导语
「云计算的太祖长拳」系列将全面解析UCloud可用区特性技术内幕,阐述基础网络的改造和外网新特性技术实现,包括基础网络的改造、NFV虚拟网关的实践、底层SDN控制面和数据转发面的演进以及建设在新老架构间平滑迁移海量用户数据的运营能力等各个方面,分享该项目中的一些心得和经验。
在本系列的第一篇文章里(解密「云计算的太祖长拳」系列之一“胆”:基础网络改造与新架构),我们详细介绍了为了支持可用区新功能,UCloud在基础网络建设和外网特性方面所做的一系列改造,其中包括基础网络的双星型拓扑结构和POP点的建设;EIP、ULB、以及共享带宽的功能跨AZ的使用;跨AZ流量调度的核心模块 - UVER (UCloud Virtual Edge Router)的实现等方面的内容。
本篇文章是该系列的第二篇,我们会着重介绍在可用区研发过程中,我们对UCloud公有云平台的底层SDN架构所做的一系列改造。这些改造有的是宏观层面的重构和演进,有的看似是局部的调整但实则是在亲历了运营一个大型IaaS平台所遇到的那些困难之后才审慎提出的一套解决方案。
Agenda:
1.SDN底层架构重构
2.支持虚拟网络广播协议带来的架构变化
3.SDN封装隧道与流表的优化
4.结语
SDN底层架构重构(网元跨可用区的互访)
UCloud IaaS平台上支持多种不同类型的计算节点,比如公有云上的虚拟主机(我们简称“公有云”),物理主机(简称“物理云”),以及托管区域的主机(简称“托管云”)等等。这些节点或者说网元在底层SDN网络的支持下互相间是可以在虚拟网络(Virtual Network)的层面上无缝地互相通信的,同时,虚拟网络也提供了租户间互相隔离的安全机制。这些都是IaaS平台所应具备的基础能力。在可用区的场景下,这些能力从用户层面看来还是保持了和从前一致的行为,但事实上,平台底层的物理网络以及SDN逻辑其实是经历了一次彻底的重构。为了更好地理解这次重构的意义,我们首先来了解一下原有的网元跨DC互通的实现:
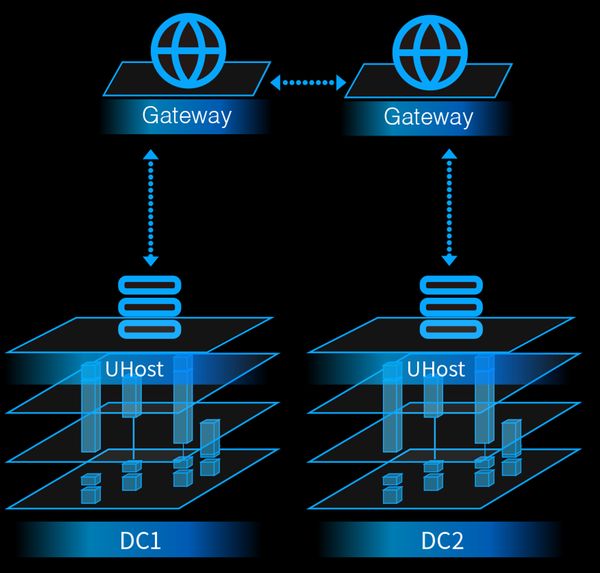
如上图所示,在之前的架构里,不同DC间的两台主机的互访是要通过跨机房的软件网关(上图中的Gateway)来转发的。当然这里底层的逻辑还是通过SDN的方式来实现的,其datapath的路径如下:
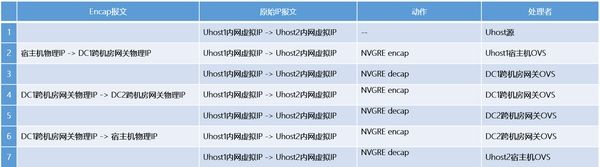
这个架构虽然能提供用户不同机房的网元间互访的能力,但从整体上来评估, 它还是具有以下三方面的问题:
互访的SDN逻辑比较复杂:两个节点间单向就需要有6条SDN的flow,所有这些flow的下发都需要经过controller和后端manager的处理,然后要考虑鉴权隔离、跨账号互通等其他相关的场景。同时,我们还必须考虑不同网元间的各种场景(比如“公有云”和“物理云”跨机房互通,“公有云”和“托管云”跨机房互通等),那复杂度必然进一步增加。
跨机房互访由于需要经过两组软件网关的转发,那么其效率一定会受到一些影响(整个逻辑链路的网络延迟会有所增加)。并且,由于这些软件网关集群位于跨机房互通的关键路径上,它们自身的可靠性和容灾能力也是我们不得不面对的问题。
后续在各个相连机房不断扩容的情况下,跨机房网关集群也必须随之扩容。但作为整个链路上必经的中央节点,这个服务理论上将面临的是O(n2)的扩容压力(假设两边机房的节点数是n),这对整个系统长期的发展来看不是一个理想的状态。
对于大型的分布式系统,一般而言,复杂度永远是软件系统稳定性和可扩展性的天敌。我们设计的目标是在保证功能性的基础上,能尽量低去简化系统,把系统“做小”:a system achieves perfection not when there is nothing more to add, but when there is nothing left to take away.
