python爬虫实践(高级篇)——爬取P站图片
上一个文章我就简简单单爬了一下官方站点的壁纸,突然间感觉78张壁纸太少了,就想再加大力度去扒图片。
刚好,在B站找到一个志趣相投的UP主,跟我一样想弄到一些关于《天使降临到我身边》。
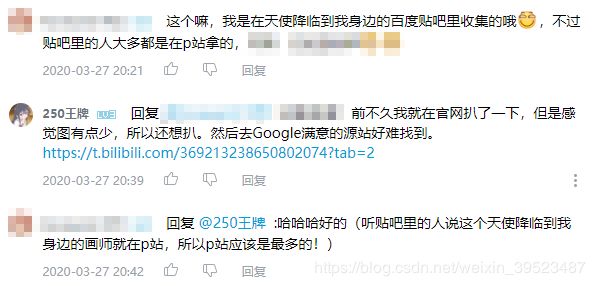
与这位UP主的对话。为保护他人隐私信息安全,已把部分信息马进行遮掩处理。
对呀!我可以爬P站呀!

P站搜索结果页面。
就选它了!
前提
Python的运行环境肯定要有了,要安装request库(如果没有请使用管理员CMD或者在PyCharm里面安装),当然还要一个IDE,IDE可以选择PyCharm,这是一个比较好的IDE。
工具备好后,你还要有Python和HTML的语言基础,会使用requests库,这次相比我的上一个文章而言,你还要懂一些HTTP协议的相关知识。
首先我在这里说一句:请尊重画师的劳动成果!因此扒到的图片仅用于个人用途!相信各位在爬虫的入门课的时候(应该说是在进入编程行业的时候)就已经了解版权的相关问题。再次强调一次:扒到的图片仅用于个人用途!除非画师给你授权!
其次我希望各位先尝试自己去思考解决方案,毕竟爬虫这个东西是需要日积月累才能很好地去使用,虽然P站有点难爬,但是如果你认真分析请求数据,其实可以找到突破点的,至少还没有像QQ音乐那样那么难。
开始工作
玩过P站的人都知道,玩P站是需要登录的。所以第一件要解决的事情是如何模拟登录。
我稍微看了一下登录界面的POST数据,就发现P站的反爬措施比较巨核(没有任何夸张成分),post_key的值可以在页面获取,但是难点在于如何破解reCATPCHA(P站甚至使用reCATPCHA的V3版本,V3的reCATPCHA是最新版本,也是最难破),我也不可能花大资金去弄一个AI进行机器训练(我也没在这方面深入了解)。由于UP主说他的图片不多了,急需图片。所以我另辟蹊径:就在浏览器正常登录后,使用生成的Cookie登录。至于如何通过Python全程自动模拟登录,我将在下期文章讲述。

正常请求的表单数据。就画框的地方让我抓狂!为保护个人隐私信息安全,已把部分信息马进行遮掩处理。
而P站的图片比较多,固然会让一些盗图党(滑稽)利用,因此官网多多少少肯定会有一些反爬措施。最基础的检查手段就是检查UA头和referer头是否正常。
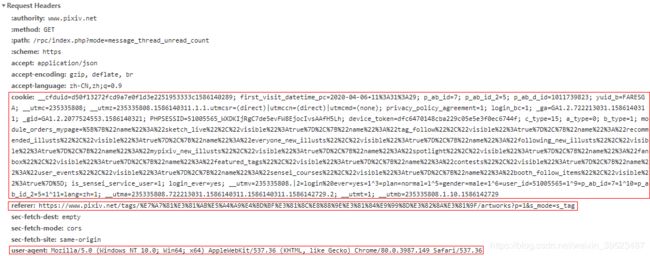
向搜索页面发出的请求头。其中画框的头是我们爬虫必须要用到的.。
现在就可以先敲一段代码了,来设置请求头。
import requests
import time # 这个玩意就很有必要了,尤其对于这种图片大站
headers = {
"cookie": "", # 根据自己的浏览器情况填写,UA头也是
"user-agent": "",
"referer": "https://www.pixiv.net/ajax/search/artworks/%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F?word=%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F&order=date_d&mode=all&p=1&s_mode=s_tag&type=all"
}现在就开始分析搜索页面的结构。打开调试工具后,在搜索框搜索你自己喜欢的动漫的图片。这篇我以《天使降临到我身边》为例。
如果有一些小伙伴没有细心观察,就以为直接利用select字符串来定位到图片元素,然后获取URL就OK。但我只能说一句:“too young!”,第一在搜索页面的图片全部都是缩略图,不是原图,因此需要获取作品ID,再跳转到作品展示页面,展示页面才是原图;第二也是很重要的,P站的搜索页面是利用JS动态发出AJAX请求,然后根据获得的数据来渲染页面的,因此如果只是单纯GET请求搜索页面是获取不到任何有价值的信息。
有些小伙伴可能会认为必须调用selenium库来模拟浏览器行为,加载JS,从而通过BeautifulSoup获取链接。其实无必要,因为如果这样的话很影响程序执行效率,尤其我们要爬取上百的图片。我们可以利用AJAX请求得到的数据找到突破点。
