0. 前言
1. MNIST 数据集
2. 二分类器
3. 效果评测
4. 多分类器与误差分析
5. Kaggle 实战
0. 前言
- “尽管新技术新算法层出不穷,但是掌握好基础算法就能解决手头 90% 的机器学习问题。”
- 本系列参考书 "Hands-on machine learning with scikit-learn and tensorflow"以及kaggle相关资料
1. MNIST 数据集
MNIST是最常用的用来实验分类模型的数据集,有7w多张手写0-9的白底黑字数字图像,每张图像大小 28*28,共784个像素,像素取值范围为[0-255],0表示白色背景,255表示纯黑,如下图:
2. 二分类器
数字识别是个多分类问题,首先我们从两分类问题开始入手,即判断一张图片是5或者非5。应用sklearn线性模型的SGDClassifier直接训练,损失函数默认是 hinge loss,即SVM分类器,如果想用logistic regression来分类,可以选用 log loss。SGDClassifier 分类器还支持不同的损失函数,如 perceptron等,这里就不一一列举了。由于SGD分类器对训练样本的顺序是敏感的,所以在模型训练之前需要shuffle训练集。
用SVM训练结束后,用模型预测得到测试集的预测结果,评估准确率(accuracy)大概是96%,看起来是一个不错的结果,但是如果我们把所有的测试样本都判定为非5,准确率也能有90%(十分之九都是对的)。看来光凭准确率,在这种情况下不能说明我们模型学习得很好,看来如何评价模型的学习能力不是件那么简单的事情。
“观察到的一个有意思的细节:一些喜好机器学习或者数据科学的初学工程师和有机器学习或者数据科学背景的科学家,在工作上的主要区别在于如何对待负面的实验(包括线下和线上)结果。初学者往往就开始琢磨如何改模型,加Feature,调参数;思考如何从简单模型转换到复杂模型。有经验的人往往更加去了解实验的设置有没有问题;实验的Metrics的Comparison是到底怎么计算的;到真需要去思考模型的问题的时候,有经验的人往往会先反思训练数据的收集情况,测试数据和测试评测的真实度问题。初学者有点类似程咬金的三板斧,有那么几个技能,用完了,要是还没有效果,也就完了。而有经验的数据科学家,往往是从问题出发,去看是不是对问题本质的把握(比如优化的目标是不是对;有没有Counterfactual的情况)出现了偏差,最后再讨论模型。”
—— by @洪亮劼
3. 效果评测
从源头出发,如下图,x、o分别表示label为负和正的样本,划分为上下两列,假设模型预测值是一个连续值(如为正的概率),把正负样本按照预测值从低到高分别排列好。一个好的模型,应该是左上角分布较密集,表示很多负样本预测值较小,右下角分布也很密集,表示为模型预测正样本的概率值普遍偏高。当然,一般模型也无法做到百分之百的分类准确,所以存在少量的负样本预测概率较高,正样本预测概率偏低,如图右上角和左下角。
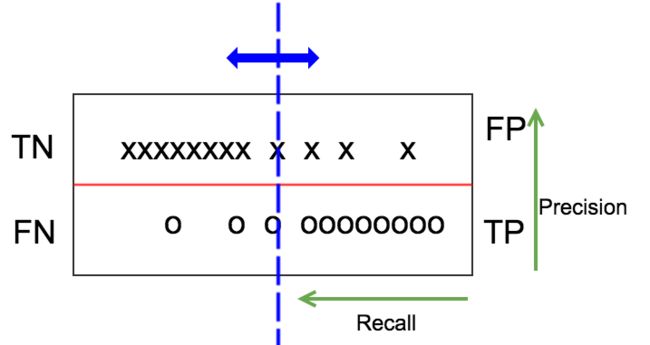
Confusion Matrix
