语音对话系统的技术突破点在哪?深度解读人机交互的技术核心
雷锋网按:本文来源公众号“极限元”,作者温正棋,极限元技术副总裁、中国科学院自动化研究所副研究员,中科院—极限元“智能交互联合实验室”主任。雷锋网(公众号:雷锋网)授权转载。
语音作为互联网的一种入口方式,正在侵入我们的生活,人机交互的核心——对话系统,对交互的应用至关重要,人脑与机器智能的结合,能够突破现有技术瓶颈吗?这里就有必要重点介绍下人机交互相关的核心技术。
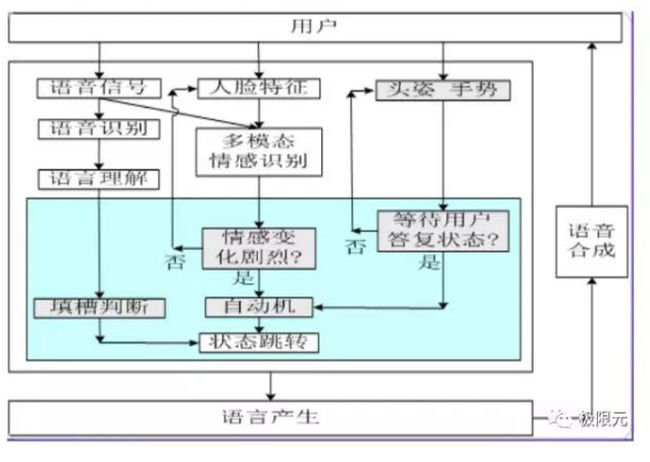
从整个交互系统接入用户的输入信息开始,包括语音、人脸、多模态情感相关的信息,我们在对话系统里面对输入的信息进行理解,通过这个对话部分以后产生输出,最后用文字也可以用语音合成展现出来,这就是整个流程,其中我们关注的最主要的是语音部分以及对话系统部分,其他的多模态今天的分享不会涉及太多。
国内研究语音相关的团队主要包括科研院所、语音技术公司以及互联网公司三部分:
-
科研院所主要包括高校和科学院,比如科学院里有声学所、自动化所,高校里面研究比较多的清华、北大、西工大、科大、上海交大等,这些都是在语音圈里占有较高位置的老牌队伍。
-
语音技术公司包括我们比较熟悉的科大讯飞、云知声、思必驰、极限元等。
-
互联网公司包括BAT、搜狗等拥有强大的语音技术团队来支撑着其本身的很多业务。
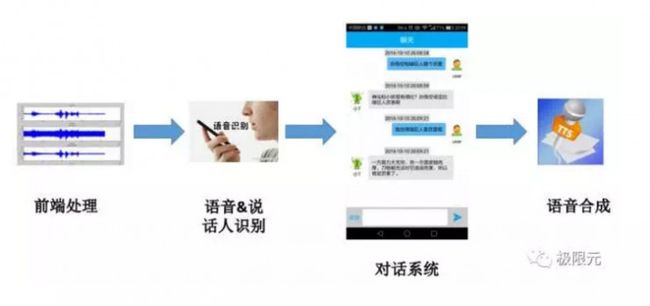
在应用对话系统时,首先从语音输入开始要有一些前端处理,包括硬件和软件的前期处理;接下来是语音内容,说话人识别等相关的内容进行判别,对话系统根据输入信息来进行对话逻辑的分析,以及对应语言的产生,最后由语音合成系统来合成语音,在这里重点介绍一下前端处理、语音识别、说话人识别语音合成等相关技术。
前端处理技术的研究进展
前端处理包括回升消除、噪声抑制、混响抑制等技术,刚开始时研究前端处理的人员并不多。近年来特别是ECHO的推出,把一些远场的问题融入到语音识别等系统中,所以这部分的研究在这几年兴起比较快。语音识别的研究从一些简单的数据如手机的录音扩展到远场的语音识别,这些促进了前端处理技术的发展,在语音圈里做前端处理比较牛的应该是陈景东老师。
