【李航-统计学习方法】第五章- 决策树-2
文章目录
- 5.2 特征选择
- 5.2.1 特征选择问题
- 5.2.2 信息增益
- (1)熵
- (2)条件熵
- (3)信息增益
- 5.2.3 信息增益比
- 5.3 决策树的生成
- 5.3.1 ID3算法
- 5.3.2 C4.5的生成算法
- 5.4 决策树的剪枝
- 5.5 CART算法
- 5.5.1 C A R T CART CART生成
- 5.5.2 C A R T CART CART剪枝
- Ref.
5.2 特征选择
5.2.1 特征选择问题
如前述所讲,特征选择在于选取对训练数据具有分类能力的特征。
如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。(这个定义…)
故扔掉没有分类能力的该类特征对决策树学习的精度影响不大。
特征选择的准则是信息增益或信息增益比。
例 5.1
说明:数据是一个由15个样本组成的贷款申请训练数据,数据包括贷款申请人的4个特征(属性)。
特征和属性是不一样的,
一个特征(属性)有三个特征值,但总共有四个特征。
注意区别:特征(属性)与特征值。(有助于理解信息增益的算法)
目的: 希望通过所给的训练数据学习一个贷款申请的决策树,用以对未来的贷款申请进行分类,即当新的客户提出贷款申请时,根据申请人的特征利用决策树决定是否批准贷款申请。
重点: 特征选择是决定用哪个特征来划分特征空间。
我们从表5.1数据学习到的两个可能的决策树,分别由两个不同特征(年龄和有工作)的根结点构成。两个决策树都可以从此延续下去。
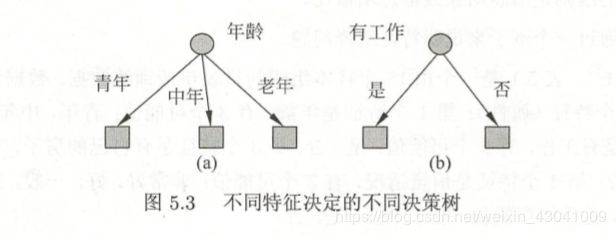
问题是:究竟选择哪个特征更好些?这需要确定选择特征的准则。
信息增益(information gain)即表示这一直观的准则。
5.2.2 信息增益
(1)熵
为了便于说明,先给出熵与条件熵的定义。
在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的度量。设 X X X是一个取有限个值得离散随机变量,其概率分布为:
P ( X = x i ) = p i , i = 1 , 2 , . . . , n P(X=x_i)=p_i,i=1,2,...,n P(X=xi)=pi,i=1,2,...,n
则随机变量 X X X的熵的定义为:
H ( X ) = − ∑ i = 1 n p i l o g p i (5.1) H(X)=-\sum_{i=1}^{n}p_ilogp_i\tag {5.1} H(X)=−i=1∑npilogpi(5.1)
在式(5.1)中,若 p i = 0 p_i=0 pi=0,则定义0log0=0.通常,式(5.1)中的对数以2为底或以e为底(自然对数),这时熵的单位分别称作比特(bit)或者纳特(nat)。由定义可知,熵只依赖于 X X X的分布,而与 X X X的取值无关,所以也可将 X X X的熵记作 H ( p ) H(p) H(p),即
H ( p ) = − ∑ i = 1 n p i l o g p i (5.2) H(p)=-\sum_{i=1}^{n}p_{i}logp_i\tag{5.2} H(p)=−i=1∑npilogpi(5.2)
熵的py代码
'''
函数功能:计算熵
参数说明:
dataset:原始数据集
返回:
ent:熵的值
'''
def calEnt(data):
n=data.shape[0] #数据集总行数
categories=data.iloc[:,-1].value_counts() #标签的所有类别
p=categories/n # 每一类标签所占比
entropy=(-p*np.log2(p)).sum() #熵的计算
return entropy
熵越大,随机变量的不确定性就越大。从定义可以验证
0 ≤ H ( p ) ≤ l o g n (5.3) 0\le H(p)\le logn \tag{5.3} 0≤H(p)≤logn(5.3)
当随机变量只取两个值,例如,1,0时,即 X X X的分布为
P ( X = 1 ) = p , P ( X = 0 ) = 1 − p , 0 < = p < = 1 P(X=1)=p,P(X=0)=1-p,0<=p<=1 P(X=1)=p,P(X=0)=1−p,0<=p<=1
熵为
H ( p ) = − p l o g 2 p − ( 1 − p ) l o g 2 ( 1 − p ) (5.4) H(p)=-plog_2p-(1-p)log_2(1-p)\tag{5.4} H(p)=−plog2p−(1−p)log2(1−p)(5.4)
(2)条件熵
设有随机变量 ( X , Y ) (X,Y) (X,Y),其联合概率分布为
P ( X = x i , Y = y j ) = p i j , i = 1 , 2 , . . . , n ; j = 1 , 2 , . . . , m P(X=x_i,Y=y_j)=p_{ij},i=1,2,...,n;j=1,2,...,m P(X=xi,Y=yj)=pij,i=1,2,...,n;j=1,2,...,m
条件熵 H ( Y ∣ X ) H(Y|X) H(Y∣X)表示在已知随机变量 X X X的条件下随机变量 Y Y Y的不确定性。随机变量 X X X给定的条件下随机变量 y y y的条件熵(conditional entropy) H ( Y ∣ X ) H(Y|X) H(Y∣X),定义为 X X X给定条件下 Y Y Y的条件概率分布的熵对 x x x的数学期望
H ( Y ∣ X ) = ∑ i = 1 n p i H ( Y ∣ X = x i ) (5.5) H(Y|X)=\sum_{i=1}^{n}p_{i}H(Y|X=x_i)\tag{5.5} H(Y∣X)=i=1∑npiH(Y∣X=xi)(5.5)
这里, p i = P ( X = x i ) , , i = 1 , 2 , . . . , n . p_i=P(X=x_i),,i=1,2,...,n. pi=P(X=xi),,i=1,2,...,n.
(这里建议结合后面的例子看,有助于理解)
当熵和条件熵的概率由数据估计(特别时极大似然估计)得到时,所对应的熵与条件熵分别成为经验熵(empirical entropy)和经验条件熵(empitical conditional entropy)。
(3)信息增益
信息增益(information gain)表示得知特征 X X X的信息而使得类 Y Y Y的信息的不确定性减少的程度。
举例:类:出去玩
特征:天气;心情;衣服
天气这个特征可以使你出去玩的不确定性下降的最多.
定义5.2(信息增益)
特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即
g ( D , A ) = H ( D ) − H ( D ∣ A ) (5.6) g(D,A)=H(D)-H(D|A)\tag{5.6} g(D,A)=H(D)−H(D∣A)(5.6)
一般地,熵 H ( Y ) H(Y) H(Y)与条件熵 H ( Y ∣ X ) H(Y|X) H(Y∣X)之差称为互信息(mutual information)。
决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
举个例子:
是否要出去玩?
在不知道任何比如天气等特征的情况下,是否出去玩类似一个抛硬币问题,出去与不出去的几率是一半一半的,这个是时候你整个人的混乱程度是很高的,也就是说熵是很高的。
在给定下雨的天气后,你就不会出去玩,你的混乱程度就有所降低,这个时候就是条件熵。
由上述可以知道,熵与条件熵之间的不确定性(混乱程度)是有差异的,而这个差值被定义为信息增益。
决策树学习应用信息增益选择特征。给定训练数据集D和特征A,经验熵H(D)表示对数据集D进行分类的不确定性。而经验条件熵H(D|A)表示在特征A给定条件下对数据集D进行分类的不确定性。那么它们的差,即信息增益,就表示由于特征A而使得对数据集D的分类不确定性减少的程度。
显然,对于数据集D而言,信息增益依赖于特征,不同的特征往往具有不同的信息增益。信息增益大的特征具有更强的分类能力。
决策树学习应用信息增益准则选择特征。信息增益大的特征具有更强的分类能力。根据信息增益准则的特征选择方法是:对训练数据集合(或子集)D,计算其
每个特征的信息增益,并比较它们的大小,选择信息增益最大的特征。
根据信息增益准则的特征选择方法是:对训练数据集合(或子集)D,计算其每个特征的信息增益,并比较它们的大小,选择信息增益最大的特征。