打开调试工具,点击Network,设置筛选条件的数据类型为“XHR",这时会显示数据交换格式(JSON、XML格式)。
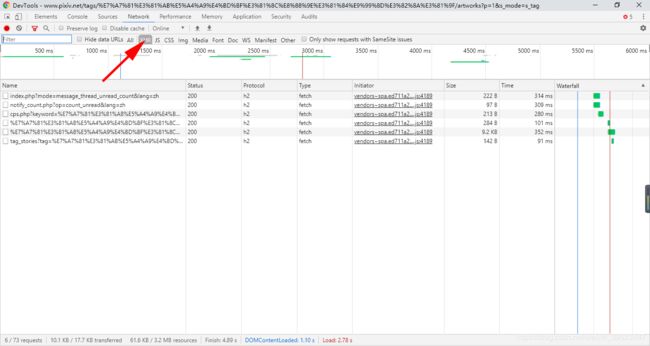
搜索页面的请求。
得到的数据都是JSON类型。可能有些小伙伴不知道应该向哪个页面的数据深入了解。这时尝试把“私に天使が舞い降りた(日文,天使降临到我身边)”转化为URL编码:
%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F很快发现有哪些数据需要注意。

调试工具界面的一部分。画框部分就是注意的地方。
其中第一个页面没有我们想要的东西,但是第二个页面有惊喜。
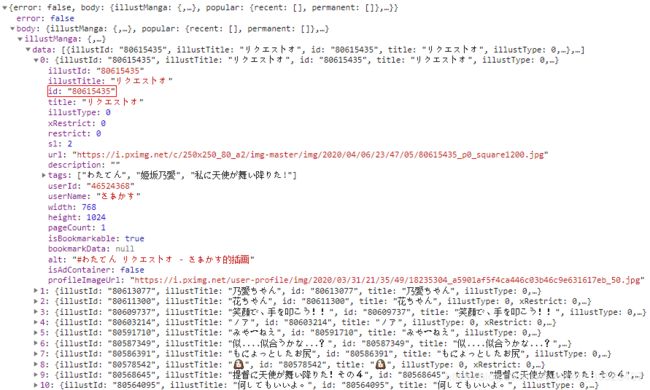
JSON数据。画框的值就是我们需要的东西。
由于每个data元素下的结构基本一致,所以可以通过循环批量获取作品ID。
继续敲键盘。
import requests
import time # 这个玩意就很有必要了,尤其对于这种图片大站
headers = {
"cookie": "", # 根据自己的浏览器情况填写,UA头也是
"user-agent": "",
"referer": "https://www.pixiv.net/ajax/search/artworks/%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F?word=%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F&order=date_d&mode=all&p=1&s_mode=s_tag&type=all"
}
URL = "https://www.pixiv.net/ajax/search/artworks/%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F?word=%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F&order=date_d&mode=all&p=1&s_mode=s_tag&type=all"
session = requests.get(URL, headers=headers)
JSON = session.json()
i = 0
while i < len(JSON["body"]["illustManga"]["data"]):
print(JSON["body"]["illustManga"]["data"][i]["id"])
i += 1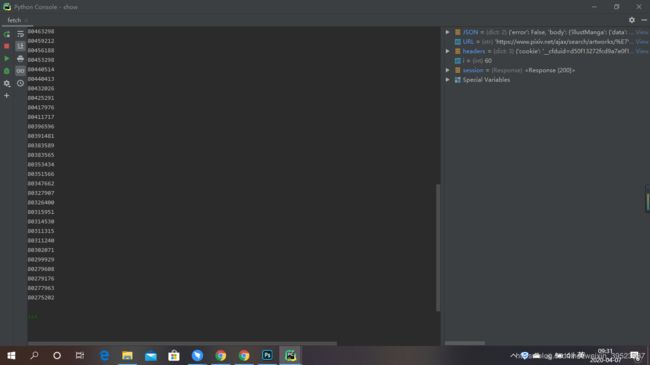
效果图。全部作品ID都弄出来了。
现在就解决如何获取作品ID里面的原图。
现在就打开调试工具,在搜索页面随便打开一个作品(最好打开一个作品ID有多个图片的页面),然后就会跳转到作品展示的页面。
由于P站使用SPA(别想错了,是单页面web应用的意思),到了作品展示的页面可以刷新一下,避免因为调试工具列表过多而寻找突破点有点困难。
作品展示页面。
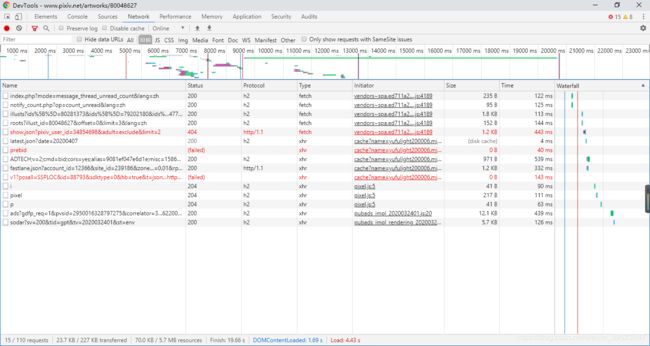
作品展示页面的请求。现在你可能没有找到什么破绽。
点击“查看全部”,然后再去看调试工具,你会发现惊喜。
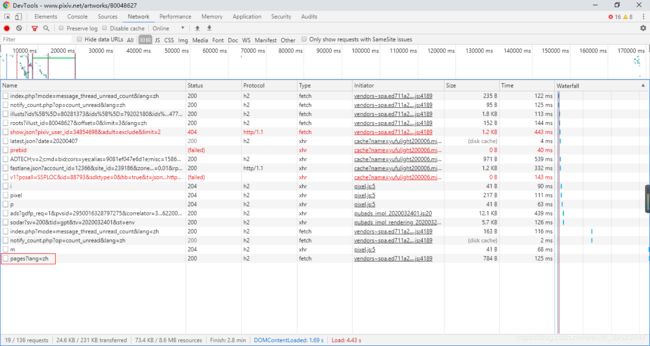
作品展示页面的请求。画框的页面就是突破点。

该页面的JSON数据,画框的地方就是原图。
为什么我说这个是原图的URL,你尝试返回作品展示的页面,放大某个图片,右键点击复制图片链接。就发现原来如此。
范例。
如果这样,可以知道如何爬取一个作品ID的全部页面,那么继续研究如何批量爬取搜索页面的全部ID的图片,关键是如何获取每个作品ID的JSON页面。
请观察刚才的JSON数据的URL:
https://www.pixiv.net/ajax/illust/80048627/pages?lang=zh发现https://www.pixiv.net/ajax/illust/${ID}/pages?lang=zh的关系,因此可以先尝试爬取一个搜索页面的全部图片,敲键盘。
import requests
import time # 这个玩意就很有必要了,尤其对于这种图片大站
headers = {
"cookie": "", # 根据自己的浏览器情况填写,UA头也是
"user-agent": "",
"referer": "https://www.pixiv.net/ajax/search/artworks/%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F?word=%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F&order=date_d&mode=all&p=1&s_mode=s_tag&type=all"
}
URL = "https://www.pixiv.net/ajax/search/artworks/%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F?word=%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F&order=date_d&mode=all&p=1&s_mode=s_tag&type=all"
session = requests.get(URL, headers=headers)
JSON = session.json()
i = j = 0
while i < len(JSON["body"]["illustManga"]["data"]):
ID = JSON["body"]["illustManga"]["data"][i]["id"]
URL = "https://www.pixiv.net/ajax/illust/"+ID+"/pages?lang=zh"
session = requests.get(URL, headers=headers)
JSON1 = session.json()
while j < len(JSON1["body"]):
print(JSON1["body"][j]["urls"]["original"])
j += 1
j = 0
i += 1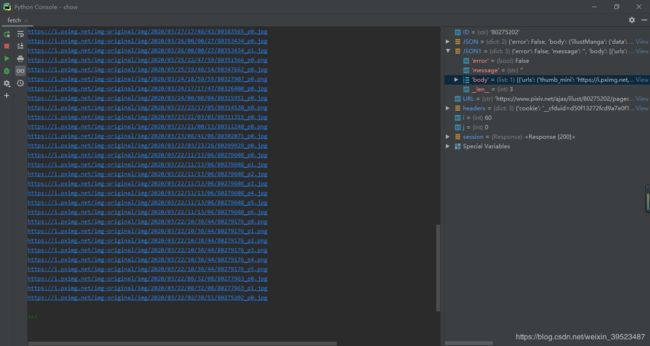
效果图。第一个搜索页面的图片全部URL都撬出来了。
URL弄出来了,那要解决下载方面问题,由于P站本身被墙,加上是用梯子,而且还要下载上百张的图片,所以稳定性方面的问题就不得不重视了。因此不建议使用Python里面的下载部件,最好使用第三方下载引擎,例如迅雷。
但是官方没有说明如何调用其API,不过我在网上溜了一下,也是有办法的,而且亲测有效。
from win32com.client import Dispatch # 引入相关库
api = Dispatch('ThunderAgent.Agent64.1') # 用于迅雷最新版本
# 参数
# api.AddTask(下载链接, 保存文件名)
# 一般而言保存文件名也可不用填,因为迅雷会自动根据URL填写,如有需要可填写
api.AddTask(${URL})
# 可以多次AddTask,到最后CommitTasks才统一把任务发送到迅雷
api.CommitTasks()继续敲键盘
import requests
import time # 这个玩意就很有必要了,尤其对于这种图片大站
from win32com.client import Dispatch
api = Dispatch('ThunderAgent.Agent64.1')
headers = {
"cookie": "", # 根据自己的浏览器情况填写,UA头也是
"user-agent": "",