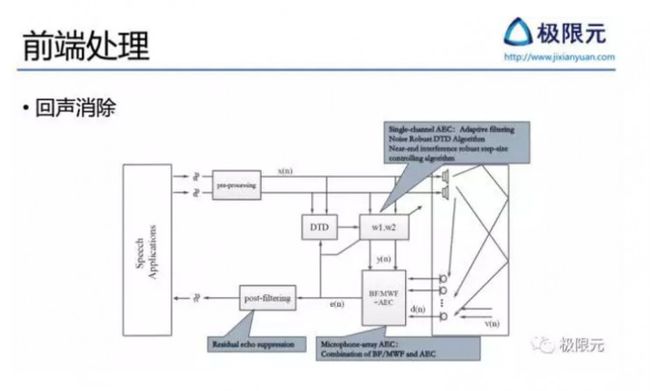
回声消除
回声消除在远场语音识别中是比较典型功能,最典型的应用是在智能终端播放音乐的时候,远场扬声器播放的音乐会回传给近端麦克风,此时就需要有效的回声消除算法来抑制远端信号的干扰,这是在智能设备如音响、智能家居当中都需要考虑的问题。比较复杂的回声消除系统,近端通过麦克风阵列采集信号,远端是双声道扬声器输出,因此近端需要考虑如何将播出形成算法跟回声消除算法对接,远端需要考虑如何对立体声信号相关。
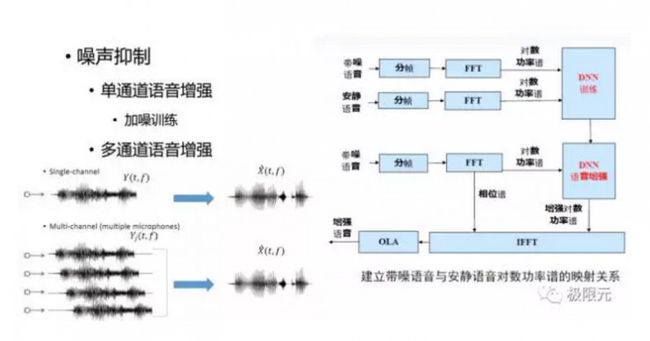
噪声抑制
噪声抑制可以有多通道的也可以有单通道的,今天主要介绍单通道噪声抑制,单通道语音增强通过DNN的方法进行增强,语音信号是有一个谐波结构的,通过加入噪声这个谐波结构会被破坏掉,语音增强的主要目的就是抬高波峰,降低波谷,这个训练对DNN来说是比较容易的。但是也有实验研究表明,基于DNN的语音增强对浊音段效果会比较好,但对轻音段效果并不是很好,语音的浊音段有显著谐波结构,因此要有目的去训练这个模型。
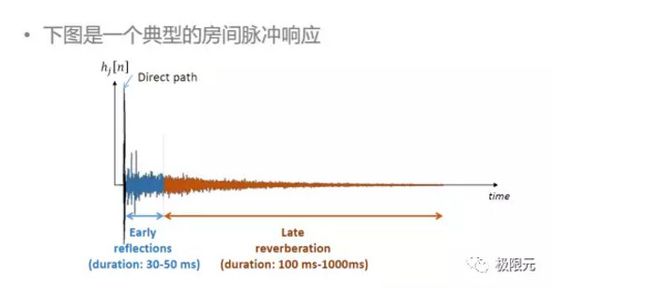
混响抑制
声音在房间传输过程中经过墙壁或者其他障碍物的反射后到达麦克风,从而生成混响语音,混响的语音会受到房间大小、声源麦克风的位置、室内障碍物等因素的影响,大多数的房间内混响时间大概在200--1000毫秒范围内,如果混响时间过短,声音会发干,枯燥无味,不具备清晰感,混响时间过长会使声音含混不清,需要合适的声音才能圆润动听。
前端处理涉及的内容比较多,除了前面提到的还包括多说话人分离、说话人移动过程中的声音采集、不同的麦克风阵列结构、各种噪声和房间模型如何更好的建模等。
音识别技术的研究进展
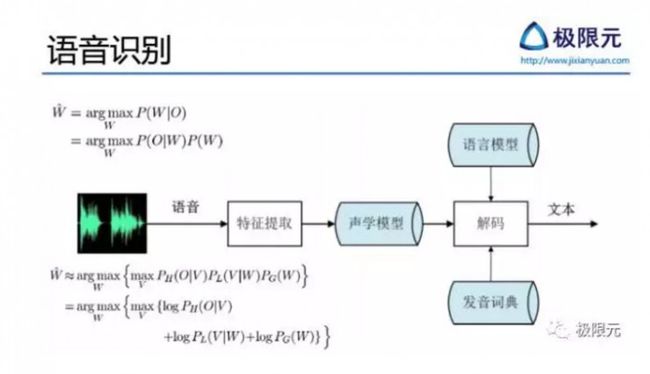
