前言
本系列为机器学习算法的总结和归纳,目的为了清晰阐述算法原理,同时附带上手代码实例,便于理解。
目录
k近邻(KNN)
决策树
线性回归
逻辑斯蒂回归
朴素贝叶斯
支持向量机(SVM)
组合算法(Ensemble Method)
K-Means
机器学习算法总结
本章为决策树算法,内容包括基本模型介绍,以及包括ID3、C4.5和CART树不同树模型的介绍。同时包括python3下的代码实战,代码实现包括自我实现和基于sklearn的算法,实战案例有...(参考《机器学习实战》)。
一、算法简介
1.1 基本模型介绍
决策树是一类常见的机器学习方法,可以帮助我们解决分类与回归两类问题。模型可解释性强,模型符合人类思维方式,是经典的树形结构。分类决策数模型是一种描述对实例进行分类的树形结构。决策树由结点 (node) 和有向边 (directed edge) 组成。结点包含了一个根结点 (root node)、若干个内部结点 (internal node) 和若干个叶结点 (leaf node)。内部结点表示一个特征或属性,叶结点表示一个类别。
简单而言,决策树是一个多层if-else函数,对对象属性进行多层if-else判断,获取目标属性的类别。由于只使用if-else对特征属性进行判断,所以一般特征属性为离散值,即使为连续值也会先进行区间离散化,如可以采用二分法(bi-partition)。
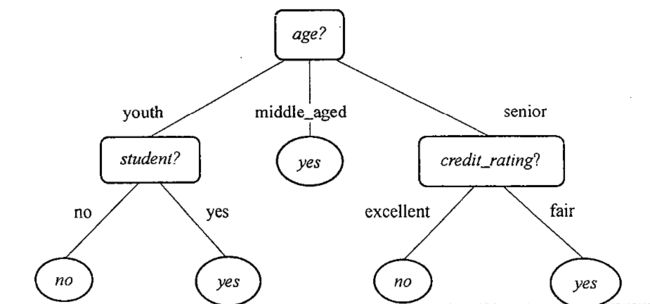
思考:选哪些特征属性参与决策树建模、哪些属性排在决策树的顶部,哪些排在底部,对属性的值该进行什么样的判断、样本属性的值缺失怎么办、如果输出不是分类而是数值能用么、对决策没有用或没有多大帮助的属性怎么办、什么时候使用决策树?
1.2 决策树特点
· 决策树优点
1)决策树易于理解和实现,人们在在学习过程中不需要使用者了解很多的背景知识,这同时是它的能够直接体现数据的特点,只要通过解释后都有能力去理解决策树所表达的意义。
2)对于决策树,数据的准备往往是简单或者是不必要的,而且能够同时处理数据型和常规型属性,在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
3)易于通过静态测试来对模型进行评测,可以测定模型可信度;如果给定一个观察的模型,那么根据所产生的决策树很容易推出相应的逻辑表达式。
· 决策树缺点
1)对连续性的字段比较难预测。
2)对有时间顺序的数据,需要很多预处理的工作。
3)当类别太多时,错误可能就会增加的比较快。
4)一般的算法分类的时候,只是根据一个字段来分类。
二、算法分类和流程
2.1 算法分类
现有的关于决策树学习的主要思想主要包含以下 3 个研究成果:
由 Quinlan 在 1986 年提出的 ID3 算法
由 Quinlan 在 1993 年提出的 C4.5 算法
由 Breiman 等人在 1984 年提出的 CART 算法
算法比较

2.2 算法流程- 划分选择
决策树学习通常包括 3 个步骤:特征选择、决策树的生成、决策树的修剪。最为关键的就是如何选择最优划分属性。一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的 “纯度” (purity) 越来越高。
2.2.1 信息增益(information gain)
信息增益表示得知特征Xj的信息而使所属分类的不确定性减少的程度。
特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定的情况下D的经验条件熵H(D|A)之差。
假设数据集D有K种分类,特征A有n种取值可能。其中数据集D的经验熵H(D)为
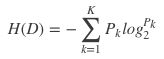
其中P
k为集合D中的任一样本数据分类k的概率,或者说属于分类k的样本所占的比例。
经验条件熵H(D|A)为

也可记作
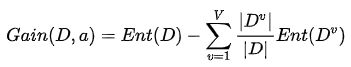
其中P
i为特征取值为第i个可取值的概率。D
i为特征A为第i个可取值的样本集合。
一般而言,信息增益越大,则意味着使用属性A来进行划分所获得的 "纯度提升" 越大。因此,我们可以用信息增益来进行决策树的划分属性选择。著名的
ID3 决策树学习算法就是以信息增益为准则来选择划分属性。
2.2.2 信息增益比(information gain ratio)
特征A对训练数据集D的信息增益gR(D,A),定义为其信息增益g(D,A)与训练集D的经验熵H(D)之比。
是为了矫正在训练数据集的经验熵大时,信息增益值会偏大,反之,信息增益值会偏小的问题。即特征选择使用了一个启发式策略:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
C4.5算法是使用该方式来划分属性。
2.2.3 基尼指数(Gini index)
ID3还是C4.5都是基于信息论的熵模型的,这里面会涉及大量的对数运算,为了简化模型同时也完全丢失熵模型的优点,在CART算法中使用基尼系数来代替信息增益比,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。这和信息增益(比)是相反的。通过子集计算基尼不纯度,即随机放置的数据项出现于错误分类中的概率。以此来评判属性对分类的重要程度。

其中p
k为任一样本点属于第k类的概率,也可以说成样本数据集中属于k类的样本的比例。
集合D的基尼指数为Gini(D),在特征A条件下的集合D的基尼指数为

其中 |D
i|为特征A取第i个值时对应的样本个数。|D|为总样本个数
CART算法中对于分类树采用的是上述的基尼指数最小化准则。对于回归树,CART采用的是平方误差最小化准则。
2.3 剪枝
剪枝 (pruning) 是决策树学习算法对付 “过拟合” 的主要手段。在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因针对训练样本学得 “太好” 了,以至于把训练集自身的一些特点当作所有数据都具有的一般性质而导致过拟合。因此,可通过主动去掉一些分支来降低过拟合的风险。
决策树剪枝的基本策略有 “预剪枝” (prepruning) 和 “后剪枝” (postpruning)。
