ESRGAN:增强型超分辨率生成对抗网络(Enhanced Super-Resolution Generative Adversarial Networks)论文笔记
ESRGAN:增强型超分辨率生成对抗网络
论文原文:https://arxiv.org/abs/1809.00219
摘要:
超分辨率生成对抗网络(SRGAN)[1]是能够在单幅图像超分辨率期间生成真实感纹理的一项重要工作。然而,幻觉的细节往往伴随着令人不快的伪影。为了进一步提高视觉质量,我们深入研究了SRGAN网络体系结构的三个关键组成部分:对抗损失和感知损失,并对其中的每一个进行了改进,得到了一个增强的SRGAN(ESRGAN)。特别地,我们将残差密集块(RRDB)中的残差作为基本的网络构建单元而不进行批量归一化。此外,我们借用相对论GAN[2]的思想,让判别器预测相对真实性而不是绝对值。最后,利用激活前的特征改善感知损失,为亮度一致性和纹理恢复提供更强的监控。基于这些改进,提出的ESRGAN比SRGAN在更逼真、更自然的纹理上获得了更好的视觉质量,并且赢得了PIRM2018-SR挑战1[3]中的第一名。代码在:https://github.com/xinntao/ESRGAN.
1 介绍
单幅图像超分辨率作为一个基础的低层视觉问题,吸引着研究社区和AI公司的注意。SISR其目的在于从单幅低分辨率(LR)图像恢复成高分辨率(HR)图像。自从先驱性的SRCNN被Dong et al.[4]提出,深度卷积神经网(CNN)取得了快速发展。不断有各种网络结构设计和训练策略被提出,提高SR性能,尤其是Peak Signal-to-Noise Ratio(PSNR)[5,6,1,8,9,10,11,12]。然而,PSNR倾向于在没有足够多细节的情况下输出过平滑的结果,因为PSNR度量从根本上不同于人类视觉的主观评价[1]。

有几种感知型驱动方法被提出,来提高SR结果的视觉质量。例如,感知损失[13,14]被提出来优化超分辨率模型在特征空间而不是在像素空间。生成对抗网络[15]由[1,16]引入SR,以鼓励网络支持看起来更像自然图像的解决方案。进一步结合语义图像先验来改进恢复的纹理细节[17]。SRGAN[1]是追求视觉体验发展中的一个里程碑。其在GAN网络使用残差块和感知损失优化来构建基础模型。通过所有这些技术,SRGAN显著提高了基于PSNR的方法重建的整体视觉质量。
然而,SRGAN的结果与真实图像之间仍然存在明显的差异,如图1所示。在我们的研究中,我们重新审视SRGAN的关键组成部分,并且从三个方面提升这个模型。首先,我们通过引入密集残差块(RDDB)来提升模型的结构,使之具有更大的容量和更易于训练。我们去除了批量归一化(BN)[19]层在[20],使用了残差缩放(residual scaling)[21,20],并且初始化较小来促进训练一个深网络。第二,我们提出了辨别器使用相对平均GAN(RaGAN)[2],相对平均GAN学习判断“是否一个图像相比于另一个更真实”而不是“是否一个图像是真或假”。我们的实验展示了,这个改进有助于生成器恢复更真实的纹理细节。第三,我们在SRGAN提出了一个改进,即感知损失,通过在VGG特征前激活,而不是在VGG特征之前激活。根据经验,我们发现调整后的感知损失提供了清晰的边缘和更具有视觉体验的结果,如4.4节所示。大量的实验表明,增强型SRGAN,称之为ESRGAN,在锐度和细节上始终优于最先进的方法(见图1和图7)。
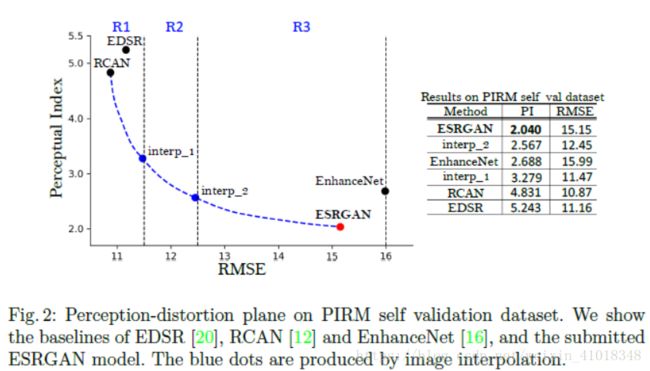