有了前端处理以后,反馈回来的信息会加到训练语音识别模型,语音识别主要是建立一个声学参数到发音单元的映射模型或者叫判别模型,现在的方法从传统的GMM-HMM模型到DNN-HMM混合模型,再到最新的端到端的CTC相关的。语音信号经过特征提取得到声学特征,再通过声学特征训练得到声学模型,声学模型结合语言模型以及发音辞典构建声码器以后,最终识别出文本。

GMM用来对每个状态进行建模,HMM描述每个状态之间的转移概率,这样就构建了一个音素或三因子的HMM模型建模单元,GMM训练速度相对较快,而且GMM声学模型可以做得比较小,可以移植到嵌入式平台上,其缺点是GMM没有利用真的上下文信息,同时GMM不能学习深层的非线性特征变换,建模能力有限。
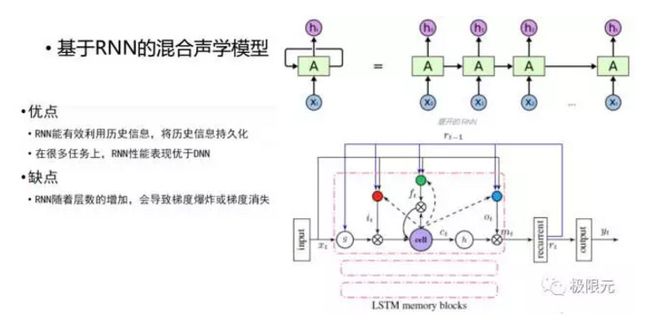
随着深度神经网络的兴起,深度神经网络也应用到了语音识别里面声学建模,主要是替换了GMM-HMM模型里的GMM模型,上端仍然是HMM模型加状态转移,在GMM模型里面可能有500至1万个状态,这个状态可以通过DNN模型预测出每个的概率,输出的就是一个三因子,我们两者结合起来构建基于DNN-HMM的声学模型。

DNN能利用的上下文系统在输入端进行扩帧,同时又非线性变换可以学习到,但DNN不能利用历史信息捕捉当前的任务,因为扩帧是有限的,不可能无限扩下去,所以他输入的历史信息还是有限的。因此,自然而然的有了基于RNN的混合声学模型,将DNN模块替换成RNN模块,RNN能够有效的对历史信息进行建模,并且能够将更多的历史信息保存下来,可于将来的预测。但是在RNN训练过程中会存在梯度消失和梯度膨胀的问题,梯度膨胀可以在训练过程中加一些约束来实现,当梯度超过一定值以后设定一个固定值,但是梯度消失很难去把握,因此有很多方法解决这种问题,比较简单的一个方法是将里面的RNN单元变成长短时记忆模型LSTM,这样长短时记忆模型能够将记忆消失问题给很好的解决,但这样会使计算量显著增加,这也是在构建声学模型中需要考虑的问题。