· 预剪枝 是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前节点的划分不能带来决策树泛化性能的提升,则停止划分并将当前结点标记为叶结点;
· 后剪枝 则是先从训练集生成一颗完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点的子树替换为叶结点能带来决策树泛化性能的提升,则将该子树替换为叶结点。
四、案例
本篇文章将在基本概念基础上,以实际案例熟悉决策树构建、可视化和分类预测等。
决策树算法训练流程主要包括:收集数据- 准备数据- 分析数据- 训练算法- 测试算法
4.1 基于python3的代码实现
基于ID3算法,实现预测贷款用户是否具有偿还贷款的能力
1)创建数据集


""" 函数说明:创建测试数据集 Parameters: 无 Returns: dataSet - 数据集 labels - 特征标签 """ def createDataSet(): dataSet = [[0, 0, 0, 0, 'no'], #数据集 [0, 0, 0, 1, 'no'], [0, 1, 0, 1, 'yes'], [0, 1, 1, 0, 'yes'], [0, 0, 0, 0, 'no'], [1, 0, 0, 0, 'no'], [1, 0, 0, 1, 'no'], [1, 1, 1, 1, 'yes'], [1, 0, 1, 2, 'yes'], [1, 0, 1, 2, 'yes'], [2, 0, 1, 2, 'yes'], [2, 0, 1, 1, 'yes'], [2, 1, 0, 1, 'yes'], [2, 1, 0, 2, 'yes'], [2, 0, 0, 0, 'no']] labels = ['年龄', '有工作', '有自己的房子', '信贷情况'] #特征标签 return dataSet, labels #返回数据集和分类属性
2)划分数据集
""" 函数说明:按照给定特征划分数据集 Parameters: dataSet - 待划分的数据集 axis - 划分数据集的特征 value - 需要返回的特征的值 Returns: 无 """ def splitDataSet(dataSet, axis, value): retDataSet = [] #创建返回的数据集列表 for featVec in dataSet: #遍历数据集 if featVec[axis] == value: reducedFeatVec = featVec[:axis] #去掉axis特征 reducedFeatVec.extend(featVec[axis+1:]) #将符合条件的添加到返回的数据集 retDataSet.append(reducedFeatVec) return retDataSet #返回划分后的数据集
3)计算香侬熵
""" 函数说明:计算给定数据集的经验熵(香农熵) Parameters: dataSet - 数据集 Returns: shannonEnt - 经验熵(香农熵) """ def calcShannonEnt(dataSet): numEntires = len(dataSet) #返回数据集的行数 labelCounts = {} #保存每个标签(Label)出现次数的字典 for featVec in dataSet: #对每组特征向量进行统计 currentLabel = featVec[-1] #提取标签(Label)信息 if currentLabel not in labelCounts.keys(): #如果标签(Label)没有放入统计次数的字典,添加进去 labelCounts[currentLabel] = 0 labelCounts[currentLabel] += 1 #Label计数 shannonEnt = 0.0 #经验熵(香农熵) for key in labelCounts: #计算香农熵 prob = float(labelCounts[key]) / numEntires #选择该标签(Label)的概率 shannonEnt -= prob * log(prob, 2) #利用公式计算 return shannonEnt #返回经验熵(香农熵)
4)选择最优特征
""" 函数说明:选择最优特征 Parameters: dataSet - 数据集 Returns: bestFeature - 信息增益最大的(最优)特征的索引值 """ def chooseBestFeatureToSplit(dataSet): numFeatures = len(dataSet[0]) - 1 #特征数量 baseEntropy = calcShannonEnt(dataSet) #计算数据集的香农熵 bestInfoGain = 0.0 #信息增益 bestFeature = -1 #最优特征的索引值 for i in range(numFeatures): #遍历所有特征 #获取dataSet的第i个所有特征 featList = [example[i] for example in dataSet] uniqueVals = set(featList) #创建set集合{},元素不可重复 newEntropy = 0.0 #经验条件熵 for value in uniqueVals: #计算信息增益 subDataSet = splitDataSet(dataSet, i, value) #subDataSet划分后的子集 prob = len(subDataSet) / float(len(dataSet)) #计算子集的概率 newEntropy += prob * calcShannonEnt(subDataSet) #根据公式计算经验条件熵 infoGain = baseEntropy - newEntropy #信息增益 # print("第%d个特征的增益为%.3f" % (i, infoGain)) #打印每个特征的信息增益 if (infoGain > bestInfoGain): #计算信息增益 bestInfoGain = infoGain #更新信息增益,找到最大的信息增益 bestFeature = i #记录信息增益最大的特征的索引值 return bestFeature
5)统计类标签
