互联网面试问题以及答案20200508
1.介绍一下项目(1-6)。(之后提问跟回答密切相关)
2.项目中提到spark streaming和spark,具体介绍一下技术
3.spark中常见算子,哪些算子会导致shuffle,groupbykey和reducebykey的区别
4.spark streaming容错这里卡了,跟面试官扯了扯hadoop容错
5.HBASE rowkey怎么设计的,以及项目中rowkey相关的问题扯了挺久
6.HBASE中数据读的过程,HBASE为什么快。
java:
7.java中线程安全和线程不安全的集合
|
|
线程安全 |
非线程安全 |
| Collection |
Vector |
ArrayList、LinkedList |
|
|
HashSet、TreeSet |
|
| Map |
HashTable currenthashmap |
HashMap、TreeMap |
| 字符串 |
StringBuffer |
StringBuilder |
8.线程同步的具体方法,知道的方式都说说。
1同步方法,有synchronized关键字修饰的方法。 由于java的每个对象都有一个内置锁,当用此关键字修饰方法时, 内置锁会保护整个方法。在调用该方法前,需要获得内置锁,否则就处于阻塞状态。synchronized关键字也可以修饰静态方法,此时如果调用该静态方法,将会锁住整个类。
2同步代码块:即有synchronized关键字修饰的语句块。 被该关键字修饰的语句块会自动被加上内置锁,从而实现同步。 注:同步是一种高开销的操作,因此应该尽量减少同步的内容。通常没有必要同步整个方法,使用synchronized代码块同步关键代码即可。
3使用局部变量实现线程同步。如果使用ThreadLocal管理变量,则每一个使用该变量的线程都获得该变量的副本,副本之间相互独立,这样每一个线程都可以随意修改自己的变量副本,而不会对其他线程产生影响。
4使用特殊域变量(volatile)实现线程同步
a.volatile关键字为域变量的访问提供了一种免锁机制
b.使用volatile修饰域相当于告诉虚拟机该域可能会被其他线程更新
c.因此每次使用该域就要重新计算,而不是使用寄存器中的值
d.volatile不会提供任何原子操作,它也不能用来修饰final类型的变量
5在java中新增了一个java.util.concurrent包来支持同步。
ReentrantLock类是可重入、互斥、实现了Lock接口的锁,它与使用synchronized方法和快具有相同的基本行为和语义,并且扩展了其能力。
6wait与notify关键字的来控制线程的同步。
7使用阻塞队列实现线程同步,前面5种同步方式都是在底层实现的线程同步,
8使用原子变量实现线程同步。在java的util.concurrent.atomic包中提供了创建了原子类型变量的工具类,使用该类可以简化线程同步。
算法:9. 5G的文件排序,内存只有1G,追问 归并排序怎么实现?
将5G 数据,按照 100M 内存拆分,然后排序有序的数据,然后写入到 file1,file2…file100。传统的排序算法一般指内排序算法,针对的是数据可以一次全部载入内存中的情况。但是面对海量数据,即数据不可能一次全部载入内存,需要用到外排序的方法。外排序采用分块的方法(分而治之),首先将数据分块,对块内数据按选择一种高效的内排序策略进行排序。然后采用归并排序的思想对于所有的块进行排序,得到所有数据的一个有序序列。
10. 两数之和,追问:三数之和,三数之和回答了快排+双指针,面试官要求优化,没优化出来。
2.yarn调度原理,如何实现高可用
3.zookeeper怎么实现高可用:
4.数据结构有什么用,具体到二叉树有什么用,java中哪些地方用到了二叉树。
数据库的存储,数据的算法的提高,算法的复杂度和空间复杂度的要求。
数据的查找利用到二分查找树 ,在hashmap中的利用的是的红黑树的来存储链表的节点大于8个的时候。等
二叉树的应用的场景:
哈夫曼编码,来源于哈夫曼树,在数据压缩上有重要应用,提高了传输的有效性,详见《信息论与编码》。
海量数据并发查询,二叉树复杂度是O(K+LgN)。二叉排序树就既有链表的好处,也有数组的好处, 在处理大批量的动态的数据是比较有用。
C++ STL中的set/multiset、map,以及Linux虚拟内存的管理,都是通过红黑树去实现的。查找最大(最小)的k个数,红黑树,红黑树中查找/删除/插入,都只需要O(logk)。
B-Tree,B+-Tree在文件系统中的目录应用。
路由器中的路由搜索引擎。
1. 介绍实验室cv算法项目,聊javaweb项目,负责的工作,项目需求功能
2. 权限管理模块的实现(这个地方还跟面试官argue一段时间,最终还是败下阵来)
3. 项目一些数据库表是如何设计的,有哪些字段
4. 项目的困难,如何克服 (至此40min过去了)
遇见的困难:1 没有接触微服务,springboot的相关的知识,先关的一些实际的商用软件开发没有接触过。2 以前写代码的时候没有空滤过代码的性能问题和优化的问题。3没有实际的接触过数据库的与优化问题。
