2}+2\)效果最好
#include
using namespace std;
const int N = 50;
int w , n ,tot , a[N] , mid , ans , m ;
vector < int > s;
inline int read()
{
register int x = 0;
register char ch = getchar();
while( ch < '0' || ch > '9' ) ch = getchar();
while( ch >= '0' && ch <= '9' )
{
x = ( x << 3 ) + ( x << 1 ) + ch - '0';
ch = getchar();
}
return x;
}
inline void dfs_1( int x , long long sum )
{
s.push_back( sum );
if( x > mid ) return ;
if( sum + a[x] <= w ) dfs_1( x + 1 , sum + a[x] );
dfs_1( x + 1 , sum );
return ;
}
inline void dfs_2( int x , long long sum )
{
register auto t = lower_bound( s.begin() , s.end() , w - sum , greater() );
if( sum + *t <= w ) ans = max( ans , I(sum) + *t );
if( x > n ) return ;
if( sum + a[x] <= w ) dfs_2( x + 1 , sum + a[x] );
dfs_2( x + 1 , sum );
return ;
}
int main()
{
w = read() , m = read() ;
for( register int i = 1 ; i <= m ; i ++ )
{
register int x = read();
if( x > w ) continue;
a[ ++ n ] = x;
}
mid = n >> 1 + 2;
sort( a + 1 , a + 1 + n , greater() );
dfs_1( 1 , 0 );
sort( s.begin() , s.end() );
unique( s.begin() , s.end() );
dfs_2( mid + 1 , 0);
cout << ans << endl;
return 0;
}
0x25 广度优先搜索
\(BFS\) 全称是 \(Breadth First Search\) ,中文名是宽度优先搜索,也叫广度优先搜索。
是图上最基础、最重要的搜索算法之一。
所谓宽度优先。就是每次都尝试访问同一层的节点。 如果同一层都访问完了,再访问下一层。
这样做的结果是,\(BFS\) 算法找到的路径是从起点开始的 最短 合法路径。换言之,这条路所包含的边数最小。
在 \(BFS\) 结束时,每个节点都是通过从起点到该点的最短路径访问的。
算法过程可以看做是图上火苗传播的过程:最开始只有起点着火了,在每一时刻,有火的节点都向它相邻的所有节点传播火苗。
AcWing 172. 立体推箱子
这到题是宽搜中比较有难度的一道
这道题中不变的是图,变化的是物体的状态,所以本题的难点就在于如何设计状态
我们可以用一个三元组\((x,y,lie)\)来代表一个状态(搜索树上的一个节点)
当\(lie=0\)时,物体立在\((x,y)\)上
当\(lie=1\)时,物体横向躺着,并且左半部分在\((x,y)\)上
当\(lie=2\)时,物体纵向躺着,并且上半部分在\((x,y)\)上
并且用数组\(d[x][y][lie]\)表述从其实状态到每个状态所需要的最短步数
设计好状态就可以开始搜索了
#include
using namespace std;
const int N = 510;
const int dx[4] = { 0 , 0 , 1 , -1 } , dy[4] = { 1 , -1 , 0 , 0 };
const int next_x[3][4] = { { 0 , 0 , -2 , 1 } , { 0 , 0 , -1 , 1 } , { 0 , 0 , -1 , 2 } };
const int next_y[3][4] = { { -2 , 1 , 0 , 0 } , { -1 , 2 , 0 , 0 } , { -1 , 1 , 0 , 0 } };
const int next_lie[3][4] = { { 1 , 1 , 2 , 2 } , { 0 , 0 , 1 , 1 } , { 2 , 2 , 0 , 0 } };
int n , m , d[N][N][3] , ans;
char s[N][N];
struct rec{ int x , y , lie; } st , ed ; //状态
queue< rec > q;
inline bool valid( int x , int y ) { return x >= 1 && x <= n && y >= 1 && y <= m; }
bool operator == (rec a ,rec b ){ return a.x == b.y && a.y == b.y && a.lie == b.lie ;}
inline void pares_st_ed()
{
for( register int i = 1 ; i <= n ; i ++ )
{
for( register int j = 1 ; j <= m ; j ++ )
{