"referer": "https://www.pixiv.net/ajax/search/artworks/%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F?word=%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F&order=date_d&mode=all&p=1&s_mode=s_tag&type=all"
}
URL = "https://www.pixiv.net/ajax/search/artworks/%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F?word=%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F&order=date_d&mode=all&p=1&s_mode=s_tag&type=all"
session = requests.get(URL, headers=headers)
JSON = session.json()
i = j = 0
while i < len(JSON["body"]["illustManga"]["data"]):
ID = JSON["body"]["illustManga"]["data"][i]["id"]
URL = "https://www.pixiv.net/ajax/illust/"+ID+"/pages?lang=zh"
session = requests.get(URL, headers=headers)
JSON1 = session.json()
while j < len(JSON1["body"]):
URL = JSON1["body"][j]["urls"]["original"]
api.AddTask(URL)
print(URL)
j += 1
j = 0
i += 1
time.sleep(0.5)
api.CommitTasks()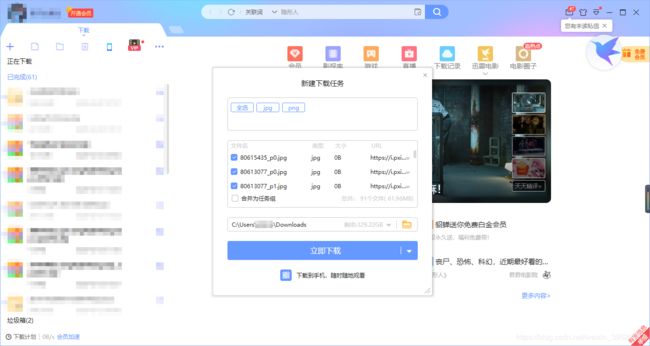
效果图。程序运行完后就会弹出迅雷下载确认框。为保护个人隐私信息安全,已把部分信息马进行遮掩处理。
好了,我们的程序基本上差不多完工了,现在解决的问题是如何爬取剩下的搜索页面。
各位尝试按顺序切换页面,观察JSON页面的URL的变化:
https://www.pixiv.net/ajax/search/artworks/%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F?word=%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F&order=date_d&mode=all&p=2&s_mode=s_tag&type=all&lang=zh注意GET里面的查询字符串的“p=2”,这个就是控制页数的关键,起始页数为1。可以挂起一个循环了。
另外我还要提醒一点,我听说P站不仅仅检查referer头是不是自家的域名,还会看查询字符串是否正常,因此我建议referer也动态改变,跟请求的URL是一模一样的。
至于搜索结果总共有多少页,可以计算在JSON数据里的total(作品总数)除以60(默认每个页面的作品量),有余数要加1(相信各位的数学不是体育老师教的(滑稽)),然后用于循环控制,不过我相信8页左右的图都满足你了,毕竟你还要把一些不好的图给删掉。在这个程序当中,总共有三个循环,第一层循环用于控制页数,第二个循环用于控制每个搜索页面的作品ID,第三个循环用于抓取该作品ID的全部图片。

搜索页面的JSON数据。画框的地方就是作品总数。
继续敲键盘,与此同时稍微增强一些功能
import requests
import time # 这个玩意就很有必要了,尤其对于这种图片大站
from win32com.client import Dispatch
api = Dispatch('ThunderAgent.Agent64.1')
i = j = 0
k = 1 # 搜索页面从1开始
count = 0 # 计数有多少个图片
