《淘宝技术这十年》读书笔记 (一).淘宝网技术简介及来源
——Eastmount序
最近时间很充实,实习也还没有找,非常的茫然,所以决定多看点书,写点读书笔记吧!第一篇读书笔记是《淘宝技术这十年》的第一部分读后感,记录一些有用的知识,同时通过这本书能介绍些学过的知识或面试中可能出现的题目,文章还是非常有趣的,希望对大家有所帮助!
一. 《你刚才在淘宝上买了一件东西》
PS:首先讲述阿里员工卡特的文章《你刚才在淘宝上买了一件东西》。
快要过年了,于是想给你的女朋友买一件毛衣,你打开了www.taobao.com。
这时你的浏览器首先查询DNS服务器,将www.taobao.com转换成IP地址。
不过你首先会发现,在不同的地区或不同的网络(电信、联通、移动)下,转换后的IP地址很可能是不一样的。这首先涉及到了负载均衡的第一步,通过DNS解析域名时,将你的访问分配到不同的入口,同时尽可能保证你所访问的入口是所有入口中可能较快的一个(这和后文的CDN不一样)。
你通过这个入口成功地访问了www.taobao.com实际的入口IP地址,这是产生了一个PV(Page View,页面访问量。每日每个网站的总PV量是形容一个网站规模的重要指标。淘宝网全网在平日非促销期间的PV大概是16-25亿个之间)。同时作为一个独立的用户,你这次访问淘宝网的所有页面均算作一个UV(UniqueVisitor,用户访问)。
因为同一时刻访问www.taobao.com的人数过于巨大,所以即便是生成淘宝首页页面的服务器,也不可能仅有一台,仅用于生成淘宝首页的服务器就可能有成百上千台,那么你的一次访问时生成页面给你看的任务便会分配给其中一台服务器完成。这个过程要保证公正、公平、平均(即这成百上千台服务器每台负担的用户数要差不多),这一很复杂的过程由几个系统配合完成,其中最关键的便是LVS(LinuxVirtual Server,世界上最流行的负载均衡系统之一)。
经过一系列复杂的逻辑运算和数据处理,这次用于给你看的淘宝网首页的HTML内容便成功生成了。对Web前端稍微有点常识的人都应该知道,浏览器下一步会加载页面中用到的CSS、JS(JavaScript)、图片等样式、脚本和资源文件。但是可能相对较少的人才会知道,你的浏览器在同一个域名下并发加载的资源数量是有限的,例如IE6和IE7是两个,IE8是6个,chrome个版本不同,一般是4-6个。我刚刚看了下,我访问淘宝首页需要加载126个资源,那么如此小的并发连接数自然会加载很久。
所以前端开发人员往往会将上述这些资源文件分布在多个域名下,变相地绕过浏览器这个限制,同时也为下文的CDN工作做准备。
据不可靠消息称,在2011年“双十一”当前高峰,淘宝的访问流量最巅峰达到871GB/s,这个数字意味着需要178万个4MB/s的家庭宽带才能负担得起,也完全有能力拖垮一个中小城市的全部互联网宽带。显然,这些访问浏览不可能集中在一起,并且不同地区、不同网络之间互访会非常缓慢,但是你却很少发现淘宝网访问缓慢,这便是CDN(ContentDelivery Network,即内容分发网络的作用)。淘宝在全国各地建立了数十个甚至上百个CDN节点,利用一些手段保证你访问的(这里主要指JS、CSS、图片等)站点是离你最近的CDN节点,这样便保证了大流量的分散以及在各地访问的加速。
这便出现另一个问题,那就是假若一个卖家发布了一个新的宝贝,上传了几张新的宝贝图片,那么淘宝网如何保证全国各地的CDN节点中都会同步存在这几张图片共用户使用呢?
