神经网络学习小记录19——微调VGG分类模型训练自己的数据(猫狗数据集)
神经网络学习小记录19——微调VGG分类模型训练自己的数据(猫狗数据集)
- 学习前言
- 什么是VGG16模型
- VGG模型的复杂程度
- 训练前准备
- 1、数据集处理
- 2、创建Keras的VGG模型
- 3、下载VGG16的权重
- 开始训练
- 1、训练的主函数
- 2、全部代码
- 训练结果
学习前言
前两天,训练了一下简化版AlexNet网络,发现整个网络训练起来太慢了,我看了许多成熟的目标检测模型,其都是基于已有的特征检测模型进行训练的。
这种方式似乎还有一个名字叫做迁移学习,于是乎,我决定微调一下VGG网络来识别猫和狗。

什么是VGG16模型
关于什么是VGG16模型,及其代码复现,其实我在另一篇博文已经讲过了,大家可以去看看。神经网络学习小记录16——VGG16模型的复现及其详解(包含如何预测)
这里还是重提一下:
VGG是由Simonyan 和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写。
该模型参加2014年的 ImageNet图像分类与定位挑战赛,取得了优异成绩:在分类任务上排名第二,在定位任务上排名第一。
可能大家会想,这样一个这么强的模型肯定很复杂吧?
其实一点也不复杂,它的结构如下图所示:
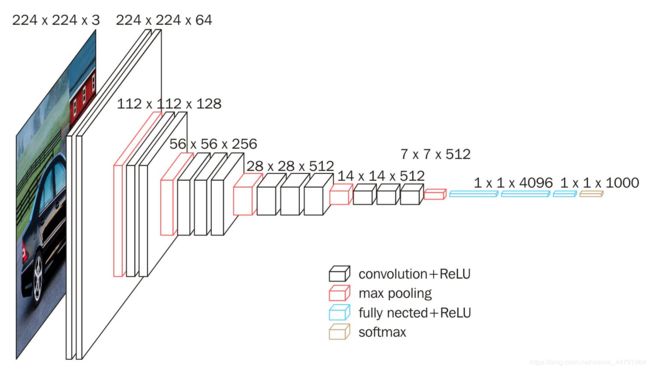
这是一个VGG被用到烂的图,但确实很好的反应了VGG的结构:
1、一张原始图片被resize到(224,224,3)。
2、conv1两次[3,3]卷积网络,输出的特征层为64,输出为(224,224,64),再2X2最大池化,输出net为(112,112,64)。
3、conv2两次[3,3]卷积网络,输出的特征层为128,输出net为(112,112,128),再2X2最大池化,输出net为(56,56,128)。
4、conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(56,56,256),再2X2最大池化,输出net为(28,28,256)。
5、conv4三次[3,3]卷积网络,输出的特征层为512,输出net为(28,28,512),再2X2最大池化,输出net为(14,14,512)。
6、conv5三次[3,3]卷积网络,输出的特征层为512,输出net为(14,14,512),再2X2最大池化,输出net为(7,7,512)。
7、利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,4096)。共进行两次。
8、利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,1000)。
最后输出的就是每个类的预测。
VGG模型的复杂程度
由于最后两个全连接层的存在,VGG模型的参数特别多,每个层的参数如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fullc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
fullc2 (Dense) (None, 4096) 16781312
fullc3 (Dense) (None, 20) 81940
=================================================================
Total params: 134,342,484
Trainable params: 134,342,484
Non-trainable params: 0
_________________________________________________________________
None
因为只对猫和狗进行分类,所以最后的全连接层可以缩小一点,本例子中将其缩小到256。
前面的卷积层可以不训练,因为卷积层的作用主要是提取特征,已经训练好的VGG提取的特征都是比较有用的,所以可以不进行调整,只对最后三个全连接层进行训练。
训练前准备
1、数据集处理
在数据集处理之前,首先要下载猫狗数据集,地址如下。
链接:https://pan.baidu.com/s/1HBewIgKsFD8hh3ICOnnTwA
提取码:ktab
顺便直接下载我的源代码吧。
链接: https://pan.baidu.com/s/1r79Ey_2ZPZc73GND-kUxxg
提取码: w5bg
这里的源代码包括了所有的代码部分,训练集需要自己下载,大概训练2个小时就可以进行预测了。
本次教程准备使用model.fit_generator来训练模型,在训练模型之前,需要将数据集的内容保存到一个TXT文件中,便于读取。
txt文件的保存格式如下:
文件名;种类

具体操作步骤如下:
1、将训练文件存到"./data/image/train/"目录下。

2、调用如下代码:
import os
with open('./data/train.txt','w') as f:
after_generate = os.listdir("./data/image/train")
for image in after_generate:
if image.split(".")[0]=='cat':
f.write(image + ";" + "0" + "\n")
else:
f.write(image + ";" + "1" + "\n")
就可以得到训练数据集的文本文件。
2、创建Keras的VGG模型
VGG的模型的结构已经在上面介绍过了,利用Keras就可以构建。在这里我给他添加了一个7x7的卷积层,同时把全连接层改为256。
import tensorflow as tf
from tensorflow import keras
from keras import Model,Sequential
from keras.layers import Flatten, Dense, Conv2D, GlobalAveragePooling2D
from keras.layers import Input, MaxPooling2D, GlobalMaxPooling2D
def VGG16(num_classes):
image_input = Input(shape = (224,224,3))
# 第一个卷积部分
x = Conv2D(64,(3,3),activation = 'relu',padding = 'same',name = 'block1_conv1')(image_input)
x = Conv2D(64,(3,3),activation = 'relu',padding = 'same', name = 'block1_conv2')(x)
x = MaxPooling2D((2,2), strides = (2,2), name = 'block1_pool')(x)
# 第二个卷积部分
x = Conv2D(128,(3,3),activation = 'relu',padding = 'same',name = 'block2_conv1')(x)
x = Conv2D(128,(3,3),activation = 'relu',padding = 'same',name = 'block2_conv2')(x)
x = MaxPooling2D((2,2),strides = (2,2),name = 'block2_pool')(x)