我们用ESRGAN的一个变体参加PIRM-SR挑战赛。这个挑战赛是第一SR竞赛,它是基于[22]在一个感知质量意识方法中评估性能,在那里作者称失真和感知质量是相互矛盾的。感知质量是通过non-reference measures of Ma's score[23]和NIQE[24]来判断的。感知指数为![]() 。一个较低的感知指数代表一个较好的感知质量。
。一个较低的感知指数代表一个较好的感知质量。
如图2所示,感知失真平面被Root-Mean-Square Error(RMSE)的阈值分成了三个区域,根据运算法则得,每个区域的最低感知指数成为该区域的最优。我们着重于区域3,我们的目的是为感知质量提升到一个新的高度。由于上述的改进和其它的调整(在4.6节讨论),我们凭借最优的感知指数赢得了PIRM-SR挑战赛(区域3)的冠军。
为了平衡视觉质量和RMSE/PSNR,我们进一步提出了网络插值策略,这个策略能连续调整结构形式和光滑度。另一个插值方式为图像插值,即直接在图像像素与像素之间进行插值。我们采用这个策略参与了区域1和区域2。网络插值和图像插值与它们之间的差异将在3.4节讨论。
2 准备工作
我们着眼于用深度神经网络来解决SR问题。其先驱为,Dong et al.[4,25]提出的SRCNN,学习映射,使用从LR到HR图像、端到端的方式,相比于之前取得了较好的表现。后来,该领域出现了各种网络体系结构,例如具有残差学习的深层网络[5]、拉普拉斯金字塔结构[6]、残差块[1]、递归学习[7,8]、密集连接网络[9]、深背投影[10]和残差密集网络[11]。特别是,Lim et al.[20]提出的EDSR模型,通过在残差块中去除了不必要的BN层,并且扩展了该模型的大小,该模型取得了显著的性能。Zhang et al.[11]提出了在SR使用有效残差密集块,并且他们进一步探索了深度网络中的注意力通道,实现了最先进的PSNR性能。除了监督学习外,其它的方法像增强学习和无监督学习也被用来解决生成图像恢复问题。
几种方法已经被提出,稳定训练一个非常深的模型。例如,残差路径被发展来稳定训练和提升性能[18,5,12]。残差缩放第一次被使用,Szegedy et al.[21],并且使用在了EDSR。通常的深度网络,He et al.[28]针对VGG-style网络提出鲁棒初始化算法,并且去除了BN。为了促进训练一个深层网络,我们研究一个紧凑有效的残差密集块,能够帮助我们提升感知质量。
感知驱动算法也已经被提出,用来为SR的结果提高视觉质量。基于接近感知相似性的思想[29,14],感知损失被提出,通过在特征空间而不是像素空间,最小化误差,来提升视觉质量。情境损失(contextual loss)[30]被开发成通过使用关注特征分布而不是仅仅比较外观的目标来生成具有自然图像统计的图像。Ledig et al.[1]提出SRGAN模型,使用感知损失和对抗损失来支持多图像上的输出。Sajjadi et al.[16]开发一种相似的方法并且进一步探索了局部纹理匹配损失。基于这些工作,Wang et al.[17]提出了空间特征变换,有效地将图像语义先验结合在一起,提高了恢复纹理。
在文献中,照相现实主义(photo-realism)经常被实现,通过与GAN进行对抗训练。最近有个分支工作,着眼于开发更有效的GAN网络。WGAN[31]提出了最小化WaSersin距离的合理和有效近似,并通过权值剪裁来正则化判别器。其它的提升正则化判别器有梯度剪裁和谱的归一化(spectral normalization)。相对判别器的开发不仅增大了生成数据真实性的可能性,还同时减少了真实数据为真实的可能性。在我们的工作中,我们通过应用一个更有效的相对平均GAN来增强SRGAN。
SR算法通常通过几种广泛使用的失真度量来评估,e.g.,PSNR和SSIM。然而,这些度量从根本上就不符人类视觉的主管评估。非参照性度量用于感知质量评估,包括Ma's score[23]和NIQE[24],两者都是用于计算感知指数在PIRM-SR挑战赛。在最近的研究中,Blau et al.[22]发现失真与感知质量是相互矛盾的。