CNN用于声学模型的建模有一个比较老的方法,在DNN的前端加两层的CNN变换,这样只对参数做了一定的非线性变换,变化完以后输入DNN和LSTM里面,但是随着非常深的CNN在图象识别里面成功应用,这些也被运用到了声学模型中,比如说谷歌、微软、IBM均在2016年发表成果证明非常深的CNN模型已经超越其他深度神经网络的模型,其词错率是最低的。
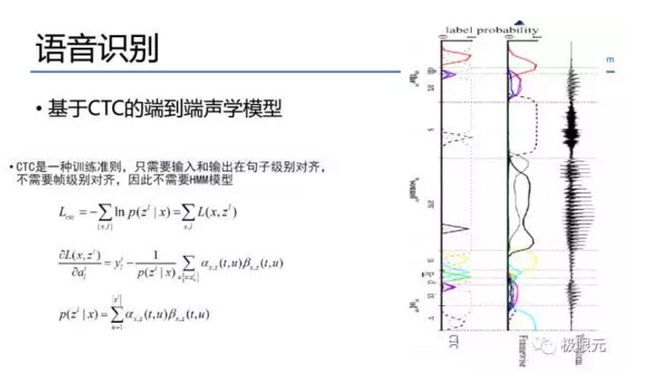
CTC本身是一个训练准则并不算声学模型,在DNN输出中,每个phone他占用的帧数可能有十帧二十帧。因为它不是一个尖峰,但CTC会把它变成一个尖峰,CTC可以将每一帧变成一个senones或者对应一个因数,但每个因数只需几帧就可以了,在解码的时候可以把一些blank帧给去掉,这样可以显著的增加解码速度。减少解码帧有两种方法,一种是通过减帧、跳帧的方法,另一种在解码过程中有一个beam,特别是遇到beam的时候把并值减少,我们的实验结果跳帧会比较好。
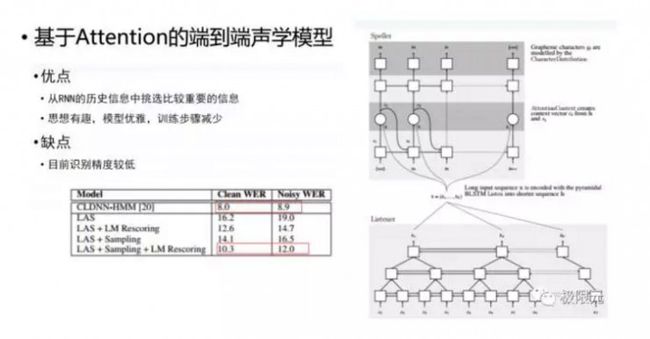
在NLP中应用较多的Attention端对端的声学模型能够从RNN历史信息中挑选出比较重要的信息对词学进行建模,目前的准确率比较低,这应该是一种趋势,至少在NLP中证明了它是比较成功的。
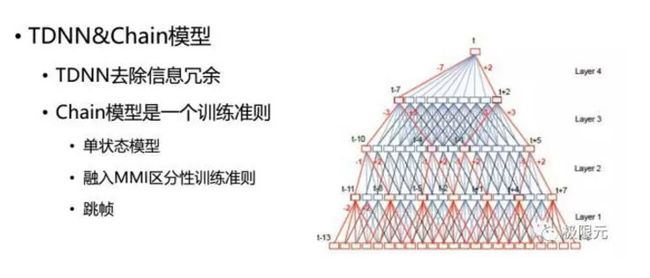
在声学模型中还有TDNN和chain模型,在声学模型中帧及运算过程中会有一些重叠,它有效的去除了信息冗余,嵌入模型也是一个训练准则,采用单状态模型,融入了MMI区分信息链准则,在训练过程中可以实现跳帧,这也加快了解码速度。总结起来现在的语音识别模型更新特别快,最重要的核心内容就是数据,如果数据量足够大的话,做出一个好的结果还是比较容易的,而且我们现在语音识别核心模块主要是在一些解码模块上调优上,这相当于是一种艺术。
语音合成技术的研究进展
语音合成是建立文本参数到声学参数的影射模型,目前的方法有拼接合成、参数合成还有端对端的语音合成。

