人体姿态估计综述(2014-2019)
所谓的人体姿态估计,就是给定一幅图像或者一段视频,从中去恢复人体关节点的过程。到目前为止,利用深度学习进行姿态估计的方法大致分为两种:自上而下的方法和自下而上的方法。自上而下(top-down),即先检测出来人体,再对单个人进行姿态估计;而自下而上(down-top),则是先检测出人体关节点,再根据检测出来的关节点连成人体骨架。下面,将对近几年的人体姿态估计的论文进行一下汇总。

1.人体姿态估计常用数据集
1.LSP
样本数:2K,关节点个数:14,全身,单人,体育
2.FLIC
样本数:20K,关节点个数:9,半身,单人,影视
3.MPII
样本数:25K,关节点个数:16,全身,单人/多人,日常
4.MicroSoft COCO
样本数:>=30W,关节点个数:18,全身,多人,10W个人体姿态标签
2.人体姿态估计常用评估指标
Percentage of Correct Parts (PCP):检测到正确部位的比例。在PCP中认为一个骨骼(limb)被检测到的标准是,骨骼的两个关节点的位置与真实关节点的位置的距离小于骨骼的长度的一半。
Percent of Detected Joints (PDJ):检测到的关节点的比例。在PDJ中认为一个关节被检测到的标准是,关节的位置与真实位置的距离小于躯干对角点的长度(如left shoulder到right hip的距离)的一个比例值。
Percentage of Correct Keypoints (PCK):关键点被准确检测的比例。计算检测的关键点与其对应的groundtruth间的归一化距离小于设定阈值的比例。FLIC 中是以躯干直径作为归一化参考。MPII 中是以头部长度作为归一化参考,即 PCKh。
Average Precision (AP):平均精确度。类似目标检测,将在真实目标和预测值目标之间的匹配程度的阈值度量由目标检测中的每个目标检测框的交并比(IOU)改为每个目标的关键点相似度(object keypoint similarity, OKS)。
3.人体姿态估计论文
3.1 DeepPose: Human Pose Estimation via Deep Neural Networks(2014)
DeepPose 2014 Google 自上而下
paper link:https://arxiv.org/pdf/1312.4659.pdf
github:https://github.com/mitmul/deeppose
这是第一个将深度学习应用到人体姿态估计的方法。这篇文章使用深度神经网络构建了一个级联的回归网络来实现人体姿态估计。文章将人体姿态估计看作是一个人体关节的回归问题,文章认为这样做有两个好处:(1)深度神经网络有着捕获全局上下文信息的能力,每一个关节的回归器都用到整张图片的信息;(2)是这种表示方相对于图模型的方法要更简单,不需要设计人体部分(part)的特征表示或者检测器,也不需要设计人体关节之间的拓扑模型和交互。
步骤:
1.首先把整个图像作为输入,使用卷积神经网络来进行全局的特征提取,初步获得人体关节点的粗略估计。
2.将图像中所有的人体关节点坐标标准化,利用深度神经网络对关节点坐标进行回归。
3.设计了级联姿态回归器,分阶段优化。利用前一阶段预测结果截取候选框(在获得初步的节点坐标之后,再在原始图片中根据该坐标选择一定的局部区域),扩充数据,增加细节,从而提高精度。
解决的问题:
1.如何使用全局观点获得关节点的坐标的问题,对于每一个关节点,都把整个图像作为输入,同时,使用卷积神经网络来作为全局的特征提取;
2.对于节点的坐标在不同的图像中处理绝对坐标的问题,作者采用在每一个环节中,通过中点,长和宽选择一个bound box,然后计算节点在bound box中的坐标,从而将绝对坐标转换为统一的坐标;
3.如何实现更高精度的坐标计算问题,作者提出的级联的卷积神经网络,在最初输入时,将图片设定为固定大小,通过缩放的方式将图片缩放到这个大小,在获得初步的节点坐标之后,再在原始图片中根据该坐标选择一定的局部区域,从而实现更高准确度的计算节点的坐标。
数据集:FLIC、LSP
性能指标(PCP):
LSP:0.56(大臂)、0.38(小臂)、0.78(大腿)、0.71(小腿)
FLIC:0.8(大臂)、0.75(小臂)、0.71(大腿)、0.5(小腿)
3.2 Convolutional Pose Machines(2016)
CPM 2016 Carnegie Mellon University 自下而上
paper link:https://arxiv.org/pdf/1602.00134.pdf
github:https://github.com/shihenw/convolutional-pose-machines-release

