小白教程:Ubuntu下使用Darknet/YOLOV3训练自己的数据集
小白教程:Ubuntu下使用Darknet/YOLOV3训练自己的数据集
YOLOV3官网教程:https://pjreddie.com/darknet/yolo/
使用预训练模型进行检测
git clone https://github.com/pjreddie/darknet(如果安装不了,先试试sudo apt-get install git)
cd darknet
make
wget https://pjreddie.com/media/files/yolov3.weights
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
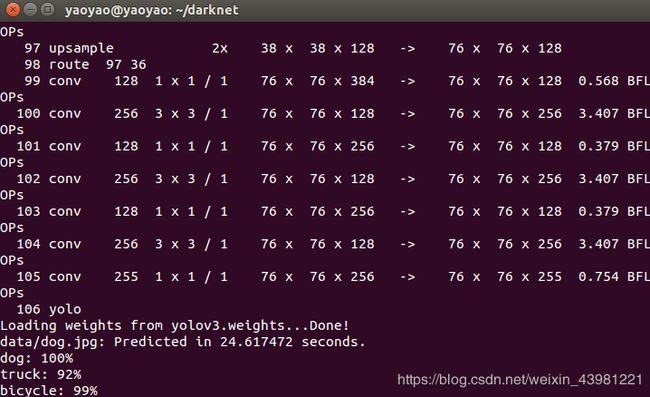
我们没有使用OpenCV编译Darknet,因此无法直接显示检测。 相反,它将它们保存在predictions.png中。 您可以打开它以查看检测到的对象。

多个图像
./darknet detect cfg/yolov3.cfg yolov3.weights
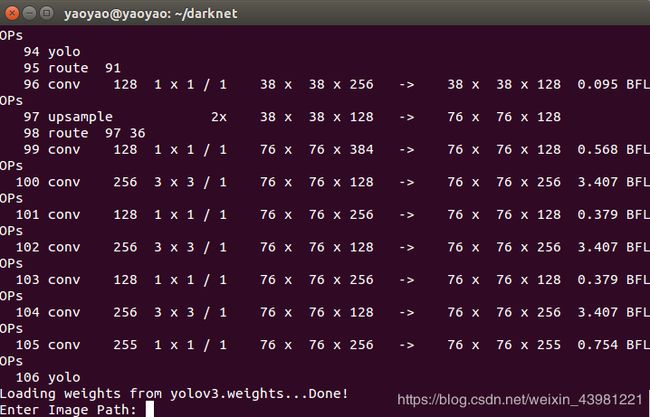
输入图片路径:
data/horses.jpg

可以在darknet文件夹下看到prediction.jpg

它将提示您尝试更多路径来尝试不同的图像。完成后Ctrl-C用于退出程序。
更改检测阈值
默认情况下,YOLO仅显示检测到的置信度为.25或更高的对象。您可以通过将-thresh 标志传递给yolo命令来更改此设置。例如,要显示所有检测,您可以将阈值设置为0:
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0
微小的YOLOv3
对于受限环境,我们有一个非常小的模型yolov3-tiny。要使用此模型,请先下载权重:
wget https://pjreddie.com/media/files/yolov3-tiny.weights
然后使用微小的配置文件和权重运行检测器:
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg
网络摄像头上的实时检测
如果您看不到结果,则在测试数据上运行YOLO并不是很有趣。而不是在一堆图像上运行它让我们在网络摄像头的输入上运行它!
要运行此演示,您需要使用CUDA和OpenCV编译Darknet。然后运行命令:
使用CUDA编译(按照这个博客安装CUDAhttps://blog.csdn.net/jonms/article/details/79318566)
CPU上的Darknet速度很快,但它在GPU上的速度要快500倍!你必须有一个Nvidia GPU,你必须安装CUDA(
安装CUDA后,Makefile将基本目录中的第一行更改为:
GPU=1
现在您可以make启用项目和CUDA。默认情况下,它将在系统的第0个图形卡上运行网络(如果您正确安装了CUDA,则可以使用列出您的图形卡nvidia-smi)。如果你想更改Darknet使用的卡,你可以给它一个可选的命令行标志-i ,如:
./darknet -i 1 imagenet test cfg/alexnet.cfg alexnet.weights
如果您使用CUDA进行编译但想要进行CPU计算,无论出于何种原因您都可以使用-nogpuCPU来代替:
./darknet -nogpu imagenet test cfg/alexnet.cfg alexnet.weights
享受您新的超快速神经网络!