基于HMM统计参数的语音合成是在训练过程中建立文本参数,如韵律参数、普参数和基频参数的映射模型,通过决策数聚类的方法对每一个上下文相关的文本特征构建GMM模型,训练其GMM模型,在合成时对输入文本预测出它的GMM以后,通过参数生成算法,生成语音参数然后再输出语音。在这个过程中,有三个地方会产生语音音质的下降,第一是决策树的聚类,第二是声码器,第三是参数生成算法,针对这三个问题,我们接下来看看各位研究者提出的解决方法。
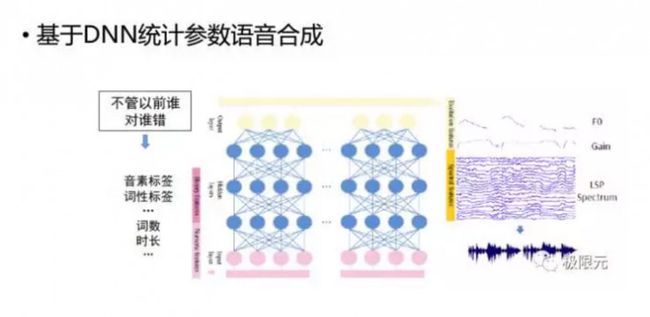
针对决策树聚类的问题,我们可以将里面的HMM决策树据类变成一个DNN模型,文本参数到语音参数的一个映射可以很容易通过DNN来实现,而且在实验效果会比决策树好一点,但是并没有达到我们理想中的那种很惊艳的一些结果。
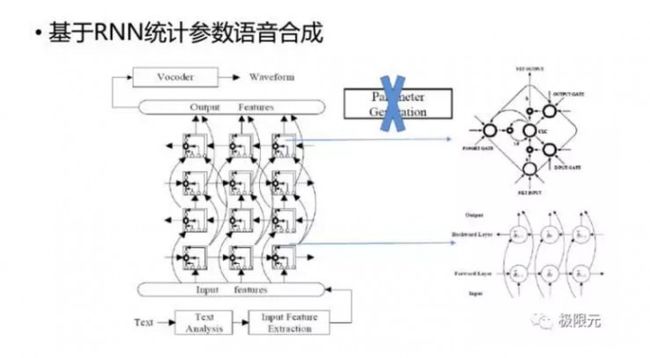
除了DNN,RNN也用到了统计参数语音合成中,而且RNN里面单元采用LSTM模型,我们可以把参数生成算法这个模块从统计参数语音合成中去掉,这样在基于LSTM-RNN中直接预测出语音参数,通过声码器就可以合成语音,跟RNN-LSTM预测出一阶二阶统计量以后,采用参数生成算法,生成语音参数合成语音的话效果差不多,所以RNN-LSTM可以把里面的参数生成算法给去掉。
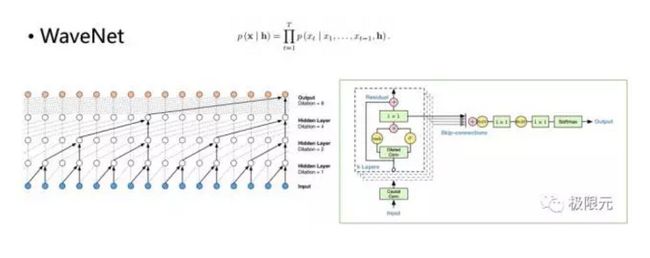
最近几年大家在这方面声码器问题上做了很多工作,比如WaveNet其实也属于声码器的模型,建立一个现今预测的模型,通过前面采样点预测出后面的采样点,但是存在几个问题:比如刚开始速度比较慢,这个问题后期被很多公司都解决了,而且它并不是一个传统的vocoder,需要文本参数作为它的输入。它有好处是在输入过程中,可以很容易的在后端控制说话人的特征,比如不同说话人情感特征这些属于外部特征我们都可以进行很好的加入。
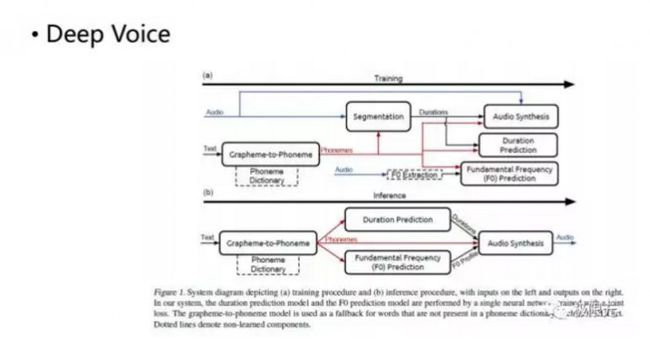
还有一个比较成功的是百度的Deep Voice,它将里面的很多模块用深度神经网络去实现,而且做到了极致,这样我们在最后通过类似WaveNet的合成器来合成,效果也是比较理想的。