这涉及大量的内容分发与同步的相关技术;另外,淘宝上拥有海量的宝贝图片等静态文件,这些文件的总容量也达到了数PB(1PB=1024TB),为了快速存取这些文件,淘宝开发了分布式文件系统TFS(TaoBao File System)来处理这类问题。
好了,此时你终于加载完成淘宝首页,然后习惯性地在首页搜索框中输入“毛衣”二字并按回车键,这时你又产生了一个PV,然后淘宝网的主搜索系统便开始为你服务,它首先对你输入的内容基于一个分词库进行分词操作。
众所周知,英文是以词为单位的,词和词之间靠空格隔开,而中文是以字为单位,句子中所有的字连接起来才能描述一个意思。例如,英文句子“I am astudent”用中文表示则是“我是一个学生”。计算机可以很简单地通过空格知道student是一个单词,但是不太容易明白“学”、“生”两个字合起来才表示一个词。把中文的汉字序列切分成有意义的词,就是中文分词,有些人也称为切词。“我是一个学生”分词的结果是“我 是 一个 学生”。
进行分词操作之后,还需要根据你输入的搜索词进行购物意图分析。用户进行搜索时常常有如下几类意图:
1.浏览型:没有明确的购物对象和意图,边看变买,用户比较随意和感性。Query例如“2010年10大香水排行”、“2010年流行毛衣”、“zippo有多少种类?”
2.查询型:有一定的购物意图,体现在对属性的要求上。Query例如:“适合老人用的手机”、“500元手表”
3.对比型:已经缩小了购物意图,具体到某几个产品。例如:“诺基亚E71 E63”、“akg k450 px200”
4.确定型:已经做了基本决定,重点考察某个对象。例如:“诺基亚N97”、“IBM T60”
通过对你的购物意图的分析,主搜索会呈现出完全不同的结果。
之后的数个步骤后,主搜索系统便会根据上述以及更多复杂的条件列出了搜索结果,这一切是由一千多台搜索服务器完成的。然后你开始逐一点击浏览搜索出的宝贝,查看宝贝详情页面。经常购物的亲们会发现,当你买过一个宝贝之后,即便商家多次修改宝贝详情页,你仍然能够通过“已买到的宝贝”查看当时的快照。这是为了防止商家对商品详情中承诺过的东西赖账不认。
显然,对于每年数十亿甚至上百亿笔交易的商品详情快照进行保存和快速调用不是一件简单的事情。这其中又设计数套系统的共同协作,其中较为重要的是Tair(淘宝自行研发的分布式KV存储方案)。
接下来,无论你是否真的进行了交易,你的这些访问行为都会如实地被系统记录下来,用于后续的业务逻辑和数据分析。这些记录中的访问日志记录便是最重要的记录之一,但是从前面我们得知,这些访问时分布在各个地区不同的服务器上的,并且由于用户众多,这些日志记录都非常庞大,达到TB级别也非常正常。
那么,为了快速、及时、同步地传输这些日志数据,淘宝研发了TimeTunnel,用于进行实时的数据传输,然后交给后端系统进行计算报表等操作。
你的浏览数据、交易数据以及其他很多数据记录均很被保留下来,使得淘宝存储的历史数据轻而易举地便达到了数十甚至更多个PB。如此巨大的数据量存储在阿里巴巴集团的数据仓库中,并且其中有些数据使用了压缩比高达1:120的极限存储技术。之后这些数据会通过一个叫做云梯的基于Hadoop的由3000多台服务器组成的超大规模数据系统,以及一个基于阿里巴巴集团自主研发的ODPS系统的数据系统,不断地进行分析和挖掘。
淘宝从这些数据中能够知道小到你是谁,你喜欢什么,你的孩子几岁了,你是否在谈恋爱,喜欢玩魔兽世界的人喜欢什么样的饮料等,大到各行各业的零售情况、各类商品的兴衰等海量信息。
说了这么多,其实也只是叙述了淘宝上正在运行的成千上万个系统中的寥寥几个。即便是你仅仅访问一次淘宝的首页,所涉及的技术和系统规模都是你完全无法想象的,是淘宝2000多名顶级的工程师们的心血结晶,其中甚至包括长江学者、国家科学技术最高奖得主等众多牛人。
同样,百度、腾讯等的业务系统也绝不比淘宝简单。你需要知道的是,你每天使用的互联网产品看似简单易用,背后却凝聚着难以想象的智慧与龙洞。
PS:从这篇文章中我看到了很多东西,包括网络DNS域名等,让我想到的是网络五层协议和一个题目”描述从中国北京传输到美国纽约的网络流程?“;同时也看到了网络访问量PV知识、Web前端技术、CND分发和资源分配;还有中文分词、LTP和一个电话面试题目”请描述搜索引擎的工作流程?“等知识。这是非常好的一篇技术文章描述淘宝网的。
二. 淘宝网的来源
2003年4月7日,马云在杭州成立了一个神秘的组织。布置的任务是在最短的时间内做出一个个人对个人(C2C)的商品交易的网站。这里出一个问题考考大家,看你适不适合做淘宝的创业团队:亲,要是让你来做,你怎么做?