我们设定一个阈值,用图中蓝色的竖线表示,高于阈值的模型预测为正样本,反之则为负样本。这个阈值是我们可以自行设定的,蓝色的竖线可以左右移动。红色的横线和蓝色的竖线将整个测试集数据分成四个部分,TN(True Positive)、FP(False Positive)、FN(False Negative)、TP(True Positive)。TPR(TP rate)即recall= TP/(TP+FN),precision=TP/(TP+FP)。上面我们计算accuracy实际上是 (TN+TP)/ALL,对于一个测试集来说,底下分母是不变的,如果TN对比TP很大,TP的变动很难通过accuracy反映出来。一个好的分类器,应该TP包含大部分圆圈,FP和FN几乎为空,所以很多比赛的评测指标是precision和recall的harmonic平均值,即:
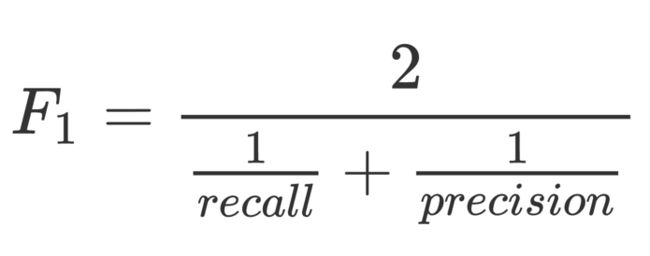
harmonic平均比直接除以2更看重较小的那个值,只有两个值都比较大,整体才会大。
PR曲线和ROC曲线
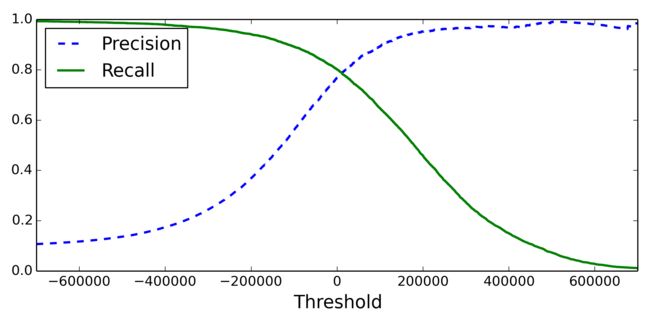
为了得到较好的F1,需要调节适当的阈值。蓝色的线从最左往右滑动时,recall= TP/(TP+FN),分母不变,分子逐渐变小,从1单调递减到0。precision=TP/(TP+FP),分子和分母同时变小,总体上,TP变小的速度慢很多,大体上是递增的,但是并不绝对单调,尤其在靠近右侧。经常可以看到TP-1,FP不变,则precision反而变小:
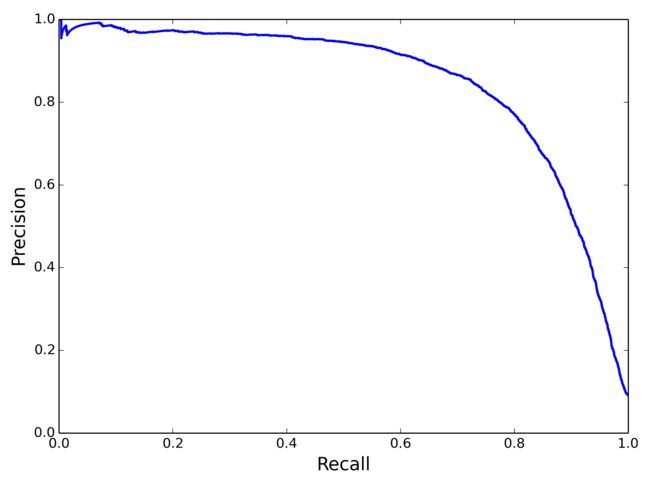
关于Recall和Precision的tradeoff,还可以画一条PR 曲线:
ROC曲线是另外一种衡量二分类模型的方法,y轴是recall=TP/(TP+FN),x轴是FPR=FP/(FP+TN):
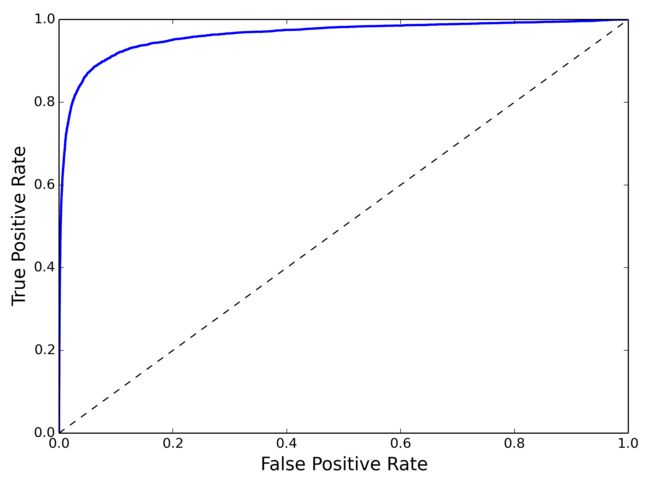
PR曲线与ROC曲线的区别在于,PR曲线不关心TN(x、y计算公式都没有包含TN),所以在负样本比例很高的时候,PR曲线波动比ROC曲线明显,更能体现优化空间。另外,ROC曲线关心TN恰好也是它的优势,比如在推荐、搜索等learn to rank 任务中,我们关心的是整个数据集的排序情况,TN也是需要考虑在内的,所以经常离线计算AUC(ROC曲线下方面积)来衡量rank model的优劣。
中场休息时间。。。喝口茶~ 欢迎关注公众号:kaggle实战,或博客:http://www.cnblogs.com/daniel-D/
4. 多分类器与误差分析
多分类器是指能区别两个以上类别的分类器,比如手写数字识别这个数据集要区分0-9,像大型图像数据集可能有几万个类别。有些算法可以直接区分多类,如softmax、RF或者贝叶斯,有些算法无法直接区分,比如上面用到的线性分类器等二分类器。二分类器也可以组合形成多分类器,常见的策略有 One vs All和 One vs One。
在数字识别这个任务中,One vs All(OVA) 一共要训练10个分类器,分别是0 vs 非0,1 vs 非1……预测的时候,10个分类器依次输出为0,为1等的概率,可直接取最大概率作为预测值。One vs One则需要10*(10-1)/ 2个分类器,依次是 0 vs 1,0 vs 2……8 vs 9。OVO和OVA在实际使用不多,这里就不赘述了。