使用OpenCV进行编译
默认情况下,Darknet stb_image.h用于图像加载。如果你想要更多支持奇怪的格式,你可以使用OpenCV!OpenCV还允许您查看图像和检测,而无需将其保存到磁盘。
首先安装OpenCV。如果你从源代码执行此操作,它将是漫长而复杂的,因此请尝试让包管理器为您执行此操作。
接下来,将第二行更改为Makefile:
OPENCV=1

你完成了!要试一试,首先要重新开始make。

然后使用imtest例程来测试图像加载和显示:
./darknet imtest data/eagle.jpg
如果你有一堆老鹰的窗户,你就成功了!他们可能看起来像:
继续前面的网络摄像头上的实时检测
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
YOLO将显示当前的FPS和预测类以及在其上绘制边界框的图像。
您需要连接到OpenCV可以连接的计算机的网络摄像头,否则它将无法工作。如果您连接了多个网络摄像头并想要选择使用哪个网络摄像头,则可以传递标记-c 以进行选择(OpenCV 0默认使用网络摄像头)。
如果OpenCV可以读取视频,您也可以在视频文件上运行它:这就是我们制作YouTube视频的方式。
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights 关于VOC的培训YOLO
如果您想要使用不同的训练方案,超参数或数据集,您可以从头开始训练YOLO。以下是如何使其在Pascal VOC数据集上运行。
获取Pascal VOC数据
要训练YOLO,您将需要2007年至2012年的所有VOC数据。您可以在此处找到数据的链接。要获取所有数据,在darknet下新建一个文件夹VOCdevkit,并从该目录运行:
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
为VOC生成标签
现在我们需要生成Darknet使用的标签文件。Darknet希望.txt每个图像都有一个文件,图像中的每个地面实况对象都有一行,如下所示:
其中x,y,width,和height相对于图像的宽度和高度。要生成这些文件,需要执行如下操作。
wget https://pjreddie.com/media/files/voc_label.py
python voc_label.py
ls

cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt
将2007和2012所有训练文件放在一个一起。
修改Pascal数据的Cfg
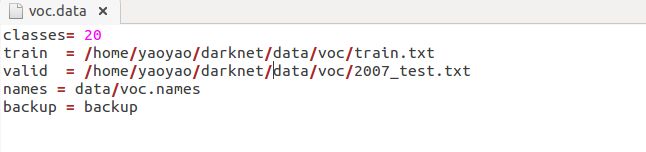
现在转到Darknet目录。我们必须更改cfg/voc.data配置文件以指向您的数据:
1 classes= 20
2 train = /train.txt
3 valid = 2007_test.txt
4 names = data/voc.names
5 backup = backup
下载预训练卷积权重
对于训练,我们使用在Imagenet上预训练的卷积权重。我们使用darknet53模型中的权重。您可以在此处下载卷积图层的权重(76 MB)。
wget https://pjreddie.com/media/files/darknet53.conv.74
训练模型
现在我们可以训练!运行命令:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
在COCO上培训YOLO
如果您想要使用不同的训练方案,超参数或数据集,您可以从头开始训练YOLO。以下是如何使用COCO数据集。
获取COCO数据
要训练YOLO,您需要所有COCO数据和标签。该脚本scripts/get_coco_dataset.sh将为您完成此操作。找出您想要放置COCO数据并下载它的位置,例如:
cp scripts/get_coco_dataset.sh data
cd data
bash get_coco_dataset.sh
现在您应该为Darknet生成所有数据和标签。
修改COCO的cfg
现在转到Darknet目录。我们必须更改cfg/coco.data配置文件以指向您的数据:

您还应该修改您的模型cfg以进行培训而不是测试。cfg/yolo.cfg应该是这样的:

训练模型
现在我们可以训练!运行命令:
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74
如果你想使用多个gpus运行:
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74 -gpus 0,1,2,3
如果要从检查点停止并重新启动训练:
./darknet detector train cfg/coco.data cfg/yolov3.cfg backup/yolov3.backup -gpus 0,1,2,3
打开图像数据集上的YOLOv3
wget https://pjreddie.com/media/files/yolov3-openimages.weights
./darknet detector test cfg/openimages.data cfg/yolov3-openimages.cfg yolov3-openimages.weights
1.获取数据与标签
(感谢大佬分享 https://blog.csdn.net/weixin_39449466/article/details/80582197)
将图片转换为xml格式,随后再转换为txt.