if( s[i][j] == 'O') ed.x = i , ed.y = j , ed.lie = 0, s[i][j] = '.';
else if( s[i][j] == 'X' )
{
for( int k = 0 ; k < 4 ; k ++ )
{
register int x = i + dx[k] , y = j + dy[k];
if( valid( x , y ) && s[x][y] == 'X' )
{
st.x = min( i , x ) , st.y = min( j , y ) , st.lie = k < 2 ? 1 : 2;
s[i][j] = s[x][y] = '.';
break;
}
}
}
if( s[i][j] == 'X' ) st.x = i , st.y = j , st.lie = 0;
}
}
}
inline bool check( rec next )
{
if( !valid( next.x , next.y ) ) return 0;
if( s[next.x][next.y] == '#' ) return 0;
if( next.lie == 0 && s[next.x][next.y] != '.' ) return 0;
if( next.lie == 1 && s[next.x][next.y] == '#' ) return 0;
if( next.lie == 2 && s[next.x][next.y] == '#' ) return 0;
return 1;
}
int bfs() {
for( register int i = 1 ; i <= n ; i ++ )
{
for( register int j = 1 ; j <= m ; j ++ )
{
for( register int k = 1 ; k <= n ; k ++ ) d[i][j][k] = -1;
}
}
while( q.size() ) q.pop();
d[st.x][st.y][st.lie] = 0 ;
q.push( st );
rec now , next;
while( q.size() )
{
now = q.front() , q.pop();
for( int i = 0 ; i < 4; i ++ )
{
next.x = now.x + next_x[now.lie][i] , next.y = now.y + next_y[now.lie][i] , next.lie = next_lie[now.lie][i];
if (!check(next)) continue;
if (d[next.x][next.y][next.lie] == -1)
{
d[next.x][next.y][next.lie] = d[now.x][now.y][now.lie]+1;
q.push(next);
if (next.x == ed.x && next.y == ed.y && next.lie == ed.lie) return d[next.x][next.y][next.lie]; // 到达目标
}
}
}
return -1;
}
int main()
{
while( 1 )
{
cin >> n >> m;
if( !n && !m ) break;
for( register int i = 1 ; i <= n ; i ++ ) scanf( "%s" , s[i] + 1 );
pares_st_ed();
ans = bfs();
if( ans == -1 ) puts("Impossible");
else cout << ans << endl;
}
return 0;
} 在上述的代码中使用了\(next\_x,next\_y,next\_lie\)这三个数组来表示向四个方向移动的变化情况时宽搜中常用的一中技巧,避免了大量使用\(if\)语句容易造成混乱的情况
Luogu P3456 GRZ-Ridges and Valleys
这道题时一个宽搜的经典题,如果用\(DFS\)会爆栈
看代码就可以理解
#include
using namespace std;
const int N = 1005;
const int dx[8] = { -1 , -1 , -1 , 0 , 0 , 1 , 1 , 1 } , dy[8] = { -1 , 0 , 1 , -1 , 1 , -1 , 0 , 1 };
//向 8 个方向扩展
int n , maps[N][N] , valley , peak;
bool vis[N][N] , v , p;
struct node
{
int x , y;
} _ , cur;// 储存搜索状态
queue< node > q;
inline int read()
{
register int x = 0;
register char ch = getchar();
while( ch < '0' || ch > '9' ) ch = getchar();
while( ch >= '0' && ch <= '9' )
{
x = ( x << 3 ) + ( x << 1 ) + ch - '0';
ch = getchar();
}
return x;
}
inline node make_node( int x , int y ) { _.x = x , _.y = y; return _; }
inline int bfs()
{
register int ux , uy;
while( !q.empty() )
{
cur = q.front() , q.pop();
for( register int i = 0 ; i <= 7 ; i ++ )