在说出这个答案之前,先介绍这个创业团队的成员:三个开发工程师(虚竹、三丰、多隆)、一个UED工程师(二当家)、三个运营工程师(小宝、阿珂、破天)、一个经理(财神),以及马云和他的秘书。
当时对整个项目压力最大的是时间,火云邪神先生说过“天下武功无坚不破,唯快不破”,同时当时eBay和易趣在资本方面打得不可开交。淘宝2003年5月10日上线,在这一个月时间怎么做呢?答案是“买一个来”。
买了这样一个架构的网站LAMP(Linux+Apache+MySQL+PHP),这个知道现在还是一个很常用的网站架构模型,其优点是无须编译,发布快速,PHP语言功能强大,能做从页面渲染到数据访问所有的事情,而且用到的技术都是开源、免费的。
当时我们从一个美国人那里买到的一个网站系统叫做PHPAuction(Auction即拍卖),对方提供了源代码。买来之后不是直接就能用,需要本地化修改,如修改数据类型,增加后台管理功能,页面模板修改,增加自己的网点简介。
其中最有技术含量的是对数据库进行了一个修改,原来是从一个数据库进行所有的读写操作,现在把它拆分成一个主库、两个从库,并且读写分离。这么做的好处有几点:存储容量增加了,有了备份,使得安全性增加了,读写分离使得读写效率得以提升(写要比读更加消耗资源,分开后互不干扰)。整个系统的架构如下图所示:

其中pear DB是一个PHP模块,负责数据访问层。另外他们也用开源的论坛系统PHPBB搭建了一个小的论坛社区,在当时论坛几乎是所有网站的标配。
虚竹负责机器采购、配置、架设等,三丰和多隆负责编码,他们把交易系统和论坛系统的用户信息打通,给运营人员开发出后台管理的功能(Admin系统),把交易类型从只有拍卖这一种增加为拍卖、一口价、求购商品、海报商品四种。
在开发过程中,这个项目的代号是BMW,因为二当家非常喜欢宝马,希望我们的网站像宝马一样漂亮、快速、安全,充满乐趣。在上线的时候需要给这个网站取个名字,为了不引起eBay的注意,这个名字需要撇开和阿里巴巴的关系,所以“阿里爷爷”、“阿里舅舅”之类的域名都是不能用的。美女阿珂提议名字“淘宝”。因为她家里人热爱收藏古董,经常去市场上淘宝,而她本人也非常热爱逛街,享受“淘”的乐趣,她觉得“淘宝”两字特别符合网站的定位(后来“支付宝”也是阿珂取得)。

在非典时期大家都不敢出门,尤其是类似商场等人多的地方,同时神州大地上最早出现的C2C网站易趣也忙得不亦乐乎,后被eBay收购。当时淘宝网允许买卖双方留下联系方式,允许同城交易,整个操作过程简单轻松;而eBay是收费的,为了收取交易佣金,eBay禁止买卖双方这么做,增加了交易过程的难度。同时eBay为了全球统一,把易趣原来的系统替换成了美国eBay系统,用户体验全变了,操作起来非常麻烦丢失了很多用户。
为了不引起eBay的注意,淘宝网在2003年里一直声称自己是一个“个人网站”,淘宝网发展非常迅猛,2003年年底就吸引了注册用户23万个,每日31万个PV,这没有引起eBay的注意,却引起了阿里巴巴内部很多员工的注意,他们觉得这个网站以后会成为阿里巴巴强劲的对手,甚至在内网发帖忠告管理层警惕,但管理层似乎却无动于衷。
当时淘宝第一个版本的系统中已经包含了商品发布、管理、搜索、商品详情、出价购买、评价投诉、我的淘宝等功能(现在主流程中也是这些模块。在2003年10月增加了一个功能结点:“安全交易”,这是支付宝的雏形)。随着用户需求和流量的不断增加,系统做了很多日常改进,服务器最初的一台变成三台,一台负责发送Email、一台负责运行数据库、一台负责运行WebApp。