在可用区的新架构中,不同AZ间的网元之间的互通不再需要通过跨AZ网关做转发,同一Region下的两个网元之间在物理网络层面上是三层(IP层)直连的,下图是可用区启用前后网络路径的对比:
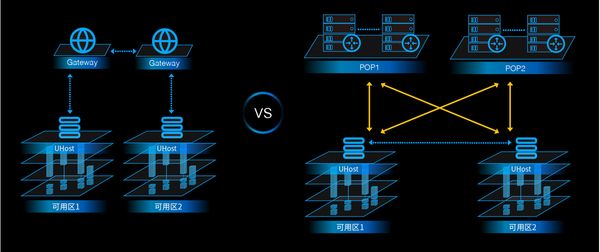
如此,不同AZ的网元间互访的datapath就和同AZ的情况是完全一致的,这就从底层保证了用户可以在其虚拟网络中部署跨AZ的云主机而不必担心受到不同物理网络拓扑的限制或影响,而在虚拟网络之上的云主机与云主机之间是一个完全“点对点”直连的“大二层”拓扑结构,在这个框架下,用户可以无缝地获得跨AZ部署高可用应用的容灾能力。
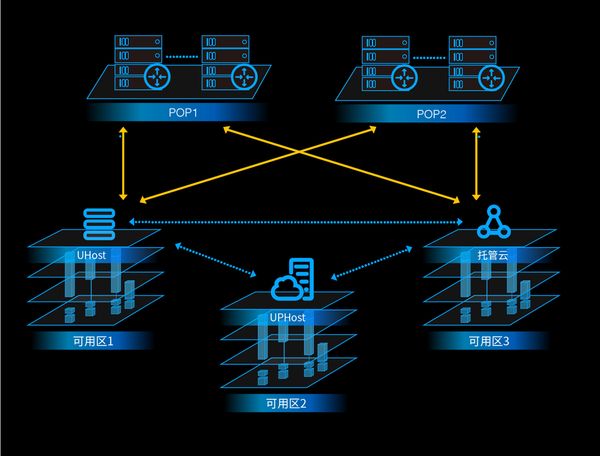
对于物理云和托管云来说,情况略有不同,因为它们有各自的网关来处理业务逻辑,但这和跨AZ互通无关,在本机房访问物理云或托管云,也是需要经过它们各自的业务逻辑的网关的。只是在可用区逻辑下,我们大力整合了对各种不同类型网元间互访的支持,使得同一个Region下,不同类型网元的互访成为默认支持的模式而无需进过特别的协调或非标操作:
支持虚拟网络广播协议带来的架构变化(广播协议在可用区中的实现)
上文提到,利用可用区的特性,用户虚拟网络“大二层”的范围事实上已经扩展到整个Region所有的AZ里了。由此带来的特性能力之前已经有了诸多阐述,但同时,也有很多基础架构层面上的挑战随之而来。在这里我们着重对于在虚拟网络中支持广播协议这一场景做一些深入的探究。
众多的公有云平台在其虚拟网络中是不支持广播协议的,包括很多国内的友商和AWS这样的公有云技术的领导者(参见:AWS | Amazon Virtual Private Cloud (VPC))。UCloud的虚拟网络是支持广播协议的,这里包括二层的和三层广播报文,如下图所示:
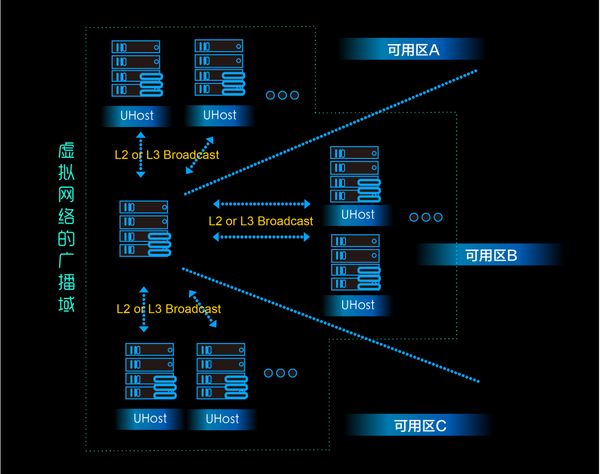
在可用区的场景下,理论上用户的子网中的主机已经不局限于某一个AZ,而是可以跨多个AZ,亦即用户的广播域事实上从一个AZ扩展到整个Region,那我们在面对支持广播协议的问题时立刻会面临以下的挑战:
对广播协议的支持是有很大的开销的,这里的开销包括两部分:
1.虚拟网络的后台管理面的服务在underlay网络中需要创建、查询、修改或删除的信息;
2.虚拟网络数据转发面上的vSwitch所需要处理的overlay网络中的报文数量。而随着广播域从一个AZ扩展到一个Region, 我们面临的问题的复杂度在现有架构中也从AZ级别的数量级提高到了Region级别的数量级。