# 第三个卷积部分
x = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv1')(x)
x = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv2')(x)
x = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv3')(x)
x = MaxPooling2D((2,2),strides = (2,2),name = 'block3_pool')(x)
# 第四个卷积部分
x = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv1')(x)
x = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv2')(x)
x = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv3')(x)
x = MaxPooling2D((2,2),strides = (2,2),name = 'block4_pool')(x)
# 第五个卷积部分
x = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv1')(x)
x = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv2')(x)
x = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv3')(x)
x = MaxPooling2D((2,2),strides = (2,2),name = 'block5_pool')(x)
# 分类部分
x = Conv2D(256,(7,7),activation = 'relu',padding = 'valid', name = 'block6_conv4')(x)
x = Flatten(name = 'flatten')(x)
x = Dense(256,activation = 'relu',name = 'fullc1')(x)
x = Dense(256,activation = 'relu',name = 'fullc2')(x)
x = Dense(num_classes,activation = 'softmax',name = 'fullc3')(x)
model = Model(image_input,x,name = 'vgg16')
return model
3、下载VGG16的权重
这个网址拉到最下面就可以了。
https://github.com/fchollet/deep-learning-models/releases
下载这个文件:vgg16_weights_tf_dim_ordering_tf_kernels.h5。
开始训练
1、训练的主函数
训练的主函数主要包括如下部分:
1、读取训练用txt,并打乱,利用该txt进行训练集和测试集的划分。
2、建立VGG16模型,载入权重。这里要注意skip_mismatch=True。
3、利用model.layers[i].trainable = False将VGG16前面的卷积层设置成不可训练。仅训练最后五层。
3、设定模型保存的方式、学习率下降的方式、是否需要早停。
4、利用model.fit_generator训练模型。
具体代码如下:
if __name__ == "__main__":
# 模型保存的位置
log_dir = "./logs/"
# 打开数据集的txt
with open(r".\data\train.txt","r") as f:
lines = f.readlines()
# 打乱行,这个txt主要用于帮助读取数据来训练
# 打乱的数据更有利于训练
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
# 90%用于训练,10%用于估计。
num_val = int(len(lines)*0.1)
num_train = len(lines) - num_val
# 建立AlexNet模型
model = VGG16(2)
# 注意要开启skip_mismatch和by_name
model.load_weights("vgg16_weights_tf_dim_ordering_tf_kernels.h5",by_name=True,skip_mismatch=True)
# 指定训练层
for i in range(0,len(model.layers)-5):
model.layers[i].trainable = False
# 保存的方式,3世代保存一次
checkpoint_period1 = ModelCheckpoint(
log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='acc',
save_weights_only=False,
save_best_only=True,
period=3
)
# 学习率下降的方式,acc三次不下降就下降学习率继续训练
reduce_lr = ReduceLROnPlateau(
monitor='acc',
factor=0.5,
patience=3,
verbose=1
)
# 是否需要早停,当val_loss一直不下降的时候意味着模型基本训练完毕,可以停止
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0,
patience=10,
verbose=1
)
# 交叉熵
model.compile(loss = 'categorical_crossentropy',
optimizer = Adam(lr=1e-3),
metrics = ['accuracy'])
# 一次的训练集大小
batch_size = 16
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
# 开始训练
model.fit_generator(generate_arrays_from_file(lines[:num_train], batch_size),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=generate_arrays_from_file(lines[num_train:], batch_size),
validation_steps=max(1, num_val//batch_size),
epochs=50,
initial_epoch=0,
callbacks=[checkpoint_period1, reduce_lr])
model.save_weights(log_dir+'last1.h5')
model.fit_generator需要用到python的生成器来滚动读取数据,具体使用方法可以看我的另一篇博文神经网络学习小记录17——使用AlexNet分类模型训练自己的数据(猫狗数据集)。
2、全部代码
大家可以整体看看哈:
from keras.callbacks import TensorBoard, ModelCheckpoint, ReduceLROnPlateau, EarlyStopping
from keras.utils import np_utils
from keras.optimizers import Adam