解决方法:1自己下班的时间补习微服务和springboot的高级的相关的知识。自己在下班后练习一些小项目的,来补充微服务的这个知识。慢慢的接触到了微服务的springboot的相关的知识和一些高级的中间件的使用。解除了redis、MQ springboot……等相关的知识。2在自己做代码的测试的时候有意的看看程序的时间复杂度和空间复杂度,并在课后不断的刷题和学习相关的数据结构的和算法的相关的知识。3不断的学习深入的数据库的表的设计字段的优化,索引的优化操作,分库分表的优化,集群的搭建的相关操作,优化是数据的读写分离们相关操作。
5. spring中拦截器与过滤器的区别
过滤器:依赖于servlet容器。在实现上基于函数回调,可以对几乎所有请求进行过滤,但是缺点是一个过滤器实例只能在容器初始化时调用一次。使用过滤器的目的是用来做一些过滤操作,获取我们想要获取的数据,比如:在过滤器中修改字符编码;在过滤器中修改HttpServletRequest的一些参数,包括:过滤低俗文字、危险字符等。在一个请求到达Controller之前能够截获其请求,并且根据其具体情况对 HttpServletRequest 中的参数进行过滤或者修改。
如何在Filter中修改后台Controller中获取到的HttpServletRequest中的参数?只需要在Filter中自定义一个类继承于HttpServlet RequestWrapper,并复写getParameterNames、getParameter、getParameterValues等方法即可。
import java.io.IOException;
import java.util.Enumeration;
import java.util.Map;
import java.util.Vector;
import javax.servlet.FilterChain;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletRequestWrapper;
import javax.servlet.http.HttpServletResponse;
import org.springframework.web.filter.OncePerRequestFilter;
public class ModifyParametersFilter extends OncePerRequestFilter {
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain)
throws ServletException, IOException {
ModifyParametersWrapper mParametersWrapper = new ModifyParametersWrapper(request);
filterChain.doFilter(mParametersWrapper, response);
}
/**
* 继承HttpServletRequestWrapper,创建装饰类,以达到修改HttpServletRequest参数的目的
*/
private class ModifyParametersWrapper extends HttpServletRequestWrapper {
private Map parameterMap; // 所有参数的Map集合
public ModifyParametersWrapper(HttpServletRequest request) {
super(request);
parameterMap = request.getParameterMap();
}
// 重写几个HttpServletRequestWrapper中的方法
/**
* 获取所有参数名
*
* @return 返回所有参数名
*/
@Override
public Enumeration getParameterNames() {
Vector vector = new Vector(parameterMap.keySet());
return vector.elements();
}
/**
* 获取指定参数名的值,如果有重复的参数名,则返回第一个的值 接收一般变量 ,如text类型
*
* @param name
* 指定参数名
* @return 指定参数名的值
*/
@Override
public String getParameter(String name) {
String[] results = parameterMap.get(name);
if (results == null || results.length <= 0)
return null;
else {
System.out.println("修改之前: " + results[0]);
return modify(results[0]);
}
}
/**
* 获取指定参数名的所有值的数组,如:checkbox的所有数据
* 接收数组变量 ,如checkobx类型
*/
@Override
public String[] getParameterValues(String name) {
String[] results = parameterMap.get(name);
if (results == null || results.length <= 0)
return null;
else {
int length = results.length;
for (int i = 0; i < length; i++) {
System.out.println("修改之前2: " + results[i]);