{
ux = cur.x + dx[i] , uy = cur.y + dy[i];
if( ux < 1 || ux > n || uy < 1 || uy > n ) continue;
//判断是否跃出边界
if( maps[ux][uy] == maps[ cur.x ][ cur.y ] && !vis[ux][uy] )
{//如果高度相同,打标记继续搜索
vis[ux][uy] = 1;
q.push( make_node( ux , uy ) );
}
else//判断当前联通块是 山峰 或 山谷
{
if( maps[ux][uy] > maps[cur.x][cur.y] ) p = 0;
if( maps[ux][uy] < maps[cur.x][cur.y] ) v = 0;
}
}
}
}
int main()
{
n = read() , v = 1;
for( register int i = 1 ; i <= n ; i ++ )
{
for( register int j = 1 ; j <= n ; j ++ )
{
maps[i][j] = read();
if( maps[i][j] != maps[1][1] ) v = 0;
}
}
if( v ) puts("1 1") , exit(0);//特殊情况判断
for( register int i = 1 ; i <= n ; i ++ )
{
for( register int j = 1 ; j <= n ; j ++ )
{
if( vis[i][j] ) continue;//判断当前点是否是被搜索的联通块
v = p = vis[i][j] = 1;
q.push( make_node( i , j ) );
bfs();
peak += p , valley += v;
}
}
cout << peak << ' ' << valley << endl;
return 0;
}
0x26广搜变形
双端队列\(BFS\)
双端队列 \(BFS\) 又称 \(0-1 BFS\)
适用范围
在一张图中,如果一张图中,有些边有边权,有些边没有边权,如果要搜索这个图,就要用双端队列\(BFS\)
具体实现
在搜索过程中,如果遇到的没有边权的边就加入队头,如果有边权就加入队尾
AcWing 175. 电路维修
可以把这张方格图,抽象成点,然后把图中有的边当成边权为\(1\),把没有的边当作没有边权的边
然后做双端队列\(BFS\)就好
#include
#define PII pair< int , int >
using namespace std;
const int N = 510 , INF = 0x7f7f7f7f;
const int dx[4] = { -1 , -1 , 1 , 1 } , dy[4] = { -1 , 1 , 1 , -1 };
const int ix[4] = { -1 , -1 , 0 , 0 } , iy[4] = { -1 , 0 , 0 , -1 };
int n , m , T , t , d[N][N];
bool vis[N][N];
char g[N][N] , cs[] = "\\/\\/";
inline int bfs()
{
deque< PII > q;
memset( vis , 0 , sizeof( vis ) );
memset( d , INF , sizeof( d ) );
d[0][0] = 0;
q.push_back( { 0 , 0 } );
while( !q.empty() )
{
auto cur = q.front() ; q.pop_front();
register int x = cur.first , y = cur.second;
if( vis[x][y] ) continue;
vis[x][y] = 1;
for( register int i = 0 ; i < 4 ; i ++ )
{
register int a = x + dx[i] , b = y + dy[i];
register int j = x + ix[i] , k = y + iy[i];
if( a >= 0 && a <= n && b >= 0 && b <= m)
{
register int w = 0;
if( g[j][k] != cs[i] ) w = 1;
if( d[a][b] > d[x][y] + w )
{
d[a][b] = d[x][y] + w;
if( w ) q.push_back( { a , b } );
else q.push_front( { a , b } );
}
}
}
}
if( d[n][m] == INF ) return -1;
return d[n][m];
}
inline void work()
{
cin >> n >> m;
for( register int i = 0 ; i < n ; i ++ ) scanf( "%s" , g[i] );
t = bfs();
if( t == -1 ) puts("NO SOLUTION");
else printf( "%d\n" , t );
return ;
}
int main()
{
cin >> T;
while( T -- ) work();
return 0;
}
优先队列\(BFS\)
这里就是利用优先队列的性质,每次优先扩展最优的状态
AcWing 176. 装满的油箱
这题要用到优先队列,因为普通的DFS会超时的
首先我们使用一个二元组\(\{city,fuel\}\)来表示一个状态,每个状态的权值就是到达这个状态所需要的权值