1.1获取图片并使用labelimg标注图片生成xml数据
使用标注工具labelimg手动给每一张图片加标签生成xml文件格式放入darknet/eye/xml文件夹中,准备好你要标记的图片,这里用的是FDDB数据库,训练数据集然后自动检测眼睛。(我创建了一个名为eye的文件夹,下载的图片放在了eye/Image,训练了200张)
1.1.1下载Iabelimg(https://github.com/tzutalin/labelImg)
sudo apt-get install pyqt4-dev-tools # 安装PyQt4
sudo pip install lxml (# 安装lxml,如果报错,可以试试下面语句sudo apt-get install python-lxml)
git clone https://github.com/tzutalin/labelImg.git
cd labelImg
make all
./labelImg.py
1.1.2 使用方法
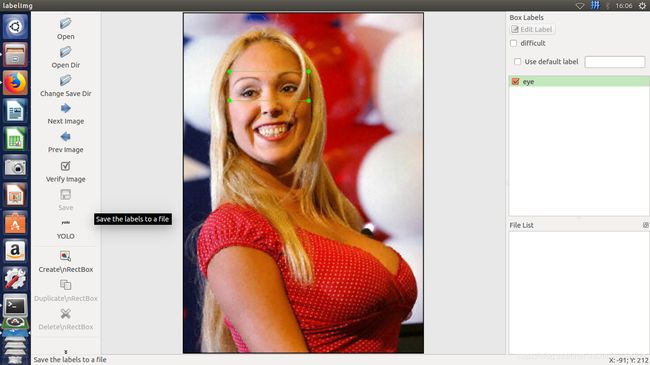
(1)修改默认的xml文件保存位置,使用快捷键“Ctrl+R”,改为自定义位置,这里的路径一定不能包含中文,否则无法保存。
(2)打开data/predefined_classes.txt,修改默认类别,比如改成你要标注的对象名称。这里就写eye就行
(3)“Open Dir”打开图片文件夹,选择第一张图片开始进行标注,使用“Create RectBox”或者“Ctrl+N”开始画框,单击结束画框,再双击选择类别。完成一张图片后点击“Save”保存,此时XML文件已经保存到本地了。点击“Next Image”转到下一张图片。
(4)标注过程中可随时返回进行修改,后保存的文件会覆盖之前的。

1.2将xml转换成为darknet能读入的txt格式文件
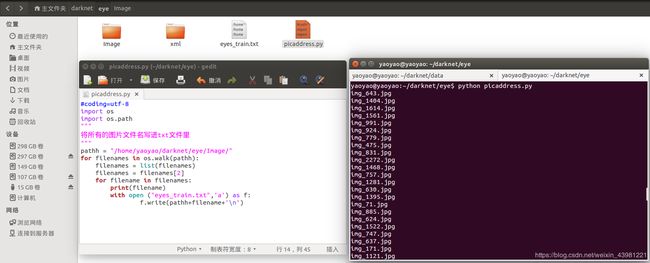
1.2.1创建一个名为picaddress.py的文件
复制以下代码(记得把路径改成自己的,需要顶头写,要不不好使)
#coding=utf-8
import os
import os.path
"""
将所有的图片文件名写进txt文件里
"""
pathh = "/home/yaoyao/darknet/eye/Image/"
for filenames in os.walk(pathh):
filenames = list(filenames)
filenames = filenames[2]
for filename in filenames:
print(filename)
with open ("eyes_train.txt",'a') as f:
f.write(pathh+filename+'\n')
在终端执行python picaddress.py,它自动生成eyes_train.txt,他保存了所有图片的路径。
1.2.2 创建文件名为voc_label.py的文件
复制以下代码(记得将路径改成自己的,把所有#后面的注释删掉,要不然运行不了)
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[]
classes = ["eyes"]
#原样保留。size为图片大小
# 将ROI的坐标转换为yolo需要的坐标
# size是图片的w和h
# box里保存的是ROI的坐标(x,y的最大值和最小值)
# 返回值为ROI中心点相对于图片大小的比例坐标,和ROI的w、h相对于图片大小的比例
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
#对于单个xml的处理
def convert_annotation(image_id):
image_add = os.path.split(image_id)[1] #截取文件名带后缀
image_add = image_add[0:image_add.find('.', 1)]#删除后缀,现在只有文件名没有后缀
in_file = open('/home/yaoyao/darknet/eye/xml/%s.xml'%(image_add))
print('now write to:/home/yaoyao/darknet/eye/eye_labels/%s.txt' % (image_add))