""" 函数说明:统计classList中出现此处最多的元素(类标签) Parameters: classList - 类标签列表 Returns: sortedClassCount[0][0] - 出现此处最多的元素(类标签) """ def majorityCnt(classList): classCount = {} for vote in classList: #统计classList中每个元素出现的次数 if vote not in classCount.keys():classCount[vote] = 0 classCount[vote] += 1 sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True) #根据字典的值降序排序 return sortedClassCount[0][0] #返回classList中出现次数最多的元素 """
6)创建决策树
""" 函数说明:创建决策树 Parameters: dataSet - 训练数据集 labels - 分类属性标签 featLabels - 存储选择的最优特征标签 Returns: myTree - 决策树 """ def createTree(dataSet, labels, featLabels): classList = [example[-1] for example in dataSet] #取分类标签(是否放贷:yes or no) if classList.count(classList[0]) == len(classList): #如果类别完全相同则停止继续划分 return classList[0] if len(dataSet[0]) == 1: #遍历完所有特征时返回出现次数最多的类标签 return majorityCnt(classList) bestFeat = chooseBestFeatureToSplit(dataSet) #选择最优特征 bestFeatLabel = labels[bestFeat] #最优特征的标签 featLabels.append(bestFeatLabel) myTree = {bestFeatLabel:{}} #根据最优特征的标签生成树 del(labels[bestFeat]) #删除已经使用特征标签 featValues = [example[bestFeat] for example in dataSet] #得到训练集中所有最优特征的属性值 uniqueVals = set(featValues) #去掉重复的属性值 for value in uniqueVals: #遍历特征,创建决策树。 myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), labels, featLabels) return myTree
递归创建决策树时,递归有两个终止条件:第一个停止条件是所有的类标签完全相同,则直接返回该类标签;第二个停止条件是使用完了所有特征,仍然不能将数据划分仅包含唯一类别的分组,即决策树构建失败,特征不够用。此时说明数据纬度不够,由于第二个停止条件无法简单地返回唯一的类标签,这里挑选出现数量最多的类别作为返回值。
7)树的可视化
""" 函数说明:获取决策树叶子结点的数目 Parameters: myTree - 决策树 Returns: numLeafs - 决策树的叶子结点的数目 """ def getNumLeafs(myTree): numLeafs = 0 #初始化叶子 firstStr = next(iter(myTree)) #python3中myTree.keys()返回的是dict_keys,不在是list,所以不能使用myTree.keys()[0]的方法获取结点属性,可以使用list(myTree.keys())[0] secondDict = myTree[firstStr] #获取下一组字典 for key in secondDict.keys(): if type(secondDict[key]).__name__=='dict': #测试该结点是否为字典,如果不是字典,代表此结点为叶子结点 numLeafs += getNumLeafs(secondDict[key]) else: numLeafs +=1 return numLeafs """ 函数说明:获取决策树的层数 Parameters: myTree - 决策树 Returns: maxDepth - 决策树的层数 """ def getTreeDepth(myTree): maxDepth = 0 #初始化决策树深度 firstStr = next(iter(myTree)) #python3中myTree.keys()返回的是dict_keys,不在是list,所以不能使用myTree.keys()[0]的方法获取结点属性,可以使用list(myTree.keys())[0] secondDict = myTree[firstStr] #获取下一个字典 for key in secondDict.keys(): if type(secondDict[key]).__name__=='dict': #测试该结点是否为字典,如果不是字典,代表此结点为叶子结点 thisDepth = 1 + getTreeDepth(secondDict[key]) else: thisDepth = 1 if thisDepth > maxDepth: maxDepth = thisDepth #更新层数 return maxDepth """ 函数说明:绘制结点 Parameters: nodeTxt - 结点名 centerPt - 文本位置 parentPt - 标注的箭头位置 nodeType - 结点格式 Returns: 无 """ def plotNode(nodeTxt, centerPt, parentPt, nodeType): arrow_args = dict(arrowstyle="<-") #定义箭头格式 font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14) #设置中文字体 createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction', #绘制结点 xytext=centerPt, textcoords='axes