算法的流程:
1.在每个尺度下,计算各个部件的相应图
2.对于每个关节点,累加所有尺度的响应图,得到总响应图
3.每个关节点的总响应图上,找出相应最大的点,为该关节点的位置
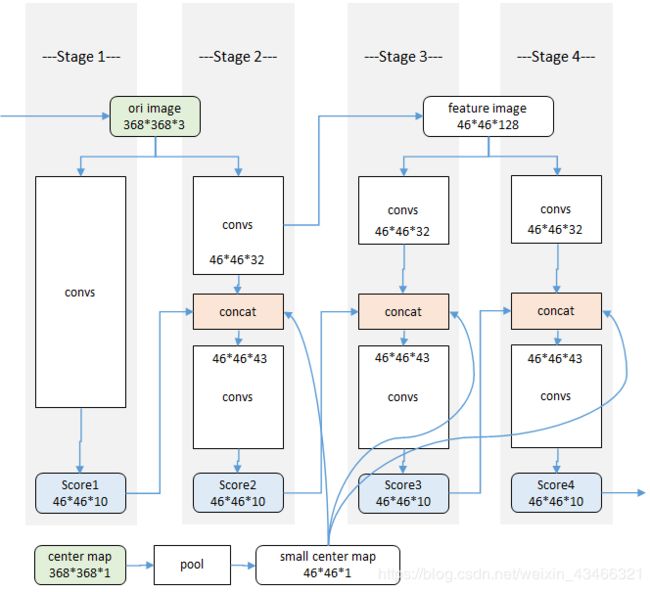
第一阶段是一个基本的卷积网络,从彩色图像直接预测每个部件的响应。半身模型有9个部件,加上一个背景响应,共10层响应图。
第二阶段在卷积层中段多了一个串联层(红色concat),把以下三个数据合一:阶段性的卷积结果46*46*32(纹理特征)、46*46*10前一阶段各部件响应(空间特征)、中心约束46*46*1。(空间约束:是一个提前生成的高斯函数模板,用来吧相应归拢到图像中心。)
第三阶段及后续阶段不再使用原始图像为输入,而是从前一阶段的中途取出一个深度为128的特征图作为输入。同样使用串联层综合三种因素:纹理特征+空间特征+中心约束。
主要特点:
1.用各部件响应图来表达各部件之间的空间约束。响应图和特征图一起作为数据在网络中传递。
2.网络分为多个阶段(stage)。各个阶段都有监督训练,避免过深网络产生的梯度消失、难以优化的问题。
3.使用同一个网络,同时在多个尺度处理输入的特征和响应。既能确保精度,又考虑了各个部件之间的远距离关系。
数据集:MPII、FLIC、LSP
性能指标(PCK):
MPII:0.8795 LSP:0.8432 FLIC:0.9759(手肘)、0.9503(手腕)
3.3 Stacked Hourglass Networks for Human Pose Estimation(2016)
Stacked Hourglass Networks 2016 University of Michigan 自上而下
paper link:https://arxiv.org/abs/1603.06937
github:https://github.com/princeton-vl/pose-hg-train
2016年提出来的堆叠沙漏模型也取得了很高的精确度。网络总体思路是受ResNet的思路影响,希望综合考虑各尺度下不同的feature来让网络学习姿态。
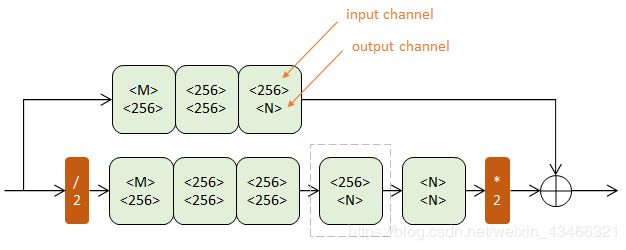
沙漏结构(单个沙漏)
沙漏结构设计:可捕捉不同尺度下图片所包含的信息
残差模块:提取较高层次的特征,同时保留原有层次的信息
一阶沙漏:
四阶沙漏:
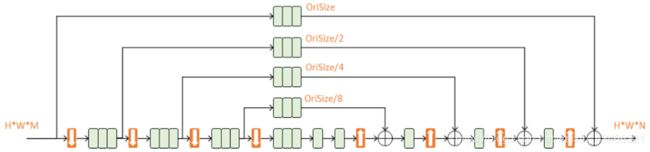
以上为单个沙漏模型。其实单个hourglass network 其实已经可以用来训练姿态估计了,关节点之间是可以互相参考预测的,所以将第一个沙漏网络给出的热力图作为下一个沙漏网络的输入,就意味着第二个沙漏网络可以使用关节点件的相互关系,从而提升了关节点的预测精度。因此要将单个沙漏级联。