results[i] = modify(results[i]);
}
return results;
}
}
/**
* 自定义的一个简单修改原参数的方法,即:给原来的参数值前面添加了一个修改标志的字符串
*
* @param string
* 原参数值
* @return 修改之后的值
*/
private String modify(String string) {
return "Modified: " + string;
}
}
}
ModifyParametersFilter
cn.zifangsky.filter.ModifyParametersFilter
ModifyParametersFilter
/param/*
REQUEST
FORWARD
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
@Controller
public class TestModifyController {
@RequestMapping("/param/modify.html")
public void modify(@RequestParam("name") String name){
System.out.println("修改之后: " + name);
}
}修改之前2: abc
修改之后: Modified: abc这就表明了我们前面自定义的过滤器已经将HttpServletRequest中原来的参数成功修改了。同时,还说明SpringMVC的@RequestParam注解本质上调用的是ServletRequest中的 getParameterValues(String name) 方法而不是 getParameter(String name) 方法。
拦截器:只能实现对controller的请求进行拦截。对于一些静态的资源的访问是没有办法的进行来拦截。
依赖于web框架,在SpringMVC中就是依赖于SpringMVC框架。在实现上基于java的反射机制,属于面向切面编程(AOP)的一种运用。由于拦截器是基于web框架的调用,因此可以使用Spring的依赖注入(DI)进行一些业务操作,同时一个拦截器实例在一个controller生命周期之内可以多次调用。但是缺点是只能对controller请求进行拦截,对其他的一些比如直接访问静态资源的请求则没办法进行拦截处理。
但是我们是否思考过:如果一个项目中有多个拦截器或者过滤器,那么它们的执行顺序应该是什么样的?或者再复杂点,一个项目中既有多个拦截器,又有多个过滤器,这时它们的执行顺序又是什么样的呢?
答案:这就说明了过滤器的运行是依赖于servlet容器的,跟springmvc等框架并没有关系。并且,多个过滤器的执行顺序跟xml文件中定义的先后关系有关。对于过个拦截器它们之间的执行顺序跟在SpringMVC的配置文件中定义的先后顺序有关。
SpringMVC拦截器配置后,主要对三个过程进行拦截校验:
方法执行前(有boolean返回值,返回true则放行)【Hanler执行之前】
方法执行后【Handler执行之后,ModelAndView返回之前】
页面渲染后【ModelAndView执行之后,对异常处理】
如有两个拦截器
方法执行前返回值都为true,则顺序如下
方法执行前1
方法执行前2
方法执行后2
方法执行后1
页面渲染后2
页面渲染后1
方法1和方法2是相对的,取决于springmvc自定义拦截器类配置的先后顺序(这里是自定义拦截器1先于拦截器2)
总结起来: 拦截器1中的方法执行前1先执行,后执行拦截器2中的方法执行前2方法,后拦截器2的方法先于拦截器1的方法执行
(2)拦截器1中方法执行前1 返回值为false,而拦截器2中方法执行前2返回值为 true 执行顺序如下:
方法执行前1 //此时被拦截,不放行
总结起来:只执行拦截器1方法执行前的方法,当拦截器1方法执行前被拦截,返回值为false不被放行,后面的拦截器链都不执行,无论2的返回值是true还是false
(3)拦截器1中方法执行前1 返回值为true,而拦截器2中方法执行前2返回值为 false 执行顺序如下:
方法执行前1
方法执行前2 //被拦截,不放行
页面渲染后1
总结顺序:
preHandle按拦截器定义顺序调用
postHandler按拦截器定义逆序调用
afterCompletion按拦截器定义逆序调用
postHandler在拦截器链内所有拦截器返成功调用
afterCompletion只有preHandle返回true才调用
6. spring面向切面编程AOP
在传统的架构中都是垂直的流程体系。但是在这个过程中经常产生一些横向问题,比如log日志记录,权限验证,事务处理,性能检查的问题,为了遵循软件的开闭原则。就是对原来不修改进而扩展原方法和原类的功能。SpringAOP就是实现了这样一种思想。通过对原方法和类在不修改代码的情况下而进行了类的增强的方式。主要是通过使用的动态代理技术来实现。
7. spring依赖反转DI,有什么好处