fraction', va="center", ha="center", bbox=nodeType, arrowprops=arrow_args, FontProperties=font) """ 函数说明:标注有向边属性值 Parameters: cntrPt、parentPt - 用于计算标注位置 txtString - 标注的内容 Returns: 无 """ def plotMidText(cntrPt, parentPt, txtString): xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0] #计算标注位置 yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1] createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30) """ 函数说明:绘制决策树 Parameters: myTree - 决策树(字典) parentPt - 标注的内容 nodeTxt - 结点名 Returns: 无 """ def plotTree(myTree, parentPt, nodeTxt): decisionNode = dict(boxstyle="sawtooth", fc="0.8") #设置结点格式 leafNode = dict(boxstyle="round4", fc="0.8") #设置叶结点格式 numLeafs = getNumLeafs(myTree) #获取决策树叶结点数目,决定了树的宽度 depth = getTreeDepth(myTree) #获取决策树层数 firstStr = next(iter(myTree)) #下个字典 cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff) #中心位置 plotMidText(cntrPt, parentPt, nodeTxt) #标注有向边属性值 plotNode(firstStr, cntrPt, parentPt, decisionNode) #绘制结点 secondDict = myTree[firstStr] #下一个字典,也就是继续绘制子结点 plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD #y偏移 for key in secondDict.keys(): if type(secondDict[key]).__name__=='dict': #测试该结点是否为字典,如果不是字典,代表此结点为叶子结点 plotTree(secondDict[key],cntrPt,str(key)) #不是叶结点,递归调用继续绘制 else: #如果是叶结点,绘制叶结点,并标注有向边属性值 plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode) plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key)) plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD """ 函数说明:创建绘制面板 Parameters: inTree - 决策树(字典) Returns: 无 """ def createPlot(inTree): fig = plt.figure(1, facecolor='white') #创建fig fig.clf() #清空fig axprops = dict(xticks=[], yticks=[]) createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #去掉x、y轴 plotTree.totalW = float(getNumLeafs(inTree)) #获取决策树叶结点数目 plotTree.totalD = float(getTreeDepth(inTree)) #获取决策树层数 plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0; #x偏移 plotTree(inTree, (0.5,1.0), '') #绘制决策树 plt.show() #显示绘制结果
8)执行决策树
依靠训练数据构造好决策树之后可以用于实际数据分类。
""" 函数说明:使用决策树分类 Parameters: inputTree - 已经生成的决策树 featLabels - 存储选择的最优特征标签 testVec - 测试数据列表,顺序对应最优特征标签 Returns: classLabel - 分类结果 """ def classify(inputTree, featLabels, testVec): firstStr = next(iter(inputTree)) #获取决策树结点 secondDict = inputTree[firstStr] #下一个字典 featIndex = featLabels.index(firstStr) for key in secondDict.keys(): if testVec[featIndex] == key: if type(secondDict[key]).__name__ == 'dict': classLabel = classify(secondDict[key], featLabels, testVec) else: classLabel = secondDict[key] return classLabel
9)决策树存储
可以调用python模块中的pickle序列化对象,这样能够在每次执行时调用已经构造好的决策树
""" 函数说明:存储决策树 Parameters: inputTree - 已经生成的决策树 filename - 决策树的存储文件名 Returns: 无 """ def storeTree(inputTree, filename): with open(filename, 'wb') as fw: pickle.dump(inputTree, fw)
4.2 基于sklearn的代码实现