out_file = open('/home/yaoyao/darknet/eye/eye_labels/%s.txt'%(image_add), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.findall("object"):
# obj.append("number") = obj.find('name').text
obj.find('name').text = "eyes"
print(obj.find('name').text)
tree.write('/home/yaoyao/darknet/eye/xml/' + image_add + '.xml')
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
# 如果训练标签中的品种不在程序预定品种,或者difficult = 1,跳过此object
for obj in root.iter('object'):
#difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes:# or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
# b是每个Object中,一个bndbox上下左右像素的元组
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
if not os.path.exists('/home/yaoyao/darknet/eye/eye_labels/'):
os.makedirs('/home/yaoyao/darknet/eye/eye_labels/')
image_adds = open("eyes_train.txt")
for image_add in image_adds:
image_add = image_add.strip()
print (image_add)
convert_annotation(image_add)
在终端输入,python voc_label.py,自动生成eye_labels文件夹,里面包含.txt文件. 随后便可以将eyes_train.txt分出来一部分生成文件名为eyes_test.txt的文件作为验证集。将eyes_label文件夹下的txt文件全部复制到Image文件夹下,图片与他们的txt标签文件一一对应。

2.修改配置文件
2.1修改.cfg文件
在cfg文件夹下复制不会报错的yolo.cfg复制为yolo-eyes.cfg(这里我将yolov2.cfg复制并重命名),随后对yolo-eyes.cfg进行修改,类别为1,即classes=1.
需要训练时将前四行中的testing注释掉,使用training参数.
[net]
# Testing
#batch=1
#subdivisions=1
# Training
注:因为内存限制最后将batch和subdivision修改为1.
如果后续训练过程中会发散,则可以调整学习率,将学习率从0.001变得再小一点.
learning_rate=0.00001#学习率可以变得再小一点,避免训练过程中发散
burn_in=1000
max_batches = 500200#训练步长可以在这一步调整,原来是500200次
policy=steps
steps=400000
scales=.1,.1

更改[region]中的classes为1,根据filters=(classes+coods+1)∗numfilters=(classes+coods+1)∗num的公式,修改最后一个[convolutional]的filter改为30.
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=30 #修改这里的filter为30
activation=linear
[region]
anchors = 0.57273, 0.677385, 1.87446, 2.06253, 3.33843, 5.47434, 7.88282, 3.52778, 9.77052, 9.16828
bias_match=1
classes=1#修改种类为1
coords=4
num=5
softmax=1
jitter=.3
rescore=1
object_scale=5
noobject_scale=1
class_scale=1
coord_scale=1
absolute=1
thresh = .1
random=0#默认random为1,但是因为因为内存限制,将random改为0.