在现有架构中,虚拟网络后台管理面的服务在子网中某个节点发起首次广播通信的时候需要完成大量的初始化工作。现实中,这样的情况并不罕见,比如说用户新建了一台云主机,然后从这台云主机发起一次广播通信,后台服务所要承担的压力是随着广播域的扩大而线性增加的。而在数据转发面上,任意节点上的vSwitch对每个广播报文也必须完成O(n)量级的处理工作。换句话说,从全局来看,支持一个子网中全量的广播协议,我们面临的问题的总体复杂度是O(n2):
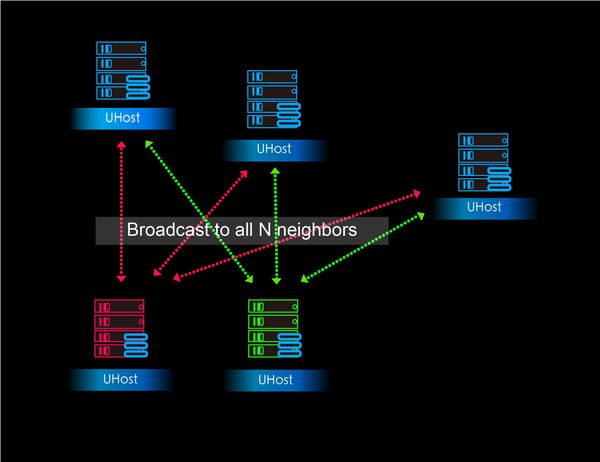
如此,当广播域增加到一定体量的时候,我们就会遇上无法避免的性能瓶颈。如果说对于无状态的后台管理面服务,我们还可以通过水平扩容来地解决一定问题的话,那对于单个节点上数据转发面的核心vSwitch来说,一旦触碰到某个之前未知的性能限制时,我们很可能将束手无策。在实际应用中,我们发现UCloud平台上某些较大的用户的广播域已经达到了600+的数量,而此时从我们用户提供的反馈来看,底层架构的瓶颈确实已经对他们的实际使用造成了可感知的影响。
为了解决这个问题,我们重新设计了以下架构来支持虚拟网络中的广播协议:

这里,我们通过一组独立的服务集群(以下简称“广播集群”)专门来处理广播报文。Overlay中的所有广播报文都会通过特定的SDN规则送到这个集群上经过处理后再转发。可以看到,在这个新架构下,广播域的变化给管理面和数据转发面带来的新增负担是一个常量(亦即:只需要负担新增节点的那部分开销就可以了,现存节点不会增加额外开销),或者说,之前的O(n2)复杂度的问题现在就降级为O(n)的问题了。
另外大家可以看到,虽然在可用区特性的开发过程中“广播集群”主要被用来处理广播报文,但我们可以很容易地对这个服务的功能做一些扩展以支持新的协议,比如广义上的BUM(Broadcast, Unknown unicast, Multicast)报文,而不需要对整体SDN后台的架构做大的变动。
SDN封装隧道与流表的优化
关于可用区中底层SDN架构改造的最后一个话题是我们对于overlay协议中使用的隧道(tunnel)和流表(flow table)的优化。为了理解这里面临的问题,我们首先来看一下可用区特性之前的Overlay协议的实现,以虚拟网络中两个节点间的单播通信为例:

Overlay中隧道的定义如下:

对应的单播flow则是:
可以看出,所有underlay中封装(encapsulation)所需要的信息都是包含在tunnel的定义中的,而flow只是包含overlay中虚拟网络的信息(除了GRE key)。
这样的做法好处就在于它很直观并容易理解,然而,这里最大的潜在麻烦在于所有任意两点间的封装信息都必须记录在案以备查询,也就是说假设虚拟网络的数量级是n, 那么保证任意两点间单播通信的问题的总体复杂度就是O(n2),这点从后台数据库中存储这些信息所需要占用的空间来看就很容易理解:

对于一个大小为n的虚拟网络来说,我们需要O(n2)条记录来存储所有相关的tunnel信息。当虚拟网络的允许范围从一个AZ扩大到整个Region的时候,n2的增量是很可怕的。