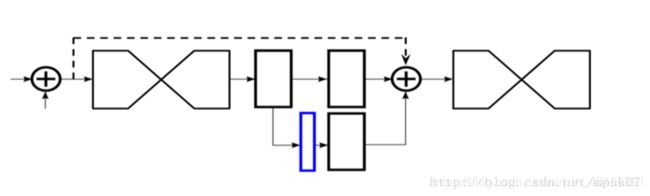
中间监督:下图的蓝色部分是输出的heat map。堆叠沙漏网络的每一个子沙漏网络都会有heat map作为预测,所以将每个沙漏输出的heat map参与到loss中,实验证实,预测精确度要远远好于只考虑最后一个沙漏预测的loss,这种考虑网络中间部分的监督训练方式,就叫做中间监督。
数据集:FLIC、MPII
性能指标 (PCK):FLIC手肘 0.99 ([email protected])、FLIC手腕 0.97 MPII 0.909 ([email protected])
3.4 Associative Embedding: End-to-End Learning for Joint Detection and Grouping(2017)
Associative Embedding 2017 University of Michigan,清华大学 自下而上
paper link:https://arxiv.org/pdf/1611.05424.pdf
github:https://github.com/princeton-vl/pose-ae-train
模型结构:

思想:
该网络在堆叠沙漏基础上同时生成每个关节点的检测热图和联合嵌入的预测标签,每个关节点的热图都有对应的标签热图。因此,如果有m个身体关节需要预测,那么网络将输出总共2m个通道,m用于检测,m用于分组。为检测到个人,该网络使用非极大值抑制得到各关节的峰值检测并在同一像素位置检索相应的标记。然后通过比较检测的标签值,匹配那些足够接近的标签值,对身体各个部位的检测进行分组。一组检测形成一个人的姿态估计。
为了训练网络,对输出热图施加检测损失和分组损失。

性能指标(AP):
MPII 0.775、MS-COCO test-std 0.663、MS-COCO test-dev 0.655.
3.5 Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields(2017)
OpenPose 2017 Carnegie Mellon University 自下而上
paper link:https://arxiv.org/abs/1611.08050
gitHub:https://github.com/ZheC/Realtime_Multi-Person_Pose_Estimation
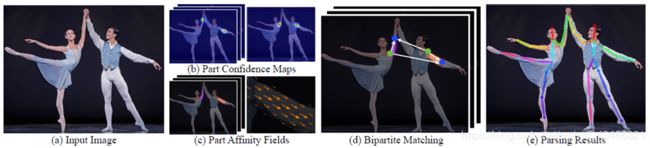
(a)该方法以整个图像为输入(b/c)用一个双分支CNN来联合预测身体部位(b)关节点检测的置信度图(c)部位组织的亲和域(d)解析步骤执行一组双边匹配,以关联身体部位的候选。(e)最后将图中所有人组装成完整的身体姿态。
网络结构:

步骤:
1,使用置信图进行关节检测
先使用 VGG19 的前十个层获得图片的特征,再将其输入后面的模块进行优化。一个阶段 中包含两个分支,一个分支用于回归关节点,另一个则回归关节点之间的链接。第一个阶段 的输入数据为 VGG 前十层得到的特征,而随后阶段的输入数据为前一个阶段的输出和特征。
2,使用PAF进行身体部分组合
对于多个人的问题,使用PAF(Part Affinity Fields,部位亲和域)的方法将每个人的身体分别组合在一起。这个方法包含了位置和方向信息。每一种肢体在关联的两个部位之间都有一个亲和区域,其中的每一个像素都有一个2D 向量的描述方向。
3,自底向上
使用匈牙利算法(Hungarian algorithm)找到两两关节点最优化的连接方式。

数据集:MPII、COCO2016
性能指标(mAP):0.797(MPII测试子集) 0.756(MPII完整测试集) 0.791(MPII验证集最佳结构) 0.653(COCO)
3.6 RMPE: Regional Multi-Person Pose Estimation(2017)
AlphaPose 2017 上海交通大学 自上而下
paper link:https://arxiv.org/abs/1612.00137v3
github:https://github.com/MVIG-SJTU/AlphaPose
目标:在第一步中检测到的是不精准的区域框的情况下,仍能检测出正确的人体姿态

大体流程:训练阶段,拿到图片用现有的单人检测,检测human proposal作为输入,分支SPPE的误差反向传播,使得STN调整bbox,得到更准确的bbox,再通过SPPE做姿态检索,将得到的所有pose proposal做NMS,除去冗余pose,得到最终结果。
对称空间变换网络和并行单人姿态估计(Symmetric STN and Parallel SPPE)
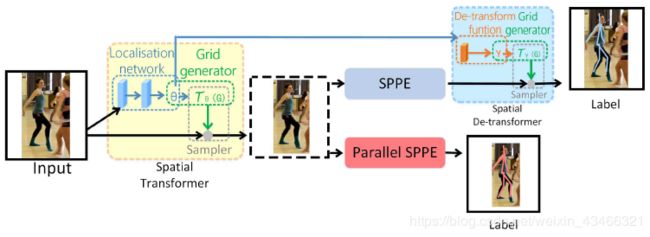
步骤:
1、用SSD检测图中人物,获得人物候选框。
2、将候选框输入到两个并行的分支里面,上面的分支是STN+SPPE+SDTN的结构,即空间变换网络(Spatial Transformer Networks) + 单人姿态估计(Single Person Pose Estimation) + 空间反变换网络(Spatial de-Transformer Networks)。不准确的检测框经过STN+SPPE+SDTN,STN对人体区域框中的姿态进行形态调整,输入SPPE做姿态估计后得到姿态线(人体骨骼框架),再用SDTN把姿态线映射到原始的人体区域框中,以此来调整原本的框,使框变成精准的。下面并行的分支充当额外的正则化矫正器。
3、对候选姿态做parametric pose NMS(参数化姿态非极大值抑制)来消除冗余。
性能指标(AP):MPII 0.723
3.7 Cascaded Pyramid Network for Multi-Person Pose Estimation(2018)
CPN 2018 清华大学 自上而下
paper link:https://arxiv.org/abs/1711.07319
github:https://github.com/chenyilun95/tf-cpn
大致流程:
文章核心提出一种使用自上而下的多人关键点估计方法。先检测人体,之后利用GlobalNet + RefineNet结构对单人目标回归人体关键点。一些比较容易识别出来的人体关键点,直接利用一个CNN模型就可以回归得到;而对于一些遮挡比较严重的关节点,则需要增大局部区域感受野以及结合上下文信息才能够进一步refine得到。
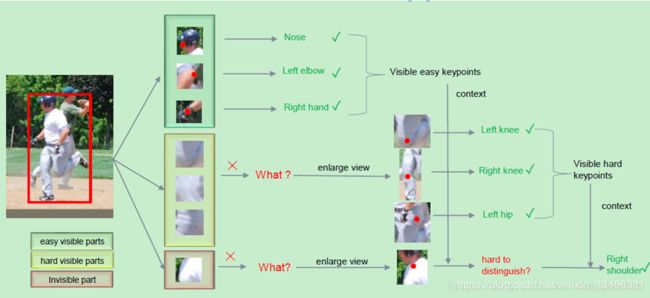
首先对于可以看见的“easy”关键点直接预测得到,对于不可见的关键点,使用增大感受野来获得关键点位置,对于还未检测出的点,使用上下文(context)进行预测。
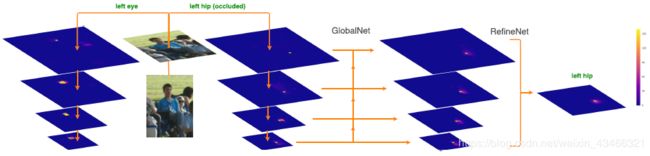
GlobalNet的作用就是简单的前向CNN组成的回归模型,目的是回归得到一些易于识别的人体关键点位置,这里作者使用ResNet的网络架构回归heatmap。RefineNet的目的则是利用GlobalNet产生的金字塔模型的特征图,融合多个感受野信息,最后concatenate所有的同一尺寸特征图进一步回归一些有歧义的关键点位置。