于是信息增益的算法如下:
输入:训练数据集D和特征A;
输出:特征A对训练数据集D的信息增益g(D,A)

最后,选择信息增益值最大的特征为最优特征。
对比理解:(发现还是按照上面的公式容易理解)
信息增益还可以理解信息增益为父结点的熵与其下所有 子结点的总熵的差值;
则其计算公式为
G a i n ( D , A ) = H ( D ) − ∑ n = 1 N ∣ D N ∣ ∣ D ∣ H ( D N ) Gain(D,A)=H(D)-\sum_{n=1}^N\frac{|D^N|}{|D|}H(D^N) Gain(D,A)=H(D)−n=1∑N∣D∣∣DN∣H(DN)
其中,D为数据集中的样本数,A为某一特征,n为特征A下的取值类别数。
(由于不同分支结点所包含的样本数不同,所以我们要给不同的分支结点赋予不同的权重,权重就是:分支结点所包含的样本数与总样本数的比值))
5.2.3 信息增益比
以信息增益作为划分训练集的特征,存在偏向于选择取值较多的特征的问题。
举例,熵从100变到90,信息增益为10;熵从10变到5,信息增益为5,但是是从百分比的角度来看,一个变化10%,一个变化50%。
使用信息增益比(information gain ratio)可以对这一问题进行校正。