同样,python的sklearn库也提供了决策树的模型-DecisionTreeClassifier,可以直接调用,使用方便。具体介绍参见 官方文档
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)
参数介绍:
· criterion: 特征选择标准,默认值为‘gini’,即CART算法。(entropy, gini)
· splitter: 特征划分标准,默认值为‘best’。(best, random) best在特征的所有划分点中找出最优的划分点,random随机的在部分划分点中找局部最优的划分点。默认的‘best’适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐‘random’。
· max_depth: 决策树最大深度。默认值是‘None’。(int, None)常用的可以取值10-100之间,常用来解决过拟合。
· min_samples_split: 内部节点再划分所需最小样本数。默认值为2。(int, float)
· min_samples_leaf: 叶子节点最少样本数。
· min_weight_fraction_leaf: 叶子节点最小的样本权重和。默认为0。(float)
· max_features: 在划分数据集时考虑的最多的特征值数量。
· random_state: 默认是None(int, randomSate instance, None)
· max_leaf_nodes: 最大叶子节点数。默认为None。(int, None)通过设置最大叶子节点数,可以防止过拟合。
· min_impurity_decrease: 节点划分最小不纯度。默认值为‘0’。(float,)
· min_impurity_split: 信息增益的阀值。
· class_weight: 类别权重。默认为None,(dict, list of dicts, balanced)
· presort: bool,默认是False,表示在进行拟合之前,是否预分数据来加快树的构建。
实例:项目采用用决策树预测隐形眼镜类型,数据集下载地址:
https://github.com/Jack-Cherish/Machine-Learning/blob/master/Decision%20Tree/classifierStorage.txt
模型构建之后可以使用Graphviz可视化树,pydotplus和Grphviz。确定好决策树后可以进行预测。项目代码如下:
# -*- coding: UTF-8 -*- from sklearn.preprocessing import LabelEncoder, OneHotEncoder from sklearn.externals.six import StringIO from sklearn import tree import pandas as pd import numpy as np import pydotplus if __name__ == '__main__': with open('lenses.txt', 'r') as fr: #加载文件 lenses = [inst.strip().split('\t') for inst in fr.readlines()] #处理文件 lenses_target = [] #提取每组数据的类别,保存在列表里 for each in lenses: lenses_target.append(each[-1]) print(lenses_target) lensesLabels = ['age', 'prescript', 'astigmatic', 'tearRate'] #特征标签 lenses_list = [] #保存lenses数据的临时列表 lenses_dict = {} #保存lenses数据的字典,用于生成pandas for each_label in lensesLabels: #提取信息,生成字典 for each in lenses: lenses_list.append(each[lensesLabels.index(each_label)]) lenses_dict[each_label] = lenses_list lenses_list = [] # print(lenses_dict) #打印字典信息 lenses_pd = pd.DataFrame(lenses_dict) #生成pandas.DataFrame # print(lenses_pd) #打印pandas.DataFrame le = LabelEncoder() #创建LabelEncoder()对象,用于序列化 for col in lenses_pd.columns: #序列化 lenses_pd[col] = le.fit_transform(lenses_pd[col]) # print(lenses_pd) #打印编码信息 clf = tree.DecisionTreeClassifier(max_depth = 4) #创建DecisionTreeClassifier()类 clf = clf.fit(lenses_pd.values.tolist(), lenses_target) #使用数据,构建决策树 dot_data = StringIO() tree.export_graphviz(clf, out_file = dot_data, #绘制决策树 feature_names = lenses_pd.keys(), class_names = clf.classes_, filled=True, rounded=True, special_characters=True) graph = pydotplus.graph_from_dot_data(dot_data.getvalue()) graph.write_pdf("tree.pdf") #保存绘制好的决策树,以PDF的形式存储。
参考:
https://blog.csdn.net/luanpeng825485697/article/details/78796773
http://cuijiahua.com/blog/2017/11/ml_1_knn.html
https://zhuanlan.zhihu.com/p/36542665