用RF模型训练后,在预测集上预测图像属于哪个类别,由于模型不是百分百准确的,会有0判定成1或者1判定成2的情况,用rowIndex表示实际的label,colIndex表示预测的label,统计预测的label落到实际label的个数,可以得到以下矩阵:

可视化之后得到下图:

可以看到对角线方块很亮,说明所有类别基本判定准确。但是“5”方块较暗,可能是由于5的图片数量较少,或者5的准确率偏低导致,要具体分析数据才能找到原因。除了对角线方块,我们还想分析其余方块的情况,可以把Confusion Matrix每个元素处理该行的总和,对角线置0,得到下图:

可以看到3和5、7和9都容易混淆,想通过RF模型要提升效果的突破口可能就在这里。
5. Kaggle 实战
实际上,3和5、7和9容易混淆的原因在于,他们形态较为相似,直接用像素作为特征,相同的数字,在图像中旋转微小角度或者平移,都会导致像素空间的巨大变化,kaggle上高分kernel普遍都用神经网络里的CNN来提取特征,准确率可以轻松超过98%。预处理流程为:
- 把 label 从0-9的dense编码转化为 one hot encode编码
- 分割出4w个训练集和2k个验证集
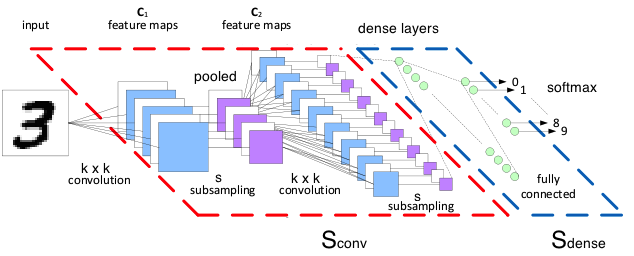
然后定义一个最常用CNN网络结构和主要的超参数如下:
-
卷积参数:一般设置stride=1,卷积后保持原尺寸,用0填充,非线性变换采用relu;pooling大小2*2,stride=2,取maxPooling
-
网络结构:
- input:(40000, 28, 28, 1)
- conv1:kernel [5, 5, 1, 32] => (40000, 28, 28, 32)
- maxPool1:kernel [1, 2, 2, 1] => (40000, 14, 14, 32)
- conv2:kernel [5, 5, 32, 64] => (40000, 14, 14, 64)
- maxPool2: kernel [1, 2, 2, 1] => (40000, 7, 7, 64)
- flat:(40000,7*7*64) => (40000, 3136)
- FC1: (40000, 1024),非线性变换仍然可以采用relu
- dropout: 0.5
- FC2:(40000, 10)
- Loss:cross-entropy
-
由于MNIST数据集各类分布都比较均匀,用准确率就能较好评估模型了,比其他指标更加直白
详细代码可以参考这个kernel:https://www.kaggle.com/kakauandme/tensorflow-deep-nn
参考资料
- Kaggle: TensorFlow deep NN
- Book: Hands-on machine learning with scikit-learn and tensorflow
- Code:03_classification.ipynb
附:公众号

顺便测试下赞赏码