5.3 决策树的生成
涉及三个经典算法:
ID3
C4.5
CART
(这三个的区别要讲清楚)
5.3.1 ID3算法
ID3算法的核心:
在决策树各个结点熵应用信息增益准则选择特征,递归地构建决策树。
具体方法:
从根结点(root node)开始,对结点计算所有可能的特征的信息增益,选择信息增益做大的特征作为结点的特征,由该特征的不同取值建立子结点;再对子结点递归地调用以上方法,构建决策树;
递归结束的条件:
程序遍历完所有的特征列,或者每个分支下的所有实例都具有相同的分类。如果所有实例具有相同分类,则得到一个叶结点。任何到达叶结点的数据必然属于叶结点的分类,即叶结点里面必须是标签。
(直到所有特征的信息增益均很小或没有特征可以选择为止。)
最后得到一棵树。ID3相当于用极大似然法进行概率模型的选择。
算法 5.2(ID3算法)*
输入;训练数据集 D D D,特征集 A A A阈值 ε \varepsilon ε
输出:决策树 T T T。


注意:ID3算法只有树的生成,所以该算法生成的树容易产生过拟合(学习的过于精细把训练集上的所有特征都分类的十分正确但在测试集上的表现不好)。
比如,某个特征的取值很多,会使得生成的树很散,着就涉及到连续型变量分桶的概念了。
5.3.2 C4.5的生成算法
C4.5算法与ID3算法类似,C4,5算法对ID3算法进行了改进。
具体来说,C4.5在生成的过程中,用信息增益比来选择特征。
5.4 决策树的剪枝
**目的:**防止过拟合,使其具有良好的泛化能力。
- 什么是过拟合呢?
就是产生的树对训练数据的分类很准确,但对未知的测试数据的分类却没有那么准确,即出现过拟合现象。 - 出现过拟合的原因:
学习时过多地考虑如何提高对训练数据的正确分类,从而构建出过于复杂的决策树。 - 如何改进呢?
考虑决策树的复杂度,对已生成的决策树进行简化,这个过程被称为剪枝(pruning)。
具体来说,剪枝从已生成的树上裁掉一些子树或叶结点,并将其根结点或父结点作为新的叶结点,从而简化分类树模型。
这里介绍一种简单的决策树学习的剪枝算法。
决策树的剪枝往往通过极小化决策树整体的损失函数(loss function)或代价函数(cost function)来实现。设树 T T T的叶结点个数为 ∣ T ∣ |T| ∣T∣,t是树 T T T的叶结点,该叶结点有 N t N_t Nt个样本点,其中 k k k类的样本点有 N t k N_{tk} Ntk个, k = 1 , 2 , . . . , K , H t ( T ) k=1,2,...,K,H_t(T) k=1,2,...,K,Ht(T)为叶结点t上的经验熵, α ≥ 0 \alpha \ge0 α≥0为参数,则决策树学习的损失函数可以定义为
C α ( T ) = ∑ t = 1 ∣ T ∣ N t H t ( T ) + α ∣ T ∣ (5.11) C_\alpha(T)=\sum_{t=1}^{|T|}N_tH_t(T)+\alpha|T|\tag{5.11} Cα(T)=t=1∑∣T∣NtHt(T)+α∣T∣(5.11)

决策树生成只考虑了通过提高信息增益(或信息增益比)对训练数据进行更好的拟合。而决策树剪枝通过优化损失函数还考虑了减小模型复杂度。决策树生成学习局部的模型,而决策树剪枝学习整体的模型。
式(5.11)或式(5.14)定义的损失函数的极小化等价于正则化的极大似然估计。所以,利用损失函数最小原则进行剪枝就是用正则化的极大似然估计进行模型选择。

5.5 CART算法
分类与回归树(classifition and regression tree, C A R T CART CART)。
它同样由特征选择、树的生成及剪枝组成,既可以用于分类也可以用于回归。
C A R T CART CART是在给定输入随机变量 X X X条件下输出随机变量 Y Y Y的条件概率分布的学习方法。
C A R T CART CART假设决策树是二叉树,内部结点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支。这样的决策树等价于递归地二分每个特征,将输入空间j即特征空间划分为有限个单元,并在这些单元上确定预测的概率分布,也就是在输入给定的条件下输出的条件概率分布。
C A R T CART CART算法由以下两部组成:
(1)决策树生成:基于训练数据集生成决策树,生成的决策树要尽量大;
(2)决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时用损失函数最小作为剪枝的标准。
5.5.1 C A R T CART CART生成
决策树的生成就是递归地构建二叉决策树的过程。
对回归树用平方误差最小化准则;
对分类树用基尼指数(Gini index)最小化准则,进行特征选择,生成二叉树。
1、回归树的生成
2、分类树的生成

5.5.2 C A R T CART CART剪枝
其他资料:
决策树背后的数学原理
Ref.
[1] 李航. 统计学习方法[M],清华大学出版社.