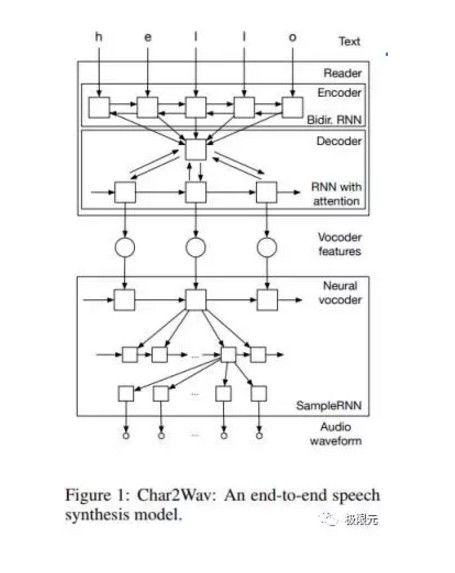
下面两个端对端的语音合成:
第一个是Char2Wav,这个模型是直接对输入的文本他进行编码,采用的模型。对输入的直接对输入的叫字母进行编码,然后生成中间的一个编码信息放到解码器里进行最后的合成,合成采用SimpleRNN的合成器来合成语音,效果也是比较理想的,而且是纯粹的End-To-End的一个语音合成模型。
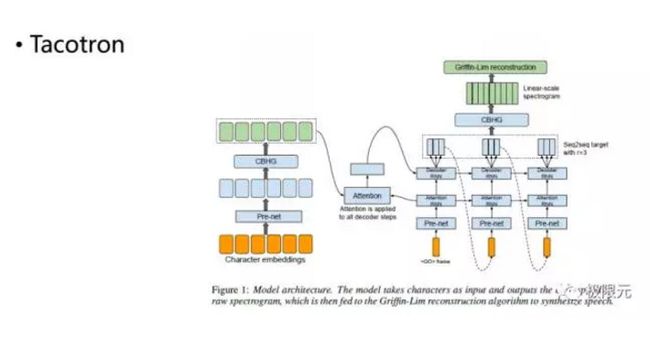
再一个是谷歌提出的端对端的语音合成系统,它跟Char2Wav比较类似,输入的也是Embeddings,合成更加直接比RNN更好。
语音合成前期工作主要放在前端文本分析上,因为我们在听感上可能更关注,但是如果有一些很好的End-to-End的模型出来以后,文本分析的工作并不是很重要,我们也可以在后端中加入一些文本分析的结果进行预测,这即是一种尝试,也是一种很好的办法。现有的合成器的音质不再首先考虑我们采用哪种声码器,我们采用直接生成的方法在实域上直接进行合成。
语音合成更重要的是一些音库,我们不能忽略音库在语音合成中所占据的位置,以及它的重要性。目前,极限元智能科技语音合成定制化支持录音人选型、录音采集、语料标注,还能实现模型迭代训练、合成引擎优化,支持在线、离线模式,适用多种平台

说话人识别也就是声纹识别,简单介绍一下现有的I-vector的系统以及如何将DNN应用到对应的I-vector系统,同时我们也跟踪了最近end to end的一种方法。基于Ivector的系统,通过UBM模型来训练数据,然后训练得到混合高斯模型,通过统计量的提取,比如零阶一阶二阶我们来训练它的差异空间T,从而提取出它的Ivector,最后考虑到不同的补偿方式进行信道补偿,使性能更加完善,同时我们在合成端、最后识别端也可以考虑不同系统的融合提高最终的准确率。
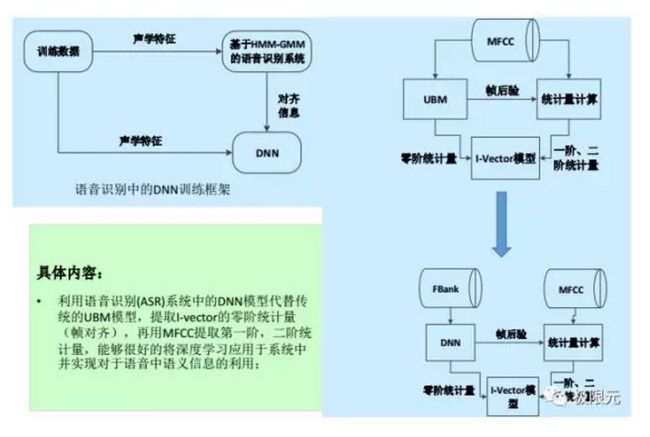