3 算法提出
我们的主要目标是提高SR的总体感知质量。在这部分,我们首先描述我们提出的网络结构,然后讨论判别器和感知损失的改进。最后,我们描述为了平衡感知质量和PSNR的网络插值策略。

3.1 网络结构
为了进一步提高SRGAN恢复图像质量,我们主要为生成器G的结构做了两个改进:1)去除掉所有的BN层。2)提出用残差密集块(RRDB)代替原始基础块,其结合了多层残差网络和密集连接,如图4所示
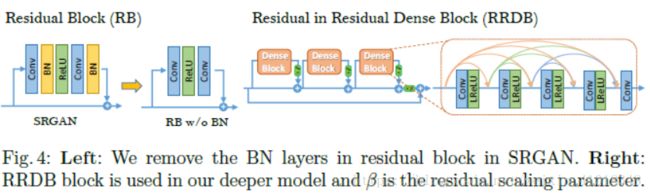
去除BN层已经被证明有助于增强性能和减少计算复杂度在不同的PSNR-oriented任务,包括SR[20]和去模糊[35]。BN层在训练期间使用批次的均值和方差对特征进行归一化,在测试期间使用整个训练数据集的估计均值和方差。当训练和测试数据集的统计数据差异很大时,BN层往往引入不适的伪影,限制了泛化能力。我们以经验观察到,BN层有可能当网络深和在GAN网络下训练时带来伪影。这些伪影偶尔出现在迭代和不同设置之间,违反了稳定性能超过训练的需求。因此,我们为了训练稳定和一致性去除了BN层。此外,去除BN层有助于提高泛化能力,减少计算复杂度和内存使用。
我们保持SRGAN的高级架构设计(参见图3),并使用如图4所示的新的基本块即RRDB。根据观察,更多的层和连接总是能提高性能[20,11,12],所提出的RRDB采用比SRGAN原始残差块更深层和更复杂的结构。特别的是,如图4所示,所提出了RRDB拥有residual-in-residual结构,残差学习用于不同的层。相似的网络结构在[36]被提出,同样也用了多层残差网络。然而,我们的RRDB不同于[36],我们在主要路径中[11]使用了密集块[34],其中网络容量从密集连接变得更高。
为了提升结构,我们也探索了几种方法来促进训练一个非常深的网络:1)残差缩放[21,20],i.e.,将残差乘以0和1之间的常数,然后将它们添加到主路径以防止不稳定。2)较小初始化,我们经验发现,当初始参数方差变小时,残差结构更容易训练。更多的讨论在supplementary material。
训练的细节和网络的有效性在第4节。
3.2 相对判别器
除了改进生成器的结构,我们还增强了判别器,基于相对GAN[2]。不同于SRGAN标准的判别器D,估算一个输入图像 真实和自然的可能性,如图5所示,相对判别器试图预测真实图像
真实和自然的可能性,如图5所示,相对判别器试图预测真实图像 比假图像
比假图像![]() 更真实的概率。
更真实的概率。

特别地,我们用相对论平均判别器RaD代替标准判别器,表示为![]() 。标准判别器在SRGAN可以表示为
。标准判别器在SRGAN可以表示为![]() ,其中
,其中 是sigmoid函数,
是sigmoid函数,![]() 是非变换判别器输出。RaD可以用公式表示为
是非变换判别器输出。RaD可以用公式表示为![]() ,其中
,其中![]() 表示在mini批处理中对所有假数据取平均值的操作。判别器损失可以定义为:
表示在mini批处理中对所有假数据取平均值的操作。判别器损失可以定义为:
![]()
生成器的对抗损失是以一种对称的形式:
![]()
其中![]() 和
和 代表LR图像输入。生成器的对抗损失包含了和
代表LR图像输入。生成器的对抗损失包含了和![]() 。因此,我们的生成器优势适合于对抗训练中生成的数据和实际数据的渐变,而在SRGAN中,只有生成的部分生效。在4.4节中,我们展示判别器模态化帮助学习更清晰的边缘和更细腻的纹理。
