azkaban3.x学习(一)安装部署
azkaban3.x学习(一)安装部署
- 背景
- 安装
- 源码构建
- solo-server模式部署
- 分布式多执行器模式部署
- 初始化DB环境
- 部署executor-server
- web-server部署
背景
公司最近需要搭建一个工作流任务调度系统,最终选择开源框架azkaban,目前只是学习分享,如有误解偏差,欢迎指正;
azkaban官网这样描述:
Azkaban is a batch workflow job scheduler created at LinkedIn to run Hadoop jobs. Azkaban resolves the ordering through job dependencies and provides an easy to use web user interface to maintain and track your workflows.
以及特性:
- Compatible with any version of Hadoop
- Easy to use web UI
- Simple web and http workflow uploads
- Project workspaces
- Scheduling of workflows
- Modular and pluginable
- Authentication and Authorization
- Tracking of user actions
- Email alerts on failure and successes
- SLA alerting and auto killing
- Retrying of failed jobs
基本可以满足Hadoop体系的工作流任务调度。
安装
azkaban3.0以上版本,支持两种部署方式:独立服务器(alone “solo-server”)模式以及分布式多执行器(distributed multiple-executor)模式。
独立服务器模式可以用于小规模的用例,使用嵌入H2数据库,Web-server和executor-server都在同一进程中运行。
分布式多执行器模式适用于重量级的生产环境。官方推荐它的DB应该由具有主从设置的MySQL实例支持。并且在理想情况下,Web-server和executor-server应在不同的主机中运行,以便升级和维护,并提升azkaban的使用性能。
不论使用哪一种部署方式,部署之前都需要先构建源码,环境依赖Java 8+;
源码地址:https://github.com/azkaban/azkaban
源码构建
- 将源码clone到服务器
git clone https://github.com/azkaban/azkaban.git
- 构建
cd azkaban
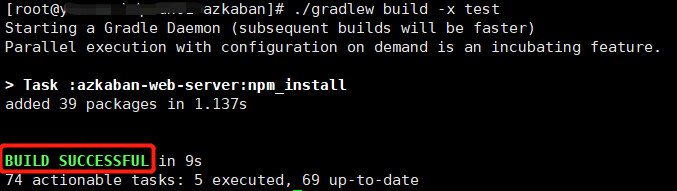
./gradlew clean installDist build -x test
注:gradle构建需要下载依赖,网络条件不好可多次构建,直至构建成功
solo-server模式部署
对于独立服务器模式,其官方文档这样描述:
- Easy to install - No MySQL instance is needed. It packages H2 as its main persistence storage.
- Easy to start up - Both web server and executor server run in the same process.
- Full featured - It packages all Azkaban features. You can use it in normal ways and install plugins for it.
确实此模式部署相当方便,我们只需要进入solo-server构建包:
cd azkaban-solo-server/build/install/azkaban-solo-server/
./bin/start-solo.sh \\这里注意从根路径启动服务
当然也可以将它的tar.gz包解压到指定目录启动,这里不再阐述:

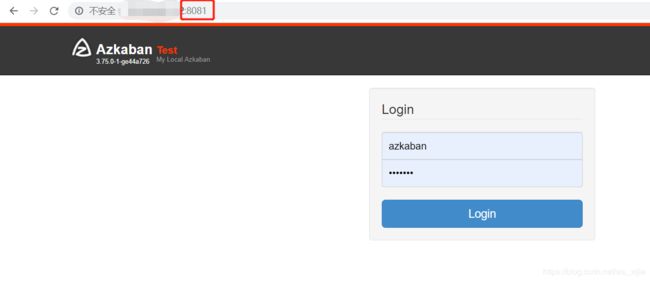
访问服务器8081端口即可,默认账号密码azkaban/azkaban:
关闭服务
./bin/shutdown-solo.sh

分布式多执行器模式部署
分布式多服务器部署步骤大概可以概括为:
- 初始化DB环境
- 部署executor-server
- 部署web-server
初始化DB环境
官方推荐使用MySQL作为azkaban的DB环境,这里MySQL安装部署就不再赘述,MySQL安装好以后;
mysql> create database azkaban;
然后找到之前azkaban构建好的db文件:
cd azkaban-db/build/install/azkaban-db/
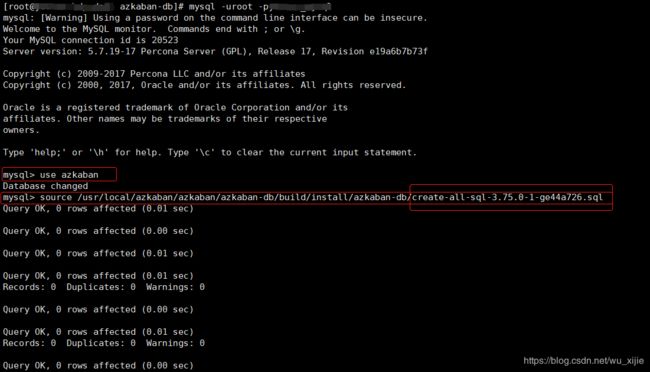
这个目录下构建成功后会有一个create-all-sql-(版本相关信息).sql的文件:

执行该文件初始化DB环境:
mysql> use azkaban
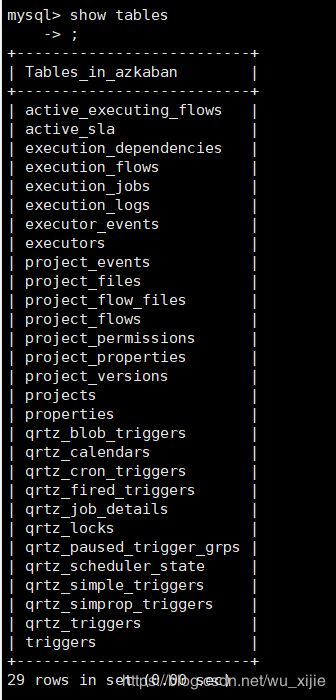
mysql> source /usr/local/azkaban/azkaban/azkaban-db/build/install/azkaban-db/create-all-sql-3.75.0-1-ge44a726.sql
部署executor-server
以下步骤同样基于构建成功,可直接从build/install包下部署,也可以copy tar.gz包解压部署。
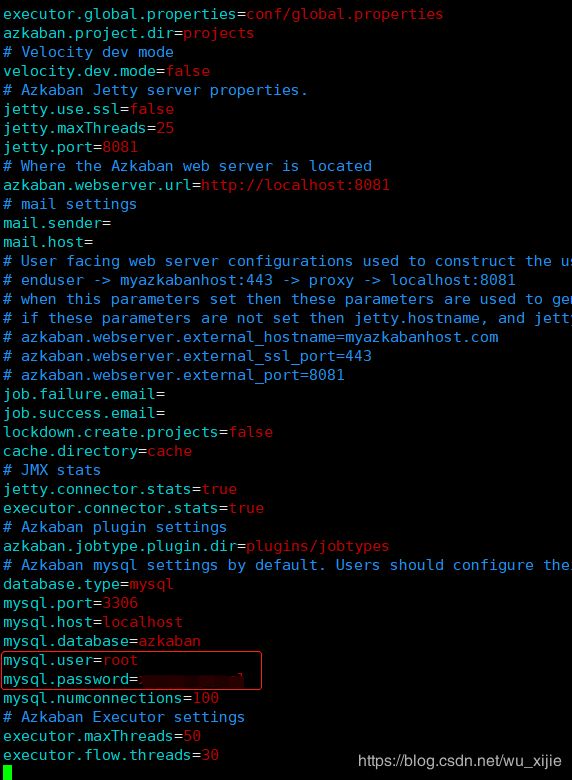
修改executor server数据库连接配置:
cd azkaban-exec-server/build/install/azkaban-exec-server/conf/
vim azkaban.properties

启动exec-server服务:
./bin/start-exec.sh
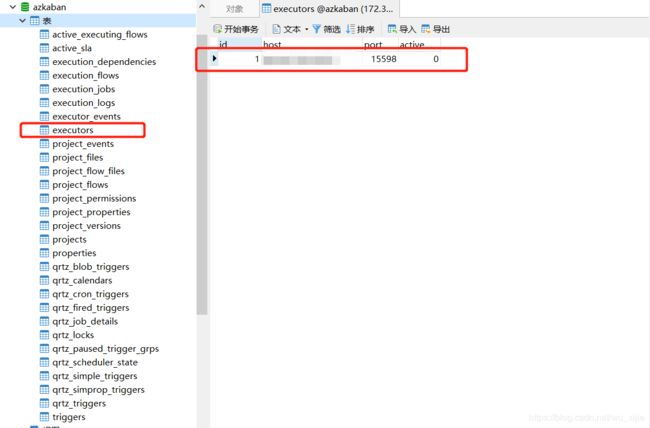
启动成功后,会在数据库executors表中插入一条记录,记录执行器信息
然后执行指令激活执行器:
curl -G "localhost:$(<./executor.port)/executor?action=activate" && echo //注意同样在exec-server根目录下执行
![]()
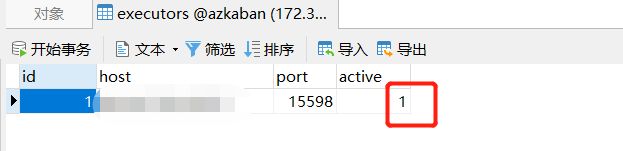
此时激活成功,数据库执行器状态变更为1
web-server部署
同样的在web-server包下修改数据库配置文件并启动服务(同exec-server步骤):

至此服务部署完成!
转载请标明出处https://blog.csdn.net/wu_xijie/article/details/97240568
本文转自wu_xijie的博客