from model.VGG16 import VGG16
import numpy as np
import utils
import cv2
from keras import backend as K
K.set_image_dim_ordering('tf')
def generate_arrays_from_file(lines,batch_size):
# 获取总长度
n = len(lines)
i = 0
while 1:
X_train = []
Y_train = []
# 获取一个batch_size大小的数据
for b in range(batch_size):
if i==0:
np.random.shuffle(lines)
name = lines[i].split(';')[0]
# 从文件中读取图像
img = cv2.imread(r".\data\image\train" + '/' + name)
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
img = img/255
X_train.append(img)
Y_train.append(lines[i].split(';')[1])
# 读完一个周期后重新开始
i = (i+1) % n
# 处理图像
X_train = utils.resize_image(X_train,(224,224))
X_train = X_train.reshape(-1,224,224,3)
Y_train = np_utils.to_categorical(np.array(Y_train),num_classes= 2)
yield (X_train, Y_train)
if __name__ == "__main__":
# 模型保存的位置
log_dir = "./logs/"
# 打开数据集的txt
with open(r".\data\train.txt","r") as f:
lines = f.readlines()
# 打乱行,这个txt主要用于帮助读取数据来训练
# 打乱的数据更有利于训练
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
# 90%用于训练,10%用于估计。
num_val = int(len(lines)*0.1)
num_train = len(lines) - num_val
# 建立AlexNet模型
model = VGG16(2)
# 注意要开启skip_mismatch和by_name
model.load_weights("vgg16_weights_tf_dim_ordering_tf_kernels.h5",by_name=True,skip_mismatch=True)
# 指定训练层
for i in range(0,len(model.layers)-5):
model.layers[i].trainable = False
# 保存的方式,3世代保存一次
checkpoint_period1 = ModelCheckpoint(
log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='acc',
save_weights_only=False,
save_best_only=True,
period=3
)
# 学习率下降的方式,acc三次不下降就下降学习率继续训练
reduce_lr = ReduceLROnPlateau(
monitor='acc',
factor=0.5,
patience=3,
verbose=1
)
# 是否需要早停,当val_loss一直不下降的时候意味着模型基本训练完毕,可以停止
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0,
patience=10,
verbose=1
)
# 交叉熵
model.compile(loss = 'categorical_crossentropy',
optimizer = Adam(lr=1e-3),
metrics = ['accuracy'])
# 一次的训练集大小
batch_size = 16
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
# 开始训练
model.fit_generator(generate_arrays_from_file(lines[:num_train], batch_size),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=generate_arrays_from_file(lines[num_train:], batch_size),
validation_steps=max(1, num_val//batch_size),
epochs=50,
initial_epoch=0,
callbacks=[checkpoint_period1, reduce_lr])
model.save_weights(log_dir+'last1.h5')
训练结果
在完成上述的一大堆内容的配置后就可以开始训练了,所有文件的构架如下:

训练效果挺好的,才训练两次准确度就已经有90%多了。(目测后面过拟合了)。
Epoch 1/50
1406/1406 [==============================] - 862s 613ms/step - loss: 0.2301 - acc: 0.9052 - val_loss: 0.1760 - val_acc: 0.9315
Epoch 2/50
1406/1406 [==============================] - 869s 618ms/step - loss: 0.1446 - acc: 0.9423 - val_loss: 0.1745 - val_acc: 0.9267
Epoch 3/50
1406/1406 [==============================] - 867s 617ms/step - loss: 0.0987 - acc: 0.9632 - val_loss: 0.1762 - val_acc: 0.9253
预测一下
import numpy as np
import utils
import cv2
from keras import backend as K
from model.VGG16 import VGG16
K.set_image_dim_ordering('tf')
if __name__ == "__main__":
model = VGG16(2)
model.load_weights("./logs/ep003-loss0.109-val_loss0.178.h5")
img = cv2.imread("./data/image/train/cat.1.jpg")
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
img = img/255
img = np.expand_dims(img,axis = 0)
img = utils.resize_image(img,(224,224))
#utils.print_answer(np.argmax(model.predict(img)))
print(utils.print_answer(np.argmax(model.predict(img))))
结果是
猫
猫