。因此,我们的生成器优势适合于对抗训练中生成的数据和实际数据的渐变,而在SRGAN中,只有生成的部分生效。在4.4节中,我们展示判别器模态化帮助学习更清晰的边缘和更细腻的纹理。
3.3 感知损失
我们也开发了一种更有效的感知损失![]() ,在SRGAN通过激活前约束特征而不是激活后。
,在SRGAN通过激活前约束特征而不是激活后。
与这个想法相近的感知相似[29,14],Johnson et al.[13]提出感知损失并且在SRGAN中扩展。感知损失先前定义在预先训练的深层网络的激活层上,其中两个激活特征之间的距离被最小化。与常规相反,我们提出在激活层之前使用特性,这将克服原始设计的两个缺点。第一,被激活的特征是非常稀疏的,特别是在非常深的网络之后,如图6所示。例如,图像“baboon”激活神经元的平均百分率在VGG19-54层后仅为11.17%(我们使用预先训练的19层VGG网络[37],其中54表示![]() 最大池化层之前通过
最大池化层之前通过![]() 卷积获得的特征,表示高级特征,类似地,22表示低级特征)。稀疏激活提供弱的监督,从而导致性能较差。第二,使用激活后的特征也会造成重建后的图像亮度与真实图像不一致,这点我们将在4.4节展示。
卷积获得的特征,表示高级特征,类似地,22表示低级特征)。稀疏激活提供弱的监督,从而导致性能较差。第二,使用激活后的特征也会造成重建后的图像亮度与真实图像不一致,这点我们将在4.4节展示。
因此,生成器完整的损失可以表示为:
![]()
其中 是评估恢复图像
是评估恢复图像 和真实图像
和真实图像 之间的1-范数距离内容损失,
之间的1-范数距离内容损失, 、
、 是平衡不同损失项的系数。
是平衡不同损失项的系数。
我们也探索了一种感知损失的变体在PIRM-SR挑战赛中。与常用的采用VGG网络进行图像经典训练的感知损失相比,我们提出了一种更适合于SR-MINC损耗的感知损失。这个是基于材料恢复VGG网络模型进行微调,其着眼于纹理而不是目标物体。虽然MINC损失带来的感知指标的增益是微乎其微的,但我们仍然认为探索以纹理为中心的感知损失对于SR是至关重要的。

3.4 网络插值
为了去掉在GAN-based 方法中令人不愉快的噪声,同时保证好的感知质量,我们提出一个灵活有效的策略,即网络插值。特别的是,我首先训练一个PSNR-oriented网络![]() ,然后通过微调GAN-based网络获得
,然后通过微调GAN-based网络获得![]() 。我们对这两个网络的所有相应参数进行插值,得到一个插值模型
。我们对这两个网络的所有相应参数进行插值,得到一个插值模型![]() ,其参数可以表示为:
,其参数可以表示为:
![]()
其中![]() ,
,![]() 和
和![]() 是
是![]() ,
,![]() 和
和![]() 的参数;
的参数;![]() 是插值参数。
是插值参数。
网络插值有两个优点。第一,首先,插值模型能够在不引入伪影的情况下对任何可行的 产生有意义的结果。第二,我们可以在不重新训练模型的情况下,持续地平衡感知质量和感觉。
产生有意义的结果。第二,我们可以在不重新训练模型的情况下,持续地平衡感知质量和感觉。
我们还探索替代的方法来平衡PSNR为导向和基于GAN的方法的影响。例如,一个可以直接对图像输出进行插值(像素到像素)而不是网络插值。然而,这样的方法无法在噪声和模糊之间实现良好的权衡,i.e.,插值图像要么太模糊,要么带有噪声(见4.5节)。其它方法是为内容损失和对抗损失调整权值,i.e.,参数 和在公式(3)。但是这种方法需要调整损失权重并微调网络,因此实现图像样式的连续控制成本太高。
和在公式(3)。但是这种方法需要调整损失权重并微调网络,因此实现图像样式的连续控制成本太高。
4 实验
4.1 训练细节