然后们把所有的状态都放入一个堆中,并且按照权值从小到大排序
每次我们去除堆顶的元素进行扩展
- 如果当前油箱还没有满,就扩展\(\{city,fuel+1\}\)这个状态
- 遍历以当前边为起点的所有边,如果当前油箱的油可以到达下一个城市,就扩展\(\{v , fuel -d[city][v\}\)这个状态
所以当我们第一次从对头取出终点,就是最优解
#include
#define F first
#define S second
using namespace std;
const int N = 1005 , C = 105 , INF = 0x7f7f7f7f;
int n , m , T , c , st , ed , tot , a[N] , head[N] , dist[N][C];
bool vis[N][C];
priority_queue< pair< int , pair< int , int > > > q;
vector< pair< int , int > > e[N];
inline int read()
{
register int x = 0;
register char ch = getchar();
while( ch < '0' || ch > '9' ) ch = getchar();
while( ch >= '0' && ch <= '9' )
{
x = ( x << 3 ) + ( x << 1 ) + ch - '0';
ch = getchar();
}
return x;
}
inline void work()
{
c = read() , st = read() , ed = read();
while( !q.empty() ) q.pop();
memset( vis , 0 , sizeof( vis ) );
memset( dist , INF , sizeof( dist ) );
dist[ st ][0] = 0;
q.push( make_pair( 0 , make_pair( st , 0 ) ) );
while( !q.empty() )
{
register int city = q.top().S.F , fuel = q.top().S.S;
q.pop();
if( city == ed )
{
cout << dist[city][fuel] << endl;
return ;
}
if( vis[city][fuel] ) continue;
vis[city][fuel] = 1;
if( fuel < c && dist[city][fuel + 1 ] > dist[city][fuel] + a[city] )
{
dist[city][ fuel + 1 ] = dist[city][fuel] + a[city];
q.push(make_pair( - dist[city][fuel] - a[city], make_pair( city , fuel + 1 ) ) );
}
for( auto it : e[city] )
{
register int y = it.F , z = it.S;
if( z <= fuel && dist[y][ fuel - z ] > dist[city][fuel] )
{
dist[y][ fuel - z ] = dist[city][fuel];
q.push(make_pair( - dist[city][fuel] , make_pair( y , fuel - z ) ) );
}
}
}
puts("impossible");
}
int main()
{
n = read() , m = read();
for( register int i = 0 ; i < n ; i ++ ) a[i] = read();
for( register int i = 1 ; i <= m ; i ++ )
{
register int u = read() , v = read() , w = read();
e[u].push_back( make_pair( v , w ) );
e[v].push_back( make_pair( u , w ) );
}
T = read();
while( T -- ) work();
return 0;
}
双向\(BFS\)
双向BFS的思想和0x24中双向搜索是相同的,因为BFS是逐层搜索,所以会更好理解,同时算法实现也很简单
从起始状态,目标状态分别开始,两边轮流进行,每次各扩展一层。当两边各自有一个状态在记录数组中发生重复时,就说明搜索过程中相遇,可以合并各自出发点到当前的最少步数
//开始结点 和 目标结点 入队列 q
//标记开始结点为 1
//标记目标结点为 2
while( !q.empty() )
{
//从 q.front() 扩展出新的s个结点
//如果 新扩展出的结点已经被其他数字标记过
//那么 表示搜索的两端碰撞
//那么 循环结束
//如果 新的s个结点是从开始结点扩展来的
//那么 将这个s个结点标记为1 并且入队q
//如果 新的s个结点是从目标结点扩展来的
//那么 将这个s个结点标记为2 并且入队q
}
0x27 A*
注:本小结在叙述过程中使用参照了\(cdcq\)和\(thu\)的\(ppt\),所以一些概念与我们常规的定义略有冲突
在之前的优先队列\(BFS\)中,我们通过记录从起始状态到当前状态的权值\(W\),并且按照\(W\)排序,这样可以减少许多不必要的搜索
这其实就是一种贪心的思想,如果遇到当前的权值比较小,但后面的权值非常大,此时在用这种套路就会增加很多不必要的搜索
所以也就有了启发式搜索\(A\),首先我们要定义一些符号方便理解