SpringIOC 是spring提供对类的全生命周期的一个管理,通过利用springIOC容器来实现bean的实例化创建和销毁。IOC容器获取对象是程序在加载xml配置文件时通过反射调用构造函数来创建对象(我们开始学就是在xml里配置的)。其中的这个SpringIOC中的最为关键的是Bean的创建一个实例化过程。这个是实例化过程大致是将首先将JVM将.java文件加载到jvm内存中。然后Spring中的Beandefintion分解得到一个map的键值表的关系在通过preinstancesingletons的方法来map中的信息放入spring单例池中得到一个类的bean对象。然后在通过getBean方法来获得对象实例化的对象。这个是spring在不在外界是可以产生bean的对象。但是spring也提供一个BeanFactorProcess函数允许程序员一起来建Bean工厂,来实现对产生Bean的是实例化。
8. @autowired 与@resource的区别
@Autowired为Spring提供的注解,需要导入包org.springframework.beans.factory.annotation.Autowired。@Autowired采取的策略为按照类型注入。
public class UserService {
@Autowired
private UserDao userDao;
}
如上代码所示,这样装配回去spring容器中找到类型为UserDao的类,然后将其注入进来。这样会产生一个问题,当一个类型有多个bean值的时候,会造成无法选择具体注入哪一个的情况,这个时候我们需要配合着@Qualifier使用。
public class UserService {
@Autowired
@Qualifier(name="userDao1")
private UserDao userDao;
}
@Resource注解由J2EE提供,需要导入包javax.annotation.Resource。@Resource默认按照ByName自动注入。
public class UserService {
@Resource
private UserDao userDao;
@Resource(name="studentDao")
private StudentDao studentDao;
@Resource(type="TeacherDao")
private TeacherDao teacherDao;
@Resource(name="manDao",type="ManDao")
private ManDao manDao;
} ①如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常。
②如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常。
③如果指定了type,则从上下文中找到类似匹配的唯一bean进行装配,找不到或是找到多个,都会抛出异常。
④如果既没有指定name,又没有指定type,则自动按照byName方式进行装配;如果没有匹配,则回退为一个原始类型进行匹配,如果匹配则自动装配。
Spring属于第三方的,J2EE是Java自己的东西。使用@Resource可以减少代码和Spring之间的耦合。两者都可以写在字段和setter方法上。两者如果都写在字段上,那么就不需要再写setter方法。当存在多个类型,却又没有指定的时候,会报如下的错误:
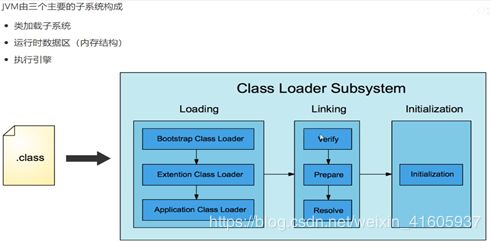
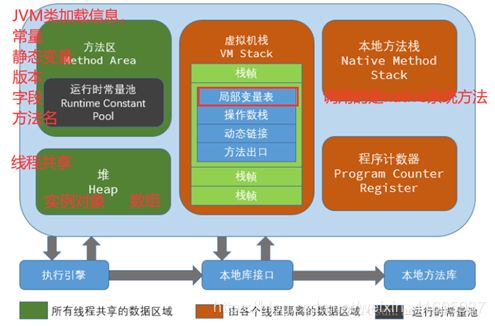
9. JVM了解?

10. mysql事务,隔离级别?
一个事务本质上有四个特点ACID:原子性、一致性、隔离性、持久性
一般的数据库,都包括以下四种隔离级别:读未提交,读已提交、可重复度,串行化
读未提交(Read Uncommitted)
读未提交,顾名思义,就是可以读到未提交的内容。因此,在这种隔离级别下,查询是不会加锁的,也由于查询的不加锁,所以这种隔离级别的一致性是最差的,可能会产生“脏读”、“不可重复读”、“幻读”。如无特殊情况,基本是不会使用这种隔离级别的。
读提交(Read Committed)
这是各种系统中最常用的一种隔离级别,也是SQL Server和Oracle的默认隔离级别。这种隔离级别能够有效的避免脏读,但除非在查询中显示的加锁,如:
select * from T where ID=2 lock in share mode;
select * from T where ID=2 for update;
不然,普通的查询是不会加锁的。
那为什么“读提交”同“读未提交”一样,都没有查询加锁,但是却能够避免脏读呢?这就要说道另一个机制“快照(snapshot)”,而这种既能保证一致性又不加锁的读也被称为“快照读(Snapshot Read)
可重复读(Repeated Read)
就是专门针对“不可重复读”这种情况而制定的隔离级别,自然,它就可以有效的避免“不可重复读”。而它也是MySql的默认隔离级别。在这个级别下,普通的查询同样是使用的“快照读”,但是,和“读提交”不同的是,当事务启动时,就不允许进行“修改操作(Update)”了,而“不可重复读”恰恰是因为两次读取之间进行了数据的修改,因此,“可重复读”能够有效的避免“不可重复读”,但却避免不了“幻读”,因为幻读是由于“插入或者删除操作(Insert or Delete)”而产生的。
串行化(Serializable)
这种级别下,“脏读”、“不可重复读”、“幻读”都可以被避免,但是执行效率奇差,性能开销也最大,所以基本没人会用。
11. 网络七层协议,每一层有哪些协议?
