知识图谱构建之二:从结构化数据到知识图谱
请关注一下微信公众号:机器学习简明教程
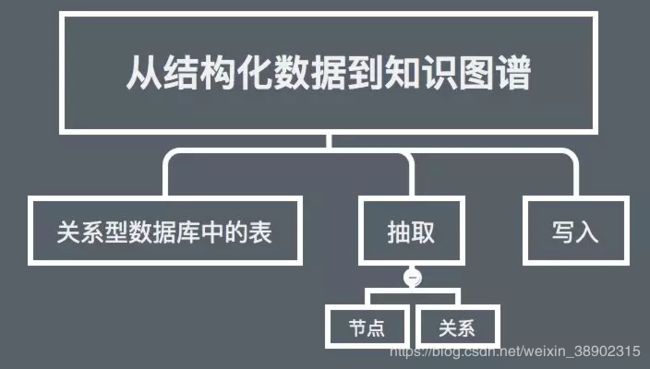
当关系型数据库oracle、mysql或者hive中存在一张关于某个主题的表时,我们应该如何基于该表创建知识图谱?
我们来看一个简单的例子。
01 关系型表
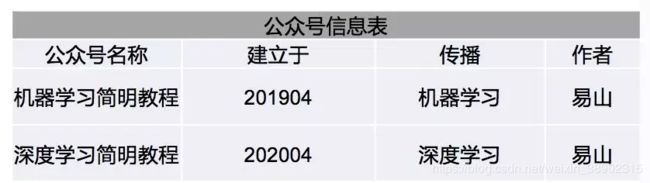
这张表结构如上图所示,包含公众号名称,建立时间,传播知识的主题,作者共4个字段。
节点的创建有两种方法。第一种方法,可以把每个字段都做成节点,公众号名称字段就是节点的标签名,具体的字段值就是name属性值;第二种方法,可以把公众号名称做成一种节点,其他字段信息做成公众号信息节点。
关系的创建其实就是把上面这张表列转行,关系的标签就是字段名:建立于、传播和作者。
详细工程代码和描述如下。
02 抽取
from py2neo import Node, Graph, Relationship
import pandas as pd
# connect neo4j
graph = Graph("bolt://localhost:7687", username="neo4j", password="****")
label_1 = "公众号节点"
label_2 = "公众号信息节点"
graph.delete_all()
# step1:read data
data = pd.read_csv("./data/raw_data.csv", header=0)
data["建立于"] = data["建立于"].astype(str)
# step2 : extract nodes
node_list = list(set(data['公众号名']))
mac下执行命令pip install py2neo==3,安装指定版本的py2neo。
实例化Graph类,并通过该类连接neo4j。
第一类节点:抽取出“公众号名称”字段,去重后转成list。
# step3 : extract nodes
node_info_list = []
for i in list(data.columns)[1:]:
node_info_list.extend(data[i])
node_info_list = list(set(node_info_list))
第二类节点:遍历除了“公众号名称”之外的所有字段值,去重后,放进node_info_list中。
# step4 : extract relationships
relation_data = pd.DataFrame()
for i in list(data.columns)[1:]:
rel_data = data[["公众号名", i]]
rel_data["关系"] = i
rel_data.columns = ["公众号节点", "公众号信息节点", "关系"]
relation_data = pd.concat([relation_data, rel_data], axis=0)
关系三元组:基于原始的data,列转行抽取关系。
03 写入
def create_node(node_list, label):
for name in node_list:
print(name)
name_node = Node(label, name=name)
print(name_node)
graph.create(name_node)
create_node(node_list, label_1)
create_node(node_info_list, label_2)
创建节点:create_node遍历节点列表,创建标签为label的节点。
def create_relation(relation_data, label_a, label_b):
for m in range(0, len(relation_data)):
print()
rel = Relationship(
graph.find_one(label_a, property_key="name", property_value=str(list(relation_data['公众号节点'])[m])),
list(relation_data['关系'])[m],
graph.find_one(label_b, property_key="name", property_value=str(list(relation_data['公众号信息节点'])[m])))
graph.merge(rel, label=[label_b, label_a])
create_relation(relation_data, label_1, label_2)
创建关系:create_relation遍历关系数据并创建关系。
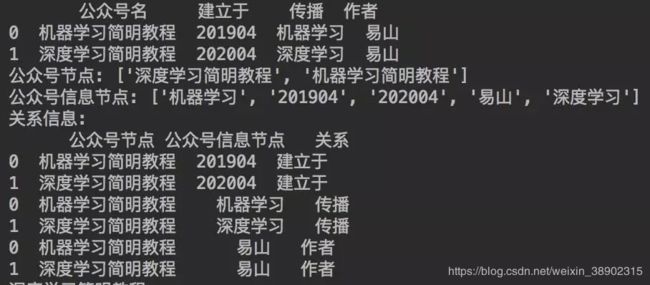
日志:节点和关系抽取过程如上。
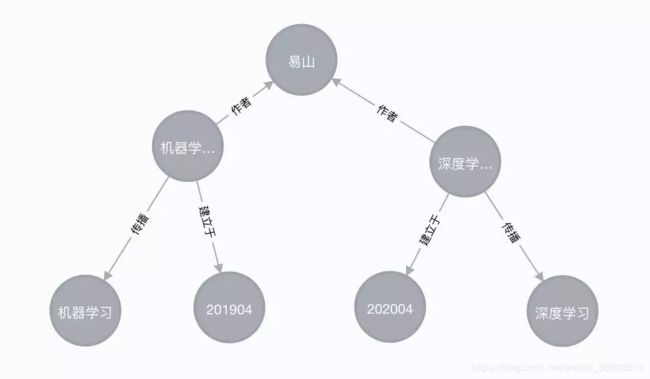
知识图谱:最后neo4j中会出现如上图所示的节点与关系。