将DNN用到说话人识别,主要是针对Ivector的系统,UBM训练是一个无监督的训练方式。不考虑音速相关的信息,因此就不考虑每个人说话音速在声学空间上法人不同,我们可以将这部分信息运用到说话人识别中,将前面提到的Ivector需要提到的临界统计量,通过DNN模型的输出把临界统计量来进行替换,在训练Ivector的过程中,考虑了每个人音速,发音音速相关的不同特征,这样会更好的对说话人进行识别。
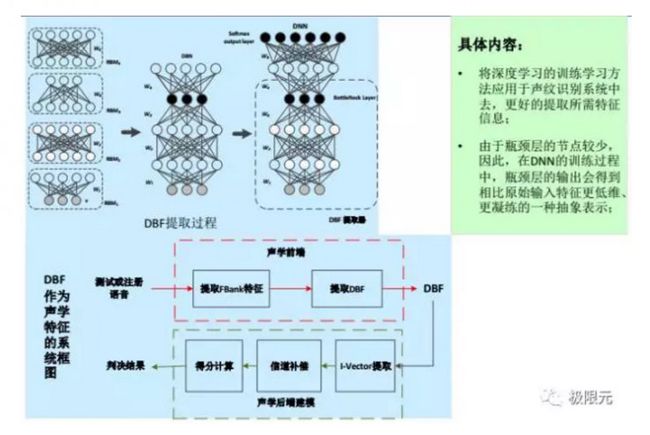
DNN还有一种应用形式,采用bottleneck特征替换掉原来的MFCC,PLP相关的特征,这也是从音速区分性,每个人发音音速不一样来考虑的。
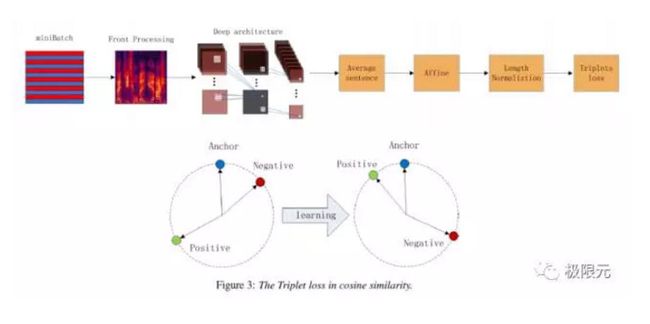
百度前段时间提到的一个Deep Speaker,这部分最主要的优点是采用了Triple Loss这种方法,能很好的用于训练中。原来如果要训练一个说话人可能是输出是一个one-hot,但是speaker的训练语并不是很多,所以训练效果并不是很好,如果我们采用这种训练误差的,可以构建很多对训练参数来进行训练,这样模型会更加棒。
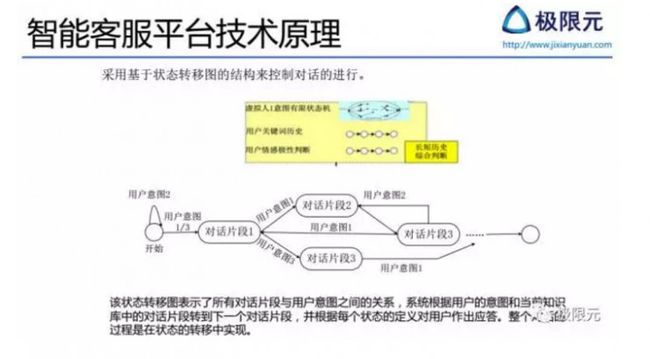
以一个简单的智能客服平台技术原理说明它采用了基于状态转移图的结构来控制对话的进行,在这个状态转移图中,表示了所有对话片断与用户意图之间的关系,系统根据用户的意图和当前知识库中的对话片断转到下一个对话片断,并根据每个状态的定义对用户做出应答,整个对话的过程是在状态转移中实现的。
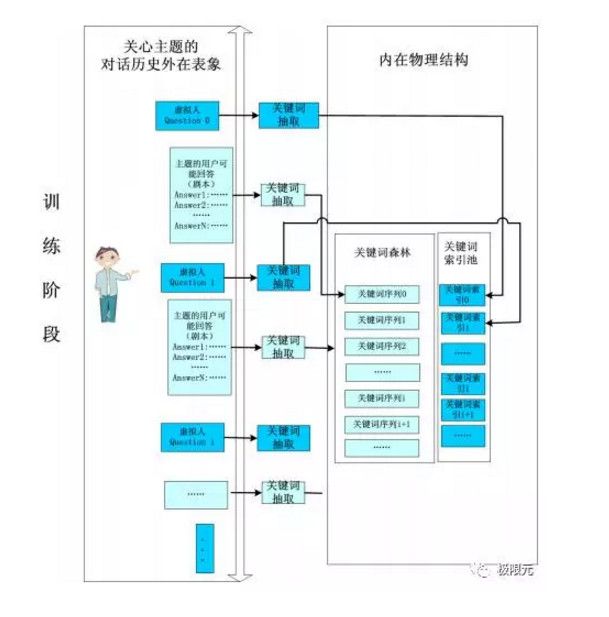
智能客服平台训练阶段主要针对本身已有的系统进行简单的数,包括两个虚拟人,在运行过程中对虚拟人的提问,通过关键词抽取对关键词进行匹配,然后找到对应的它的状态相关的信息,得到最优问题解答再进行返回。
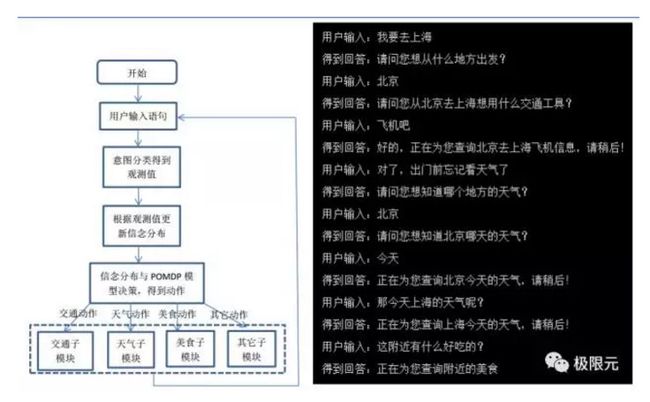