物理层 数据链路层 网路层 传输层 表现层 会话层 应用层
12. java的线程池用过吗?
1线程池的作用2 线程池的基本参数 3 线程的缓存队列 4 线程池的拒绝策略,5线程的关闭方式。
13. 讲一下平衡二叉树?
平衡二叉树(AVL树)在符合二叉查找树的条件下,还满足任何节点的两个子树的高度最大差为1。
这四种失去平衡的姿态都有各自的定义:
LL:LeftLeft,也称“左左”。插入或删除一个节点后,根节点的左孩子(Left Child)的左孩子(Left Child)还有非空节点,导致根节点的左子树高度比右子树高度高2,AVL树失去平衡。
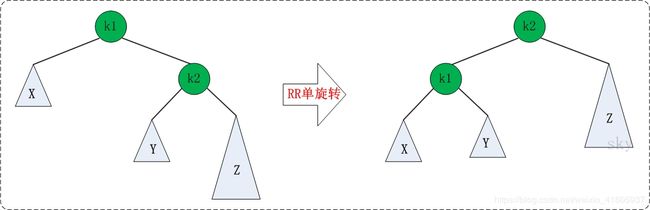
RR:RightRight,也称“右右”。插入或删除一个节点后,根节点的右孩子(Right Child)的右孩子(Right Child)还有非空节点,导致根节点的右子树高度比左子树高度高2,AVL树失去平衡。
LR:LeftRight,也称“左右”。插入或删除一个节点后,根节点的左孩子(Left Child)的右孩子(Right Child)还有非空节点,导致根节点的左子树高度比右子树高度高2,AVL树失去平衡。
RL:RightLeft,也称“右左”。插入或删除一个节点后,根节点的右孩子(Right Child)的左孩子(Left Child)还有非空节点,导致根节点的右子树高度比左子树高度高2,AVL树失去平衡。
AVL树失去平衡之后,可以通过旋转使其恢复平衡。下面分别介绍四种失去平衡的情况下对应的旋转方法。
LL的旋转。LL失去平衡的情况下,可以通过一次旋转让AVL树恢复平衡。步骤如下:
将根节点的左孩子作为新根节点。
将新根节点的右孩子作为原根节点的左孩子。
将原根节点作为新根节点的右孩子。

RR的旋转:RR失去平衡的情况下,旋转方法与LL旋转对称,步骤如下:
将根节点的右孩子作为新根节点。
将新根节点的左孩子作为原根节点的右孩子。
将原根节点作为新根节点的左孩子。
LR的旋转:LR失去平衡的情况下,需要进行两次旋转,步骤如下:
围绕根节点的左孩子进行RR旋转。
围绕根节点进行LL旋转。

RL的旋转:RL失去平衡的情况下也需要进行两次旋转,旋转方法与LR旋转对称,步骤如下:
围绕根节点的右孩子进行LL旋转。
围绕根节点进行RR旋转。

14. 为什么面工程不面算法
15. 反问哪些不足。
1)java方面需加强,如类加载器,容器,JVM,线程池,NIO,BIO,缓存,中间件;(非常nice,后面有用到,重点!)
2)项目中当流量放大的时候该如何设计,重构;
二面,电话面,约40min
1. 聊javaweb项目,然后突然被问到微信小程序怎么做;(项目我个人负责web端开发,另一个老师负责微信小程序开发)
2. 工作当中有没有碰到一些问题
3. 本科成绩是多少,前十名都去了哪
4. 读研究生对你的成长是什么
5. 除了科研之外,现在在学习哪些新知识
6. 后台开发常用的一些中间件介绍
redis MQ dubbo zookeeper
7. 又回到了javaweb项目,跟ERP系统对接有哪些功能接口(这也是另一个老师负责的工作)
8. 项目中RPC的交互用什么技术做的,为啥用HTTP协议来做,你觉得还可以用什么方法来做
9. 开源的RPC框架有什么好处?有哪些框架,dubbo的协议
10. 嘴贱提了一句dubbo的协议跟http的RESTful风格是不一样的,被反问你确定你们用的是RESTful嘛(卒)
11. 又突然跳到了实验室cv算法项目,它的应用场景是什么样的。
12. 十分犀利,你这个算法准嘛?你的算法的优势是什么?