1)GlobalNet
A)采用ResNet的不同Stage的最后一个残差块输出(C2,C3,C4,C5)作为组合为特征金字塔;拿ResNet50来说,当输入大小为1×3×256×192时: C2 = res2c(1×256×64×48) C3 = res3d(1×512×32×24) C4 = res4f(1×1024×16×12) C5 = res5c(1×2048×8×6) 这样就构成特征金字塔。C2,C3具有较高的空间分辨率和较低语义信息,而C4,C5具有较低空间分辨率和更丰富的语义信息;将他们结合在一起,则即可利用C2,C3空间分辨率优势定位关键点,也可利用C4,C5丰富语义信息识别关键点
B)然后各层进行1×1卷积将通道都变为256
C)将分辨率小的层上采样一次,在对应神经元相加,输出P2,P3,P4,P5
D)输出:对每层,即P2,P3,P4,P5都进行3×3卷积,再生成heatmaps
2)RefineNet
A)对GlobalNet的4层输出P2,P3,P4,P5分别接上不同个数的Bottleneck模块
B)将这4路输出,上采样到同一分辨率,这里以P2路(64×48)为基础,P3路放大2倍,P4路放 大4倍,P4路放大8倍
C)将4路按通道Concat一起,再接bottleneck,最后接输出层
性能指标(AP):COCO 0.721
3.8 Deep High-Resolution Representation Learning for Human Pose Estimation(2019)
HRNet 2019 中国科学技术大学 ,微软亚洲研究院
paper link:https://arxiv.org/pdf/1902.09212.pdf
github:https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
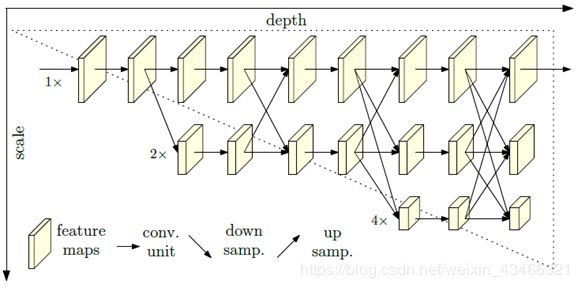
特点:网络能在整个过程中都保持高分辨率的表示。
该架构从作为第一阶段的高分辨率子网开始,逐步逐个添加高到低分辨率的子网,以形成更多的阶段并连接并行的多分辨率子网。通过在整个过程中反复进行跨越多分辨率并行子网络的信息交换来实现多尺度融合。
使用重复的多尺度融合,利用相同深度和相似级别的低分辨率表示来提高高分辨率表示,反之亦然,从而使得高分辨率表示对于姿态的估计也很充分。因此,该网络预测的热图可能更准确。
数据集:COCO、MPII
性能指标(AP):HRNet-W48、COCO:关键点检测0.763、姿态估计0.770、多人姿态估计0.770