s//初始状态
t//目标状态
n//当前状态
g*[n] //从 s 到 n 的最小代价
h*[n] //从 n 到 t 的最小代价
f*[n] = h*[n] + g*[n]//从 s 到 t 的最小代价对于每个状态,我们按照他的\(f[n]\)排序,每次取出最优解,扩展状态,直到第一次扩展到\(t\),结束循环
虽然\(A\)算法保证一定可以最先找到最优解,但多数时候会因为求\(h^*[n]\),会耗费很大的代价,导致时间复杂度变大
所以就有了另一种算法最佳图搜索算法\(A^*\),还是我们要定义一些符号
g[n] // g*[n] 的估计值 ,但是由于我们已经访问到当前状态所以g[n] == g*[n]
h[n] // h*[n] 的估计值
f[n] = h[n] + g[n] // f*[n] 的估计值 称为估价函数只要保证\(h[n] \le h^*[n]\),剩余不变\(A\)算法就变成了\(A^*\)算法
可以简单的叙述下正确性,因为\(h[n] \le h^*[n]\),即使估计函数不太准确,导致路径上的非最有状态被提前扩展
但是由于\(g[n]\)不断累加,\(f[n]\)会不段的逼近\(f^*[n]\),所以最先扩展到状态时一定还是最优解,因为\(h[t]==0\)
另外如果\(h[n]=0\)的话,\(A^*\)算法就变成了优先队列\(BFS\),所以优先队列\(BFS\)就是估价函数不够优秀的\(A^*\)算法
所以如何设计一个优秀的估价函数就是\(A^*\)算法的精髓
AcWing 178. 第K短路
听说因为数据比较水,所以可以\(dijkstra\)第\(k\)次弹出也可以过
\(A^*\)的题都没什么好说的,只要知道怎么设计估价函数其他就是模板了
我们看估价函数的定义式\(h[x]=f[x]+g[x]\)
我们发现\(g[x]\)是关键,\(g[x]\)的定义就是从当前状态的步数到目标状态的可能步数,且必须保证\(g[x]\le g^*[x]\)
不难想到求个最短路就好了,不过要求的是多源单汇最短路,且图是个有向图,用\(floyed\)也是不合适的
所以我们可以在反向图上跑从T出发的单源多汇最短路的值作为\(g[x]\)即可
#include
#define PII pair< int , int >
#define IPII pair< int , PII >
#define F first
#define S second
using namespace std;
const int N = 1005 , INF = 0x7f7f7f7f ;
int n , m , vis[N] , g[N] , st , ed , k , ans;
vector< PII > from[N] , to[N];
inline int read()
{
register int x = 0;
register char ch = getchar();
while( ch < '0' || ch > '9' ) ch = getchar();
while( ch >= '0' && ch <= '9' )
{
x = ( x << 3 ) + ( x << 1 ) + ch - '0';
ch = getchar();
}
return x;
}
inline void addedge( int u , int v , int w )
{
to[u].push_back( { v , w } );
from[v].push_back( { u ,w } );
}
inline void dijkstra()
{
priority_queue< PII , vector < PII > , greater< PII > > q;
memset( g , INF , sizeof( g ) );
g[ed] = 0;
q.push( { g[ed] , ed } );
int u , v , dist , w ;
while( !q.empty() )
{
u = q.top().S , dist = q.top().F , q.pop();
if( vis[u] ) continue;
for( auto it : from[u] )
{
v = it.F , w = it.S;
if( g[v] <= g[u] + w ) continue;
g[v] = g[u] + w;
q.push( { g[v] , v } );
}
}
return ;
}
inline void A_star()
{
priority_queue< IPII , vector< IPII > , greater< IPII > > q;
memset( vis , 0 , sizeof( vis ) );
q.push( { g[st] , { st , 0 } } );
int u , v , w , dist;
while( !q.empty() )
{
u = q.top().S.F , dist = q.top().S.S , q.pop();
if( vis[u] >= k ) continue;
vis[u] ++;
if( u == ed && vis[u] == k ) printf( "%d\n" , dist ) , exit(0);
for( auto it : to[u] )
{
v = it.F , w = it.S;
if( vis[v] >= k ) continue;
q.push( { dist + w + g[v] , { v , dist + w } } );
}
}
return ;
}
int main()
{
n = read() , m = read();