13. 你认为我们国家智能驾驶处于什么阶段,什么时候能够上路
14. 又突然毫无防备的跳到了另一个问题,抖音用过吗?你觉得它做的好在哪里?(讲推荐,讲交互,被打断)
15. 你觉得抖音的推荐会用到哪些算法来做(没了解过,逼逼了一周编不下去了)
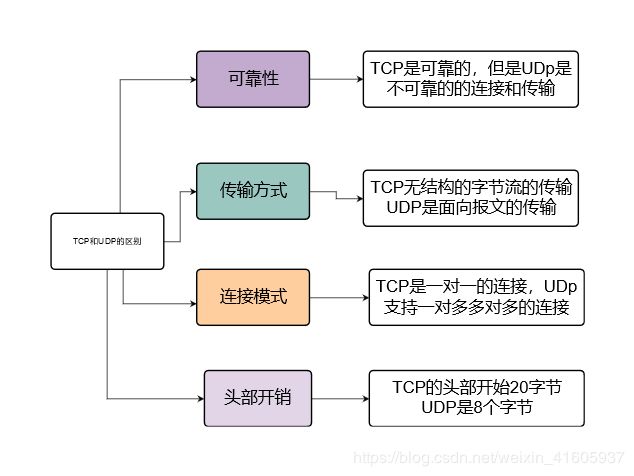
16. tcp与udp区别,微信发文件用什么协议,为什么?
17. 个人的优点缺点是什么?
18. 你觉得你是天赋多一点还是勤奋多一点?天赋为什么会觉得少一点?
19. 你认识的同学有没有投阿里,没有那种没有阿里的嘛
20. 反问评价:好奇心要加强,为啥不去了解推荐算法呢?可能不能比他们做的更好,但应该要了解一些。
21. 然后又开始问问题,本科的比赛获奖的含金量
22. 那你没参加其他的一些比赛,研究生主要都在干嘛呢(当然是科研,论文呀。。。)
23. 专利的含金量的,论文的含金量,整个年级的发论文情况
面试体验比较差,经常被打断,经常沉默,经常来回跳,问的范围很发散,都是跟你有点相关但又不直接相关,很多问题回答的不太好。最后给的评价没有好奇心,,哎,可能了解技术面比较窄也没有表现出对技术的热情吧。
三面,电话面,约25min
1. 自我介绍
2. 如何学习新技术
3. 科研项目的背景,成果,自己做了哪些功能
4. 进程与线程
线程是执行的最小的单位,而进程是资源分配的最小的单位。 进程是资源分配的最小单位,线程是程序执行的最小单位。
区别是:
1.地址空间和其他资源(如打开文件):进程间相互独立,同一进程的各线程间共享。某进程内的线程在其他进程内不可见。
2.通信:进程间通信IPC(管道,信号量,共享内存,消息队列),线程间可以直接独写进程数据段(如全局变量)来进程通信—需要进程同步和互斥手段的辅助,以保证数据的一致性。
3.调度和切换:线程上下文切换比进程上下文切换快得多。
4.在多线程OS中,进程不是一个可执行的实体。
5. 进程间通信,同步机制,win下线程同步的API
线程同步的方法是:
1同步方法,有synchronized关键字修饰的方法。 由于java的每个对象都有一个内置锁,当用此关键字修饰方法时, 内置锁会保护整个方法。在调用该方法前,需要获得内置锁,否则就处于阻塞状态。synchronized关键字也可以修饰静态方法,此时如果调用该静态方法,将会锁住整个类。
2同步代码块:即有synchronized关键字修饰的语句块。 被该关键字修饰的语句块会自动被加上内置锁,从而实现同步。 注:同步是一种高开销的操作,因此应该尽量减少同步的内容。通常没有必要同步整个方法,使用synchronized代码块同步关键代码即可。
3使用局部变量实现线程同步。如果使用ThreadLocal管理变量,则每一个使用该变量的线程都获得该变量的副本,副本之间相互独立,这样每一个线程都可以随意修改自己的变量副本,而不会对其他线程产生影响。
4使用特殊域变量(volatile)实现线程同步
a.volatile关键字为域变量的访问提供了一种免锁机制
b.使用volatile修饰域相当于告诉虚拟机该域可能会被其他线程更新
c.因此每次使用该域就要重新计算,而不是使用寄存器中的值
d.volatile不会提供任何原子操作,它也不能用来修饰final类型的变量
5在java中新增了一个java.util.concurrent包来支持同步。
ReentrantLock类是可重入、互斥、实现了Lock接口的锁,它与使用synchronized方法和快具有相同的基本行为和语义,并且扩展了其能力。
6wait与notify关键字的来控制线程的同步。
7使用阻塞队列实现线程同步,前面5种同步方式都是在底层实现的线程同步,
8使用原子变量实现线程同步。在java的util.concurrent.atomic包中提供了创建了原子类型变量的工具类,使用该类可以简化线程同步。
6. socket编程有没有接触过,select epoll区别
7. java怎么学的,javaweb项目介绍
8. 有没有读过框架源码?