POMDP是一个六元组,包括状态集合、观察集合、行动集合、回报函数、转移函数和观测函数,根据用户输入语句来得到意图分类,然后根据意图分类得到观测值,再通过对立面POMDP里面的训练分布进行更新,训练分布与POMDP结合得到动作,分析各个子动作得到反馈后再接收新的数据。比如我要去上海,它会问你从哪里出发,用什么交通工具,对应一些信息,比如说查天气,因为查天气的时候你需要反馈到是上海的天气还是北京的天气,这些都会根据上面的语句进行提问。
人机交互未来的研究方向
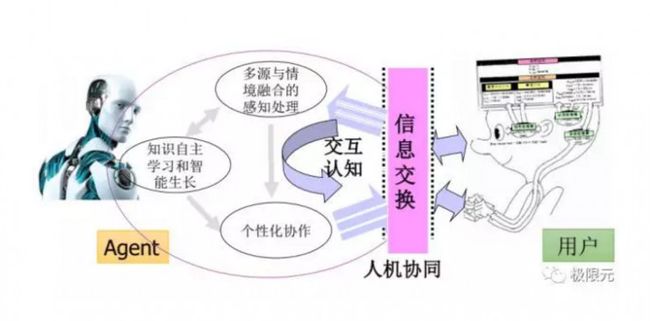
除了前面提到语音作为主要接口的一种对话形式,我们也会考虑一些多模态相关的信息,比如对于用户和机器人,当中有一个人机交换属于人机协同,但是需要处理的信息会比较多,比如机器人会根据用户输出个性化声音,同时融合多元情感融合的处理,机器人会根据你输入的信息进行自主学习以及智能生长,这些都是将来人机交互这块需要考虑的问题。
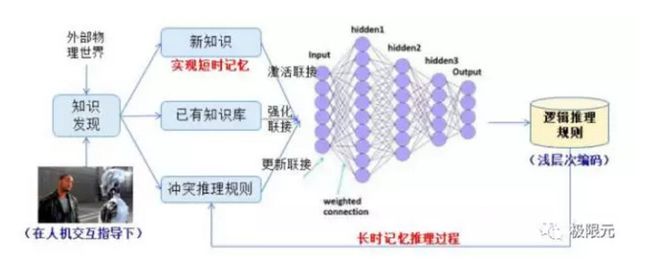
基于交互学习的知识问答和智能生长,目前最主要基于短时工作记忆,未来主要工作可能转换到长时记忆的转换,同时我们也能对新知识进行快速的学习和更新。
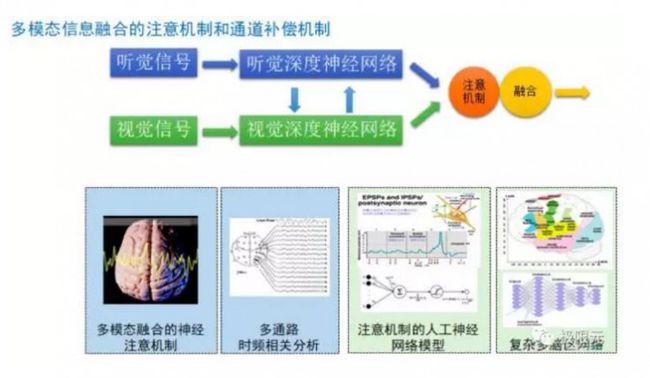
我们考虑的信息除了听觉信息还有视觉信息,通过多模态融合的方法,我们也会研究在脑部这些脑区功能的一些主要关注点,这些都会成为将来的研究点。对话平台有了前面的多模态的信息输入,我们希望把这些都融合起来做成一个多模态融合的一个对话系统。
语音作为互联网的重要入口,功能得到了大家越来越多的重视,当然语音产业也需要更多的人才去发展,目前对话系统的功能在体验上有些不理想,这也是行业从业者需要考虑的问题,同时我们在将来会研究采用多模态智能生长等相关交互技术,促进人机交互的发展。
相关文章:
专访阿里 iDST 语音组总监鄢志杰:智能语音交互从技术到产品,有哪些坑和细节要注意?
本文作者:雷锋专栏
本文转自雷锋网禁止二次转载,原文链接