一段时间之后,商品搜索的功能占用数据库资源太大了(用like搜索的,很慢),2003年7月,多隆又把阿里巴巴中文站的搜索引擎iSearch搬了过来。
随着访问量和数据量的飞速上涨,问题很快就出来了,第一个问题出现在数据库上。MySQL当时是第4版的,我们用的是默认存储引擎MyISAM,这种存储引擎在写数据的时候会把表锁住。当时Master同步数据到Slave的时候,会引起Slave写,这样Slave的读操作都要等待。还有一点是会发生Slave上的主键冲突,经常会导致同步停止,这样你发布的一些东西命名已经成功了,但就是查询不到。另外,当年的MySQL不必如今的MySQL,在数据的容量和安全性方面也有很多先天不足(和Oracle相比)。
三. 支付宝和旺旺的出现
讲到这里,顺便先辟个谣,网上有很多这样骗转发的励志段:“1998年,马化腾等一伙人凑了50万元创办了腾讯,没买房;1998年,史玉柱借了50万元搞脑白金,没买房;1999年,丁磊用50万元创办了163.com,没买房;1999年,陈天桥炒股赚了50万元,创办盛大,没买房;1999年,马云等18人凑了50万元注册阿里巴巴,没买房。如果当年他们用这50万元买了房,现在估计还在还着银行的贷款吧。”
事实上,阿里巴巴和淘宝网都是在马云自己的房子里创办的,阿里巴巴是1999年初发布上线的。所以关于马云买房的事情真相是这样的。
淘宝网作为个人网站发展的时间并不长,由于它太引人注目了,马云在2003年7月就宣布这个是阿里巴巴旗下的网站,随后在市场上展开了很成功的推广运作。最著名的就是利用中小网站来做广告,突围eBay在门户网站上对淘宝的广告封锁。eBay买断了新浪、搜狐、网易等电子商务类型的广告,签署了排他性协议,切断淘宝在这上面做广告的路子。网站中经常见到的那些右下脚的弹窗和网站腰封上一闪一闪的广告。市场部那位到处花钱买广告的家伙太能花钱了,一出手就是几百万元,被称为“大少爷”。
带来的是迅速上涨的流量和交易量。在2003年年底,MySQL已经支撑不住了,技术的替代方案非常简单,换成Oracle。原因除了它容量大、稳定、安全、性能高之外,还有人才方面的原因。
在2003年阿里巴巴已经有一支很强大的DBA团队了,有鲁国良、冯春培、汪海(七公)这样的人物,还有冯大辉、陈吉平(拖雷)。这样的任务牛到什么程度呢?Oracle给全球的技术专家颁发头衔最高级别是ACE(就是扑克牌的“尖儿”),被授予这个头衔的人目前全球只有300多名,当年全球只有十几名,而阿里巴巴就有4名(阿里巴巴的首席数据库管理员(DBA)冯春培为甲骨文全球第100个ACE)。有如此强大的技术后盾,把MySQL换成Oracle是顺理成章的事情。
但更换数据库不是只换个库就可以的,其访问方式和SQL语法都要跟着变,最重要的是Oracle的性能和并发访问能力之所以强大有一个关键性的设计——连接池,连接池中方的是长连接,是进程级别的,在创建进程的时候,它就要独占一部分内存空间。
也就是说,这些连接数在固定内存的OracleServer上是有限的,任何一个请求只需要从连接池中取得一个连接即可,用完后释放,这不需要频繁地创建和断开连接,而连接的创建和断开的开销是非常大的。但对于PHP语言来说,它对数据库的访问都是很直接的,每一个请求都要一个连接。如果是长连接,应用服务器增多时,连接数就多,就会把数据库拖挂;如果是短连接,频繁地连接后再断开,性能会非常差。那如何是好呢?