那么我们如何来解决这个问题呢?我们重新设计了overlay协议中tunnel和flow的定义:

对应的单播flow是:
我们将原本存在于tunnel定义内的封装信息全部移到了flow中,并且由于flow作用在本地的网卡上,因此源端的tunnel地址就无需再显式地定义了,只需要定义对端的tunnel地址。而对端在接收到这样一个封装后的数据报文时,也完全可以通过tunnel的目标地址和GRE key来解封装(decapsulation)。这样的设计,完全免除了原来对O(n2)的tunnel信息的增删改查操作,所有的信息完全包含在点对点的flow中了。
结语
在本篇技术分享中,我们着重介绍了为了支持可用区特性所做的一系列底层SDN网络架构的改造:
1.不同类型公有云网元间的互访
2.广播协议的处理
3.SDN隧道和流表的优化
这些底层架构的改动和演进也许对于用户而言来说大多数时间都是不可见的,但这其中要付出的努力以及敢于推翻和重构已有架构的魄力,所面临的挑战的难度其实丝毫不亚于提供那些用户直观可见的功能。有些工作我们根据已知的用户反馈知道那是我们必须立刻解决的,而有些工作则更多的是一种前瞻性的设计,因为结合我们之前积累的经验以及现网数据累积的趋势来看,我们可以比较有把握的推断出架构上的不合理性在哪个程度会给整个平台的可靠性和可用性带来可感知的影响,对于这类问题,我们也必须有魄力去未雨绸缪地进行解决。
在下一篇连载中,我们将讨论我们是如何运营和发布可用区这个特性的。实现一个生产环境下的大型分布式系统,如果面对的问题数量级很小,通常很多矛盾都不会暴露出来。如果所有的新功能都能重起炉灶,同样的,一切都会显得很简单美好。但真正的困难往往就是在运营海量数据和保证现网服务不回归这两个前提下才会集中爆发出来,而在这两个前提条件下稳定地迭代新的特性和功能,就犹如是给高速飞驰中的跑车更换引擎,是对一个系统和它背后的研发运营团队的真正挑战。
相关推荐阅读:
解密「云计算的太祖长拳」系列之一“胆”:基础网络改造与新架构
从Google Maglev说起,如何造一个牛逼的负载均衡?
本文由『UCloud基础云计算研发团队』提供。
关于作者:
Y3(俞圆圆),UCloud基础云计算研发中心总监,负责超大规模的虚拟网络及下一代NFV产品的架构设计和研发。在大规模、企业级分布式系统、面向服务架构、TCP/IP协议栈、数据中心网络、云计算平台的研发方面积累了大量的实战经验。曾经分别供职于Microsoft Windows Azure和Amazon AWS EC2,历任研发工程师,高级研发主管,首席软件开发经理,组建和带领过实战能力极强的研发团队。
「UCloud机构号」将独家分享云计算领域的技术洞见、行业资讯以及一切你想知道的相关讯息。
欢迎提问&求关注 o(*////▽////*)q~
以上。