2.2新建cfg/eyes.data文件
终端中输入
gedit cfg/eyes.data
在eyes.data文件中写下以下参数:
classes=1
train=/home/yaoyao/darknet/eye/eyes_train.txt
valid=/home/yaoyao/darknet/eye/eyes_test.txt
names=data/eyes.names
backup=backup
names是训练的名字,backup是在训练过程中相应步数的权重文件文件夹.
gedit data/eyes.names
生成data/eyes.names文件并写入 *eyes *类别.
生成backup文件夹.
mkdir backup
3.开始训练
./darknet detector train cfg/eyes.data cfg/yolo-eyes.cfg | tee person_train_log.txt
为了可视化,加上的| tee person_train_log.txt
可以使用GPU监视命令,来查看GPU使用情况.
watch -n 1 nvidia-smi(这个只支持nvidia显卡的电脑,AMD显卡的不行)
训练log中各参数的意义:
Region Avg IOU:平均的IOU,代表预测的bounding box和ground truth的交集与并集之比,期望该值趋近于1。
Avg Recall: 这个表示平均召回率, 意思是 检测出物体的个数 除以 标注的所有物体个数。期望该值趋近1
Class:是标注物体的概率,期望该值趋近于1.
Obj:期望该值趋近于1.
No Obj:期望该值越来越小但不为零.
avg:平均损失,期望该值趋近于0
count: 标注的所有物体的个数。 如果 count = 6, recall = 0.66667, 就是表示一共有6个物体(可能包含不同类别,这个不管类别),然后我预测出来了4个,所以Recall 就是 4 除以 6 = 0.66667 。
rate:当前学习率
4.测试
在GTX1050显卡(2G)训练了大约不到两天后在backup文件夹中可以看到所有的backup文件。
其中yolo-eyes_final.weights便是训练了50W次后的训练权重。
我在darknet中放入了一张照片名为prediction.jpg
在终端输入命令测试:
./darknet detect cfg/yolo-eyes.cfg backup/yolo-eyes_final.weights prediction.jpg -thresh 0.4
#####我的工作站检测 ./darknet detect cfg/yolo-eyes.cfg backup/yolo-eyes_900.weights predictions.jpg -thresh 0.4
如果中途终止,比如训练了2000次,想看下效果,就输入
./darknet detect cfg/yolo-eyes.cfg backup/yolo-eyes_2000.weights prediction.jpg -thresh 0.4
这时候你看到的可能是满屏都是框,因为还没训练好,继续训练输入
./darknet detector train cfg/eyes.data cfg/yolo-eyes.cfg backup/yolo-eyes_2000.weights| tee person_train_log.txt
5.训练过程中的可视化
./darknet detector train cfg/eyes.data cfg/yolo-eyes.cfg backup/yolo-eyes_2000.weights| tee person_train_log.txt
在前面的训练命令后面加上| tee person_train_log.txt即可,保存log时会生成两个文件,文件1里保存的是网络加载信息和checkout点保存信息,person_train_log.txt中保存的是训练信息。 在使用脚本绘制变化曲线之前,需要先使用extract_log.py脚本,格式化log,用生成的新的log文件供可视化工具绘图,格式化log的extract_log.py脚本如下:
# coding=utf-8
# 该文件用来提取训练log,去除不可解析的log后使log文件格式化,生成新的log文件供可视化工具绘图
def extract_log(log_file,new_log_file,key_word):
f = open(log_file)
train_log = open(new_log_file, 'w')
for line in f:
# 去除多gpu的同步log
if 'Syncing' in line:
continue
# 去除除零错误的log
if 'nan' in line:
continue
if key_word in line:
train_log.write(line)
f.close()
train_log.close()
extract_log('person_train_log.txt','person_train_log_loss.txt','images') #voc_train_log.txt 用于绘制loss曲线
extract_log('person_train_log.txt','person_train_log_iou.txt','IOU')
使用train_loss_visualization.py脚本可以绘制loss变化曲线
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#%matplotlib inline
lines =9873
result = pd.read_csv('person_train_log_loss.txt', skiprows=[x for x in range(lines) if ((x%10!=9) |(x<1000))] ,error_bad_lines=False, names=['loss', 'avg', 'rate', 'seconds', 'images'])
result.head()
result['loss']=result['loss'].str.split(' ').str.get(1)
result['avg']=result['avg'].str.split(' ').str.get(1)
result['rate']=result['rate'].str.split(' ').str.get(1)
result['seconds']=result['seconds'].str.split(' ').str.get(1)
result['images']=result['images'].str.split(' ').str.get(1)
result.head()
result.tail()
#print(result.head())
# print(result.tail())
# print(result.dtypes)
print(result['loss'])