begin = int(time.time()) # 好奇算一下时长
while k <= 8: # 至于要爬多少你自己定了
URL = "https://www.pixiv.net/ajax/search/artworks/%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F?word=%E7%A7%81%E3%81%AB%E5%A4%A9%E4%BD%BF%E3%81%8C%E8%88%9E%E3%81%84%E9%99%8D%E3%82%8A%E3%81%9F&order=date_d&mode=all&p="+str(k)+"&s_mode=s_tag&type=all"
headers = {
"cookie": "", # 根据自己的浏览器情况填写,UA头也是
"user-agent": "",
"referer": URL
}
session = requests.get(URL, headers=headers)
print("获得"+URL+"的JSON数据")
JSON = session.json()
session.close()
while i < len(JSON["body"]["illustManga"]["data"]):
ID = JSON["body"]["illustManga"]["data"][i]["id"]
URL = "https://www.pixiv.net/ajax/illust/" + ID + "/pages?lang=zh"
session = requests.get(URL, headers=headers)
print("\t获得"+URL+"的JSON数据")
JSON1 = session.json()
session.close()
while j < len(JSON1["body"]):
URL = JSON1["body"][j]["urls"]["original"]
api.AddTask(URL)
print("将"+URL+"加入到待下载队列")
count += 1
j += 1
j = 0
i += 1
time.sleep(0.5)
i = 0
k += 1
api.CommitTasks()
print("共抓取"+str(count)+",时长"+str(int(time.time())-begin))
效果图。爬到图片真是多,没压缩前都上GB了。
好了,终于可以收工了。
常见问题
- 网络不稳定,连接老是中断,那应该如何处理?
选择比较稳定的网络和梯子,或者考虑用try……except……
while True:
try:
session = requests.get(URL, headers=headers)
break
except requests.exceptions.ProxyError:
print("超时!请检查网络!60秒后重新尝试")
time.sleep(60)这样会先尝试与服务器连接,如果失败了也不会终止程序运行,会等一段时间后重新尝试连接。当然时间长度可以设置别的。这样的话可以让你有足够的时间去排除故障,恢复网络。
- 返回的状态码为403
请检查请求头设置是否正确,不要用爬虫默认的请求头,要不然会被墙的。
- 返回的状态码为429
在一段时间内请求过多也会被墙,因此最好使用time.sleep()来间隔请求,最好每次请求完后使用session.close()关闭对话。
如果万一真的被墙了,就只有两个办法,一是你就想办法改变请求的IP,二是忍着性子等一段时间(不知多久,大概1天吧,不过IP一般而言3天后就变了)后再请求。
目前遇到的问题就这么多,有问题可以留言,我有空可以解决。
选做
在P站爬取自己喜欢的漫画的图片。
这期的文章终于写完了!我可能写完这个文章后就要“隐居”一段时间了,因为我要全身心投入中考复习了。现在中考时间还没通知要推迟。原本我今天就在学校了,但因为国外输入疫情,开学时间又不得不推迟到月底。
开学时间的推迟简直是对毕业生的一种煎熬!但没办法!哎!
最后祝愿这届毕业生身体健康、学业进步!
也希望各位在Python学习之路顺利度过、收获颇多!
