谨以此文缅怀我18个小时的持续工作,今天金工实习西门子CNC的时候乘着空闲还在草稿纸上不断的写写画画。我觉得这项技术还是有意义的,可能我还是比较愚蠢,基础不够,还没有办法解决这个问题。
我们在使用GPU做光线跟踪的时候,无一例外的要找到一个加速遍历场景的方法。在体素渲染Volumn Rendering中,大部分还是使用的固定网格Uniform Grid Structure进行渲染,效率比较低。我们只有在来自Standford的一些GPU光线跟踪器的实现的Paper中才可以看到kD树的身影。如何使用kD树分割模型大家可以看我以前写的那片利用SAH分割模型的文章,在许多著名CG人士提供的自己的代码中都有各自kD树的实现。问题是,GPU上如何实现呢?
GPU的优点极多,主要是,超快的SIMD/MIMD指令处理单元,特别优化过的纹理寻址功能,在这两点上CPU就远远比不上了。但是最为致命的一点,目前的GPU无法在Shader中访问内存,也就是还没有实现指针结构,无法实现动态内存分配,当然分配的应该是显存。如果用CUDA,可能可以实现,不过那是后话,还没有多少人拥有G80系列的显卡,那样也没有实际的意义了。
我的构想是,在Shader中增加3个纹理贴图。一个是平面纹理化的kD树,另外两个是绑定盒,分别储存对点的两个坐标,为了能够遍历三角形,我们还需要把三角形按照次序把3个顶点分别储存到3个纹理中。由于这个kD树还需要与三角形索引纹理进行交互,所以,我们必须事先准备好“混乱索引数组”Chao Index Array,下面简称CIA(可不是中央情报局)。下面详细解释这些个纹理在Shader里是如何运作的,示意图如下。
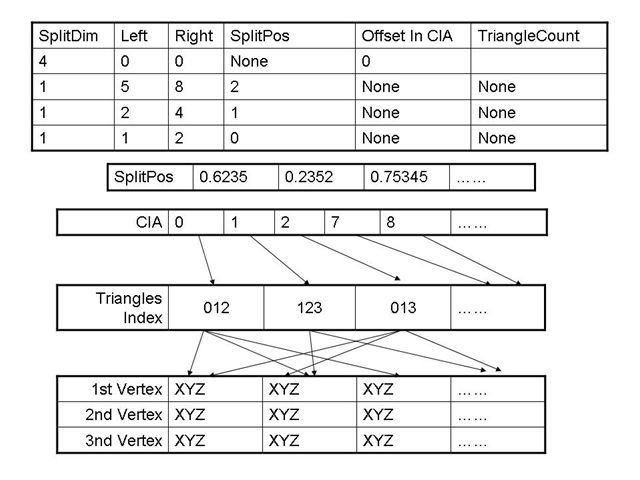
我们都了解了kD树的构造。首先,kD树的节点分为2类,一类是Node类型,一类是Leaf类型。Node类型记录了当前分割的维度和分割位置,不储存任何几何体信息。而到了树的底端,就差不多都是Leaf类型了。Leaf类型记录了三角形的树木和在CIA中的起始偏移位置。为什么是CIA而不是标准的从0开始的索引呢?因为我用的kD树构造方法,使用了STL中的stable_partition算法处理三角形数组。
在Shader里面,首先我们计算光线的起始位置和方向,这个很简单。然后,我们把绑定盒的世界位置输入(或者我们仅仅绘制绑定盒),在FragShader中开始遍历kD树纹理。首先从最底层开始,取得第一个整数,如果是在123范围内就认为是Node(其实肯定是的),如果是Node,查询后面的SplitPos,通过这个整数,在SplitPosArray中找到具体的分割位置,判断向左向右。如果需要向左,查询Left中的整数,自动的给这个纹理坐标的t分量加上偏移量,开始新的查询,直到找到Leaf,读取偏移量和三角形数目,开始测试插值。
所有的纹理都使用RECTANGLE_NV纹理,使用Nearest过滤方式。
伪GLSL代码如下:
ivec2 traverselptr(0,0);
bool found = false;
int offset = 0,count = 0;
while( found == false ){
int Dim = texture2D(kDAccMap,traverselptr.st).x;
if( Dim == 4 ){
found = true;
offset = texture2D(kDAccMap,traversalptr+ivec2(0,4)).x;
count = texture2D(kDAccMap,traversalptr+ivec2(0,5)).x;
countinue:
}
TestRay();
if ( need goto Left ){
traverselptr.s += texture2D(kDAccMap,traverselptr + ivec2(0,1));
}else if( need goto Right ){
traverselptr.s += texture2D(kDAccMap,traverselptr + ivec2(0,2));
}
}
for( int i=0;i //use CIA and standard triangles index to coordinate vertices } 看起来挺不错是么?这里有一个严重问题:如果我们需要同时遍历Left和Right如何是好?在CPU上,和OpenRT的设计上,这里是使用了一个优先堆栈,可是在Shader里面有这个玩意么?也许这个情况的出现导致出错的概率比较小,可是依旧需要考虑到。