print(result['avg'])
print(result['rate'])
print(result['seconds'])
print(result['images'])
result['loss']=pd.to_numeric(result['loss'])
result['avg']=pd.to_numeric(result['avg'])
result['rate']=pd.to_numeric(result['rate'])
result['seconds']=pd.to_numeric(result['seconds'])
result['images']=pd.to_numeric(result['images'])
result.dtypes
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(result['avg'].values,label='avg_loss')
#ax.plot(result['loss'].values,label='loss')
ax.legend(loc='best')
ax.set_title('The loss curves')
ax.set_xlabel('batches')
fig.savefig('avg_loss')
#fig.savefig('loss')
可以通过分析损失变化曲线,修改cfg中的学习率变化策略,比如上图:模型在100000万次迭代后损失下降速度非常慢,几乎没有下降。结合log和cfg文件发现,自定义的学习率变化策略在十万次迭代时会减小十倍,十万次迭代后学习率下降到非常小的程度,导致损失下降速度降低。修改cfg中的学习率变化策略,10万次迭代时不改变学习率,30万次时再降低。
除了可视化loss,还可以可视化Avg IOU,Avg Recall等参数
可视化’Region Avg IOU’, ‘Class’, ‘Obj’, ‘No Obj’, ‘Avg Recall’,’count’这些参数可以使用脚本train_iou_visualization.py,使用方式和train_loss_visualization.py相同,train_iou_visualization.py脚本如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#%matplotlib inline
lines =9873
result = pd.read_csv('voc_train_log_iou.txt', skiprows=[x for x in range(lines) if (x%10==0 or x%10==9) ] ,error_bad_lines=False, names=['Region Avg IOU', 'Class', 'Obj', 'No Obj', 'Avg Recall','count'])
result.head()
result['Region Avg IOU']=result['Region Avg IOU'].str.split(': ').str.get(1)
result['Class']=result['Class'].str.split(': ').str.get(1)
result['Obj']=result['Obj'].str.split(': ').str.get(1)
result['No Obj']=result['No Obj'].str.split(': ').str.get(1)
result['Avg Recall']=result['Avg Recall'].str.split(': ').str.get(1)
result['count']=result['count'].str.split(': ').str.get(1)
result.head()
result.tail()
#print(result.head())
# print(result.tail())
# print(result.dtypes)
print(result['Region Avg IOU'])
result['Region Avg IOU']=pd.to_numeric(result['Region Avg IOU'])
result['Class']=pd.to_numeric(result['Class'])
result['Obj']=pd.to_numeric(result['Obj'])
result['No Obj']=pd.to_numeric(result['No Obj'])
result['Avg Recall']=pd.to_numeric(result['Avg Recall'])
result['count']=pd.to_numeric(result['count'])
result.dtypes
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(result['Region Avg IOU'].values,label='Region Avg IOU')
#ax.plot(result['Class'].values,label='Class')
#ax.plot(result['Obj'].values,label='Obj')
#ax.plot(result['No Obj'].values,label='No Obj')
#ax.plot(result['Avg Recall'].values,label='Avg Recall')
#ax.plot(result['count'].values,label='count')
ax.legend(loc='best')
#ax.set_title('The Region Avg IOU curves')
ax.set_title('The Region Avg IOU curves')
ax.set_xlabel('batches')
#fig.savefig('Avg IOU')
fig.savefig('Region Avg IOU')xianka
YX师弟的补充:关于可视化
YOLO-V3可视化训练过程中的参数,绘制loss、IOU、avg Recall等的曲线图
https://blog.csdn.net/qq_34806812/article/details/81459982
./darknet detector train pds/fish/cfg/fish.data pds/fish/cfg/yolov3-fish.cfg darknet53.conv.74 2>1 | tee visualization/train_yolov3.log
YOLOv3训练过程中重要参数的理解和输出参数的含义
https://blog.csdn.net/maweifei/article/details/81148414
avg: 是平均Loss,这个数值应该越低越好,一般来说,一旦这个数值低于0.060730 avg就可以终止训练了。