多隆在网上找到一个开源的连接池代理服务SQL Relay,网址如下:
http://sqlrelay.sourceforge.net
多隆对这个能够提供连接池功能的东西进行了改进,系统的架构变成了如下形式:
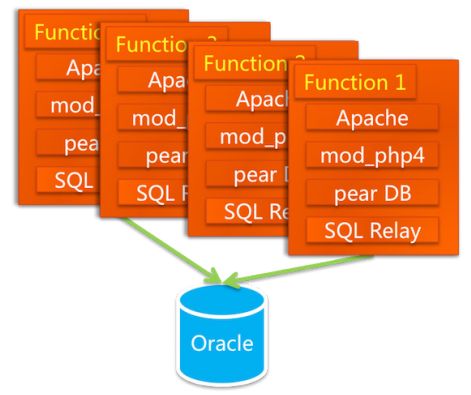
数据开始是放在本地的,七公带领的DBA们对Oracle做调优的工作,也对SQL进行调优。后来数据量变大后,本地存储无法满足了,买了NetApp 公司的NAS(NetworkAttached Storage,网络附属存储)作为数据库的存储设备,加上Oracle RAC来实现负载均衡。后来数据量变大,变成了购买小型机的道路。
替完数据库后,在2004年春天他们在把数据的连接放在SQL Relay之后就噩梦不断,这个代理服务经常会死锁,如之前的MySQL死锁一样。虽然多隆做了很多修改,但当时那个版本内部处理的逻辑不对,问题很多,最快的解决办法就是“重启”它的服务。这在白天还好,只要连接上机房的服务器,把进程杀掉,然后开启就可以了;但是最痛苦的是它在晚上也要死掉,于是工程师需要24小时开机,一旦收到“SQL Relay进程挂起”的短信,就会重启。做这事最多的据说是三丰,他现在是淘宝网的总裁。现在我们知道,任何牛B的人物,都有一段苦B的经历。
微博上有人说“好的架构是进化来的,不是设计来的”。的确如此,在架构的进化过程中,业务的进化也非常迅猛。最早买家打钱给卖家都是通过银行转账汇款,有些骗子收了钱却不发货甚至逃之夭夭。这是一个很严重的问题,淘宝网这伙人开始研究防骗子的解决方案,他们看了PayPal的支付方式,发现不能解决问题。研究了类似QQ币的东西,想弄出个“淘宝币”出来,发现也不行。后来几个聪明的想法黏合起来,想到了“担保交易”这种第三方托管资金的办法。于是淘宝网上线了一个功能“安全交易”,卖家如果选择支持这种功能,买家就会把钱交给淘宝网,等他收到货后淘宝网再把钱给卖家,这就是现在的“支付宝”。
有人说淘宝打败易趣(eBay中国)是靠免费,其实这只是原因之一。如果说和易趣过招的第一招是免费,让用户无须成本就能进来,那么第二招就是“安全支付”,这让用户放心付款,不必担心被骗。而淘宝的第三招就是“旺旺”,淘宝旺旺是从阿里巴巴的“贸易通”复制过来砍价的。
SQL Relay的问题搞得三丰等人很难睡个好觉,不能总这样通过不断地重启保证系统的稳定性。于是,2004年上半年开始,整个网站就开始了一个脱胎换骨的手术。下一篇文章将介绍第二部分,关于Java时代和创造技术。
PS:最后还是希望文章对大家有所帮助,虽然文章中出现的很多涉及淘宝网的专业词汇我也不知道其技术是什么,但是还是能从《淘宝技术这十年 著:子柳》书中学到一些有用的知识。我主要是记录了其中自己认为比较好的文字复述出来,希望大家购买正版书籍阅读学习。
(By:Eastmount 2015-4-20 夜5点 http://blog.csdn.net/eastmount/)