9. 反问部门工作以及前景(介绍的挺多的)
10. 反问评价:基础比较好,技术方面眼光比较窄,应该多去了解云部署相关的技术框架啥的。
然后赶紧接着他的话又自己陈述了一下自己情况以及今后的努力方向。稳妥
十分钟后通知三面过了,四面等了一周后进行的
四面,电话面,约30min
2. 介绍javaweb项目时直接被打断,甲方为啥要做这个平台?为啥不找工作室做找你们做?
3. 聊一下个人情况,本科专业,研究生专业,开设哪些课程,成绩,参加的比赛
4. 数据结构,一个字典找到最多的重复英文单词(应该是这个情景)
采用的是hasmap这样的的一个数据的结构来实现的。或者是两层循环的一种结构来实现。
5. 如何构建前缀树
6. 二叉树有哪些遍历方式,分别有哪些应用场景(回答的不好)
四中遍历:前中序、后序、层序遍历的四种遍历方式。用的最多的应该是平衡二叉树,有种特殊的平衡二叉树红黑树,查找、插入、删除的时间复杂度最坏为O(log n),Java集合中的TreeSet和TreeMap,C++ STL中的set、map,以及Linux虚拟内存的管理,都是通过红黑树去实现的。还有哈夫曼树编码方面的应用。B-Tree,B+-Tree在文件系统中的应用。
7. 情景题,杭州现有30个消防站,如今想再增加3个,如何规划。
我会考虑使用的是的knn的方法。来实现的最优化的问题实现。利用的每一个点的距离来实现的到达每一个点距离最短是最优化的一种方法。
8. hashmap底层实现,如何解决哈希冲突
JDK1.7中采用的是的数组+链表 JDK1.8采用的是是数组+链表+红黑树 JDK1.7中的出现的线程安全问题,就是在多线程的时候出现的是闭环死循环的情况。由于是采用的头插入的方法。改进后的是尾插入的方法。但是出现了数据丢失的情况。所以有currenthashmap类采用分段锁的机制来保证线程安全问题。但是效率比较低下在jdk1.8后采用的是CAS+Node+synchronize的这样的一种机制保证线程的安全的方式。
9. JVM内存分布,不同版本之间有区别吗,什么区别?哪些区可能发生内存溢出并举例
五个部分是;堆内存 栈内存 程序计数器 方法区 本地方法栈。
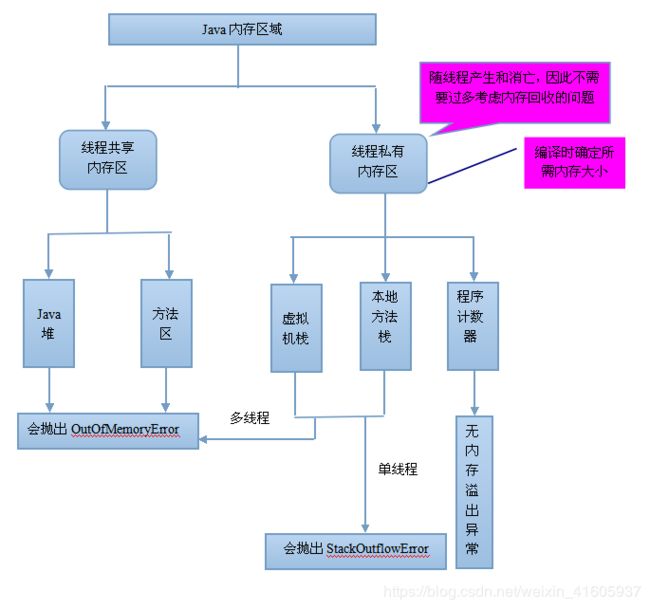
Java内存溢出的几种情况:1Java堆溢出(对象数量到达最大堆的容量限制后就会产生内存溢出异常。)2虚拟机栈和本地方法栈溢出。3.方法区和运行时常量池溢出4本机直接内存溢出,DirectMemory容量可通过-XX: MaxDirectMemorySize指定,如果不指定,则默认与Java堆最大值 (-Xmx指定)一样。
Java代码导致OutOfMemoryError错误的解决:
检查代码中是否有死循环或递归调用。
检查是否有大循环重复产生新对象实体。
检查对数据库查询中,是否有一次获得全部数据的查询。一般来说,如果一次取十万条记录到内存,就可能引起内存溢出。这个问题比较隐蔽,在上线前,数据库中数据较少,不容易出问题,上线后,数据库中数据多了,一次查询就有可能引起内存溢出。因此对于数据库查询尽量采用分页的方式查询。