train_iou_visualization.py
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#%matplotlib inline
lines = 122956
result = pd.read_csv('train_log_iou.txt', skiprows=[x for x in range(lines) if (x%10==0 or x%10==9) ] ,error_bad_lines=False, names=['Region Avg IOU', 'Class', 'Obj', 'No Obj', 'Avg Recall','count'])
result.head()
result['Region Avg IOU']=result['Region Avg IOU'].str.split(': ').str.get(1)
result['Class']=result['Class'].str.split(': ').str.get(1)
result['Obj']=result['Obj'].str.split(': ').str.get(1)
result['No Obj']=result['No Obj'].str.split(': ').str.get(1)
result['Avg Recall']=result['Avg Recall'].str.split(': ').str.get(1)
result['count']=result['count'].str.split(': ').str.get(1)
result.head()
result.tail()
# print(result.head())
# print(result.tail())
# print(result.dtypes)
print(result['Region Avg IOU'])
result['Region Avg IOU']=pd.to_numeric(result['Region Avg IOU'])
result['Class']=pd.to_numeric(result['Class'])
result['Obj']=pd.to_numeric(result['Obj'])
result['No Obj']=pd.to_numeric(result['No Obj'])
result['Avg Recall']=pd.to_numeric(result['Avg Recall'])
result['count']=pd.to_numeric(result['count'])
result.dtypes
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(result['Region Avg IOU'].values,label='Region Avg IOU')
# ax.plot(result['Class'].values,label='Class')
# ax.plot(result['Obj'].values,label='Obj')
# ax.plot(result['No Obj'].values,label='No Obj')
# ax.plot(result['Avg Recall'].values,label='Avg Recall')
# ax.plot(result['count'].values,label='count')
ax.legend(loc='best')
# ax.set_title('The Region Avg IOU curves')
ax.set_title('The Region Avg IOU curves')
ax.set_xlabel('batches')
# fig.savefig('Avg IOU')
fig.savefig('Region Avg IOU')
train_loss_visualization.py
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#%matplotlib inline
lines =987300
result = pd.read_csv('train_log_loss.txt', skiprows=[x for x in range(lines) if ((x%10!=9) |(x<1000))] ,error_bad_lines=False, names=['loss', 'avg', 'rate', 'seconds', 'images'])
result.head()
result['loss']=result['loss'].str.split(' ').str.get(1)
result['avg']=result['avg'].str.split(' ').str.get(1)
result['rate']=result['rate'].str.split(' ').str.get(1)
result['seconds']=result['seconds'].str.split(' ').str.get(1)
result['images']=result['images'].str.split(' ').str.get(1)
result.head()
result.tail()
#print(result.head())
# print(result.tail())
# print(result.dtypes)
print(result['loss'])
print(result['avg'])
print(result['rate'])
print(result['seconds'])
print(result['images'])
result['loss']=pd.to_numeric(result['loss'])
result['avg']=pd.to_numeric(result['avg'])
result['rate']=pd.to_numeric(result['rate'])
result['seconds']=pd.to_numeric(result['seconds'])
result['images']=pd.to_numeric(result['images'])
result.dtypes
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(result['avg'].values,label='avg_loss')
#ax.plot(result['loss'].values,label='loss')
ax.legend(loc='best')
ax.set_title('The loss curves')
ax.set_xlabel('batches')
fig.savefig('avg_loss')
#fig.savefig('loss')