hive中求相邻时间问题的两种解决方法
hive中经常会有求连续数字或者连续的时间这种问题,其实处理的方法一致。
首先给出数据的结构:
假如表dw.tmp_interview_data中存放有如下样式的数据:
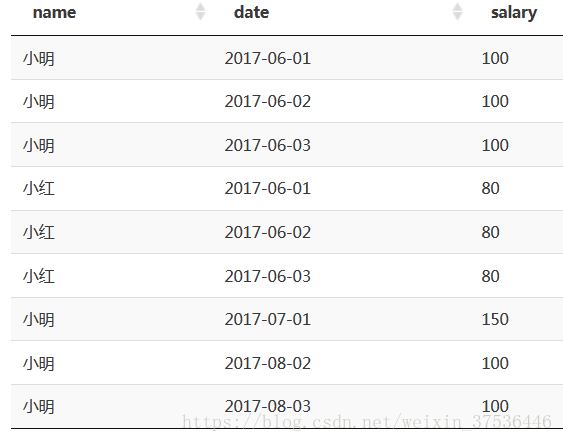
求出表dw.tmp_interview_data中每个人连续工作时间段及对应的工资和,结果表如下:
| 姓名 |
开始日期 |
结束日期 |
总工资 |
| 小明 |
2017-06-01 |
2017-06-03 |
300 |
| 小红 |
2017-06-01 |
2017-06-03 |
240 |
| 小明 |
2017-07-01 |
2017-07-01 |
150 |
| 小明 |
2017-08-02 |
2017-08-03 |
200 |
此种为题可以归类为求连续时间的问题(求连续数字是相同的解决办法),现给出两种解决办法。
第一种:
SELECT a.name
,b.starttime
,b.endtime
,sum(case when a.date>=b.starttime and a.date<=b.endtime then a.salary else 0 end) as total_salary
FROM dw.tmp_interview_data a
LEFT JOIN
( SELECT name
,diff
,qujian[0] endtime
,case when diff=0 then qujian[0]
when diff=1 then qujian[1]
when diff=2 then qujian[2]
when diff=3 then qujian[3] end as starttime --此处如有其它时间差,需要进行枚举
FROM --取出连续时间范围
( SELECT name
,datediff(max(date),min(date)) diff
,COLLECT_set(date) qujian
FROM --求出连续时间之差
( SELECT name
,date
,salary
,date_sub(date,rank) as date2
FROM --日期与排名之间的差值
( SELECT name
,date
,salary
,row_number () over (partition by name order by date) rank
FROM dw.tmp_interview_data --按name分组后对date进行排序
) a
) a
GROUP BY name,date2
) a
) b on a.name=b.name
GROUP BY a.name,b.starttime,b.endtime
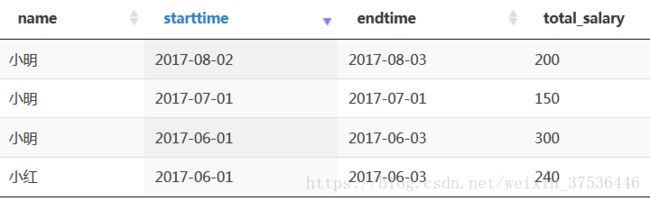
运行结果如下:
第二种方法:
SELECT name
,first1
,last1
,salary * (datediff(last1, first1)+1) as salary
FROM
( SELECT name
,num
,salary
,min(date) as first1
,max(date) as last1
FROM
( SELECT a.name
,a.date
,date_sub(date, rn - 1) num
,salary
FROM
( SELECT name
,date
,salary
,row_number() over(PARTITION BY name ORDER BY date) rn
FROM dw_htlbizdb.tmp_qh_liu_interview_data
GROUP BY name,date,salary
) a
) b group by name,num,salary
) a
运行结果如下:

其实两种方法比较下来,都先先用row_number()函数通过name分组,并对日期进行排序,然后利用日期与所得排名之间的差值来做进一步的处理。连续数字问题思路同上~