检查List、MAP等集合对象是否有使用完后,未清除的问题。List、MAP等集合对象会始终存有对对象的引用,使得这些对象不能被GC回收。
解决java.lang.OutOfMemoryError的方法有如下几种:
增加jvm的内存大小。方法有:
1)在执行某个class文件时候,可以使用java -Xmx256M aa.class来设置运行aa.class时jvm所允许占用的最大内存为256M。
2)对tomcat容器,可以在启动时对jvm设置内存限度。对tomcat,可以在catalina.bat中添加
3)对resin容器,同样可以在启动时对jvm设置内存限度。在bin文件夹下创建一个startup.bat文件,
4)优化程序,释放垃圾。主要包括避免死循环,应该及时释放种资源。
内存泄漏和内存溢出:
内存溢出是指程序所需要的内存超出了系统所能分配的内存(包括动态扩展)的上限。
内存泄露是指分配出去的内存没有被回收回来,由于失去了对该内存区域的控制,因而造成了资源的浪费。Java中一般不会产生内存泄露,因为有垃圾回收器自动回收垃圾,但这也不绝对,当我们new了对象,并保存了其引用,但是后面一直没用它,而垃圾回收器又不会去回收它,这边会造成内存泄露,
10. 自定义的java.lang.string类能否加载,为什么不能?(顺带讲了类加载器跟双亲委派机制)
不能,因为是JVM中采用了双亲委派的机制的来实现的类的自动接在的由于string类是属于的jdk中的自带的类,有自定义的类 --程序启动类加载器---系统扩展类---系统启动的类加载的这样的一种方式。
11. 那怎么可以实现加载这样的一个string类呢?
感觉被坑了,如果是java.lang.string的话一定是加载不了的,编译器会抛出异常;而我当时回答的是自定义类加载器,然就后逼逼了一段,面试官就嗯也没说别的。
12. 最近在学什么?
13. 优缺点
14. 详细介绍一下目前最有成就感的项目(可能是凑时间)。
15. 项目的困难,学习到哪些东西。
16. 反问对供应链部门的看法,被拒绝回答;反问对我的评价,被拒绝回答;(无情)
五面,电话面,约30min
就说一下hr面的感受吧,问题都是常规的一些hr问题,但阿里的hr面很不一样,最直接的感受就是不好糊弄。。。
问问题会问的特别细,特别深入,就一个问题,不断地问你为什么,更深层的原因是什么。
印象最深的就是让我说一下自己的优缺点,这个问题讨论了十分钟,特别恐怖,我感觉她一定有研究过心理学,不停的往深层次去问,不停的剖析你。
起初我回答的是优点是学习能力强,抗压能力强;hr很不满意,要我具体举例子,然后不断问我,后来对我的总结是勤奋+负责任
缺点我说的是二面面试官的评价,缺乏好奇心,然后就会问那你自己是如何觉得的呢?那为什么会这样呢?不断剖析下去说我是因为不想去看更大的世界。
面试的最后就直接说我过了,可能各种问题我回答的还算可以吧。之后三天左右发了意向书。