for( register int i = 1 ; i <= m ; i ++ )
{
register int u = read() , v = read() , w = read();
addedge( u , v , w );
}
st = read() , ed = read() , k = read();
if( st == ed ) k ++;
dijkstra();
A_star();
puts( "-1" );
return 0;
}
0x28 IDA*
\(cdcq\):\(ID\)还是那个\(ID\),\(A^*\)还是那个\(A^*\)
首先我们设计一个估价函数,然后在\(ID-DFS\)的框架下进行搜索
如果当前深度+未来估计深度 > 深度的限制 立即回溯
这就是\(IDA^*\)的核心,换言之\(IDA^*\)就是迭代加深的\(A^*\)
\(IDA^*\)算法的实现流程基本和\(ID - DFS\)相同
只需要咋搜索每次执行前写上这句即可
if( dep + f() > max_dep ) return ;
所以\(IDA^*\)和\(A^*\)共同精髓都是设计估价函数
并且要保证\(f(x)\le f^*(x)\) ,证明如下
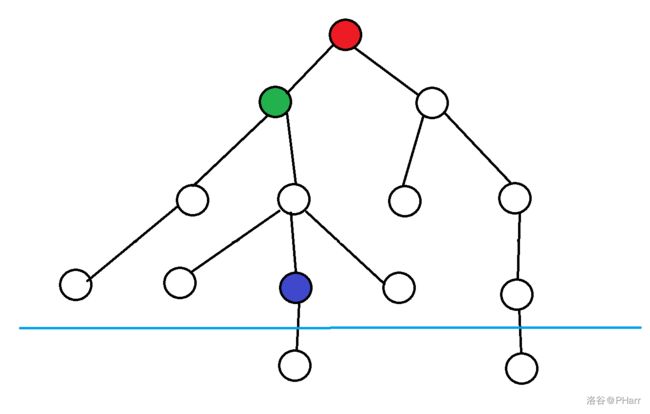
红色点是起始状态,绿色点是当前状态,紫色为目标,蓝色线为我们迭代到的最大权值
我们现在要估计绿色到紫色点的权值,如果我么的估计值小于实际值,则已消耗的权值加估计值就一定小于最大权值这可以继续搜索
如果不能保证估计权值小于实际权值,则可能会出现已消耗的权值加估计值大于最大权值,此时就不会继续搜索绿色点的子树,也就不可能的到达紫色点
所以不保证估计值小于实际值就不能保证正确性
AcWing 180. 排书
这道题就是经典的\(IDA^*\)
由于n比较小,且最多搜索5层,所以可以直接用一个数组来存下每一层 的状态
然后就是设计估价函数
我们可以每次修改一个区间
对于任意一种状态下如果$p[i+1] \neq p[i]+1 \(则\)i$和i+1是一定要调开的,我们把这种情况称作一个错误状态
我们统计一下错误的状态为\(cnt\)
我们的每一次操作最多可以改变3个错误状态,所以最理想的状态下就是$次可以把整个序列调整成目标序列
所以就得到了一种估价函数\(f() = \left \lceil \frac{cnt}{3} \right \rceil\)
#include
using namespace std;
const int N = 20;
int T , n , q[N] , cur[5][N] , max_dep , ans;
bool flag;
inline int read()
{
register int x = 0;
register char ch = getchar();
while( ch < '0' || ch > '9' ) ch = getchar();
while( ch >= '0' && ch <= '9' )
{
x = ( x << 3 ) + ( x << 1 ) + ch - '0';
ch = getchar();
}
return x;
}
inline int f()
{
register int cnt = 0;
for( register int i = 1 ; i < n ; i ++ )
{
if( q[ i + 1 ] != q[i] + 1 ) cnt ++ ;
}
return (cnt + 2 ) / 3;
}
inline bool check()
{
for( register int i = 1 ; i <= n ; i ++ )
{
if( q[i] == i ) continue;
return 0;
}
return 1;
}
inline void ida_star( int dep )
{
if( dep + f() > max_dep || flag ) return ;
if( check() )
{
ans = dep , flag = 1;
return ;
}
for( register int l = 1 ; l <= n ; l ++ )
{
for( register int r = l ; r <= n ; r ++ )
{
for( register int k = k + 1 ; k <= n ; k ++ )
{
memcpy( cur[ dep ] , q , sizeof( q ) );
register int x , y;
for( x = r + 1 , y = l ; x <= k ; x ++ , y ++ ) q[y] = cur[dep][x];
for( x = l ; x <= r ; x ++ , y ++ ) q[y] = cur[dep][x];
ida_star( dep + 1 );
if( flag ) return ;
memcpy( q , cur[dep] , sizeof( q ) );
}
}
}
return ;
}
inline void work()
{
n = read() , flag = 0;
for( register int i = 1 ; i <= n ; i ++ ) q[i] = read();
for( max_dep = 1 ; max_dep <= 4 , !flag ; max_dep ++ ) ida_star(0);
if( flag ) printf( "%d\n" , ans );
else puts("5 or more");
return ;
}
int main()
{
T = read();
while( T -- ) work();
return 0;
}